Python绘制高颜值柱状图展示数据分布
- 2026-06-29 19:49:59
Python绘制高颜值柱状图展示数据分布

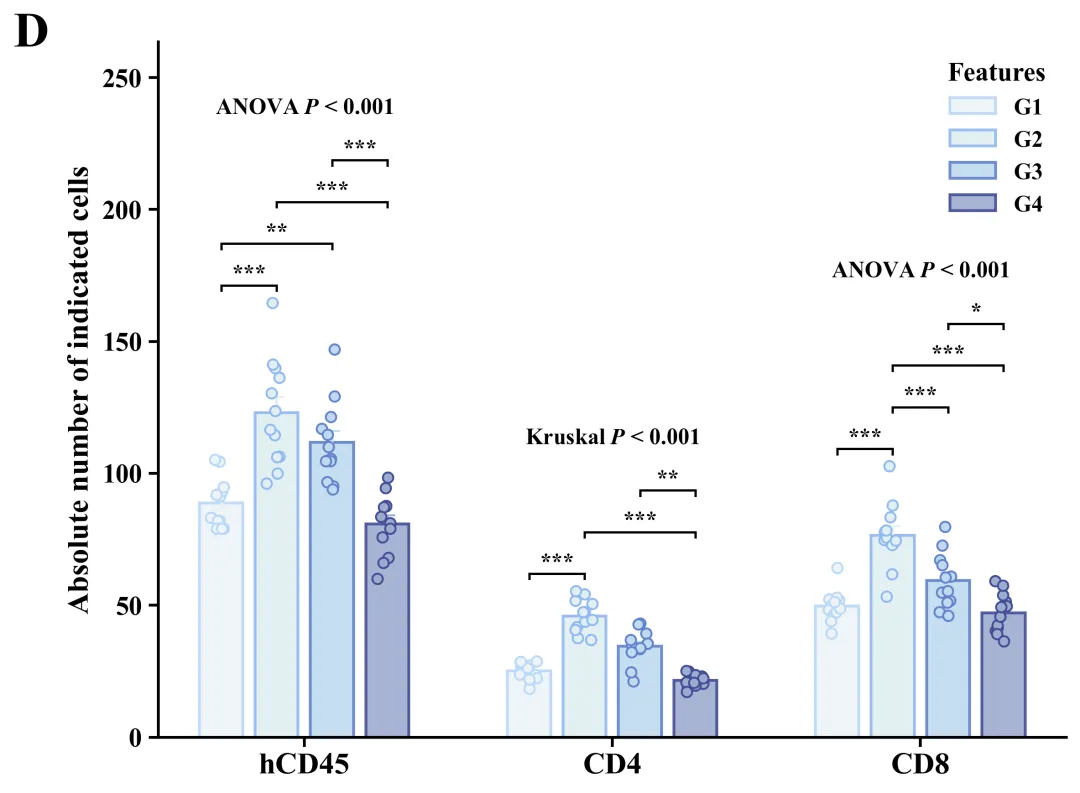
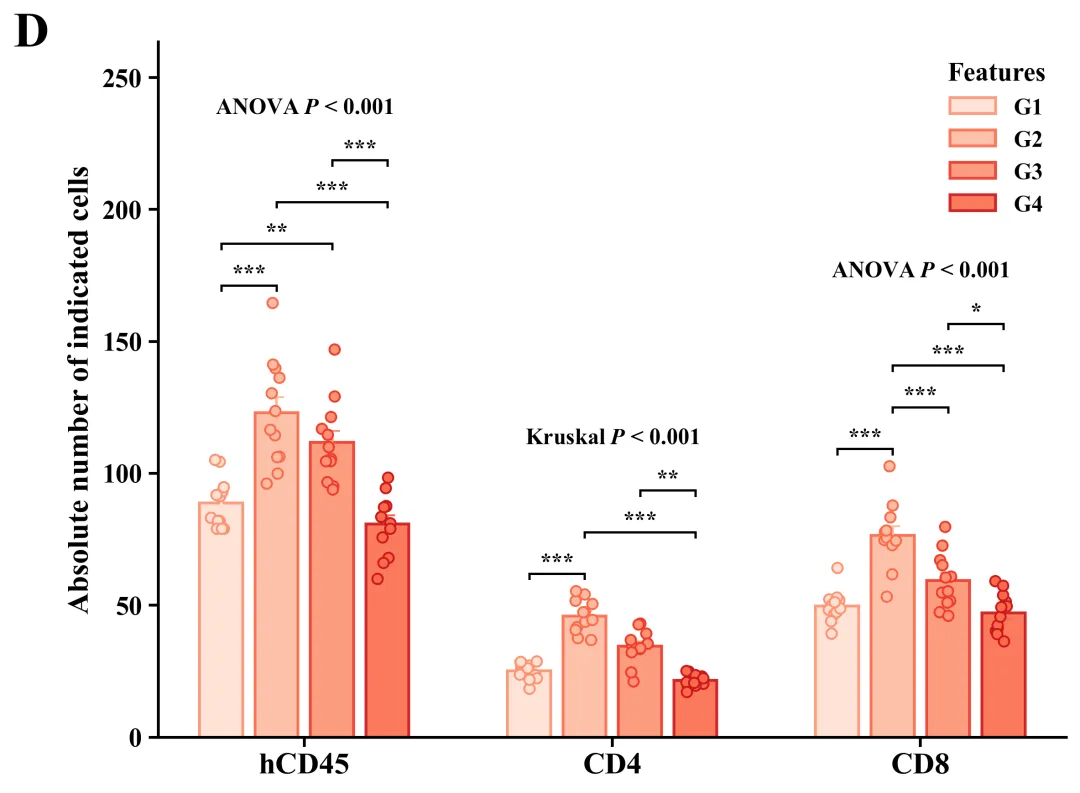


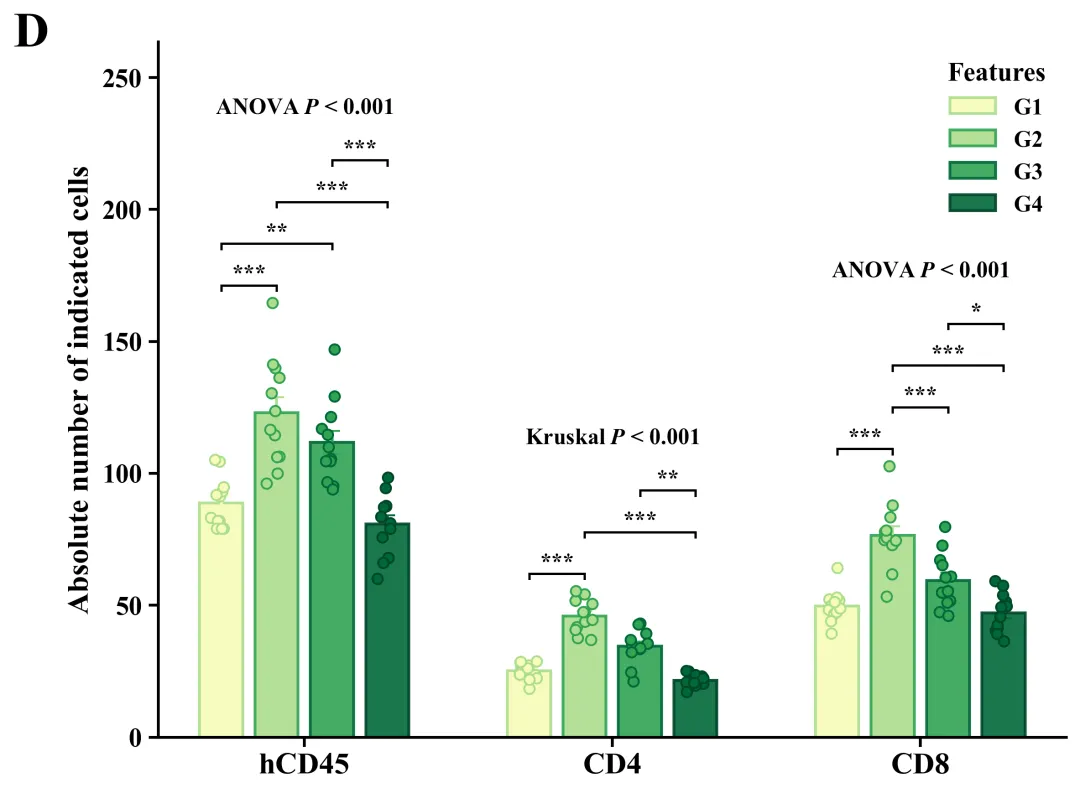
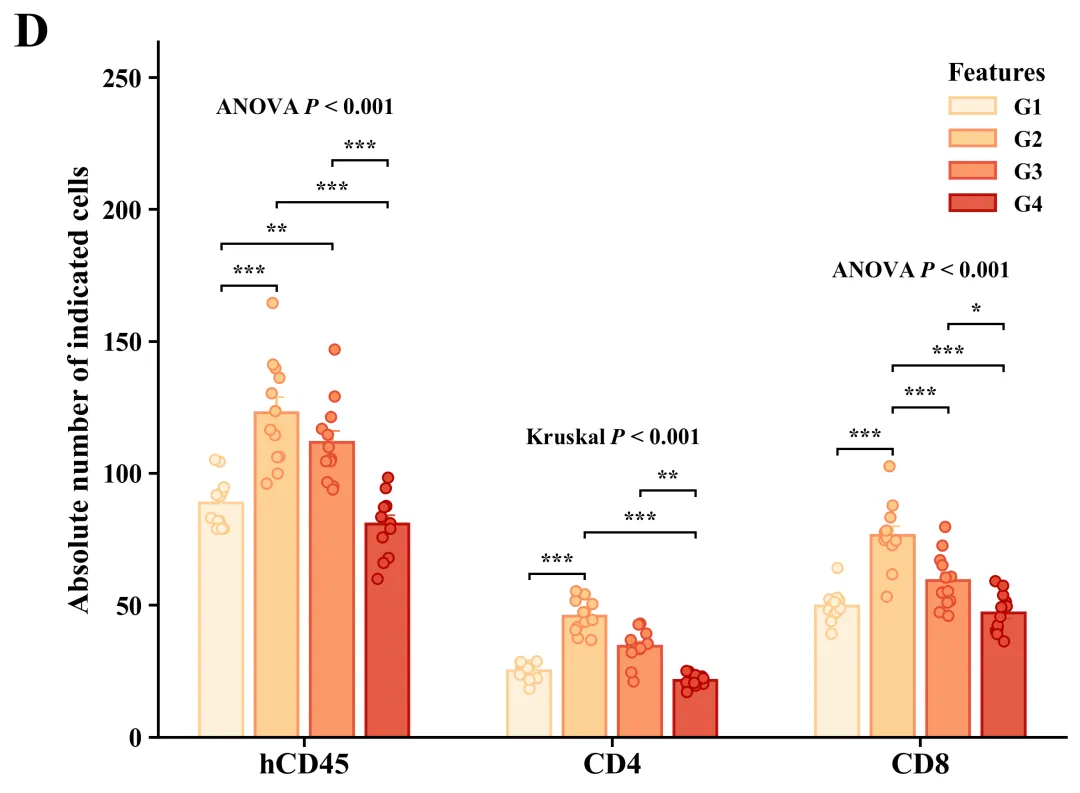




库的导入以及字体设置 

颜色库设置 

绘图函数:画布初始化与坐标计算 

绘图函数:绘制带有误差棒的柱状图与散点图 

绘图函数:边框、图例、刻度等细节设置 

绘图函数:绘制显著性标注线与显著性标注文本 

执行部分:数据读取与描述性统计 

执行部分:正态性检验 

执行部分:方差齐性检验 

执行部分:参数与非参数检验及事后多重检验 

执行部分:绘图 



期刊图片复现|Python绘制二维偏依赖PDP图 期刊复现|python绘制基于SHAP分析和GAM模型拟合的单特征依赖图 期刊图片复现|python绘制带有渐变颜色shap特征重要性组合图(条形图+蜂巢图) 期刊复现|用Python绘制SHAP特征重要性总览图、依赖图、双特征交互效应SHAP图,解锁XGBoost模型的终极奥秘 期刊图片复现|Python绘制shap重要性蜂巢图+单特征依赖图+交互效应强度气泡图+交互效应依赖图(回归+二分类+分类) 

公众号中的所有所有的免费代码都已经下架了,都并入到付费部分里了,付费合集代码和数据的购买通道已经开通,全部合集100元,后续将会持续更新,决定购买请后台私信我,注意只会分享练习数据和代码文件,不会提供答疑服务,代码文件中已经包含了每行代码的完整注释,购买前请确保真的需要!!!
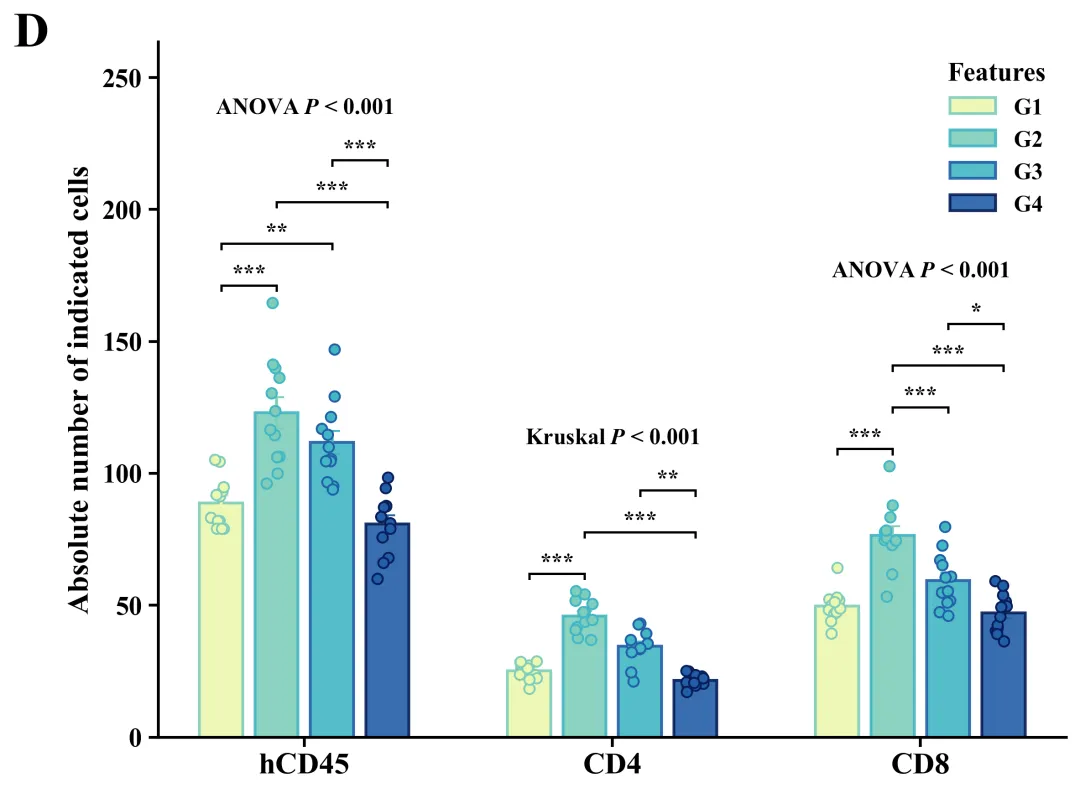
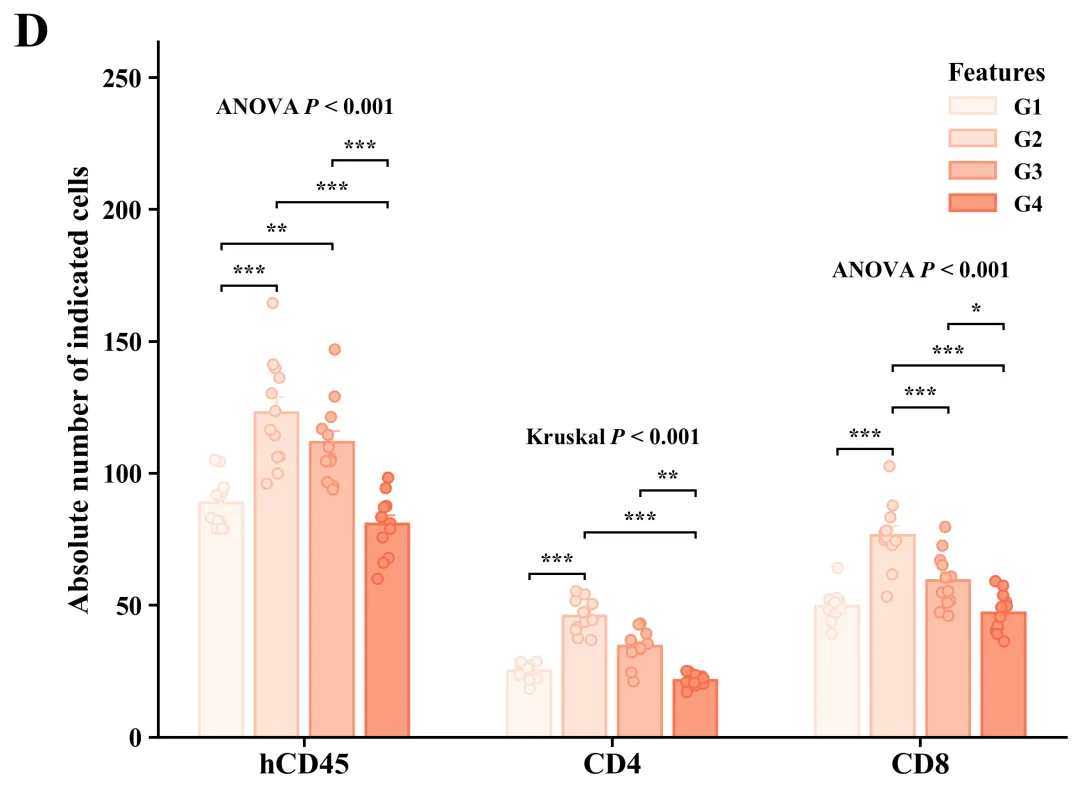
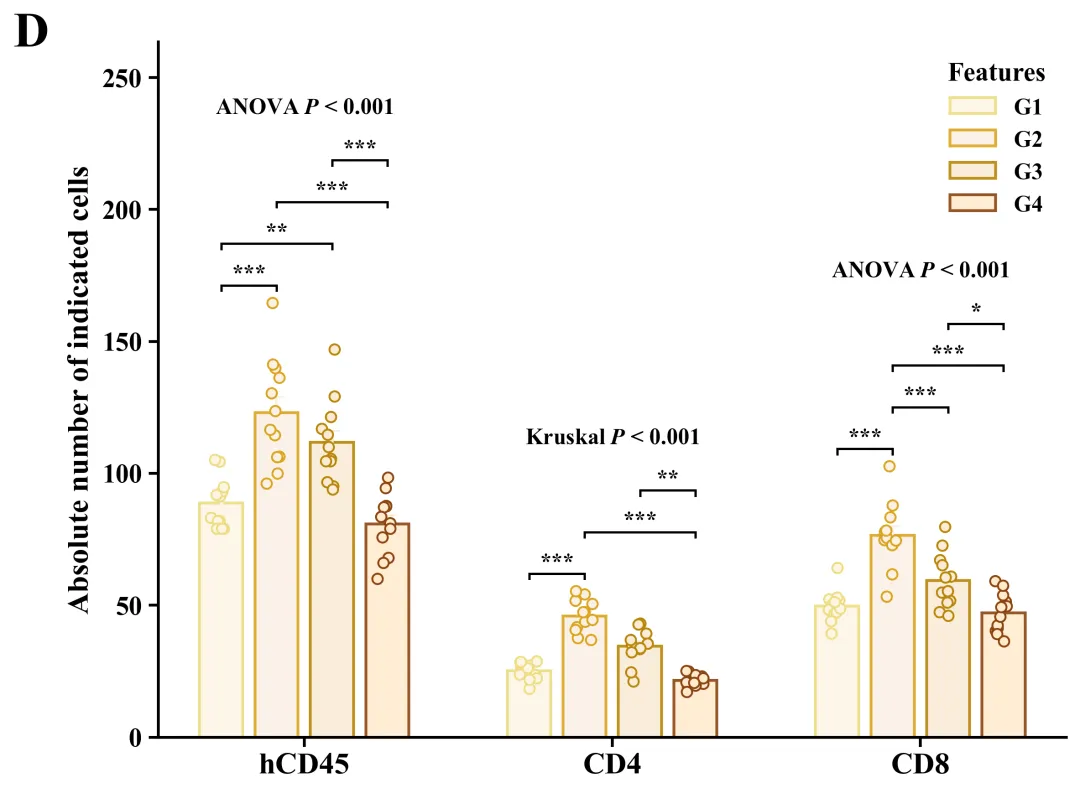
代码绘制成果展示
此图主体由带颜色的实心柱体、垂直误差棒和半透明空心散点叠加而成,其中柱体高度代表各组样本的平均值,误差棒反映了基于当前样本量估算总体均值时的标准误(SEM),而叠加的散点则毫无保留地展示了每个独立样本的实际数值、分布形态及样本量大小。在统计学显著性标注方面,正上方明确标示了全局检验结果,例如“ANOVA P < 0.001”(代表数据满足参数检验前提),而标有“Kruskal P < 0.001”(代表采用了非参数检验),这均表明各分类下的四个分组整体上存在极显著的统计学差异;同时,内部利用带有星号的黑色阶梯状连线清晰标明了事后两两比较的具体差异水平(*代表P < 0.05,代表P < 0.01,代表P < 0.001)。
代码首先从Excel文件载入分组数据并输出描述性统计报告,随后对各组数据依次进行Shapiro-Wilk正态性检验和Levene方差齐性检验;接着依据这两项前提假设的结果进行设置,对满足参数检验条件的数据执行单因素方差分析(ANOVA)及Tukey事后多重比较,对不满足条件的数据则采用非参数的Kruskal-Wallis检验与Dunn事后比较;最终通过分析结果和内置绘制函数进行绘图,并基于内置的60套配色方案,自动化批量绘制出组合图。
代码解释
第一部分
# =========================================================================================# ====================================== 1. 环境设置 =======================================# =========================================================================================import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom scipy.stats import f_oneway, shapiro, levene, kruskalfrom statsmodels.stats.multicomp import pairwise_tukeyhsdimport scikit_posthocs as spimport matplotlib
第二部分
# =========================================================================================# ======================================2.颜色库=======================================# =========================================================================================COLOR_SCHEMES = {1: {'fill': ['#eef3f8', '#e0eff2', '#c0daf0', '#9dabd0'], 'edge': ['#b9d8f7', '#90b8f1', '#6182cc', '#424d95']},}
第三部分
# =========================================================================================# ======================================3.绘图函数=======================================# =========================================================================================def draw_custom_bar_scatter(df, stats_results,scheme_id=1, bar_width=0.14):#创建画布fig, ax = plt.subplots(figsize=(8, 6), dpi=150)groups = df['Group'].unique().tolist() #提取组元素features = df['Feature'].unique().tolist() #提取组内每个住的信息offsets = [(i - (len(features) - 1) / 2) * step for i in range(len(features))] #柱子的X轴中心偏移量x_base = np.arange(len(groups)) #分组位置索引legend_handles = [] #用于保存句柄
第四部分
# 遍历所有特征for i, feat inenumerate(features):bars = ax.bar(x_positions, #xmeans, #ywidth=bar_width, #柱子宽color=face_color, #填充色edgecolor=edge_color, #边缘色linewidth=1.5, #边缘线宽alpha=0.9, #透明度yerr=sems,#误差棒值capsize=4, #误差棒横线error_kw={'elinewidth': 1.5, #误差棒线宽'ecolor': face_color}, #颜色zorder=1 #层)ax.scatter(scatter_x,#xvals, #ycolor=face_color, #填充颜色edgecolor=edge_color, #边缘颜色s=30,#大小alpha=1.0, #透明度linewidth=1.0, #边缘线宽zorder=3 #层)
第五部分
#去掉边框线ax.spines['right'].set_visible(False)ax.spines['top'].set_visible(False)#设置边框粗细ax.spines['left'].set_linewidth(1.5)ax.legend(legend_handles, #句柄features, #文本title='Features', #标题loc='upper right', #位置frameon=False, #去掉边框fontsize=12, #字体大小title_fontsize=14) #图例标题字体大小
第六部分
max_y_global = df['Value'].max() #最大值y_step = max_y_global * 0.08 #控制显著性标注线的位置group_current_y = {} #用于保存每个分组区域当前绘制到的Y轴高度res = stats_results[group] #分析结果ax.plot([x1, x2], [y_pos, y_pos], lw=1.2, color='black') #标注线的基准横线tick_len = y_step * 0.15 #标注线两侧垂直短线长度#绘制垂直线ax.plot([x1, x1], [y_pos - tick_len, y_pos], lw=1.2, color='black')ax.plot([x2, x2], [y_pos - tick_len, y_pos], lw=1.2, color='black')#文本标注ax.text((x1 + x2) * 0.5, #xy_pos, #ysig_text, #显著性文本ha='center', #水平va='bottom', #垂直color='black', #颜色fontsize=12) #字体大小ax.text(group_idx, #xy_pos_omnibus, #yres['omnibus_plot_text'], # 文本ha='center', #水平va='bottom', #垂直fontsize=12, #字体大小fontweight='bold', #加粗color='black') #颜色group_current_y[group] += y_step * 1.2 #更新
第七部分
# =========================================================================================# ======================================4.主程序执行=======================================# =========================================================================================if __name__ == '__main__':data_path = r'data.xlsx' #原始数据df_real_data = pd.read_excel(data_path) #读取groups = df_real_data['Group'].unique().tolist() #组名features = df_real_data['Feature'].unique().tolist() #柱子名print(f"\n{'=' * 50}")print("描述性统计")print(f"{'=' * 50}")#按列进行分组,打印描述性统计量print(df_real_data.groupby(['Group', 'Feature'])['Value'].describe())
第八部分
print(f"\n{'=' * 50}")print("正态性检验 (Shapiro-Wilk)")print(f"{'=' * 50}")group_shapiro_p = {} #记录每个组内最严格的正态性检验P值vals = df_real_data[(df_real_data['Group'] == group) & (df_real_data['Feature'] == feat)]['Value']if len(vals) >= 3:stat, p = shapiro(vals) #正态性检验min_p = min(min_p, p) #最小P值print(f"{group} - {feat}: 统计量={stat:.4f}, P值={p:.4f}")group_shapiro_p[group] = min_p #保存最小P值
第九部分
print(f"\n{'=' * 50}")print("方差齐性检验 (Levene)")print(f"{'=' * 50}")group_levene_p = {} #用于保存方差齐性检验P值feat_vals = [group_df[group_df['Feature'] == f]['Value'].values for f in features if len(group_df[group_df['Feature'] == f]) > 0]if len(feat_vals) >= 2:stat, p = levene(*feat_vals) #进行方差齐性检验,group_levene_p[group] = p #保存print(f"{group}: 统计量={stat:.4f}, P值={p:.4f}")else:group_levene_p[group] = 1.0 #无法检验,默认P值为1
第十部分
print(f"\n{'=' * 50}")print("整体与事后差异检验 (动态选择)")print(f"{'=' * 50}")if len(feature_data) < 2:continue#设置显著性标记if p_omnibus < 0.001:omnibus_sig = "***"omnibus_plot_text = "ANOVA $P$ < 0.001"elif p_omnibus < 0.01:omnibus_sig = "**"omnibus_plot_text = f"ANOVA $P$ = {p_omnibus:.3f}"elif p_omnibus < 0.05:omnibus_sig = "*"omnibus_plot_text = f"ANOVA $P$ = {p_omnibus:.3f}"else:omnibus_sig = "ns"omnibus_plot_text = f"ANOVA $P$ = {p_omnibus:.3f} (ns)"print(f"\n【{group}】 (满足参数检验前提)")print(f" {test_name}: F={stat:.4f} | P值={p_omnibus:.4e} | 显著性={omnibus_sig}")posthoc_pairs = [] #用于存放事后多重比较检验结果if p_adj < 0.001:sig_text = "***"elif p_adj < 0.01:sig_text = "**"elif p_adj < 0.05:sig_text = "*"else:sig_text = "ns"print(f" Tukey事后检验: {feat1} vs {feat2} : P-adj = {p_adj:.4e} | 显著性 = {sig_text}")posthoc_pairs.append((feat1, feat2, reject, sig_text))else:print(" P >= 0.05, 跳过Tukey HSD事后检验。")#不满足正态分布或方差齐性else:stat, p_omnibus = kruskal(*feature_data) #执行非参数的Kruskal-Wallis H检验test_name = "Kruskal" #检验方法# 显著性标记if p_omnibus < 0.001:omnibus_sig = "***"omnibus_plot_text = "Kruskal $P$ < 0.001"elif p_omnibus < 0.01:omnibus_sig = "**"omnibus_plot_text = f"Kruskal $P$ = {p_omnibus:.3f}"elif p_omnibus < 0.05:omnibus_sig = "*"omnibus_plot_text = f"Kruskal $P$ = {p_omnibus:.3f}"else:omnibus_sig = "ns"omnibus_plot_text = f"Kruskal $P$ = {p_omnibus:.3f} (ns)"if p_adj < 0.001:sig_text = "***"elif p_adj < 0.01:sig_text = "**"elif p_adj < 0.05:sig_text = "*"else:sig_text = "ns"print(f" Dunn's事后检验: {feat1} vs {feat2} : P-adj = {p_adj:.4e} | 显著性 = {sig_text}")posthoc_pairs.append((feat1, feat2, reject, sig_text)) #保存结果else:print(" P >= 0.05, 跳过Dunn's事后检验。")#汇总结果stats_results[group] = {'omnibus_plot_text': omnibus_plot_text,'posthoc_pairs': posthoc_pairs}
第十一部分
target_bar_width = 0.14 #柱子宽plot_all = True #是否批量绘图if plot_all:for i in COLOR_SCHEMES.keys():draw_custom_bar_scatter(df_real_data, #原始数据stats_results, #统计结果scheme_id=i, #配色方案bar_width=target_bar_width) #柱子宽else:TARGET_SCHEME = 1draw_custom_bar_scatter(df_real_data, stats_results,scheme_id=TARGET_SCHEME,bar_width=target_bar_width)
如何应用到你自己的数据
1.设置配色方案,执行部分:
data_path = r'\data.xlsx' #原始数据2.读取数据,执行部分:
groups = df_real_data['Group'].unique().tolist() #组名features = df_real_data['Feature'].unique().tolist() #柱子名
3.设置是否进行批量绘图,执行部分:
plot_all = True #是否批量绘图4.设置绘图结果的保存地址,执行部分:
plt.savefig(rf'result_plot_{scheme_id}.png', dpi=300,bbox_inches='tight')推荐
获取方式
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

