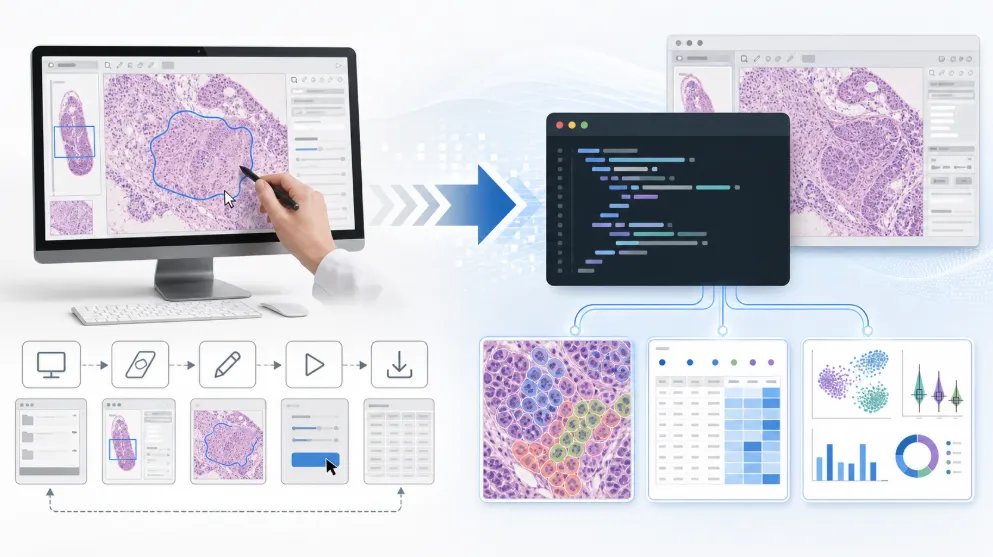
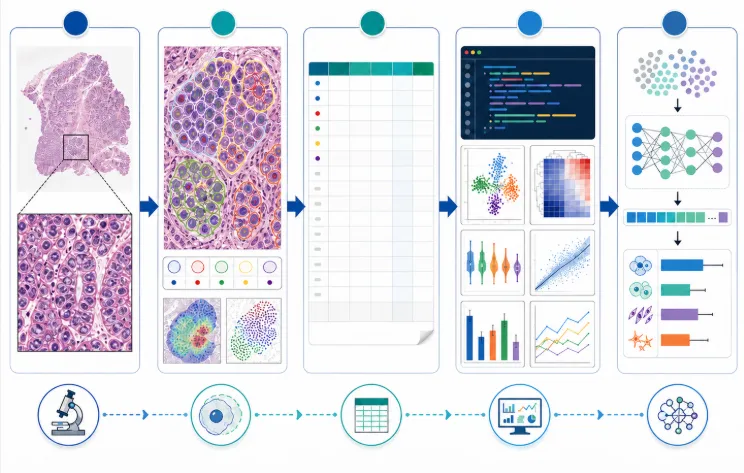
做过数字病理分析的人,大概都经历过这样的场景:打开QuPath,加载切片,手动画ROI,跑细胞检测,导出数据,再切换到Excel或Python做统计和绘图。一张切片还好,十张、五十张呢?当你的课题需要处理上百张切片时,这套
打开软件→点击菜单→等待结果→手动导出
的流程,就成了科研效率的瓶颈。
有没有可能,不打开QuPath的界面,也能完成分析?
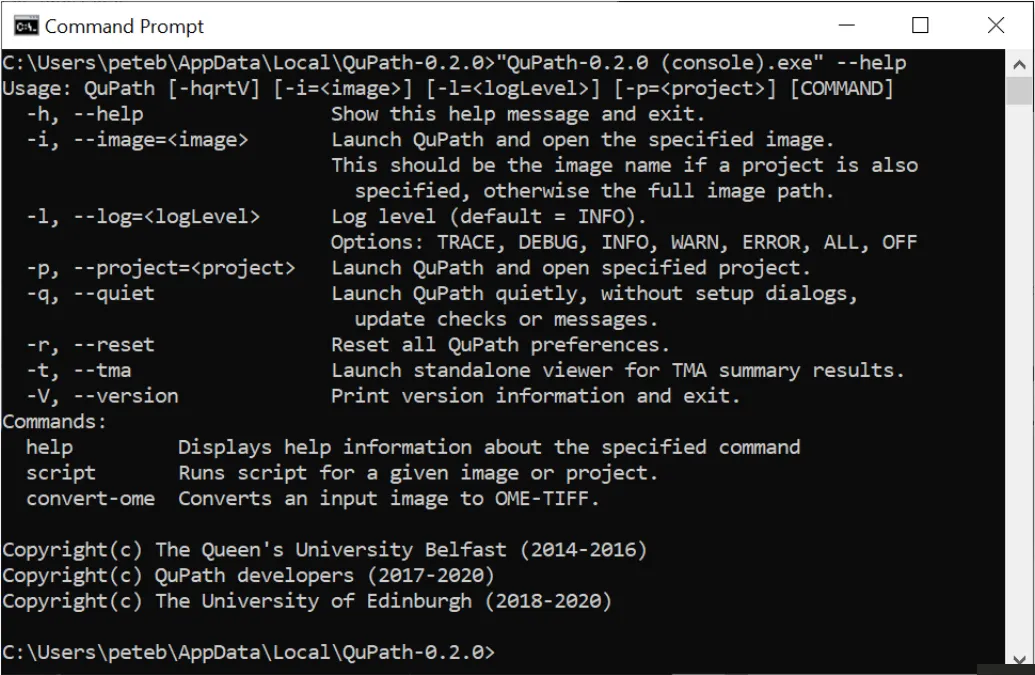
答案是肯定的。QuPath从0.2.0版本开始就提供了命令行接口(CLI),允许用户在终端中直接执行Groovy脚本。这意味着我们可以用Python的subprocess模块调用QuPath,把整个分析流程串成一条自动化流水线——从细胞分割到数据导出再到结果可视化,一行python run.py就能搞定。
这篇文章,我想和大家聊聊这条技术路线背后的思路和价值,而不仅仅是操作步骤。
为什么要去界面化
QuPath的图形界面设计得非常优秀,对于日常的标注和分析完全够用。但界面操作有一个本质缺陷:不可精确复现。你上周用的阈值是什么?你画ROI时鼠标停在了哪里?你是否在不同切片上用了完全一致的检测设置?这些问题,在点击式操作中很难回答。
2025年Digital Pathology & AI Congress上,多个报告强调了同一个趋势:随着研究规模的扩大,标准化的质控流程、可互操作的分析管线和结构化的数据管理,正在成为保障结果可靠性的基本要求。手动操作并非不好,而是它无法规模化,也难以被审计。
将分析逻辑固化在脚本中,本质上是在做一件事:把我做了什么变成代码记录了什么。这对于科研论文的可重复性、多中心研究的一致性,乃至未来临床验证的规范化,都有实际意义。
核心原理:三要素驱动
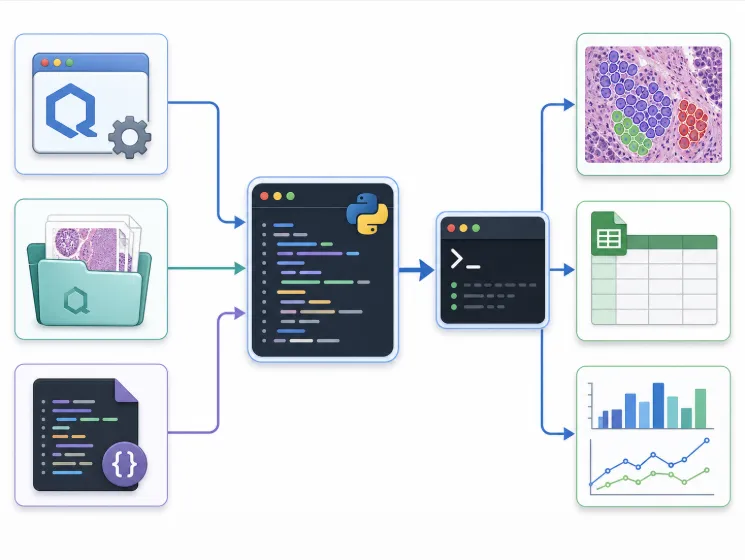
用Python调用QuPath CLI的技术原理并不复杂,核心就是三个要素:
第一,QuPath可执行文件的路径。 告诉系统去哪里找QuPath。无论是0.6.0还是最新的0.7.0,CLI接口的基本用法是一致的。
第二,QuPath项目文件(.qpproj)的路径。 项目文件记录了你的切片在哪里、标注信息是什么。这是分析的上下文。需要特别注意的是,Windows系统下路径的斜杠方向问题——这个看似琐碎的细节,恰恰是初学者最常踩的坑。
第三,Groovy脚本的路径。 这个脚本定义了你想让QuPath做什么——跑Cellpose细胞检测、测量形态学指标、导出CSV……所有分析逻辑都写在这里。
有了这三样东西,Python通过subprocess.run()构造一条命令行指令,QuPath就会在后台(headless模式)安静地完成分析,不弹出任何窗口。根据QuPath官方文档,CLI的调用格式为QuPath script -p project_path script_path,还支持通过--args传递参数、通过--server指定图像读取方式等进阶用法。
Groovy脚本:headless模式下的关键适配
这里有一个容易被忽视的技术细节:在QuPath界面里能跑通的Groovy脚本,放到headless模式下不一定直接能用。
原因在于,界面模式下QuPath会自动设置当前图像数据(currentImageData),而命令行模式下你需要自己处理I/O逻辑。具体到本文讨论的Cellpose分析场景,一个适配headless模式的Groovy脚本至少需要包含以下调整:
一是明确指定Cellpose所依赖的Python环境路径。Cellpose本身是一个Python深度学习模型,QuPath的Cellpose扩展在运行时需要知道去哪里调用Python。这个路径在界面里可以通过设置菜单配置,但在headless模式下必须写死在脚本中。
二是在脚本末尾加入数据保存逻辑。界面操作时你可以手动点Save,但headless模式下如果脚本不主动保存,分析结果会随进程结束而消失。关键的操作包括调用saveImageData保存标注数据,以及将测量结果导出为CSV文件。
这两点看似简单,却是能跑和白跑的分界线。
Python生态的接力
QuPath CLI完成的只是分析链条的中间环节。真正让这条路线具有吸引力的,是Python生态在上下游的无缝衔接。
在上游,你可以用Python批量管理切片文件、自动建立QuPath项目、根据元数据筛选需要分析的样本。在下游,CSV格式的测量结果可以直接被pandas读取,用matplotlib或seaborn绘制出版级别的图表——细胞面积分布、核质比统计、不同区域的细胞密度对比,这些在QuPath界面里需要反复操作的可视化任务,用几行Python代码就能批量生成。
更重要的是,这种模式天然适合与机器学习流程对接。你可以把QuPath的细胞检测结果作为特征输入,送进scikit-learn做分类,或者用PyTorch训练自定义模型。从标注到特征提取到建模,整条链路都在Python中完成,不需要在不同软件之间反复导入导出。
当然,Python与QuPath的交互并非只有CLI一条路。Paquo库可以直接读写QuPath项目文件,QuBalab则提供了通过JPype桥接Java的方式调用QuPath内部API。但CLI方案的优势在于零额外依赖——你不需要安装任何Python桥接库,不需要处理Java环境兼容性问题,只要QuPath本身能跑,这条路就通。对于不想折腾环境配置的临床科研人员来说,这可能是门槛最低的选择。(这些内容在阿图的QuPath训练营里都有详细介绍)。
一个实用建议
我的建议是,不要一开始就试图写headless脚本。先在QuPath的图形界面里完成一次完整的分析:加载图像,画好ROI,运行Cellpose,确认检测效果满意,记下所有参数。然后把这些参数固化到Groovy脚本中,加上保存逻辑,再用Python调用。
这个先手动、后自动的思路,既降低了调试难度,也确保了自动化流程的结果与你手动验证过的结果一致。QuPath的Cellpose扩展本身就提供了脚本模板(Extensions → Cellpose),你可以在此基础上修改,而不必从零开始写。
阿图的第五期QuPath图像处理训练营将在5月16,17日;5月23,24日两个周末开营,8个名额(即将报满)。欢迎加阿图咨询报名:

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
