用Python解析HTML页面
在前面的课程中,我们讲解了使用requests第三方库获取网络资源,还介绍了一些前端基础知识。接下来,我们继续探索如何解析HTML代码,从页面中提取有用信息。此前,我们尝试过用正则表达式的捕获组操作提取页面内容,但编写一个正确的正则表达式,对开发者来说是一件令人头疼的事情。为解决这一问题,我们需要先深入了解HTML页面的结构,再在此基础上学习其他更便捷的页面解析方法。
HTML 页面的结构
我们在浏览器中打开任意一个网站,通过鼠标右键菜单选择“显示网页源代码”,即可查看该网页对应的HTML代码。
代码第1行是文档类型声明,第2行的<html>标签是整个页面根标签的开始标签,最后一行</html>是根标签的结束标签。<html>标签下包含两个子标签<head>和<body>:放在<body>标签下的内容会显示在浏览器窗口中,是网页的主体部分;放在<head>标签下的内容不会显示在浏览器窗口中,却包含页面的重要元信息,通常称为网页的头部。HTML页面的大致代码结构如下所示。
<!doctype html><html><head><!-- 页面的元信息,如字符编码、标题、关键字、媒体查询等 --></head><body><!-- 页面的主体,显示在浏览器窗口中的内容 --></body></html>
标签、层叠样式表(CSS)、JavaScript是构成HTML页面的三要素:标签用于承载页面要显示的内容,CSS负责页面的样式渲染,JavaScript则控制页面的交互式行为。要实现HTML页面解析,有两种常用方法:一是使用XPath语法,它原本是XML的查询语法,可根据HTML标签的层次结构,提取标签内容或标签属性;二是使用CSS选择器定位页面元素,原理与CSS渲染页面元素完全一致。
XPath 解析
XPath是用于在XML(可扩展标记语言,eXtensible Markup Language)文档中查找信息的语法。XML与HTML类似,均是用标签承载数据的标记语言,不同之处在于XML的标签可扩展、可自定义,且语法要求更严格。XPath使用路径表达式选取XML文档中的节点或节点集,这里的节点包括元素、属性、文本、命名空间、处理指令、注释、根节点等。下面我们通过一个示例,说明如何使用XPath解析页面。
<?xml version="1.0" encoding="UTF-8"?><bookstore><book><titlelang="eng">Harry Potter</title><price>29.99</price></book><book><titlelang="zh">Learning XML</title><price>39.95</price></book></bookstore>
对于上述XML文件,我们可以使用如下XPath路径表达式获取文档中的节点。
| |
/bookstore | 选取根元素 bookstore。注意:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
//book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
//@lang | |
/bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
/bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
/bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
/bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
//title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
//title[@lang='eng'] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
/bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
/bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
XPath还支持通配符用法,具体如下所示。
| |
/bookstore/* | |
//* | |
//title[@*] | |
如果需要选取多个节点,可使用如下方法。
| |
//book/title, //book/price | 选取 book 元素的所有 title 和 price 元素。 |
//title , //price | 选取文档中的所有 title 和 price 元素。 |
/bookstore/book/title , //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
说明:上面的例子来自于“菜鸟教程”网站上的 XPath 教程,有兴趣的读者可以自行阅读原文。
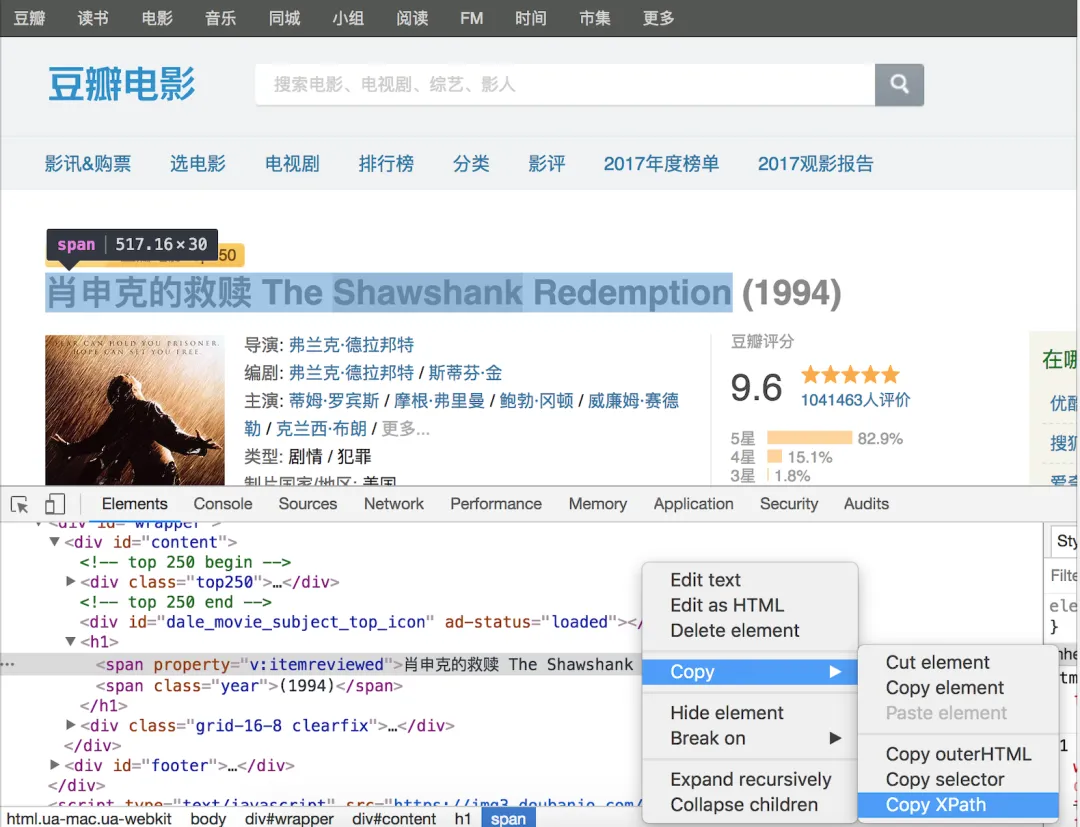
如果不理解或不熟悉XPath语法,可在浏览器开发者工具中直接查看元素的XPath语法。下图是在Chrome浏览器开发者工具中,查看豆瓣电影详情页中影片标题的XPath语法示例。
实现XPath解析需要第三方库lxml的支持,可使用以下命令安装lxml。
pip install lxml
下面我们用XPath解析方式,改写之前获取豆瓣电影Top250的代码,具体如下所示。
from lxml import etreeimport requestsfor page inrange(1, 11): resp = requests.get( url=f'https://movie.douban.com/top250?start={(page - 1) * 25}', headers={'User-Agent': 'BaiduSpider'} ) tree = etree.HTML(resp.text)# 通过XPath语法从页面中提取电影标题 title_spans = tree.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]')# 通过XPath语法从页面中提取电影评分 rank_spans = tree.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[2]/div/span[2]')for title_span, rank_span inzip(title_spans, rank_spans):print(title_span.text, rank_span.text)
CSS 选择器解析
对于熟悉CSS选择器和JavaScript的开发者来说,通过CSS选择器获取页面元素会更为简单——浏览器中运行的JavaScript,本身就可以通过document对象的querySelector()和querySelectorAll()方法,基于CSS选择器获取页面元素。在Python中,我们可以借助第三方库beautifulsoup4(简称bs4)或pyquery实现同样的功能。
Beautiful Soup可用于解析HTML和XML文档,能自动修复未闭合标签等语法错误,它通过在内存中为待解析页面创建树结构,封装了数据提取的相关操作,上手便捷。可使用以下命令安装Beautiful Soup。
pip install beautifulsoup4
下面是使用bs4改写的、获取豆瓣电影Top250电影名称和评分的代码。
import bs4import requestsfor page inrange(1, 11): resp = requests.get( url=f'https://movie.douban.com/top250?start={(page - 1) * 25}', headers={'User-Agent': 'BaiduSpider'} )# 创建BeautifulSoup对象,指定解析器为lxml soup = bs4.BeautifulSoup(resp.text, 'lxml')# 通过CSS选择器从页面中提取包含电影标题的span标签 title_spans = soup.select('div.info > div.hd > a > span:nth-child(1)')# 通过CSS选择器从页面中提取包含电影评分的span标签 rank_spans = soup.select('div.info > div.bd > div > span.rating_num')for title_span, rank_span inzip(title_spans, rank_spans):print(title_span.text, rank_span.text)
关于BeautifulSoup的更多用法,可参考它的官方文档。
总结
下面我们对三种HTML页面解析方式做简单对比,方便大家根据需求选择合适的方法。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
