经过前10节,我们已经建立了完整体系:
👉 但一个更高层问题是:
统计学 和 机器学习,本质上到底是什么关系?
Part 1统一视角
所有方法,本质都在解决:
👉 区别在于:
👉 统一表达:
Part 2全图谱
数据 → 描述统计 → 分布认知↓CLT / Bootstrap↓参数估计(MLE)↓推断(CI / 检验)↓建模(Regression)↓正则化(Ridge / Lasso)↓Bias–Variance 分解↓模型选择(CV)↓工程决策
Part 3Python可视化(全流程认知)
# file: full_pipeline_visualization.pyimport numpy as npimport matplotlib.pyplot as pltdeftrue_function(x):return np.sin(2*np.pi*x)defmain(): np.random.seed(0) x = np.linspace(0,1,100) y_true = true_function(x) y_obs = y_true + np.random.normal(0,0.2,100) plt.figure(figsize=(10,6))# 原始数据 plt.scatter(x, y_obs, alpha=0.5, label="data")# 低复杂度模型 coef1 = np.polyfit(x, y_obs, 1) y1 = np.polyval(coef1, x) plt.plot(x, y1, label="underfit")# 高复杂度模型 coef2 = np.polyfit(x, y_obs, 15) y2 = np.polyval(coef2, x) plt.plot(x, y2, label="overfit")# 真实函数 plt.plot(x, y_true, linewidth=3, label="true") plt.legend() plt.title("Full Pipeline: Data → Model → Overfitting") plt.show()if __name__ == "__main__": main()
执行结果如下: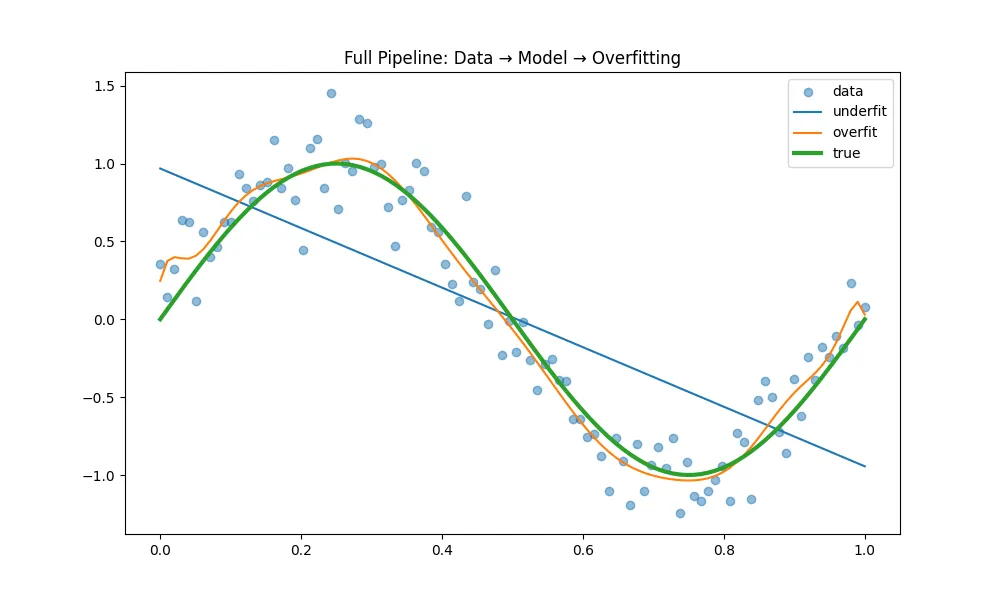
Part 4Bias–Variance 可视化(核心)
# file: bias_variance_curve.pyimport numpy as npimport matplotlib.pyplot as pltdefmain(): complexity = np.linspace(1,20,100) bias = 1 / complexity variance = complexity / 20 total = bias + variance plt.figure(figsize=(8,5)) plt.plot(complexity, bias, label="Bias^2") plt.plot(complexity, variance, label="Variance") plt.plot(complexity, total, label="Total Error", linewidth=3) plt.xlabel("Model Complexity") plt.ylabel("Error") plt.title("Bias-Variance Tradeoff") plt.legend() plt.show()if __name__ == "__main__": main()
执行结果如下: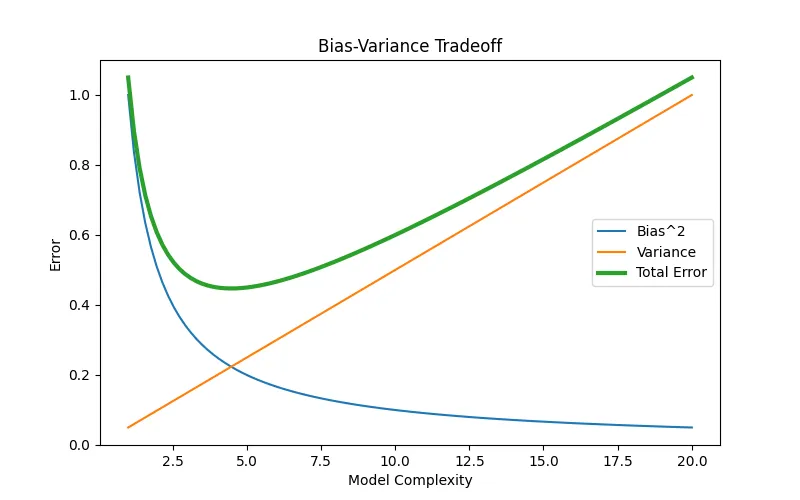
Part 5Cross Validation 可视化
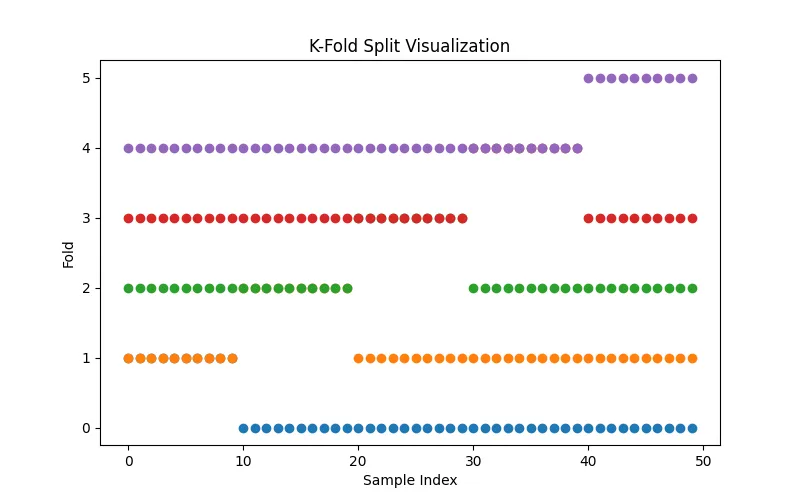
# file: cv_visualization.pyimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.model_selection import KFolddefmain(): n = 50 K = 5 kf = KFold(n_splits=K) plt.figure(figsize=(8,5))for i, (train, test) in enumerate(kf.split(range(n))): y = np.zeros(n) y[test] = 1 plt.scatter(range(n), y + i, label=f"Fold {i}") plt.title("K-Fold Split Visualization") plt.xlabel("Sample Index") plt.ylabel("Fold") plt.show()if __name__ == "__main__": main()
执行结果如下:Part 6Bootstrap 可视化
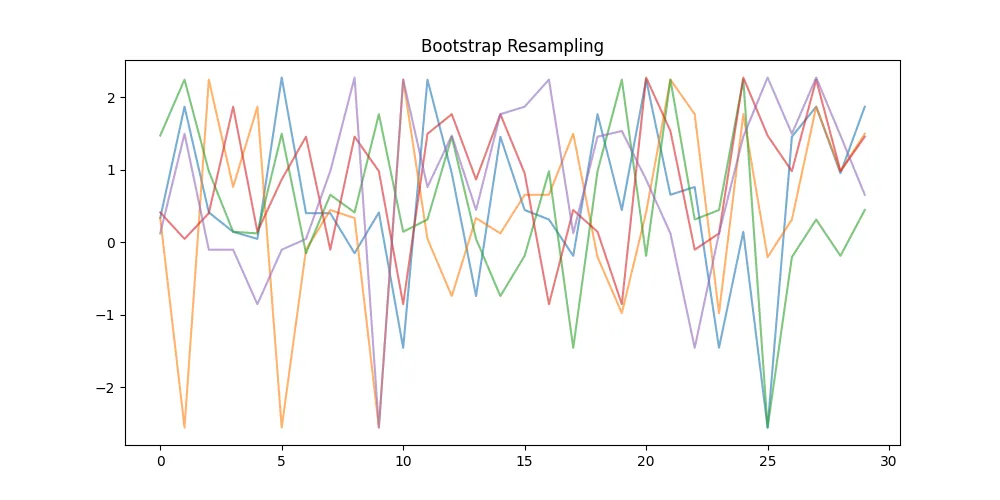
# file: bootstrap_visual.pyimport numpy as npimport matplotlib.pyplot as pltdefmain(): np.random.seed(0) data = np.random.normal(0,1,30) plt.figure(figsize=(10,5))for i in range(5): sample = np.random.choice(data, len(data), replace=True) plt.plot(sample, alpha=0.6) plt.title("Bootstrap Resampling") plt.show()if __name__ == "__main__": main()
执行结果如下:Part 7方法选型指南
情况1:小样本 + 分布未知
👉 使用:
情况2:大样本
👉 使用:
情况3:高维数据
👉 使用:
情况4:模型选择
👉 使用:
情况5:解释 vs 预测
Part 8最终统一公式
整个统计学习可以统一为:
👉 所有方法只是这个框架的不同实例
Part 9最终理解
统计学关注:
机器学习关注:
👉 本质统一:
都是在逼近真实函数