项目配置
以往需要搭配setup.py,requirements.txt,pytest.ini,mypy.ini 等多个配置文件。而现在,一切皆可纳入 pyproject.toml。这不仅减少了文件数量,还让工具链配置更加透明。此外,Python官方标准 PEP 621 也推荐使用pyproject.toml作为依赖管理。以下为analysis_service项目的配置。
[project]name = "analysis-service"version = "0.1.0"description = "一个可持续的数据分析项目"requires-python = ">=3.14" dependencies = [ "pandas>=2.0.0", "numpy>=2.4.3", "fastapi>=0.135.2", "uvicorn>=0.42.0", "loguru>=0.7.0", "psutil>=7.2.2", "pydantic>=2.12.5"][build-system]requires = ["hatchling"]build-backend = "hatchling.build"[tool.hatch.build.targets.wheel]packages = ["src/analysis_service"][tool.hatch.build]sources = ["src"]
# 运行扁平结构项目uv run main.py# 运行FastAPI - src结构项目uv run -m uvicorn analysis_service.main:app --reload --host 0.0.0.0 --port 8000
其他uv特性可以参考[中文官网](https://uv.doczh.com)
❞
Python项目在多环境部署时,解释器与依赖包的版本正确性尤为重要。uv.lock 确保了在不同环境下,依赖版本的一致性,同时,在删除部分依赖包后,uv 也会快速解析依赖树,按依赖关系剔除不必要的包。相比之下,传统 requirements.txt 缺乏依赖的严格锁定,容易导致依赖臃肿、版本飘逸、依赖冲突等问题。当然,部分机器学习与神经网络工程涉及底层驱动 (例如 NVIDIA CUDA 或其他 C/C++ Lib等),conda 依旧是目前较优选择。
工具对比
| | |
|---|
| 开发语言 | | |
| 检查速度 | | |
| 严格程度 | | |
| IDE 集成 | | VS Code 原生支持,PyCharm 插件支持 |
| 配置灵活性 | mypy.ini | pyrightconfig.json |
| 错误提示 | | |
| 社区趋势 | | |
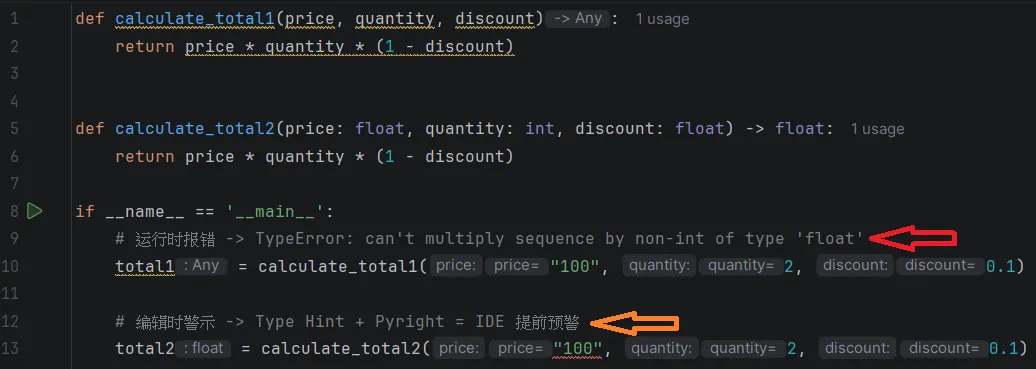
为什么选择 Pyright? 虽然 mypy 是行业的先行者,但 Pyright 在处理复杂类型推断(如泛型、协议 Protocol)时表现更为精准。特别是在数据科学中,我们经常使用 numpy.ndarray 或 pandas.DataFrame,Pyright 对这些库的类型存根(stub files)支持更好,能更早发现维度不匹配或属性错误。
PyCharm 集成
为了最大化利用类型提示,我们需要配置 PyCharm 和外部工具链:
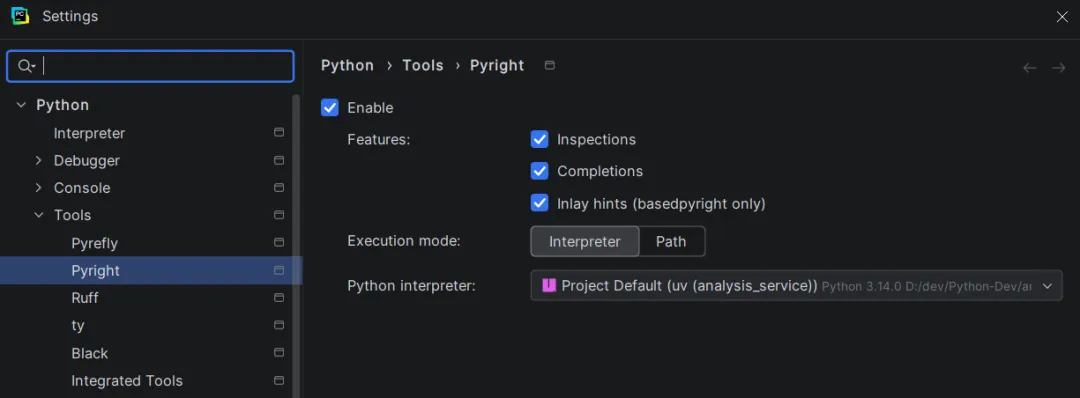
- 在 Settings -> Python-> Tools -> Pyright Enable。
- Settings -> Tools -> Actions on Save:勾选 "Run ruff" 或 "Optimize imports"。
- 配置
File Watchers,在文件保存时自动运行 pyright 进行局部检查。
严格模式:在 pyproject.toml 中设置 typeCheckingMode = "strict",这将强制你为所有函数参数和返回值添加类型注解,极大减少运行时错误。
4. 可观测性
在大型应用中,合适的日志库对项目维护和问题排查起到决定性作用。很多初学者习惯使用 print(),但这类Console打印模式在生产环境中是极其糟糕的。必须使用结构化、可分级、可持久化输出的日志功能。
对比分析
| logging | loguru |
|---|
| 配置复杂度 | | |
| 文件轮转/压缩 | | 内置 rotation, retention, compression |
| 性能 | | |
| 异常捕获 | | 装饰器 + 完整堆栈跟踪 @logger.catch |
| 学习曲线 | | |
| 依赖项 | | |
| 推荐场景 | | |
配置结构化日志
我们可以在系统核心逻辑启动前统一完成 loguru全局设置,以便于后续多个 Python 代码里统一日志。此外,可基于上下文增加额外属性如request_id信息到日志中,以便于追踪整个调用链路。
import sysfrom loguru import loggerfrom pathlib import Pathfrom analysis_service.core.config import settingsfrom analysis_service.utils.trace import TraceTooldefrequest_id_filter(record):"""从上下文获取 requestId 并添加到日志记录中""" request_id = TraceTool.get_request_id()if request_id is None:return False record["extra"]["request_id"] = request_idreturn Truedefsetup_logging(): logger.remove()# 自定义Formatter 为打印上下文RequestID信息,否则可使用默认 formatter : str = ("<green>{time:YYYY-MM-DD HH:mm:ss}</green> | ""<level>{level: <8}</level> |""{extra[request_id]}| ""<cyan>{name}</cyan>:<cyan>{function}</cyan>:<cyan>{line}</cyan> : <level>{message}</level>")# 控制台输出 logger.add(sys.stdout, format=formatter, level=settings.LOG_LEVEL, filter=request_id_filter)# 文件输出 Path(settings.LOG_DIR).mkdir(parents=True, exist_ok=True) logger.add(f"{settings.LOG_DIR}/app_{{time:YYYY-MM-DD}}.log", rotation="00:00", retention="14 days", level="DEBUG", encoding="utf-8", enqueue=True, filter=request_id_filter)
上下文request_id生成示例。如使用 FastAPI 框架,可继承starlette.middleware.base.BaseHTTPMiddleware重写dispatch()方法,从HTTP Request Header中提取或主动生成并追加。
from contextvars import ContextVarfrom datetime import datetime, timezoneimport uuidRequestIdKey = "request_id"# 定义上下文变量 (每个异步任务独立)request_id_var: ContextVar[str | None] = ContextVar(RequestIdKey, default=None)_formatter: str = '%Y%m%d'classTraceTool: @staticmethoddefgenerate(utc: datetime | None) -> str:if utc is None: utc = datetime.now(timezone.utc) dt_prefix = utc.strftime(_formatter)return dt_prefix + str(uuid.uuid4()).replace("-", "")[len(dt_prefix):] @staticmethoddefget_request_id() -> str | None:return request_id_var.get() @staticmethoddefset_request_id(request_id: str) -> None: request_id_var.set(request_id) # 注意清理,避免泄露 @staticmethoddefclean() -> None: request_id_var.set(None)
日志呈现:
2026-03-28 23:38:37 | INFO |20260328f40d4b56b872497d76e9d4c2| analysis_service.core.tracing:dispatch:22 : Request started: GET /api/v1/system/status2026-03-28 23:38:38 | INFO |20260328f40d4b56b872497d76e9d4c2| analysis_service.services.system_status:get_system_status:54 : System status collected: CPU 12.5%, Mem 84.5%2026-03-28 23:38:38 | INFO |20260328f40d4b56b872497d76e9d4c2| api.v1.system:get_status:18 : API request: /system/status | response: {"success":true,"code":0,"message":"success","data":{...}}}2026-03-28 23:38:38 | INFO |20260328f40d4b56b872497d76e9d4c2| analysis_service.core.tracing:dispatch:31 : GET Request [/api/v1/system/status] - 0.510s
5. 配置管理
在构建 Python 项目时,安全性与配置管理是最容易被忽视的一环。许多开发者为了方便,将 APIKey, AccessKey 等敏感信息直接硬编码在源代码中。这无异于将家门钥匙藏在门口地垫下,一旦代码被提交到公共仓库,敏感信息将彻底暴露,造成严重的安全事故。
方式对比
推荐模式
使用 pydantic-settings,结合 pydantic 的类型验证能力和环境变量加载功能。相比传统的 python-dotenv,它能确保在应用启动时即刻发现配置缺失或类型错误的字段,极大提升开发与排查效率。
使用 uv 添加配置管理依赖:
uv add pydantic-settings
定义一个配置类,不仅统一配置读取入口,还提供IDE自动补全和类型检查。
import osfrom pathlib import Pathfrom pydantic import Field, SecretStr, model_validatorfrom pydantic_settings import BaseSettings, SettingsConfigDict# 合理配置!BASE_DIR = Path(__file__).resolve().parent.parent.parent.parentclassAppSettings(BaseSettings): model_config = SettingsConfigDict( env_file = BASE_DIR / ".env", env_file_encoding = "utf-8", case_sensitive = False, # 环境变量不区分大小写以增强容错! ) APP_NAME: str = Field(default="App", description="应用名称") ENV: str = Field(default="dev", description="运行环境") LOG_LEVEL: str = Field(default="INFO", description="日志级别") LOG_DIR: str = Field(default="./log", description="日志根目录") ACCESS_KEY_NAME: str = Field(..., description="访问密钥 ID") ACCESS_KEY_SECRET: SecretStr = Field(..., description="访问密钥密文") THREADPOOL_SIZE: int = Field(default=4, ge=2, le=64, description="线程池大小 (1-64)") @model_validator(mode="after")defcheck_env_consistency(self):if self.ENV not in ["dev", "prod"]:raise ValueError("Env must be 'dev' or 'prod'")if self.ENV == "prod" and self.LOG_LEVEL == "DEBUG":raise ValueError("生产环境禁止开启 DEBUG 日志级别")return selfdefget_secret_value(self) -> str:return self.ACCESS_KEY_SECRET.get_secret_value()defget_settings(env: str | None = None) -> AppSettings:if env is None: env = os.getenv("ENV", "dev") env_file = BASE_DIR / f".env.{env}"ifnot os.path.exists(env_file): print(f"Warning: {env_file} not found, trying .env.prod (if exists)") env_file = ".env.prod"return AppSettings(_env_file=env_file) settings = get_settings() # Singleton
https://docs.pydantic.dev/latest
在项目根目录创建对应不同环境的 .env 文件用于开发和部署。同时创建 .env.example 作为模板提交到仓库,告知其他开发者需要哪些配置。
.env (本地文件):
APP_NAME=Analysis-ServiceENV=prodLOG_LEVEL=INFOLOG_DIR=./logsACCESS_KEY_NAME=prod_key_001ACCESS_KEY_SECRET=prod_secret_123456THREADPOOL_SIZE=8
.env.example (提交到 Git 的模板):
APP_NAME=ExampleAppENV=envLOG_LEVEL=INFOLOG_DIR=./logsACCESS_KEY_NAME=xxxxACCESS_KEY_SECRET=xxxxTHREADPOOL_SIZE=4
确保敏感文件不会被意外提交。在使用 uv init 生成的 .gitignore 基础上,追加以下内容:
# .gitignore# 环境变量文件.env.env.dev# 敏感密钥文件*.keycredentials.json# 日志文件logs/*.log
总结
上述这些看似微不足道,实际在支撑着项目可持续迭代的细节往往最容易被忽视。AI 大模型可以实现大部分代码,但不能决定系统设计的可持续性,约束性和安全底线。AI 越强大,作为研发工程师需要掌握的设计模式,基础架构思维也要更牢靠,否则不仅无法评审AI实现的合理性,也会逐步放弃对完整系统的控制权,最终沦为AI的搬运工。
本文为Python实战系列的开篇,后续将持续带来数据与特征分析,MCP与Agent搭建,量化模型训练与评估等内容,「敬请期待」。