智能招聘数据分析平台
一、项目简介
1.1 项目背景
在数字化转型浪潮下,IT行业人才需求呈现爆发式增长,但信息不对称成为求职者和企业的共同痛点:
1.2 解决方案
本平台构建了一套完整的招聘数据智能分析体系,通过:
为求职者提供市场洞察、薪资预测、岗位匹配三大核心服务,实现从"盲目投递"到"精准定位"的转变。
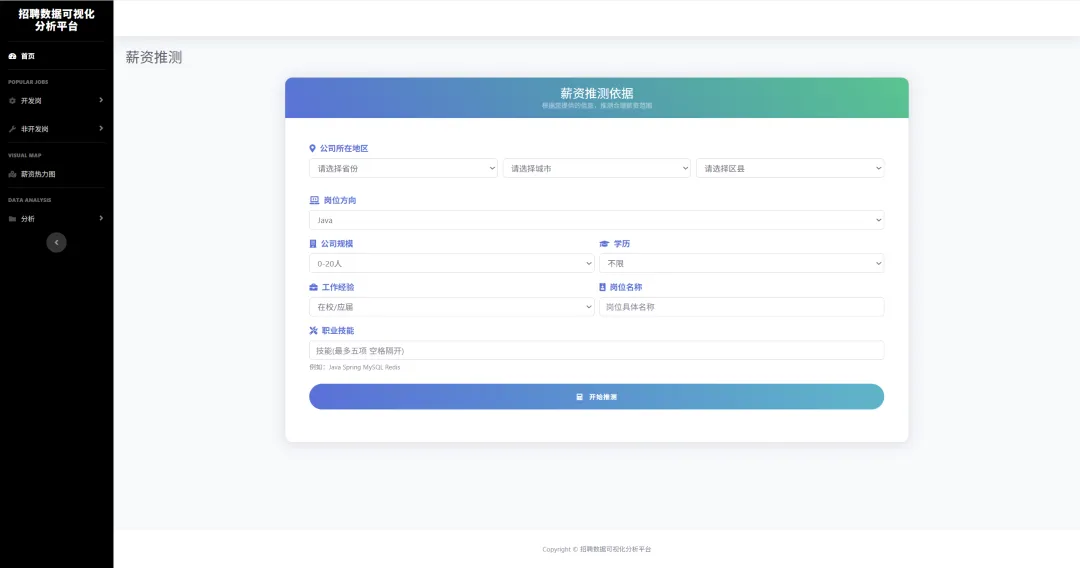
1.3 项目截图
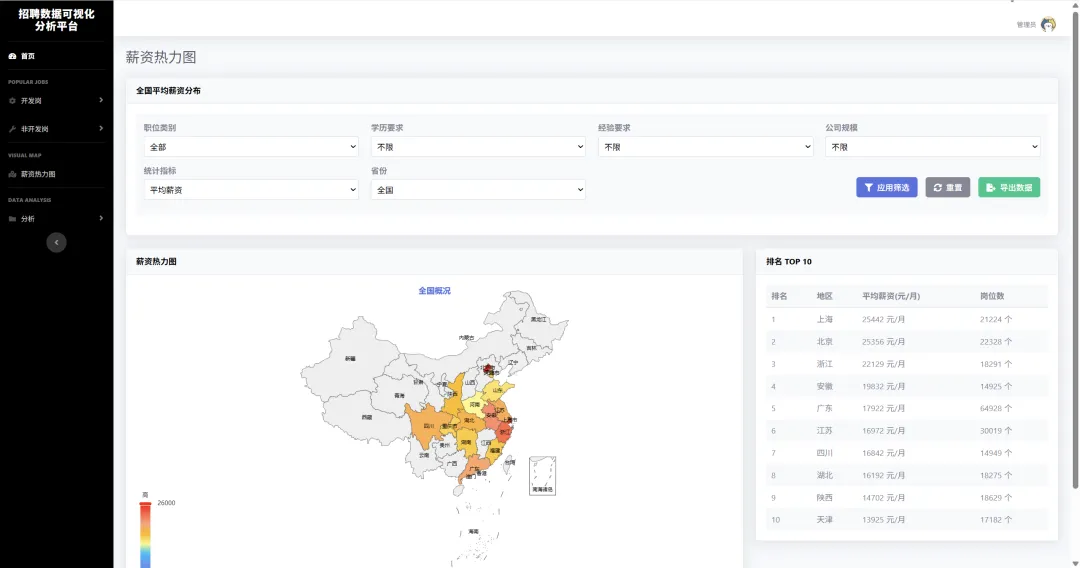
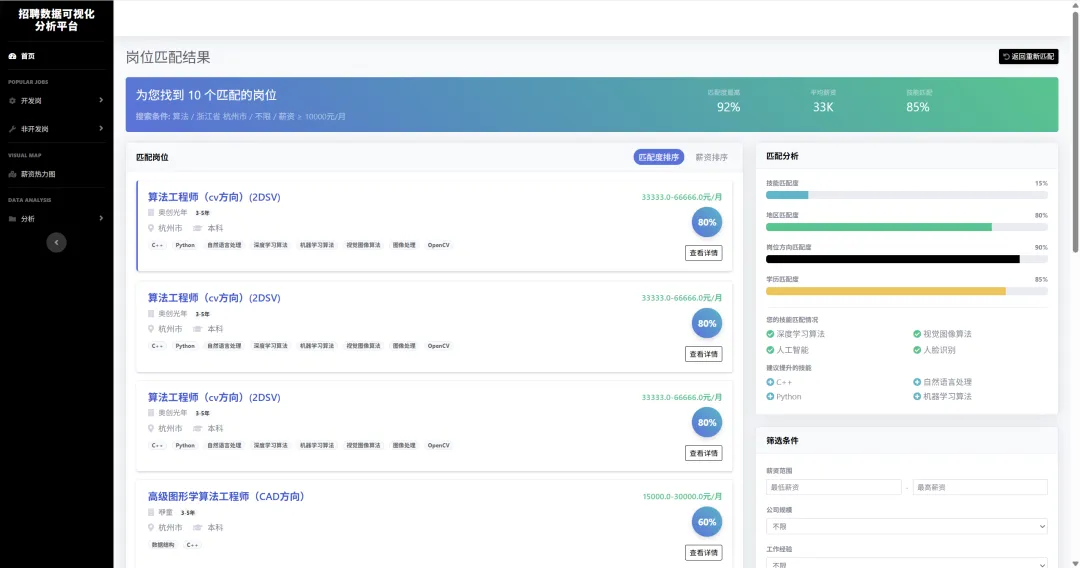
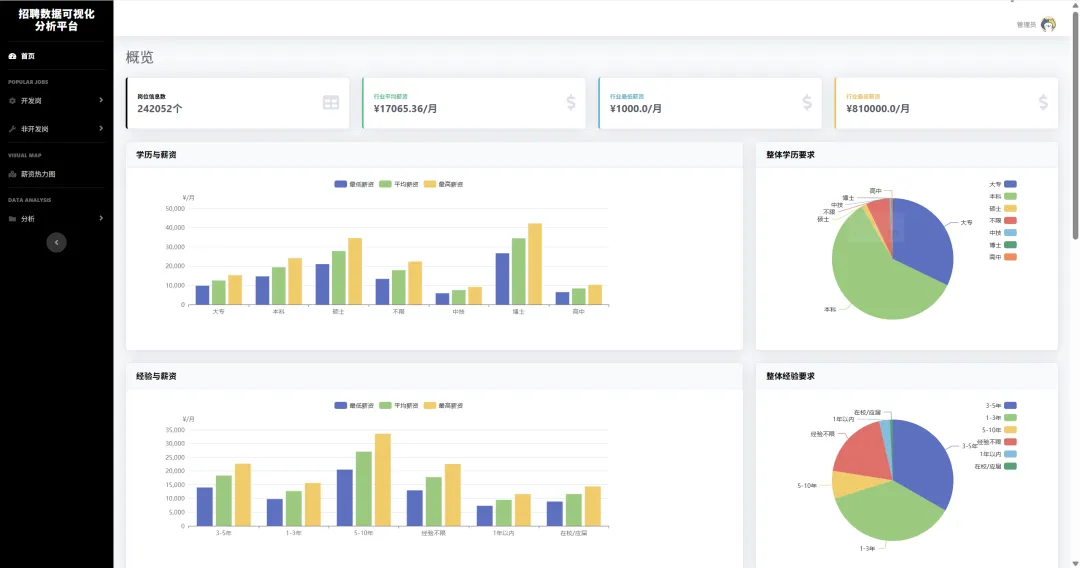
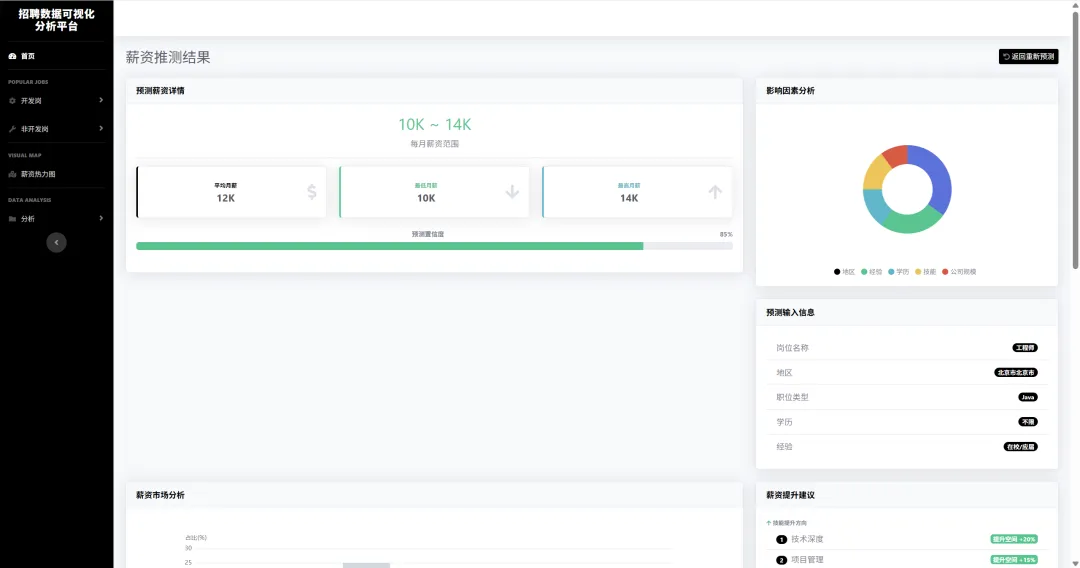
`
二、核心功能架构
| | | |
|---|
| 📊 市场洞察 | | | |
| 💰 薪资预测 | | | |
| 🎯 智能匹配 | | | |
| 🗺️ 地理分析 | | | |
| 📈 趋势预警 | | | |
三、技术架构
3.1 系统架构图
┌─────────────────────────────────────────────────────────────┐
│ 前端展示层 (Presentation) │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────────────┐ │
│ │ Vue3/React │ │ ECharts │ │ Bootstrap/Ant Design│ │
│ │ 响应式UI │ │ 数据可视化 │ │ 组件库 │ │
│ └─────────────┘ └─────────────┘ └─────────────────────┘ │
└──────────────────────────┬──────────────────────────────────┘
│ RESTful API
┌──────────────────────────▼──────────────────────────────────┐
│ 应用服务层 (Application) │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────────────┐ │
│ │ Flask API │ │ 岗位匹配引擎 │ │ 薪资预测服务 │ │
│ │ 路由控制 │ │ 相似度计算 │ │ ML模型推理 │ │
│ └─────────────┘ └─────────────┘ └─────────────────────┘ │
└──────────────────────────┬──────────────────────────────────┘
│
┌──────────────────────────▼──────────────────────────────────┐
│ 数据处理层 (Data Processing) │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────────────┐ │
│ │ Pandas │ │ Scikit-learn│ │ NLP处理 │ │
│ │ 数据清洗 │ │ 特征工程/建模 │ │ 技能提取/文本分析 │ │
│ └─────────────┘ └─────────────┘ └─────────────────────┘ │
└──────────────────────────┬──────────────────────────────────┘
│
┌──────────────────────────▼──────────────────────────────────┐
│ 数据存储层 (Data Storage) │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────────────┐ │
│ │ MySQL │ │ Redis │ │ Elasticsearch │ │
│ │ 结构化数据 │ │ 缓存/会话 │ │ 全文检索 │ │
│ └─────────────┘ └─────────────┘ └─────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
│
┌──────────────────────────┬──────────────────────────────────┐
│ 数据采集层 (Data Collection) │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────────────┐ │
│ │ Scrapy │ │ Playwright │ │ 代理IP池 │ │
│ │ 分布式爬虫 │ │ 动态渲染 │ │ 反爬策略 │ │
│ └─────────────┘ └─────────────┘ └─────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
3.2 技术栈详解
后端技术
| | |
|---|
| Python 3.9+ | | |
| Flask 2.x | | |
| SQLAlchemy | | |
| Pandas/NumPy | | |
| Scikit-learn | | |
| XGBoost | | |
| Celery | | |
前端技术
| | |
|---|
| Vue3 + TypeScript | | |
| ECharts 5.x | | |
| Element Plus | | |
| Axios | | |
数据存储
| | |
|---|
| MySQL 8.0 | | |
| Redis | | |
| Elasticsearch | | |
四、数据工程流程
4.1 数据Pipeline架构
┌──────────────┐ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ 数据采集 │ -> │ 数据清洗 │ -> │ 数据存储 │ -> │ 数据服务 │
│ (Ingestion) │ │ (Cleaning) │ │ (Storage) │ │ (Serving) │
└──────────────┘ └──────────────┘ └──────────────┘ └──────────────┘
│ │ │ │
▼ ▼ ▼ ▼
┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐
│多源爬虫 │ │去重/纠错 │ │关系型存储 │ │REST API │
│反爬策略 │ │标准化 │ │索引优化 │ │缓存策略 │
│增量更新 │ │特征提取 │ │分区策略 │ │权限控制 │
└─────────┘ └─────────┘ └─────────┘ └─────────┘
4.2 关键数据处理步骤
Step 1: 数据采集(Data Collection)
- 反爬策略:IP代理池轮换、请求频率控制、User-Agent池、Cookie管理
- 动态渲染:Playwright处理JavaScript动态加载内容
Step 2: 数据清洗(Data Cleaning)
# 核心清洗流程示例
清洗流程 = {
"去重": "基于URL+职位ID的布隆过滤器去重",
"标准化": {
"薪资": "统一转换为元/月,处理'面议'、'K'等单位",
"学历": "映射为:初中/高中/大专/本科/硕士/博士",
"经验": "解析为年数区间,处理'应届生'、'不限'等"
},
"纠错": "基于规则的异常值检测与修正",
"补全": "地理位置解析(省市区三级)、公司行业分类"
}
Step 3: 特征工程(Feature Engineering)
- 文本特征:TF-IDF提取技能关键词、职位描述向量化
五、核心算法实现
5.1 智能岗位匹配算法
算法原理
采用多因子加权相似度模型,综合考虑用户画像与岗位特征的匹配程度:
匹配得分 = Σ(权重i × 相似度i)
其中:
- 技能匹配度:Jaccard相似度(用户技能 ∩ 岗位要求)/(用户技能 ∪ 岗位要求)
- 地区匹配度:地理距离衰减函数,考虑通勤意愿
- 薪资匹配度:期望薪资与岗位薪资区间的重叠度
- 经验匹配度:工作年限与要求年限的偏差惩罚
- 方向匹配度:职位类别语义相似度(基于Word2Vec)
策略引擎
支持四种匹配策略,动态调整权重:
| | |
|---|
| 综合最优 | 技能0.3 + 地区0.2 + 薪资0.3 + 经验0.2 | |
| 技能优先 | 技能0.5 + 地区0.1 + 薪资0.2 + 经验0.2 | |
| 地区优先 | 技能0.2 + 地区0.5 + 薪资0.2 + 经验0.1 | |
| 薪资优先 | 技能0.2 + 地区0.1 + 薪资0.5 + 经验0.2 | |
5.2 薪资预测模型
模型架构
# 模型选择对比
模型对比 = {
"线性回归": {"RMSE": 3500, "R²": 0.72, "特点": "可解释性强,基线模型"},
"Random Forest": {"RMSE": 2800, "R²": 0.81, "特点": "处理非线性关系,特征重要性"},
"XGBoost": {"RMSE": 2200, "R²": 0.87, "特点": "精度最高,最终选用"},
"LightGBM": {"RMSE": 2350, "R²": 0.85, "特点": "训练速度快,备选方案"}
}
特征重要性(Top 10)
- 职位类别(25%):算法工程师 > 前端 > 测试
- 技能组合(10%:Python+算法 > 单一技能
预测输出
{
"predicted_salary": {
"min": 18000,
"max": 25000,
"median": 21000
},
"confidence": 0.85,
"market_position": "高于同经验75%的求职者",
"suggestions": [
"掌握Kubernetes可提升薪资约12%",
"考虑杭州/成都等二线城市,性价比更高"
]
}
六、项目目录结构
smart-recruit-analytics/
├── 📁 app/ # 应用核心
│ ├── __init__.py # 应用工厂
│ ├── api/ # RESTful API
│ │ ├── v1/
│ │ │ ├── jobs.py # 职位接口
│ │ │ ├── analysis.py # 分析接口
│ │ │ ├── predict.py # 预测接口
│ │ │ └── match.py # 匹配接口
│ │ └── errors.py # 全局异常处理
│ ├── models/ # 数据模型
│ │ ├── job.py # 职位模型
│ │ ├── company.py # 公司模型
│ │ └── user.py # 用户模型
│ ├── services/ # 业务逻辑层
│ │ ├── spider_service.py # 爬虫调度
│ │ ├── analysis_service.py # 数据分析
│ │ ├── predict_service.py # 薪资预测
│ │ └── match_service.py # 岗位匹配
│ └── utils/ # 工具函数
│ ├── decorators.py # 装饰器
│ ├── validators.py # 验证器
│ └── exceptions.py # 自定义异常
│
├── 📁 spider/ # 数据采集模块
│ ├── core/
│ │ ├── base_spider.py # 爬虫基类
│ │ ├── boss_spider.py # Boss直聘爬虫
│ │ ├── lagou_spider.py # 拉勾网爬虫
│ │ └── scheduler.py # 调度器
│ ├── middleware/
│ │ ├── proxy_pool.py # 代理池管理
│ │ ├── user_agent_rotator.py # UA轮换
│ │ └── retry_middleware.py # 重试机制
│ └── pipelines/
│ ├── validation.py # 数据验证
│ ├── cleaning.py # 清洗管道
│ └── storage.py # 存储管道
│
├── 📁 ml/ # 机器学习模块
│ ├── features/ # 特征工程
│ │ ├── extractors.py # 特征提取器
│ │ ├── transformers.py # 特征转换
│ │ └── selectors.py # 特征选择
│ ├── models/ # 模型定义
│ │ ├── salary_predictor.py # 薪资预测模型
│ │ ├── job_matcher.py # 岗位匹配模型
│ │ └── skill_extractor.py # 技能提取模型
│ ├── training/ # 训练脚本
│ │ ├── train_salary_model.py # 薪资模型训练
│ │ └── evaluate.py # 模型评估
│ └── deployed/ # 部署模型
│ ├── salary_xgb_v2.pkl # 薪资预测模型
│ ├── skill_vectorizer.pkl # 技能向量化器
│ └── scalers/ # 标准化器
│
├── 📁 analytics/ # 数据分析模块
│ ├── descriptive/ # 描述性统计
│ ├── diagnostic/ # 诊断分析
│ └── predictive/ # 预测分析
│
├── 📁 frontend/ # 前端项目
│ ├── src/
│ │ ├── components/ # 组件
│ │ ├── views/ # 页面
│ │ ├── api/ # 接口封装
│ │ └── store/ # 状态管理
│ └── public/
│
├── 📁 database/ # 数据库
│ ├── migrations/ # 迁移脚本
│ ├── seeds/ # 种子数据
│ └── schema.sql # 表结构
│
├── 📁 config/ # 配置文件
│ ├── settings.py # 主配置
│ ├── production.py # 生产环境
│ └── development.py # 开发环境
│
├── 📁 tests/ # 测试
│ ├── unit/ # 单元测试
│ ├── integration/ # 集成测试
│ └── e2e/ # 端到端测试
│
├── 📁 docs/ # 文档
│ ├── api/ # API文档
│ ├── deployment/ # 部署文档
│ └── architecture/ # 架构设计
│
├── 📁 scripts/ # 运维脚本
│ ├── deploy.sh # 部署脚本
│ ├── backup.sh # 备份脚本
│ └── crawl.sh # 采集脚本
│
├── 📄 requirements.txt # 依赖
├── 📄 docker-compose.yml # 容器编排
├── 📄 Dockerfile # 镜像构建
├── 📄 README.md # 项目说明
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
