教室场景学生行为识别与专注度分析系统【python源码+Pyqt5界面+数据集+训练代码】
- 2026-06-30 17:45:15
关注上方“公众号”,有福利哦!
小伙伴们好,我是阿旭。专注于人工智能、计算机视觉领域相关分享研究。【目标检测、图像分类、图像分割、目标跟踪等项目都可做,也可做不同模型对比实验;需要的可联系(备注来意)。】
《------往期经典推荐------》
一、AI应用系统实战项目
《------正文------》
基本功能演示
❝摘要:传统课堂评估依赖人工,难以精准量化“举手、阅读、写作、使用手机、低头、趴桌子”等行为,导致教学状态如同“黑盒”。本文基于
YOLO26的深度学习框架,通过6021张实际场景中教室场景学生行为相关图片,训练了一个可进行学生行为识别的检测模型,可检测6种行为状态。最终基于训练好的模型制作了一款带UI界面的教室场景学生行为识别与专注度分析系统,能够进行学生行为专注度分析,并一键生成分析报告。该系统是基于python与PyQT5开发的,支持图片、视频以及摄像头进行检测。本文提供了完整的Python代码和使用教程,给感兴趣的小伙伴参考学习,完整的代码资源文件获取方式见文末。
研究背景
传统课堂评估依赖人工,难以精准量化“举手、阅读、写作、使用手机、低头、趴桌子”等行为,导致教学状态如同“黑盒”。本系统基于YOLO框架,能实时识别六类行为并生成可视化的“专注度曲线”与“等级分布报告”。这将教育评价从“经验型”转变为“数据驱动型”,帮助教师调整教学节奏,促进家校共育,具有重要的应用价值。
应用场景
教师实时教学调整:实时分析全班行为数据,当“低头”或“趴桌子”比例过高时即时提示,辅助教师调整语速或增加互动,挽回学生注意力,提升授课效果。
教研督导与评估:自动生成专注度报告与行为统计,为听评课提供客观量化数据,替代传统填表式评价,帮助教师定位教学痛点,优化教学设计。
学生学情诊断:长期追踪个体行为轨迹,分析阅读、写作投入度及手机使用频率,辅助教师识别学习动力不足的学生,开展针对性辅导,实现因材施教。
智慧教室环境验证:作为硬件改造效果验证工具,对比改造前后“趴桌子”率与专注度数据,科学评估教学环境变化影响,为基建投入提供依据。
远程课堂监控:在双师或直播课堂中充当远端“助教”,实时监测异地学生状态,发现异常行为即刻预警,弥补远程教学缺乏现场感的短板。
主要工作内容
本文的主要内容包括以下几个方面:
搜集与整理数据集:搜集整理实际场景中教室场景学生行为的相关数据图片,并进行相应的数据处理,为模型训练提供训练数据集;训练模型:基于整理的数据集,根据最前沿的YOLO26目标检测技术训练目标检测模型,实现对需要检测的对象进行有效检测的功能;模型性能评估:对训练出的模型在验证集上进行了充分的结果评估和对比分析,主要目的是为了揭示模型在关键指标(如Precision、Recall、mAP50和mAP50-95等指标)上的表现情况。可视化系统制作:基于训练出的目标检测模型,搭配Pyqt5制作的UI界面,用python开发了一款界面简洁的软件系统,可支持图片、视频以及摄像头检测,同时可以将图片或者视频检测结果进行保存。其目的是为检测系统提供一个用户友好的操作平台,使用户能够便捷、高效地进行检测任务。
软件初始界面如下图所示: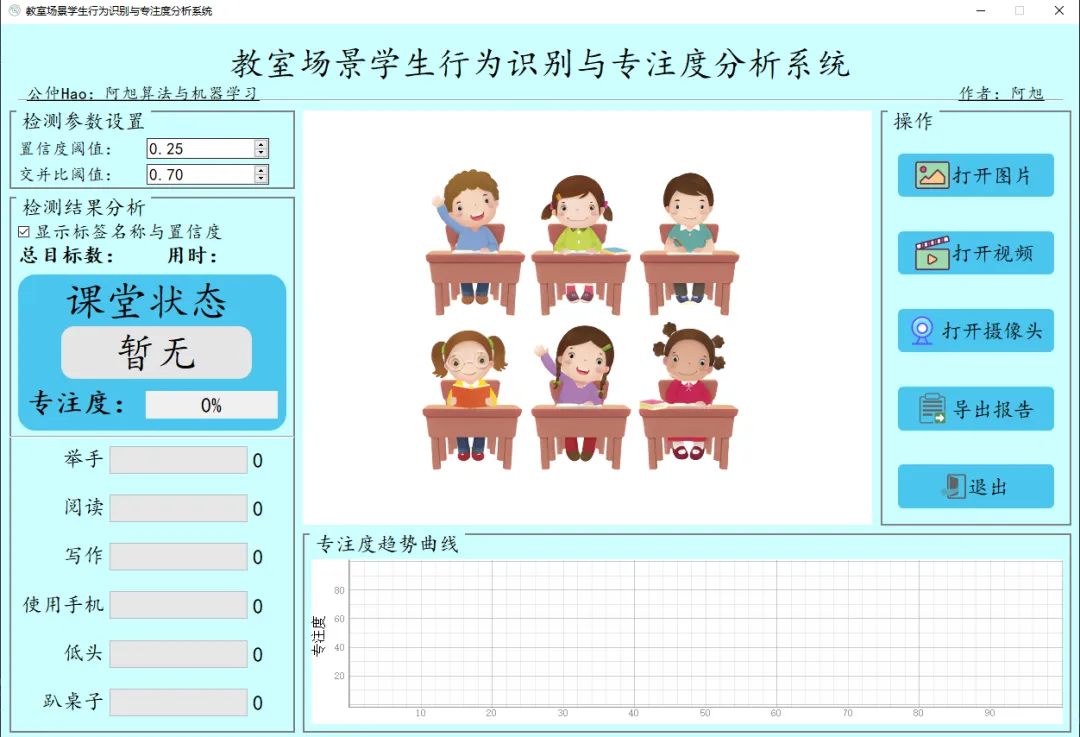
检测结果界面如下: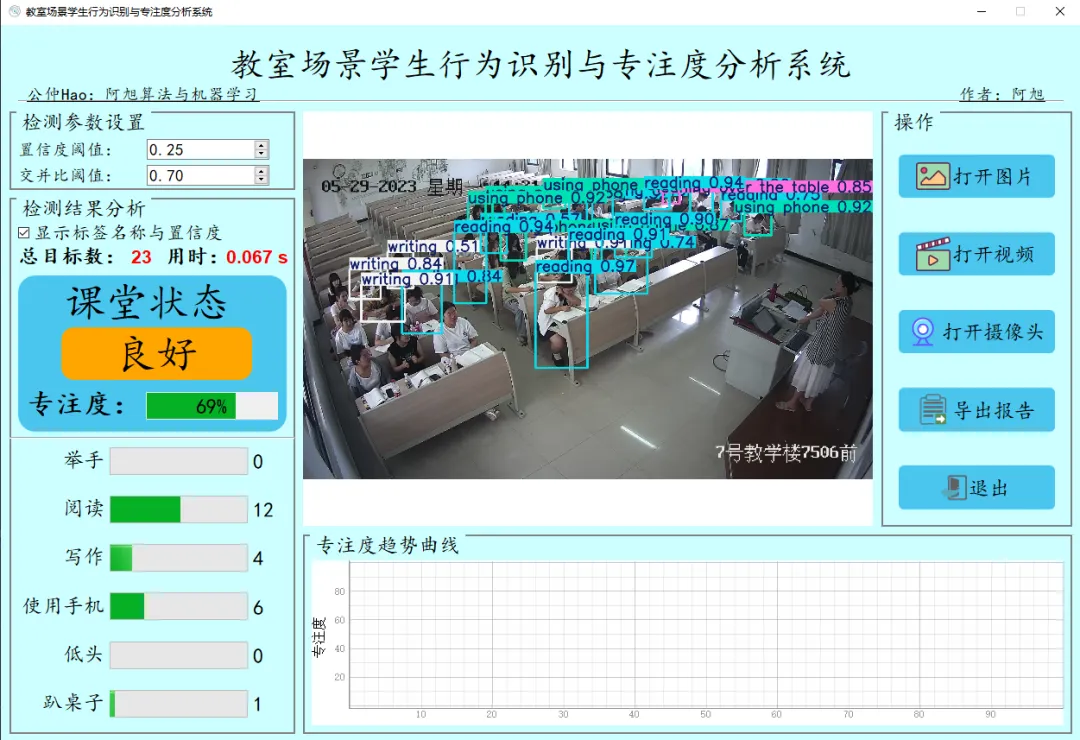
一、软件核心功能介绍及效果演示
软件主要功能
**1. 可对教室场景学生行为进行检测识别,分6个检测类别:['举手','阅读','写作','使用手机','低头','趴桌子'];
支持 图片、视频及摄像头进行检测;界面可实时显示 目标总数、用时、课堂状态、专注度等信息;可显示画面中 每个类别行为数量;支持将 视频或摄像头检测结果,一键导出分析报告;
界面参数设置说明
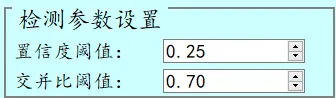 置信度阈值:也就是目标检测时的conf参数,只有检测出的目标框置信度大于该值,结果才会显示; 交并比阈值:也就是目标检测时的iou参数,对检测框重叠比例iou大于该阈值的目标框进行过滤【也就是说假如两检测框iou大于该值的话,会过滤掉其中一个,该值越小,重叠框会越少】;
置信度阈值:也就是目标检测时的conf参数,只有检测出的目标框置信度大于该值,结果才会显示; 交并比阈值:也就是目标检测时的iou参数,对检测框重叠比例iou大于该阈值的目标框进行过滤【也就是说假如两检测框iou大于该值的话,会过滤掉其中一个,该值越小,重叠框会越少】;
检测结果说明
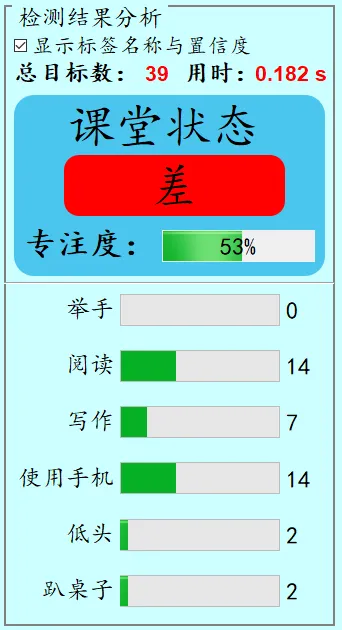
显示标签名称与置信度:表示是否在检测图片上标签名称与置信度,显示默认勾选,如果不勾选则不会在检测图片上显示标签名称与置信度;总目标数:表示画面中检测出的目标数目;柱状图对应每个类别的数量;专注度:根据当前画面中的学生各类状态数目计算得出,详细介绍见项目文档;课堂状态:根据专注度进行课堂状态等级划分,分3个等级:优秀、良好、差.
主要功能说明
功能视频演示见文章开头,以下是简要的操作描述。
(1)图片检测说明
点击打开图片按钮,选择需要检测的图片,可对单张图片进行检测;
(2)视频检测说明
点击打开视频按钮,打开选择需要检测的视频,就会自动显示检测结果,再次点击可以关闭视频。 点击导出报告按钮,会对视频检测结果进行分析,并导出一个html格式报告,存储路径为:save_data目录下。
(3)摄像头检测说明
点击打开摄像头按钮,可以打开摄像头,可以实时进行检测,再次点击,可关闭摄像头。 点击导出报告按钮,会对视频检测结果进行分析,并导出一个html格式报告,存储路径为:save_data目录下。
(4)导出报告
视频或者摄像头检测完成后,点击导出报告,会根据检测结果生成一个html格式报告,在save_data目录下。
生成报告的具体内容如下: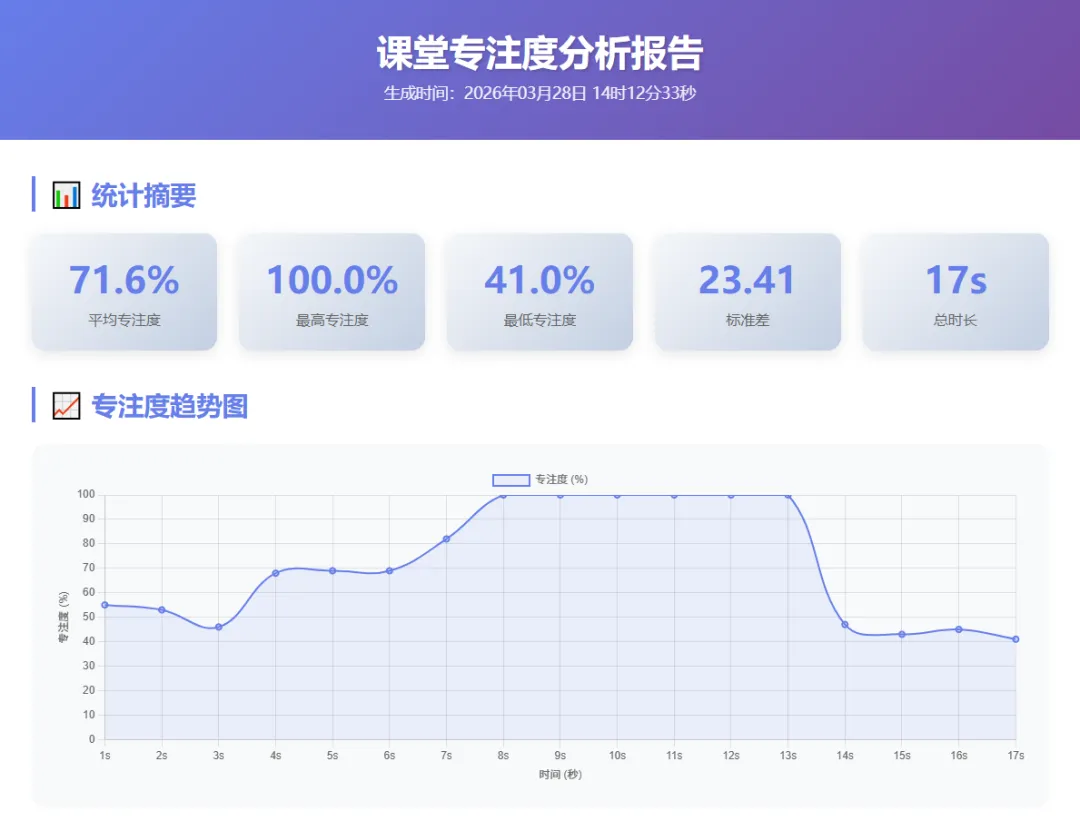
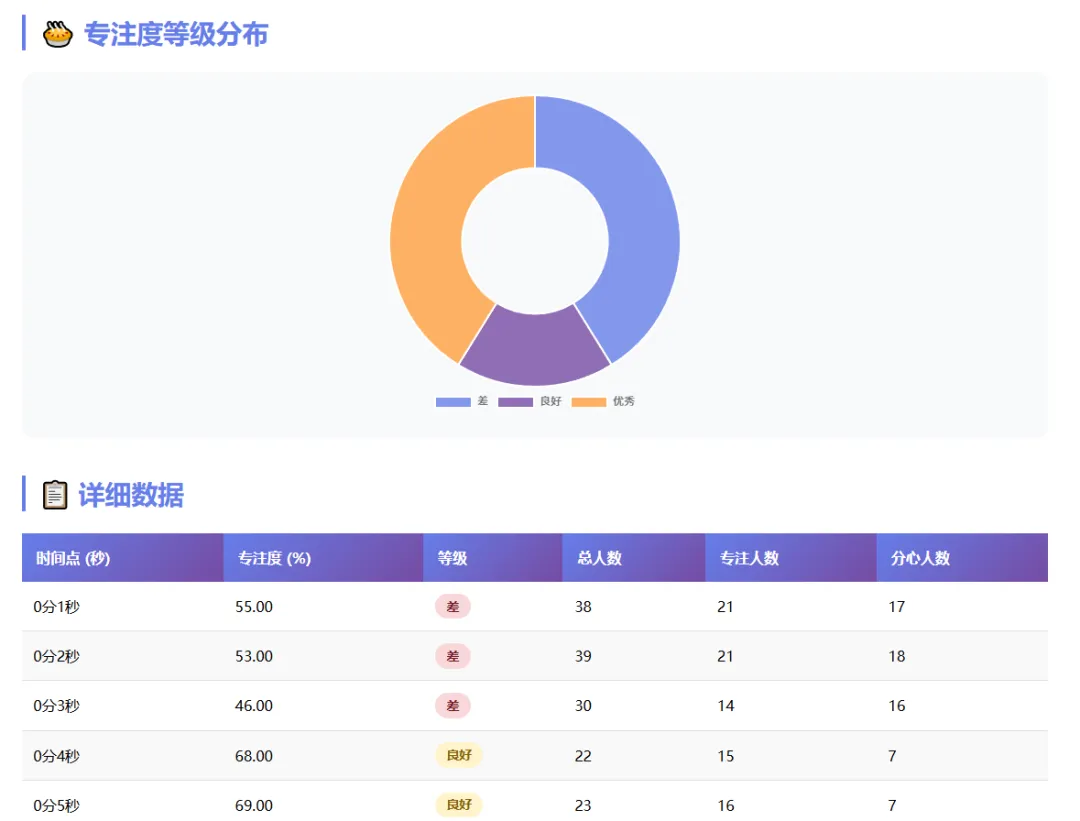
包括专注度统计,专注度曲线、专注度等级分布以及详细的结果数据。专注度曲线:表示课堂专注度随时间的变化曲线;专注度等级分布:表示检测的时间段内,每个专注度状态的百分数占比;详细数据:记录每一秒,课堂学生各行为人数,以及专注度情况。
二、模型的训练、评估与推理
1.YOLO26介绍
本项目采用的是最新的YOLO26模型。YOLO26 是 Ultralytics 2026 年 1 月推出的新一代计算机视觉模型,主打边缘优先、高效部署。它采用端到端免 NMS 架构,移除 DFL 模块,CPU 推理速度较前代提升 43%;搭配 MuSGD 优化器与 ProgLoss+STAL 损失策略,强化小目标检测能力,支持检测、分割、姿势估计等多任务,可无缝适配树莓派、嵌入式设备等终端,广泛应用于智慧农业、安防监控等领域。YOLO各版本性能对比: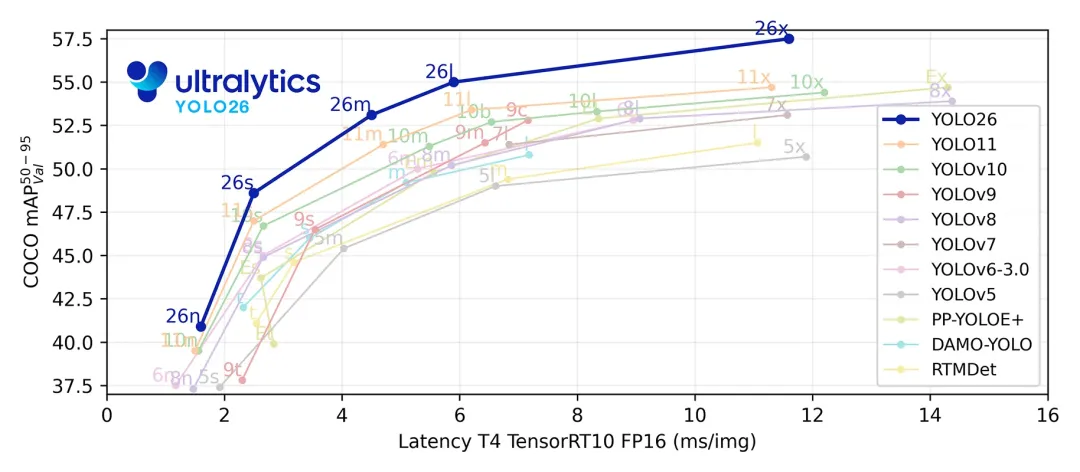
数据集准备与训练
本文主要基于YOLO26n模型进行模型训练,训练完成后对模型在验证集上的表现进行全面的性能评估及对比分析。模型训练和评估流程基本一致,包括:数据集准备、模型训练、模型评估。
1. 数据集准备与训练
搜集关于实际场景中教室场景学生行为的相关图片,然后进行相关的数据处理与划分,为模型训练提供基础数据。分6个检测类别:['举手','阅读','写作','使用手机','低头','趴桌子']。
最终数据集一共包含6021张图片,其中训练集包含4786张图片,验证集包含1235张图片。部分图像及标注如下图所示:

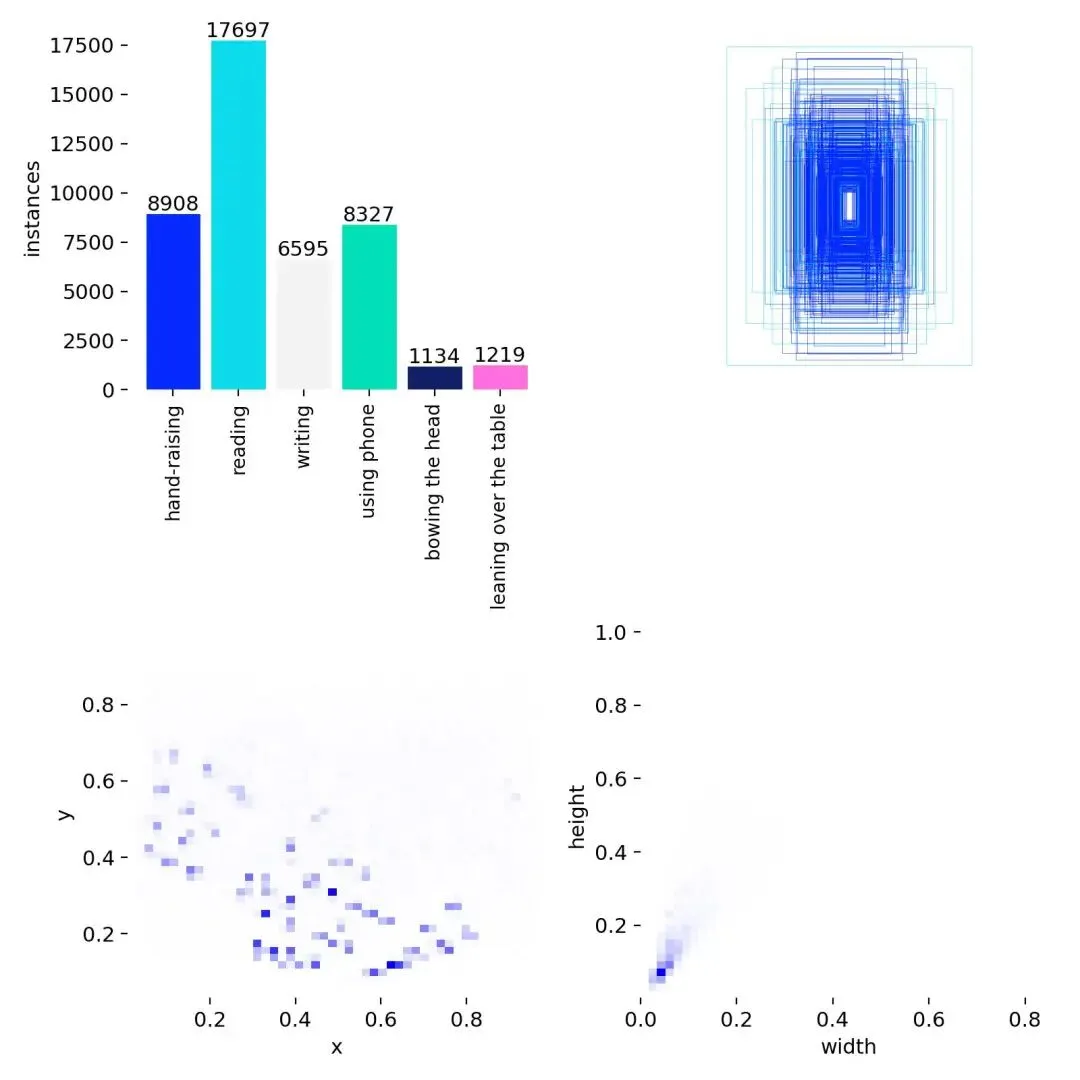
数据集各类别数目分布情况如下:
2.模型训练
准备好数据集后,将图片数据以如下格式放置在项目目录中。在项目目录中新建datasets目录,同时将检测的图片分为训练集与验证集放入Data目录下。
同时我们需要新建一个data.yaml文件,用于存储训练数据的路径及模型需要进行检测的类别。在进行模型训练时,会读取该文件的信息,用于进行模型的训练与验证。data.yaml的具体内容如下:
train: E:\MyCVProgram\ClassBehaviorDetection_v26\datasets\ClassBehavior\images\trainval: E:\MyCVProgram\ClassBehaviorDetection_v26\datasets\ClassBehavior\images\val# number of classesnc: 6# class namesnames: ['hand-raising', 'reading', 'writing', 'using phone', 'bowing the head', 'leaning over the table']注:train与val后面表示需要训练图片的路径,建议直接写自己文件的绝对路径。数据准备完成后,通过调用train.py文件进行模型训练,epochs参数用于调整训练的轮数,batch参数用于调整训练的批次大小【根据内存大小调整,最小为1】,optimizer设定的优化器为SGD,训练代码如下:
#coding:utf-8from ultralytics import YOLOimport matplotlibmatplotlib.use('TkAgg')# 模型配置文件model_yaml_path = "ultralytics/cfg/models/26/yolo26.yaml"#数据集配置文件data_yaml_path = r'datasets/data.yaml'#预训练模型pre_model_name = 'yolo26n.pt'if __name__ == '__main__':#加载预训练模型 model = YOLO(model_yaml_path).load(pre_model_name)#训练模型 results = model.train(data=data_yaml_path, epochs=150, batch=32, name='train_26')模型常用训练超参数参数说明:YOLO26模型的训练设置包括训练过程中使用的各种超参数和配置。这些设置会影响模型的性能、速度和准确性。关键的训练设置包括批量大小、学习率、动量和权重衰减。此外,优化器、损失函数和训练数据集组成的选择也会影响训练过程。对这些设置进行仔细的调整和实验对于优化性能至关重要。以下是一些常用的模型训练参数和说明:
3. 训练结果评估
在深度学习中,我们通常用损失函数下降的曲线来观察模型训练的情况。YOLO在训练时主要包含三个方面的损失:定位损失(box_loss)、分类损失(cls_loss)和动态特征损失(dfl_loss),在训练结束后,可以在runs/目录下找到训练过程及结果文件,如下所示:
各损失函数作用说明:定位损失box_loss:预测框与标定框之间的误差(GIoU),越小定位得越准;分类损失cls_loss:计算锚框与对应的标定分类是否正确,越小分类得越准;动态特征损失(dfl_loss):DFLLoss是一种用于回归预测框与目标框之间距离的损失函数。在计算损失时,目标框需要缩放到特征图尺度,即除以相应的stride,并与预测的边界框计算Ciou Loss,同时与预测的anchors中心点到各边的距离计算回归DFLLoss。本文训练结果如下: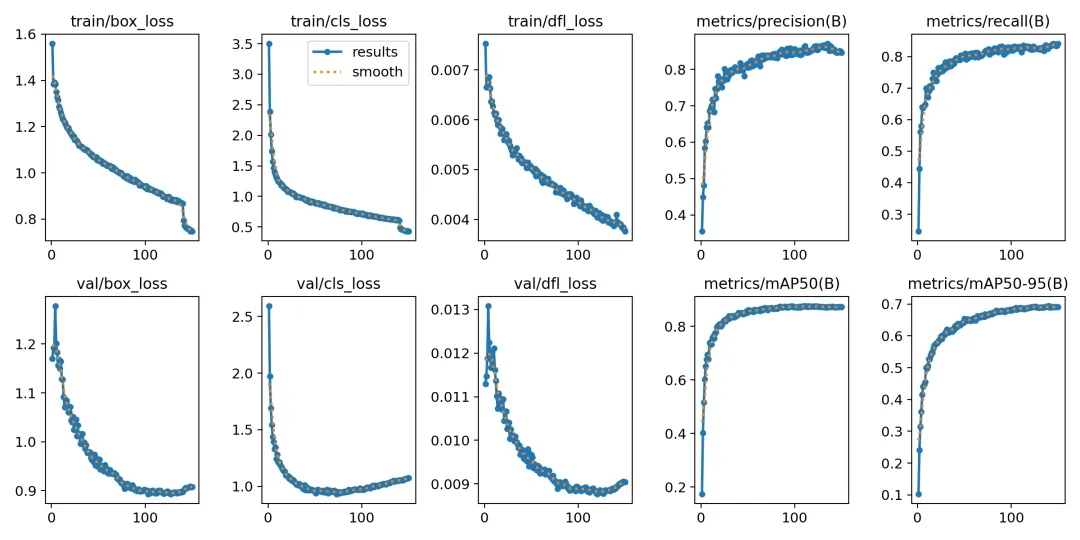 混淆矩阵图如下:
混淆矩阵图如下: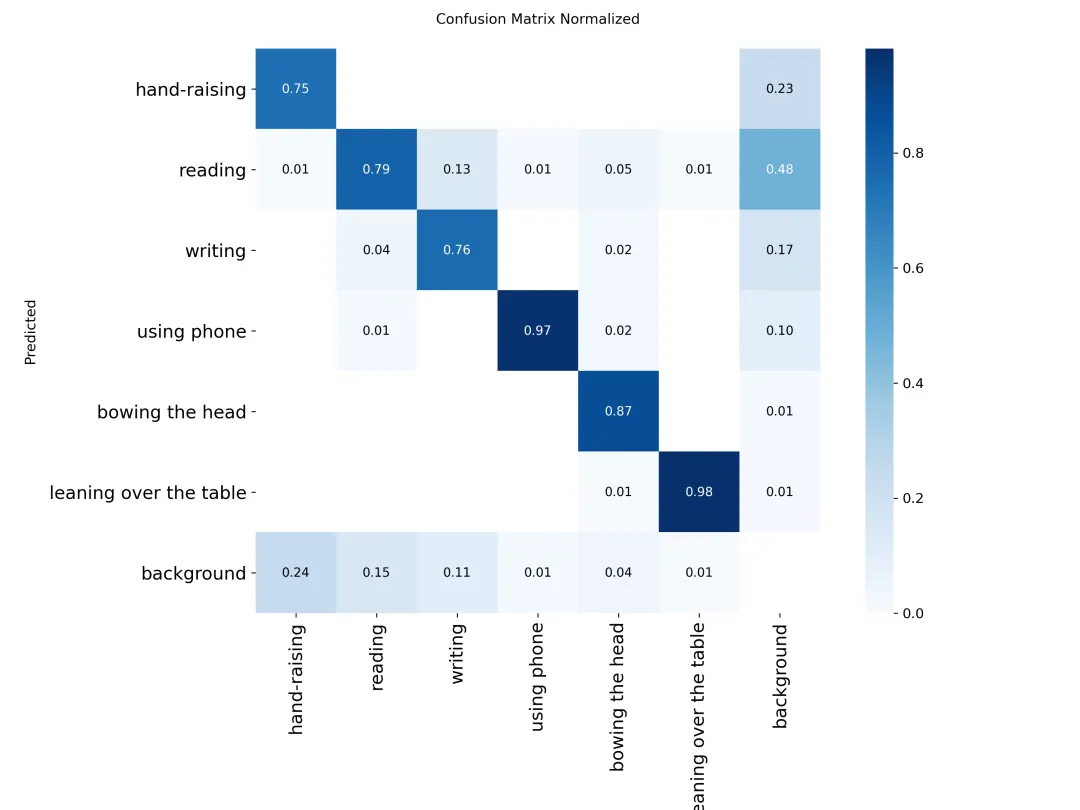
我们通常用PR曲线来体现精确率和召回率的关系,本文训练结果的PR曲线如下。mAP表示Precision和Recall作为两轴作图后围成的面积,m表示平均,@后面的数表示判定iou为正负样本的阈值。mAP@.5:表示阈值大于0.5的平均mAP,可以看到本文模型目标检测的mAP@0.5值为0.874,结果还是十分不错的。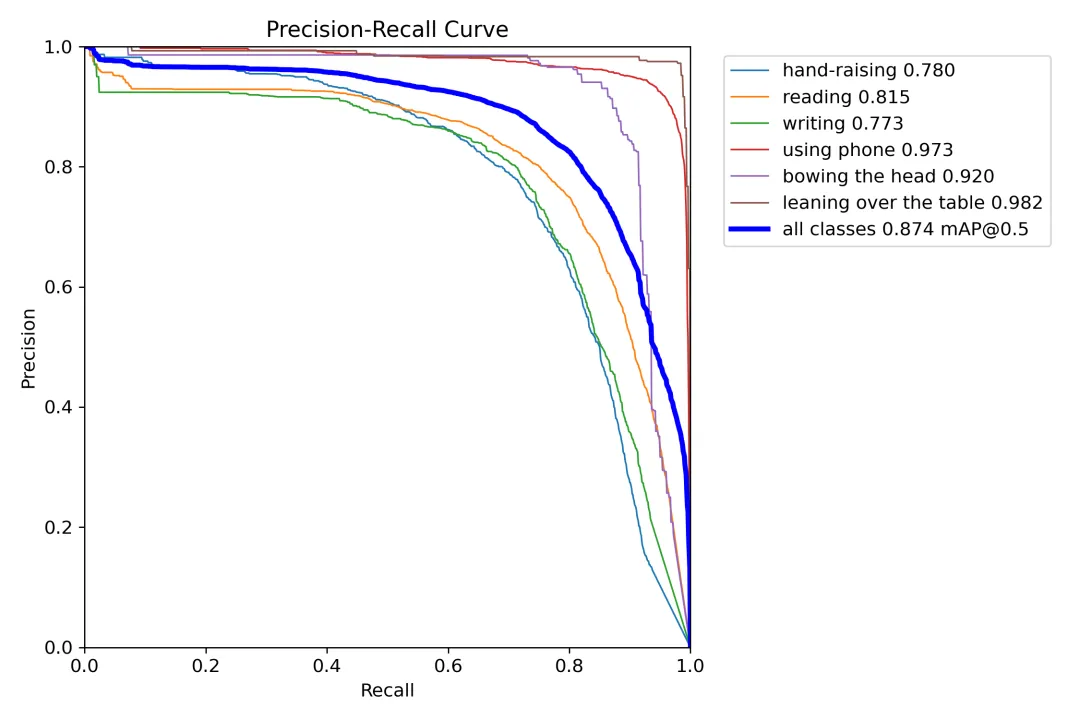
4. 使用模型进行推理
模型训练完成后,我们可以得到一个最佳的训练结果模型best.pt文件,在runs/train/weights目录下。我们可以使用该文件进行后续的推理检测。 图片检测代码如下:
#coding:utf-8from ultralytics import YOLOimport cv2# 所需加载的模型目录path = 'models/best.pt'# 需要检测的图片地址img_path = "TestFiles/40030249.jpg"# 加载预训练模型model = YOLO(path, task='detect')# 检测图片results = model(img_path)print(results)res = results[0].plot()res = cv2.resize(res,dsize=None,fx=0.5,fy=0.5,interpolation=cv2.INTER_LINEAR)cv2.imshow("Detection Res", res)cv2.waitKey(0)执行上述代码后,会将执行的结果直接标注在图片上,结果如下:
更多检测结果示例如下:
四、可视化系统制作
基于上述训练出的目标检测模型,为了给此检测系统提供一个用户友好的操作平台,使用户能够便捷、高效地进行检测任务。博主基于Pyqt5开发了一个可视化的系统界面,通过图形用户界面(GUI),用户可以轻松地在图片、视频和摄像头实时检测之间切换,无需掌握复杂的编程技能即可操作系统。【系统详细展示见第一部分内容】
Pyqt5详细介绍
关于Pyqt5的详细介绍可以参考之前的博客文章:《Python中的Pyqt5详细介绍:基本机构、部件、布局管理、信号与槽、跨平台》,地址:
❝https://a-xu-ai.blog.csdn.net/article/details/143273797
系统制作
博主基于Pyqt5框架开发了此款教室场景学生行为识别与专注度分析系统,即文中第一部分的演示内容,能够很好的支持图片、视频及摄像头进行检测。
通过图形用户界面(GUI),用户可以轻松地在图片、视频和摄像头实时检测之间切换,无需掌握复杂的编程技能即可操作系统。这不仅提升了系统的可用性和用户体验,还使得检测过程更加直观透明,便于结果的实时观察和分析。此外,GUI还可以集成其他功能,如检测结果的保存与导出、检测参数的调整,从而为用户提供一个全面、综合的检测工作环境,促进智能检测技术的广泛应用。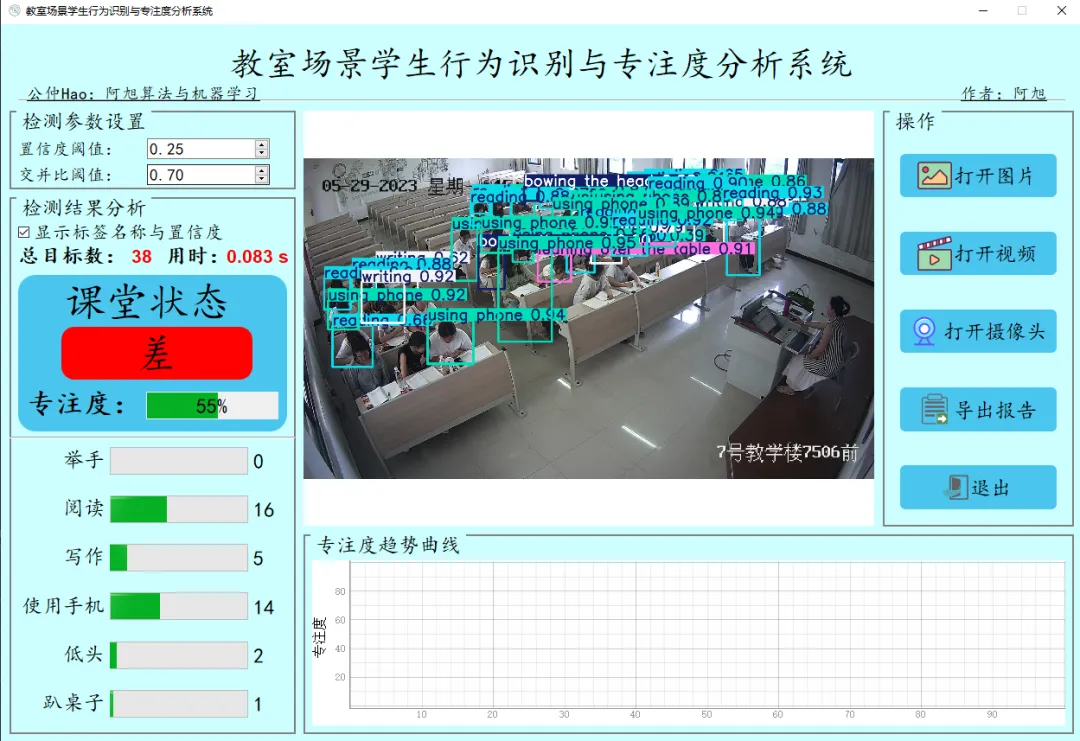
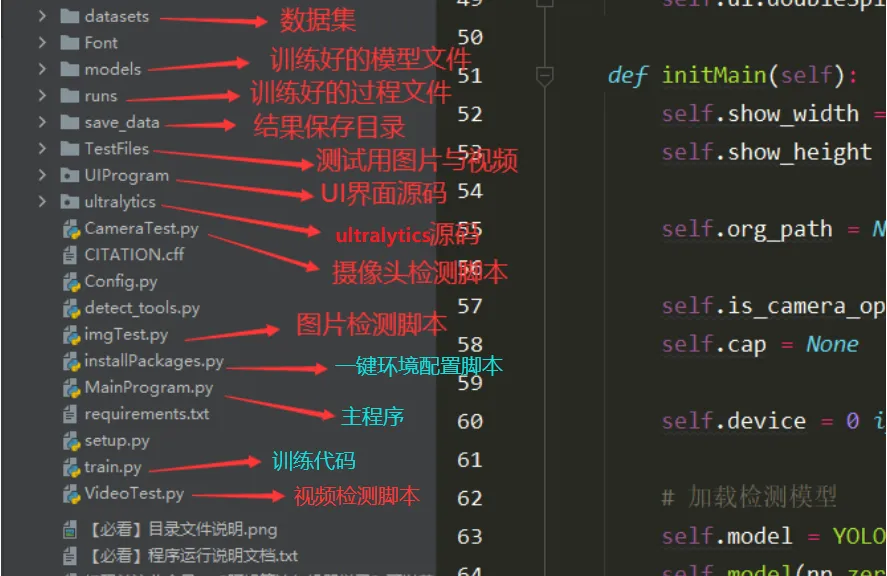
关于该系统涉及到的完整源码、UI界面代码、数据集、训练代码、训练好的模型、测试图片视频等相关文件,均已打包上传,感兴趣的小伙伴可以通过下载链接自行获取。
【获取方式】
关注下方公众号【阿旭算法与机器学习】,号内发送【源码】获取下载方式
❝本文涉及到的完整全部程序文件:包括python源码、数据集、训练好的结果文件、训练代码、UI源码、测试图片视频等(见下图),获取方式见文末:
end
福利!!!本公众号为粉丝精心整理了超级全面的python学习、算法、大数据、人工智能等重磅干货资源,关注公众号即可免费领取!无套路!
看到这里,如果你喜欢这篇文章的话,
点击下方【在看】【转发】就是对我最大支持!
如果觉得有用就点个“赞”呗
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- AI学习-- Python中的广播
- 用Python轻松搞定物流报价:一键选出最优渠道,省时又省钱!
- Python其实很水,五天背完就了!
- 基于YOLO11的食材检测系统(Python源码+数据集+Pyside6界面)
- 一套图看懂Python Web开发
- Python 最快的工具被 OpenAI 收了:Ruff + uv 的下一步是什么?
- 9个Python自动化神器:让我感觉自己像个黑客!
- Python中组合数据类型常用“字符串提取和分割与合并”
- 无人机飞手正在被内卷,懂Python数据处理的飞手才是未来的香饽饽
- 12、VM虚拟机安装CentOS Linux系统(安装包内附安装教程)
