零基础入门Python爬虫:从Python基础到实操爬取,看完就能上手!
- 2026-06-24 22:47:43
大家好~ 经常有小伙伴问:“零基础能学Python爬虫吗?”“学爬虫需要先把Python学透吗?”“简单的爬虫到底怎么写?”
答案很明确:零基础完全可以学! 而且Python爬虫是最适合新手入门的Python应用方向——不用高深的编程功底,掌握核心基础+常用工具,就能轻松写出第一个爬虫,实现“自动抓取网页信息”。
今天就从0到1,手把手带大家梳理Python爬虫的完整学习路径,从Python介绍、基础学习,到爬虫入门、实操案例,每个环节都讲透,新手也能跟着学、跟着练,看完就能动手写自己的第一个爬虫!

一、先搞懂:Python到底是什么?为什么适合做爬虫?
很多新手没接触过Python,先给大家做个通俗科普,不用记复杂概念,看懂核心就行!
Python的定义:一种简洁、易读、可扩展的编程语言,诞生于1989年,核心特点就是“上手快、代码简洁、生态强大”——同样的功能,用其他语言可能要写10行代码,用Python可能3行就搞定。
而它之所以成为爬虫的“首选语言”,核心就3个原因,新手记好:
语法简单:零基础也能快速上手,不用死记硬背复杂语法,专注于“实现功能”即可
生态完善:有大量现成的第三方库,不用自己从零开发,调用现成工具就能实现爬虫核心功能
灵活性高:不管是简单的“爬取网页文字”,还是复杂的“批量爬取数据、处理动态网页”,Python都能轻松应对
补充一句:Python不止能做爬虫,还能做数据分析、自动化办公、web开发、人工智能等,学会Python,相当于掌握了一门“万能技能”,不管是兼职接单,还是职场提升,都很有帮助。

二、Python基础:必学知识点+高效学习方法(新手重点)
很多新手会陷入一个误区:“想直接学爬虫,不想学Python基础”。其实不然——爬虫是Python的“应用”,基础是“根基”,根基打牢,学爬虫会事半功倍;跳过基础直接学爬虫,只会越学越懵。
但不用慌,学爬虫需要的Python基础,不用学太深,掌握以下核心知识点就足够,新手1-2周就能吃透
1. 必学基础知识点
不用学完所有Python知识点,重点掌握这5块,完全能支撑爬虫学习:
基础语法:变量、数据类型(字符串、列表、字典、元组)、运算符(算术、比较、逻辑),这是所有代码的基础,就像“汉字和拼音”;
流程控制:if条件判断、for/while循环,爬虫中“批量爬取、筛选数据”全靠它,比如“循环爬取10页网页”;
函数基础:会定义简单函数、调用函数,能把重复的代码封装起来,减少冗余(比如爬虫中“发送请求”的代码,封装成函数可重复使用);
文件操作:会用open()函数读写文件(txt、csv等),爬虫爬取到的数据,需要保存到文件中,这一步必不可少;
异常处理:了解try-except语句,避免爬虫因为“网页无法访问、数据不存在”而直接崩溃,让爬虫更稳定
2. 新手高效学习方法
很多新手学基础,容易陷入“只看不动手”“盲目刷题”的误区,分享3个高效方法,帮你快速掌握基础,为爬虫铺路:
第一步:先学基础语法,每天1小时,7天吃透不用看厚厚的教材,找一套新手教程(比如菜鸟教程、Python官方教程),每天学1个知识点,配合简单的代码练习(比如“定义一个列表、写一个简单的循环”),不追求速度,追求“听懂、会写”。
第二步:边学边练,做小案例巩固学完基础语法后,做2-3个简单小案例,比如“写一个计算器”“统计一段文字的字数”“批量重命名文件”,把学到的知识点用起来,避免“一看就会,一写就废”。这里提醒大家,学Python最核心的就是动手,只看不动手,永远学不会。
第三步:针对性补充,不贪多求全不用学完所有Python知识点(比如类、面向对象、多线程等),学到“能写简单函数、能处理列表/字典、能读写文件”就可以,剩下的知识点,在学爬虫的过程中,遇到再补充,效率更高。
推荐工具:编辑器用VS Code或者Pycharm,不用纠结复杂的配置,安装好Python环境,就能直接写代码、运行代码

三、快速入门Python爬虫
掌握Python基础后,就可以正式入门爬虫了。先搞懂核心概念,再掌握常用工具,最后动手实操,就能快速上手。
1. 爬虫的核心概念
很多人觉得爬虫很高深,其实通俗来讲,爬虫就是一个“自动化的信息采集员”——它模拟我们人类浏览网页的行为,自动打开网页、读取网页内容、提取有用信息,最后把信息保存起来,省去我们手动复制粘贴的麻烦。
爬虫的核心流程(记好这4步,所有爬虫都离不开):
发送请求:向目标网页发起访问(相当于我们在浏览器输入网址,按回车);
获取响应:拿到网页的原始代码(相当于我们看到的网页“源代码”,里面包含了网页的所有文字、图片等信息);
解析数据:从杂乱的网页代码中,筛选出我们需要的信息(比如网页中的文章文字、图片链接);
保存数据:把筛选出来的信息,保存到文件(txt、csv)或数据库中,方便后续查看、使用。
注意:爬虫虽好用,但要遵守规则,不要爬取涉密、违规网站,也不要频繁请求同一个网站(避免给网站服务器造成压力),合法合规爬取才是关键。
2. 学爬虫必用的第三方库
Python爬虫的强大,离不开第三方库——这些库是别人已经开发好的工具,我们直接调用,就能实现爬虫的核心功能,不用自己从零开发。新手重点掌握这3个,足够应对基础爬虫需求,进阶场景可再补充其他工具。
先教大家一个通用操作:安装第三方库。打开电脑的“命令提示符”(Windows)或“终端”(Mac),输入“pip install 库名”,就能快速安装,建议用清华源加速,下载更快(在命令末尾加上“-i https://pypi.tuna.tsinghua.edu.cn/simple”)。
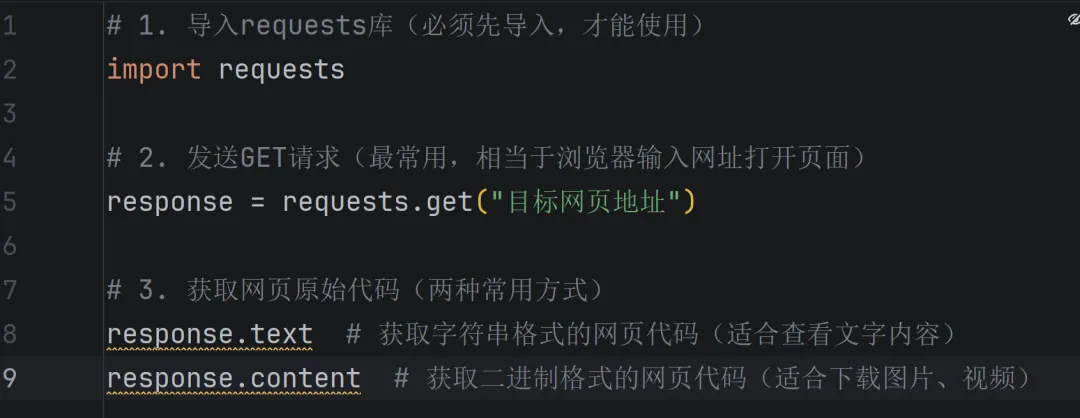
(1)requests库:发送网页请求
作用:模拟浏览器,向目标网页发送请求,获取网页的原始代码(响应内容),是爬虫的第一步,也是最基础的一步。
核心语法
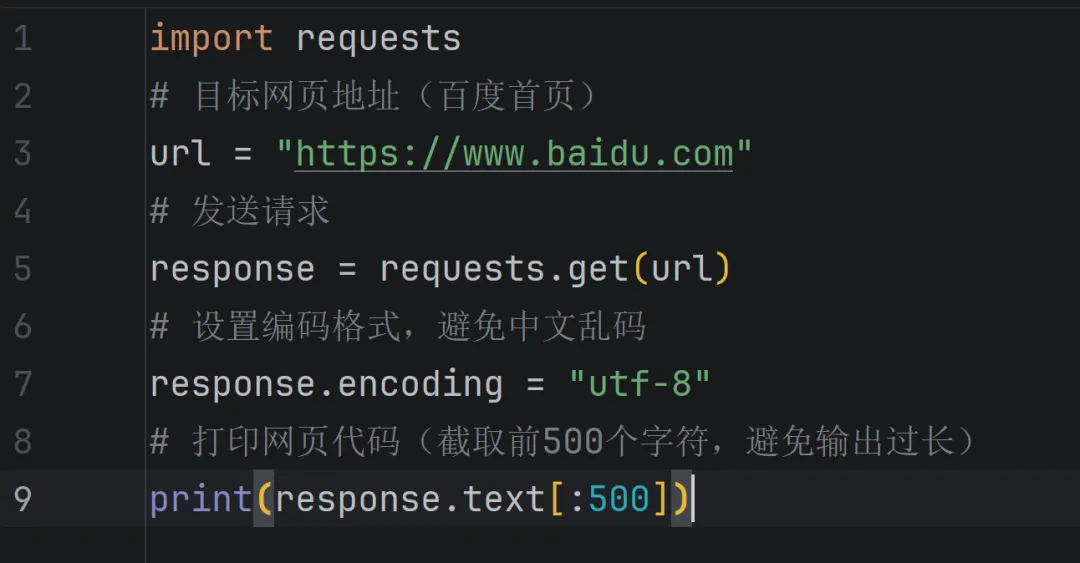
简单示例:获取百度首页的代码
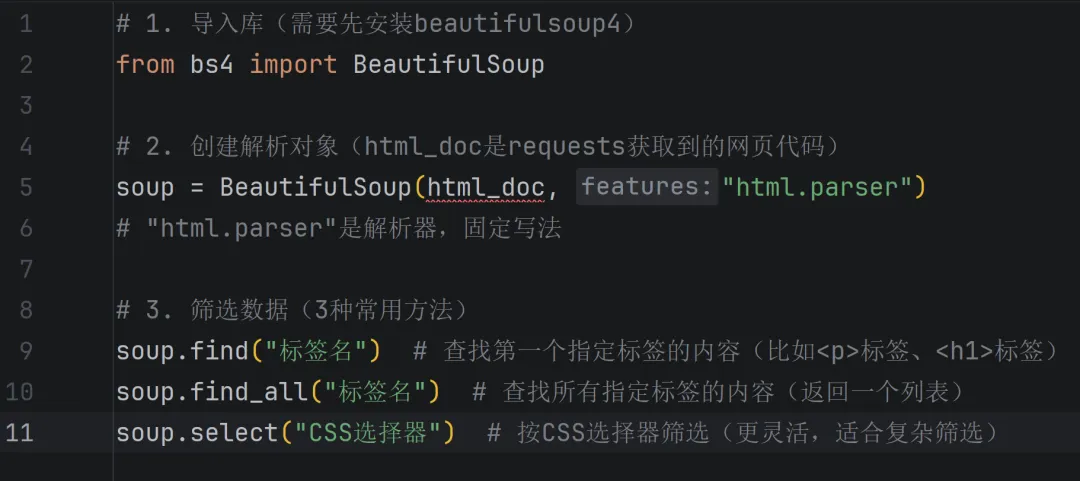
(2)BeautifulSoup库:解析网页数据
作用:把requests获取到的杂乱网页代码,进行整理、解析,快速筛选出我们需要的信息(比如文字、链接、图片地址),不用手动去代码里找,效率极高。
核心语法
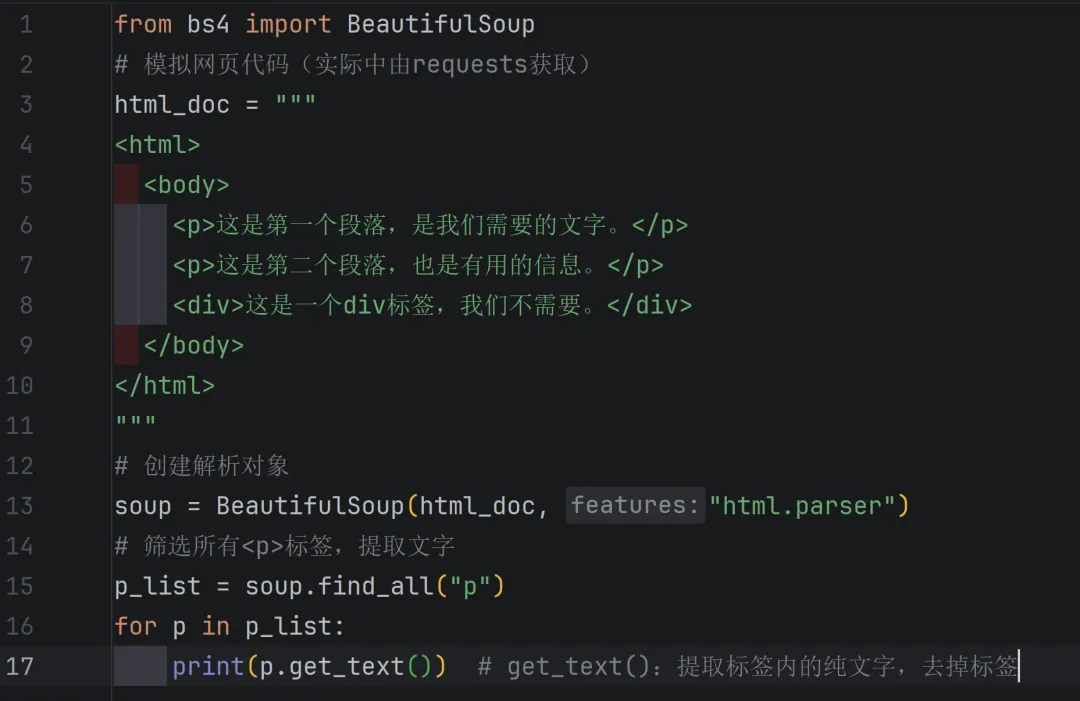
简单示例:从网页代码中,筛选出所有<p>标签的文字内容(网页中的段落文字)
(3)lxml库:高效解析
作用:和BeautifulSoup功能类似,也是解析网页代码,但解析速度更快,支持XPath语法,适合处理复杂、庞大的网页代码。
核心语法
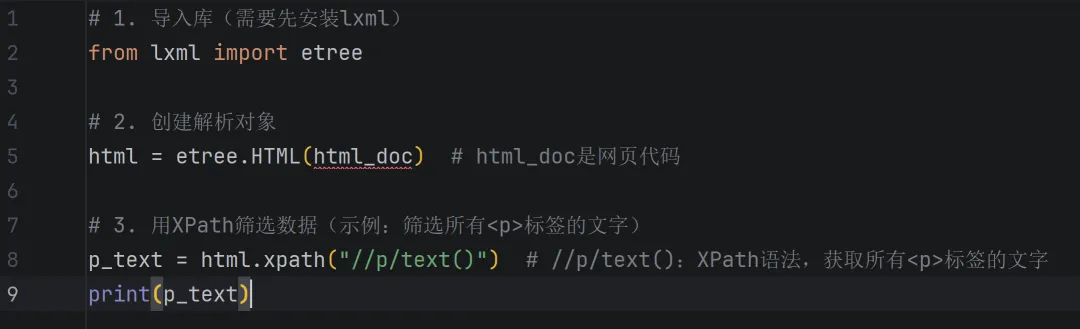
3. 新手入门爬虫的3个关键技巧
先从“静态网页”入手:新手不要一开始就挑战动态网页(比如需要登录、滚动加载的网页),先爬取静态网页(比如简单的博客、文档网页),难度低、易上手
学会查看网页源代码:在浏览器中打开目标网页,按F12就能查看网页源代码,找到我们需要的信息对应的标签,再用BeautifulSoup筛选
遇到报错不要慌:新手写爬虫,很容易遇到“请求失败、中文乱码、筛选不到数据”等问题,先查看报错信息,大概率是“网页地址错误、编码格式未设置、标签找错了”,逐一排查就能解决。

四、实操案例:写一个简单的网络爬虫
掌握了上面的知识点,我们就来动手写第一个爬虫——爬取一个静态网页的文字信息(以一个简单的文章网页为例),全程手把手,复制代码就能运行,新手也能轻松搞定!
案例目标:爬取目标网页中的“文章标题”和“所有段落文字”,并保存到txt文件中。
准备工作:先安装好requests和beautifulsoup4库,命令如下(复制到终端执行):

完整爬虫代码(带详细注释,看不懂的地方看注释)
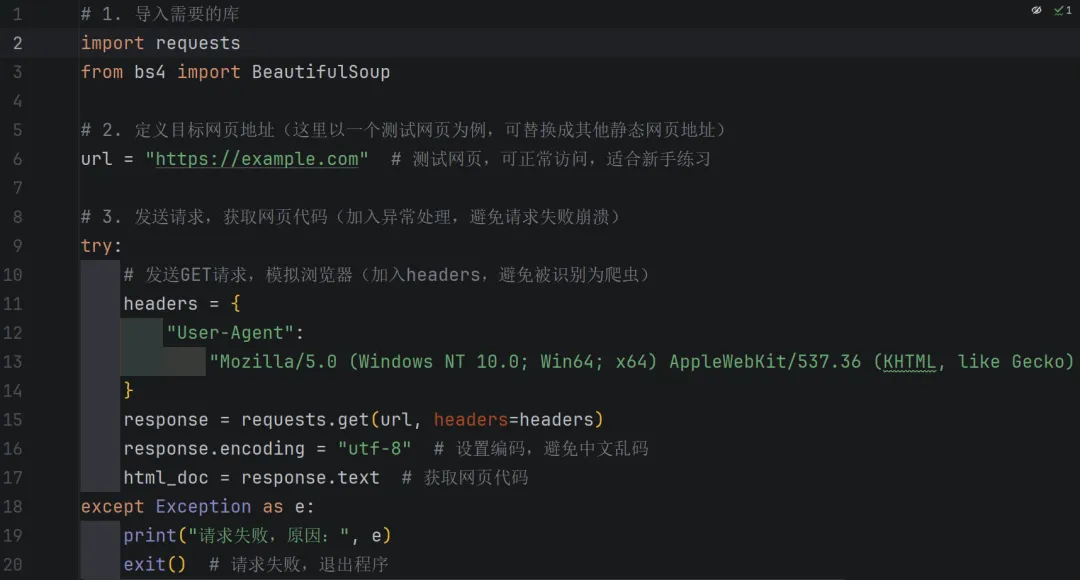
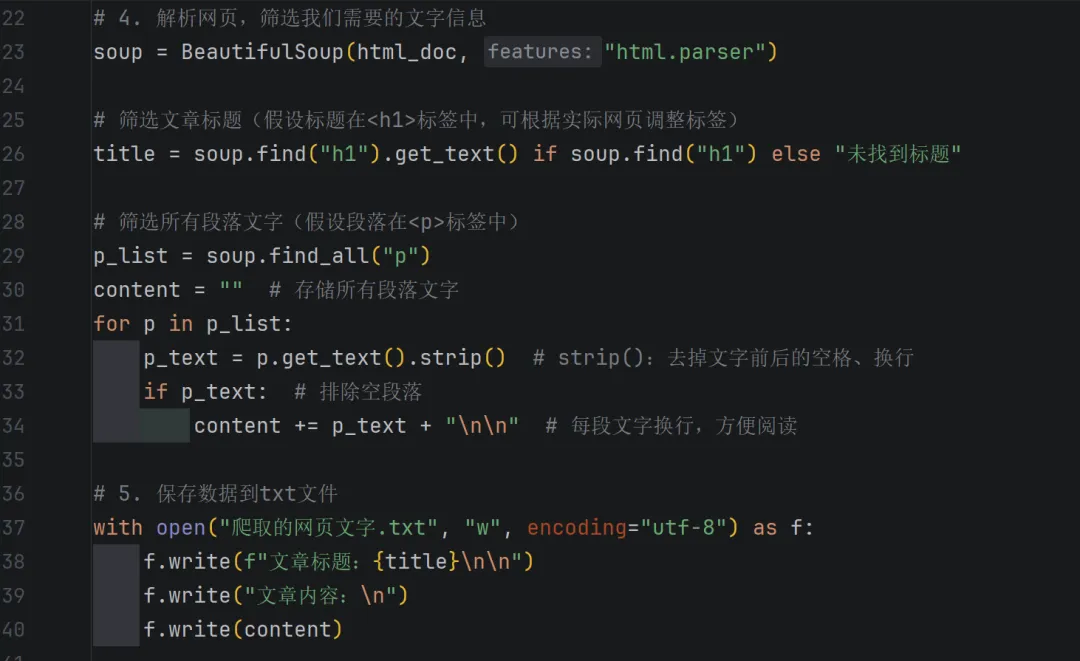
代码运行说明(新手必看)
替换网页地址:把url中的“https://example.com”替换成你想爬取的静态网页地址(比如简单的博客文章、文档网页);
调整标签:如果爬取不到标题或段落,大概率是标签找错了——打开目标网页,按F12查看源代码,找到标题、段落对应的标签(比如标题可能在<h2>标签中),修改代码中的标签名即可;
查看结果:运行代码后,会在当前文件夹生成一个“爬取的网页文字.txt”文件,打开就能看到爬取到的文字信息。
提示:这个案例是最基础的爬虫,适合新手练习;如果想爬取更复杂的内容(比如图片、多页网页),可以后续深入学习。

五、从零基础到爬虫入门,你只差这一步
今天我们完整梳理了Python爬虫的学习路径:从Python的基本介绍,到Python基础的必学知识点、学习方法,再到爬虫的概念、核心库用法,最后用一个实操案例,带大家动手写出了第一个爬虫。
其实不难发现,Python爬虫入门真的很简单——只要掌握“Python基础+3个核心库+爬虫流程”,就能轻松上手,实现简单的信息爬取。不管你是零基础想入门编程,还是想掌握一项实用技能(比如批量采集数据、自动化整理信息),Python爬虫都是一个非常好的选择。
很多新手在学习过程中,会遇到“基础学不牢、爬虫报错不会解决、不知道怎么进阶”的问题,为了帮大家少走弯路,快速掌握Python和爬虫技能,我这边专门有一节python精品直播课,里面讲解了有关python基础学习思路、爬虫案例讲解分析以及python学习后的就业方向指导,想要了解的可以添加一下下面的助理信息,去预约一下课程。

直播课全程干货,针对零基础新手,手把手教你打牢Python基础、拆解爬虫案例,还会分享Python就业干货(比如爬虫工程师、数据分析岗位的需求和技能要求),帮你明确学习方向,避免盲目学习。
最后提醒大家:学习爬虫,动手是关键,多写代码、多练案例,遇到问题多排查,慢慢就能从新手变成“爬虫高手”,赶紧动手试试今天的实操案例吧!

往期文章:
【从零入门Python】一文带你了解Python九大核心模块
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Python3——输入输出 + 代码注释
- 运行Python代码的N种姿势:从零开始,轻松跑起你的第一行程序!
- 跟着NOAI考纲学Python,学完就能考,第14课
- 不用死磕Python!Claude Code自动生成200+行分析脚本,搭配Codex3轮审稿,论文从4分逆袭到可投级,科研人直接抄作业
- 国家送的编程神器,不会Python的死磕这个
- 一份自用的Python学习知识库,分享给大家
- 别再手工跑 DID 了!一文讲清Python 的双重差分实现(含平行趋势检验)
- Python实例属性与方法——对象的数据与行为
- Python第七周项目
- 零基础Python自学,8个免费网站全够用!
