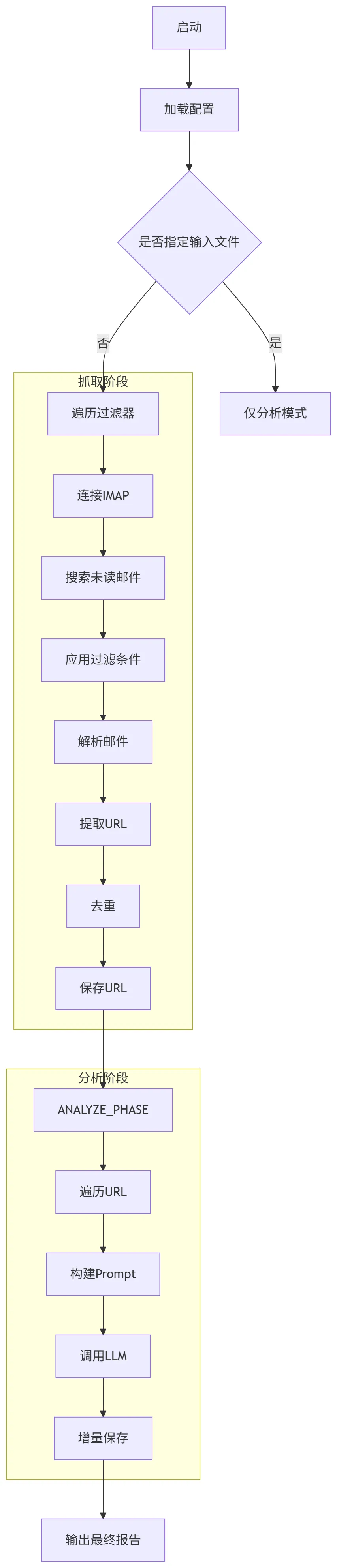
流程拆解
1. 启动 / 初始化
2. 邮件抓取
3. URL 提取
4. 分析阶段
5. 输出生成
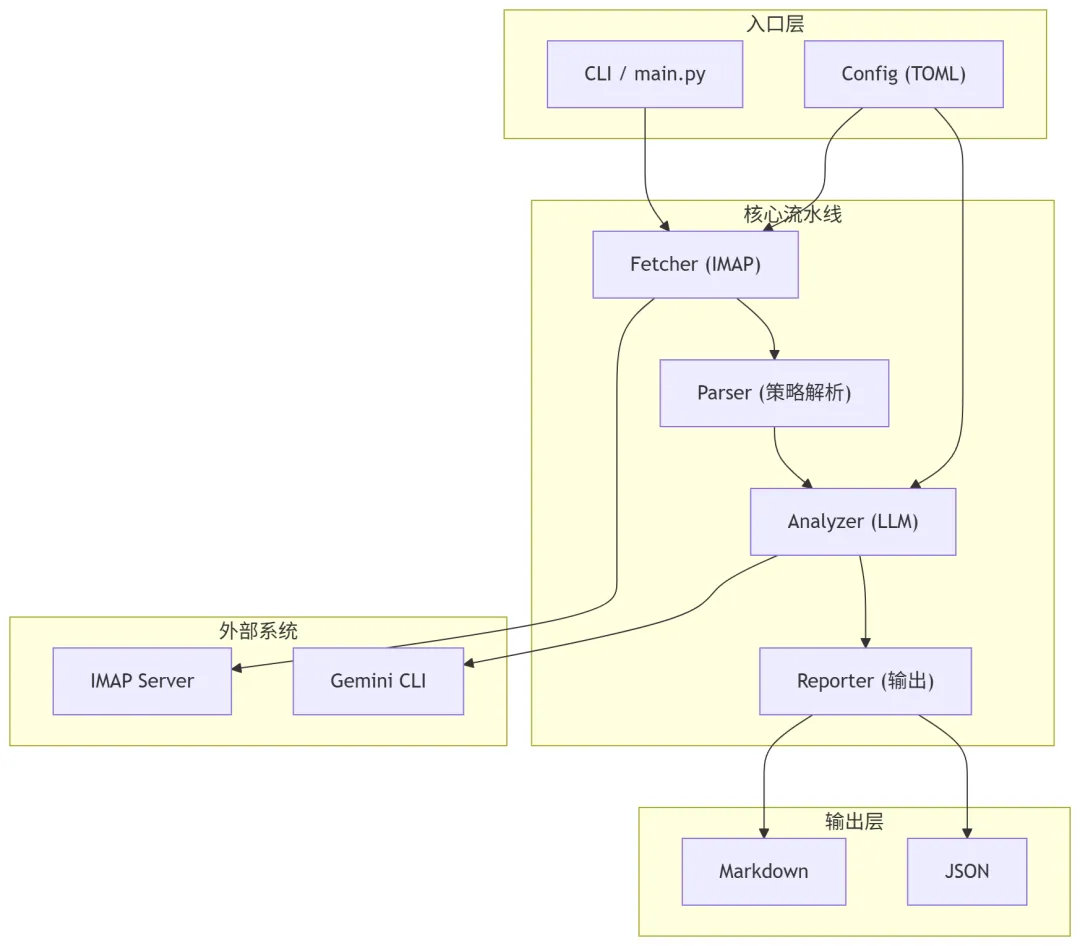
核心实现解析(Key Implementation)
配置系统(类型安全 + 多过滤器)
统一管理多来源邮件规则,避免硬编码。
@dataclasses.dataclassclass FilterConfig: name: str sender: str title_keywords: List[str] max_emails: int extract_format: str = "name_url"for f in filters_data: if name in names: raise ValueError("Duplicate filter name")
设计
Fetcher(IMAP + 双层过滤)
高效筛选目标邮件,减少无效解析。
search_criteria = ["UNSEEN"]if filter_config.sender: search_criteria.extend(["FROM", filter_config.sender])if not filter_config.title_keywords: return True
设计
Parser(策略模式)
适配不同邮件格式(Medium / Newsletter 等)
class ParserFactory: def create(extract_format): if extract_format == "name_url": return MediumParser()
设计
URL 解析与清洗(抗噪核心)
去除跳转链接、过滤无效页面
redirect_params = ["redirectUrl", "url", "target"]if any(keyword in lower_title for keyword in _NOISY_TITLE_KEYWORDS): return False
设计
Analyzer(LLM 调用工程化)
稳定调用 Gemini CLI,生成结构化分析
with tempfile.NamedTemporaryFile(...) as tmp_user:env["GEMINI_SYSTEM_MD"] = tmp_sys_path
关键设计
增量输出(防数据丢失)
for result in analyzer.analyze_articles(...): reporter.generate_summaries_report(...)
设计
★ 源码 URL:https://github.com/alwaysrun/EmailExtractor
”
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
