当前位置:首页>python>Python+LangChain/LangGraph框架开发Ai智能体系列��17节 | RAG 进阶 | LangChain RetrievalQA + 自定义 Retriever + 过滤策略
Python+LangChain/LangGraph框架开发Ai智能体系列��17节 | RAG 进阶 | LangChain RetrievalQA + 自定义 Retriever + 过滤策略
- 2026-07-04 18:38:38
Python+LangChain/LangGraph框架开发Ai智能体系列��17节 | RAG 进阶 | LangChain RetrievalQA + 自定义 Retriever + 过滤策略
环境:win11+python3.11+vscode编辑器 代码层级图: 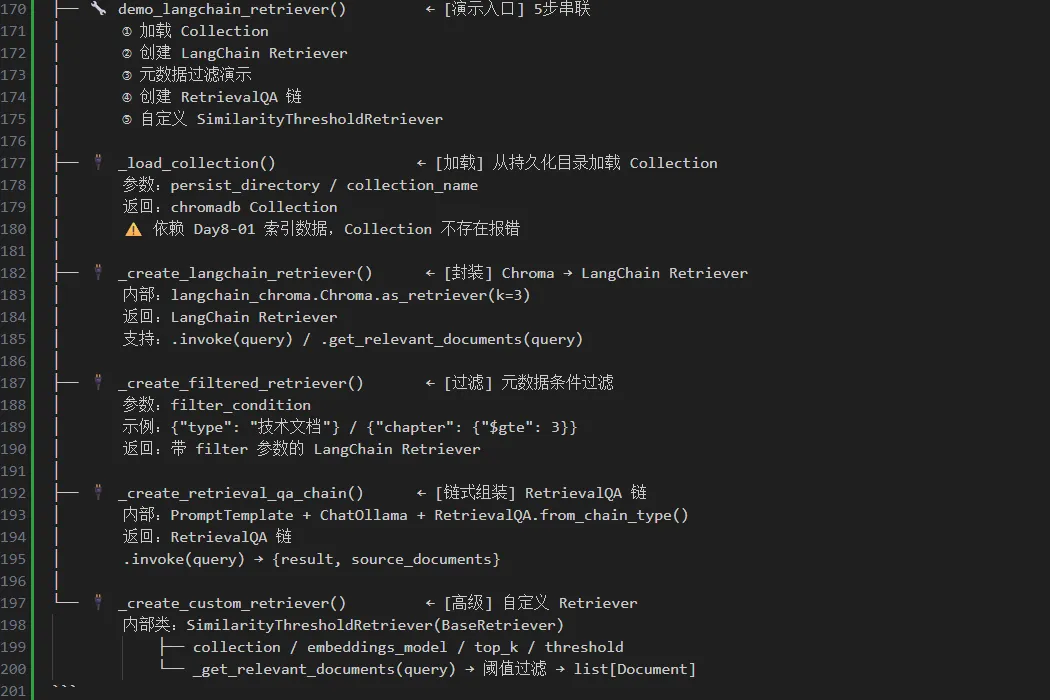
3.1步骤 1:加载已存在的 Chroma Collection(原生 API) 4.代码运行: 4.2 运行结果: 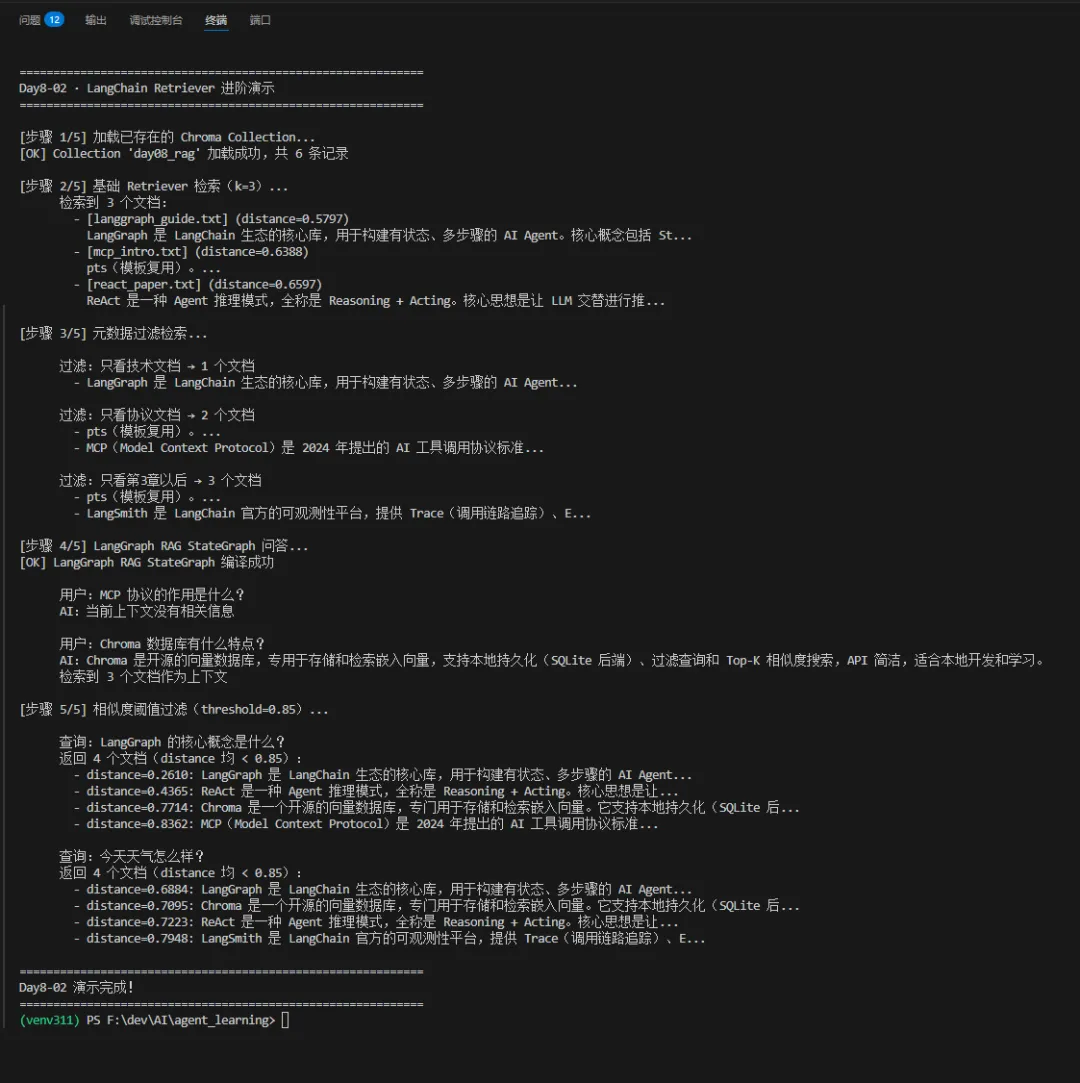
热点文章推荐: 🦞10分钟极速搭建OpenClaw龙虾智能体服务(Windows11版)“炒鸡详细” Python+langchain框架开发Ai智能体系列(一)
1. 学习目标
1. 掌握 LangChain 的 RetrievalQA 链(简化 RAG 实现)
2. 掌握自定义 Retriever 的写法(支持过滤、元数据筛选)
3. 理解 BM25 混合检索概念(为 Day9 做铺垫)
4. 掌握 Chroma 的过滤查询(metadata filtering)
2.核心概念速览
全链路图:
### 核心特点
前置条件:
chroma_db 目录已存在
Collection 已建索引
ollama pull nomic-embed-text (本地ollama已下载nomic-embed-text向量模型)
执行顺序:** ①(加载)→ ②(封装)→ ③(可选过滤)→ ④或⑤(Retriever)→ 最终接口调用:
3.代码实现
提醒:源代码请关注“极简工具盒”公众号,在文章末尾扫二维码加入技术交流群获取!
def _load_collection(persist_directory: str, collection_name: str = "day08_rag"):"""从持久化目录加载已有的 Chroma Collection。这里只用原生 chromadb API,不走 langchain_chroma.Chroma,避免 chromadb 1.5.7 + langchain-chroma 1.1.0 版本兼容问题。参数:persist_directory:Chroma 数据库目录(Day8-01 创建的)collection_name:Collection 名称返回:chromadb.Collection 对象(含 .query() 方法)"""import chromadbclient = chromadb.PersistentClient(path=persist_directory)collection = client.get_collection(name=collection_name)print(f"[OK] Collection '{collection_name}' 加载成功,共 {collection.count()} 条记录")return collection
3.2步骤 2:自定义 LangChain Retriever(Pydantic v2 规范)
def _build_chroma_retriever(collection, embeddings_model: str = "nomic-embed-text", top_k: int = 3):"""将原生 chromadb.Collection 封装为 LangChain Retriever。Pydantic v2 规范(踩坑总结):1. 类级别必须声明所有字段(collection: object,top_k: int = 3)2. super().__init__() 必须传入所有声明的字段3. 可选字段用 dict | None = None,禁止 dict = None参数:collection:原生 chromadb.Collection(Day8-01 写入的数据)embeddings_model:Ollama 嵌入模型名称top_k:返回的文档数量返回:实现了 .invoke(query) 方法的 ChromaRetriever 实例"""from langchain_core.documents import Documentfrom langchain_core.retrievers import BaseRetrieverfrom langchain_ollama import OllamaEmbeddingsclass ChromaRetriever(BaseRetriever):"""直接包装原生 chromadb.Collection 的 LangChain Retriever。继承 langchain_core.retrievers.BaseRetriever(Pydantic v2)。必须实现:_get_relevant_documents(query: str) -> list[Document]"""# ── Pydantic v2:类级别声明所有字段 ─────────────────────collection: object # 原生 chromadb.Collectionembeddings_model: str # Ollama 嵌入模型名称top_k: int = 3 # 返回的文档数量def _get_relevant_documents(self, query: str) -> list[Document]:"""核心方法:根据 query 获取相关文档。流程:1. embed_query(query) → 向量2. collection.query() → Chroma 检索3. 组装 list[Document] 返回"""# embeddings 在方法内实例化,不作为 Pydantic 字段embeddings = OllamaEmbeddings(model=self.embeddings_model)query_vector = embeddings.embed_query(query)# Chroma 原生查询results = self.collection.query(query_embeddings=[query_vector],n_results=self.top_k,include=["documents", "metadatas", "distances"],)# 组装 Document 列表docs = []raw_docs = results.get("documents", [[]])[0]raw_metas = (results.get("metadatas") or [[]])[0]raw_dists = (results.get("distances") or [[]])[0]for i, content in enumerate(raw_docs):meta = raw_metas[i] if i < len(raw_metas) else {}meta["distance"] = raw_dists[i] if i < len(raw_dists) else Nonedocs.append(Document(page_content=content, metadata=meta))return docsreturn ChromaRetriever(collection=collection,embeddings_model=embeddings_model,top_k=top_k,)
3.3步骤 3:带元数据过滤的 Retriever
def _build_filtered_retriever(collection, filter_condition: dict):"""创建支持元数据过滤的 Retriever。示例过滤条件:{"type": "技术文档"} → type 等于"技术文档"{"type": {"$in": ["技术文档", "论文"]}} → type 在列表中{"chapter": {"$gte": 3}} → chapter >= 3参数:collection:Chroma Collectionfilter_condition:Chroma where 子句(dict)返回:支持过滤的 ChromaFilteredRetriever 实例"""from langchain_core.documents import Documentfrom langchain_core.retrievers import BaseRetrieverfrom langchain_ollama import OllamaEmbeddingsclass ChromaFilteredRetriever(BaseRetriever):"""支持元数据过滤的 Retriever"""# ── Pydantic v2 ────────────────────────────────────────collection: objectembeddings_model: strtop_k: int = 3filter_condition: dict | None = None # 可选字段必须用 | Nonedef _get_relevant_documents(self, query: str) -> list[Document]:embeddings = OllamaEmbeddings(model=self.embeddings_model)query_vector = embeddings.embed_query(query)query_kwargs = {"query_embeddings": [query_vector],"n_results": self.top_k,"include": ["documents", "metadatas", "distances"],}if self.filter_condition:query_kwargs["where"] = self.filter_conditionresults = self.collection.query(**query_kwargs)docs = []raw_docs = results.get("documents", [[]])[0]raw_metas = (results.get("metadatas") or [[]])[0]raw_dists = (results.get("distances") or [[]])[0]for i, content in enumerate(raw_docs):meta = raw_metas[i] if i < len(raw_metas) else {}meta["distance"] = raw_dists[i] if i < len(raw_dists) else Nonedocs.append(Document(page_content=content, metadata=meta))return docsreturn ChromaFilteredRetriever(collection=collection,embeddings_model="nomic-embed-text",top_k=3,filter_condition=filter_condition,)
3.4步骤 4:相似度阈值 Retriever(高级)
def _build_threshold_retriever(collection, threshold: float = 0.85):"""自定义 Retriever:只返回 distance < threshold 的结果。用途:- 过滤掉低相关度的噪音文档- threshold=1.0 时等同于 top_k 检索(几乎所有文档都通过)- threshold=0.0 时只返回完全匹配的文档参数:collection:Chroma Collectionthreshold:距离阈值(distance < threshold 才返回)返回:SimilarityThresholdRetriever 实例"""from langchain_core.documents import Documentfrom langchain_core.retrievers import BaseRetrieverfrom langchain_ollama import OllamaEmbeddingsclass SimilarityThresholdRetriever(BaseRetriever):"""只返回相似度超过阈值的结果"""# ── Pydantic v2 ────────────────────────────────────────collection: objectembeddings_model: str = "nomic-embed-text"top_k: int = 5 # 多取一些,过滤掉不相关的threshold: float = 0.85 # distance < threshold 才返回def _get_relevant_documents(self, query: str) -> list[Document]:embeddings = OllamaEmbeddings(model=self.embeddings_model)query_vector = embeddings.embed_query(query)results = self.collection.query(query_embeddings=[query_vector],n_results=self.top_k,include=["documents", "metadatas", "distances"],)docs = []raw_docs = results.get("documents", [[]])[0]raw_metas = (results.get("metadatas") or [[]])[0]raw_dists = (results.get("distances") or [[]])[0]for i, content in enumerate(raw_docs):distance = raw_dists[i] if i < len(raw_dists) else 999if distance >= self.threshold:continuemeta = raw_metas[i] if i < len(raw_metas) else {}meta["distance"] = distancedocs.append(Document(page_content=content, metadata=meta))return docsreturn SimilarityThresholdRetriever(collection=collection,embeddings_model="nomic-embed-text",top_k=5,threshold=threshold,)
3.5 步骤 5:LangGraph RAG StateGraph
def _build_langgraph_rag_chain(retriever):"""使用 LangGraph StateGraph 构建 RAG 问答链。这是 LangChain 1.0+ 推荐的方式(替代已废弃的 RetrievalQA)。节点:- retrieve:调用 retriever 获取相关文档- generate:用 LLM 基于文档上下文生成回答边:- retrieve → generate(固定顺序)参数:retriever:LangChain Retriever 实例返回:compiled graph(可通过 .invoke({"question": "..."}) 调用)"""from typing import Annotated, TypedDictfrom operator import add as add_messagesfrom langgraph.graph import StateGraph, ENDfrom langchain_core.documents import Documentfrom langchain_ollama import ChatOllamafrom langchain_core.messages import HumanMessage, SystemMessagefrom langchain_core.prompts import PromptTemplate# ── 定义状态类型 ─────────────────────────────────────────class RAGState(TypedDict):"""RAG 链的状态:问题 + 检索到的文档 + LLM 回复"""question: str # 用户问题context: Annotated[list[Document], add_messages] # 检索到的文档列表answer: str | None # LLM 回答# ── 节点函数 ──────────────────────────────────────────────def retrieve_node(state: RAGState) -> dict:"""节点1:检索相关文档"""docs = retriever.invoke(state["question"])return {"context": docs}def generate_node(state: RAGState) -> dict:"""节点2:基于上下文生成回答"""# 构造上下文字符串context_str = "\n\n".join(f"[来源 {i+1}] {doc.page_content}"for i, doc in enumerate(state["context"]))prompt = f"""你是一个有帮助的 AI 助手,基于提供的上下文回答问题。【上下文】{context_str}【问题】{state["question"]}请简洁、准确地回答。如果上下文无法回答,请说明"当前上下文没有相关信息"。"""llm = ChatOllama(model="qwen3:4b", temperature=0, num_ctx=8192)response = llm.invoke([HumanMessage(content=prompt)])return {"answer": response.content}# ── 构建图 ────────────────────────────────────────────────graph = StateGraph(RAGState)graph.add_node("retrieve", retrieve_node)graph.add_node("generate", generate_node)graph.set_entry_point("retrieve")graph.add_edge("retrieve", "generate")graph.add_edge("generate", END)compiled = graph.compile()print("[OK] LangGraph RAG StateGraph 编译成功")return compiled
4.1 演示函数
def demo():"""演示 LangChain Retriever 进阶用法:1. 加载已存在 Collection2. 基础 Retriever 检索3. 元数据过滤检索4. LangGraph RAG StateGraph 问答(替代已废弃的 RetrievalQA)5. 相似度阈值过滤"""print("\n" + "=" * 60)print("Day8-02 · LangChain Retriever 进阶演示")print("=" * 60)persist_dir = str(_SCRIPT_DIR / "chroma_db")# ── 步骤 1:加载 Collection ────────────────────────────────print("\n[步骤 1/5] 加载已存在的 Chroma Collection...")try:collection = _load_collection(persist_dir)except Exception as e:print(f"[错误] 无法加载 Collection:{e}")print(" 请先运行 Day8-01 完成索引:python 01_rag_basics.py")return# ── 步骤 2:基础 Retriever ────────────────────────────────print("\n[步骤 2/5] 基础 Retriever 检索(k=3)...")retriever = _build_chroma_retriever(collection, top_k=3)docs = retriever.invoke("LangGraph 是什么?")print(f" 检索到 {len(docs)} 个文档:")for d in docs:src = d.metadata.get("source", "?")dist = d.metadata.get("distance")dist_str = f"{dist:.4f}" if dist is not None else "?"print(f" - [{src}] (distance={dist_str})")print(f" {d.page_content[:60]}...")# ── 步骤 3:元数据过滤 ────────────────────────────────────print("\n[步骤 3/5] 元数据过滤检索...")filter_tests = [("只看技术文档", {"type": "技术文档"}),("只看协议文档", {"type": "协议文档"}),("只看第3章以后", {"chapter": {"$gte": 3}}),]for name, condition in filter_tests:filtered = _build_filtered_retriever(collection, condition)docs = filtered.invoke("LangGraph 是什么?")print(f"\n 过滤:{name} → {len(docs)} 个文档")for d in docs[:2]:print(f" - {d.page_content[:50]}...")# ── 步骤 4:LangGraph RAG ────────────────────────────────print("\n[步骤 4/5] LangGraph RAG StateGraph 问答...")rag_graph = _build_langgraph_rag_chain(retriever)for q in ["MCP 协议的作用是什么?", "Chroma 数据库有什么特点?"]:print(f"\n 用户:{q}")result = rag_graph.invoke({"question": q})print(f" AI:{result['answer'].strip()}")print(f" 检索到 {len(result['context'])} 个文档作为上下文")# ── 步骤 5:相似度阈值过滤 ───────────────────────────────print("\n[步骤 5/5] 相似度阈值过滤(threshold=0.85)...")threshold_retriever = _build_threshold_retriever(collection, threshold=0.85)for q in ["LangGraph 的核心概念是什么?", "今天天气怎么样?"]:docs = threshold_retriever.invoke(q)print(f"\n 查询:{q}")if docs:print(f" 返回 {len(docs)} 个文档(distance 均 < 0.85):")for d in docs:dist = d.metadata.get("distance")print(f" - distance={dist:.4f}: {d.page_content[:50]}...")else:print(f" 无相关结果(所有文档 distance >= 0.85)")print("\n" + "=" * 60)print("Day8-02 演示完成!")print("=" * 60)if __name__ == "__main__":demo()
后续分享更系列教程关注“极简工具盒”公众号探索更多精彩内容,谢谢!

本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 被低估的Linux灵魂:Bash Shell,程序员的效率神器
- Linux IIO 子系统:从原理到驱动开发,一文读懂传感器与ADC的内核框架
- ATZ Linux(铜豌豆 Linux)——为中国用户打磨的 Debian 中文桌面系统
- posix_fadvise(2) - Linux 手册页
- Linux杂记-- 获取运行中 Linux 内核的信息
- 嵌入式Linux学习指南之设备树——Linux内核设备树编译机制深度解析
- Python 数据容器:列表和字典让数据管理更简单
- 真实的Linux故障诊断场景 13 软件管理
- 不懂 TLB,别再说你懂 Linux 内核了
- 一个授予普通进程ROOT权限的Linux内核级后门:原理与实现深度解析
