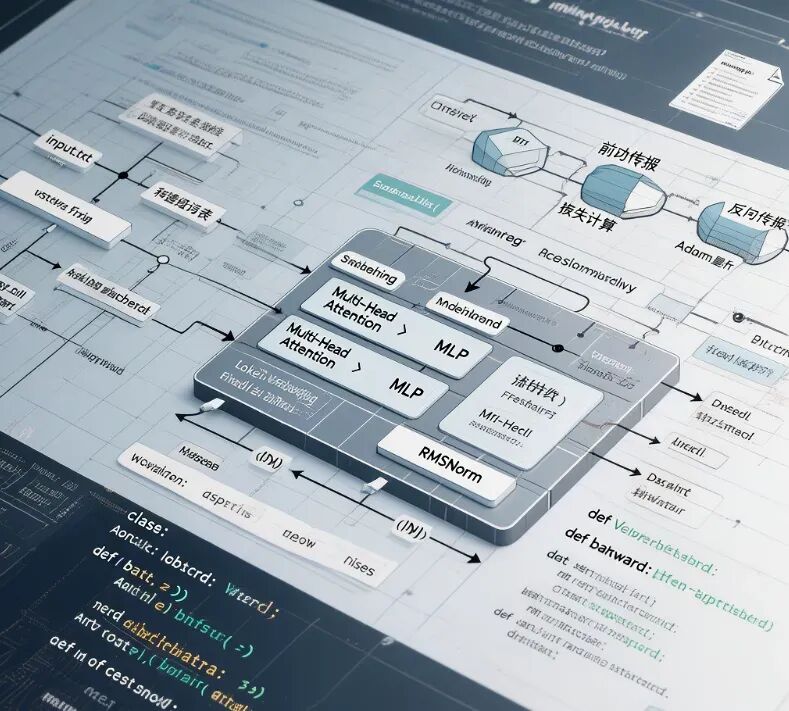
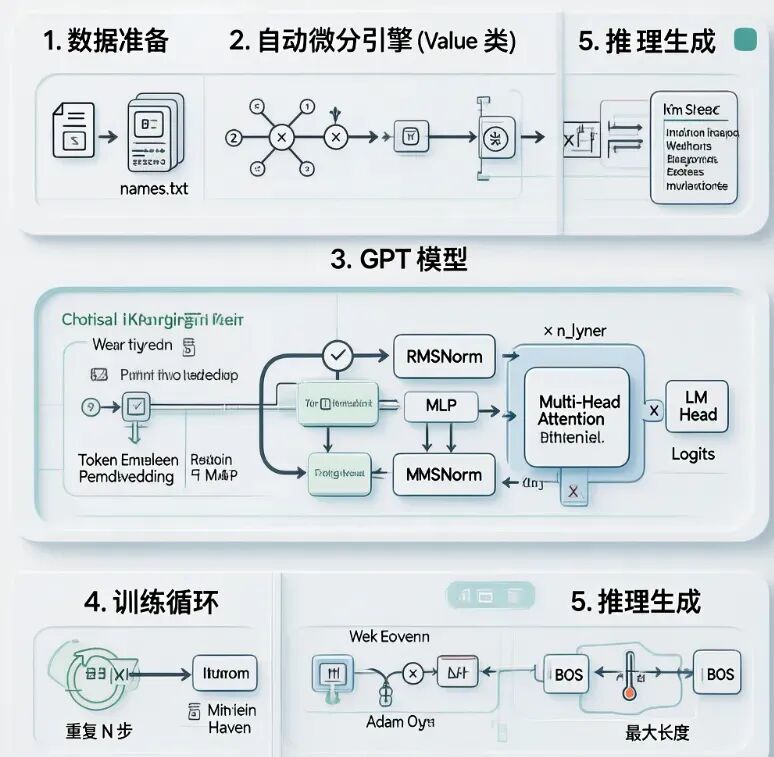
"""The most atomic way to train and run inference for a GPT in pure, dependency-free Python.This file is the complete algorithm.Everything else is just efficiency.@karpathy"""import os # os.path.existsimport math # math.log, math.expimport random # random.seed, random.choices, random.gauss, random.shufflerandom.seed(42) # Let there be order among chaos# Let there be a Dataset `docs`: list[str] of documents (e.g. a list of names)if not os.path.exists('input.txt'): import urllib.request names_url = 'https://raw.githubusercontent.com/karpathy/makemore/988aa59/names.txt' urllib.request.urlretrieve(names_url, 'input.txt')docs = [line.strip() for line in open('input.txt') if line.strip()]random.shuffle(docs)print(f"num docs: {len(docs)}")# Let there be a Tokenizer to translate strings to sequences of integers ("tokens") and backuchars = sorted(set(''.join(docs))) # unique characters in the dataset become token ids 0..n-1BOS = len(uchars) # token id for a special Beginning of Sequence (BOS) tokenvocab_size = len(uchars) + 1 # total number of unique tokens, +1 is for BOSprint(f"vocab size: {vocab_size}")# Let there be Autograd to recursively apply the chain rule through a computation graphclass Value: __slots__ = ('data', 'grad', '_children', '_local_grads') # Python optimization for memory usage def __init__(self, data, children=(), local_grads=()): self.data = data # scalar value of this node calculated during forward pass self.grad = 0 # derivative of the loss w.r.t. this node, calculated in backward pass self._children = children # children of this node in the computation graph self._local_grads = local_grads # local derivative of this node w.r.t. its children def __add__(self, other): other = other if isinstance(other, Value) else Value(other) return Value(self.data + other.data, (self, other), (1, 1)) def __mul__(self, other): other = other if isinstance(other, Value) else Value(other) return Value(self.data * other.data, (self, other), (other.data, self.data)) def __pow__(self, other): return Value(self.data**other, (self,), (other * self.data**(other-1),)) def log(self): return Value(math.log(self.data), (self,), (1/self.data,)) def exp(self): return Value(math.exp(self.data), (self,), (math.exp(self.data),)) def relu(self): return Value(max(0, self.data), (self,), (float(self.data > 0),)) def __neg__(self): return self * -1 def __radd__(self, other): return self + other def __sub__(self, other): return self + (-other) def __rsub__(self, other): return other + (-self) def __rmul__(self, other): return self * other def __truediv__(self, other): return self * other**-1 def __rtruediv__(self, other): return other * self**-1 def backward(self): topo = [] visited = set() def build_topo(v): if v not in visited: visited.add(v) for child in v._children: build_topo(child) topo.append(v) build_topo(self) self.grad = 1 for v in reversed(topo): for child, local_grad in zip(v._children, v._local_grads): child.grad += local_grad * v.grad# Initialize the parameters, to store the knowledge of the modeln_layer = 1 # depth of the transformer neural network (number of layers)n_embd = 16 # width of the network (embedding dimension)block_size = 16 # maximum context length of the attention window (note: the longest name is 15 characters)n_head = 4 # number of attention headshead_dim = n_embd // n_head # derived dimension of each headmatrix = lambda nout, nin, std=0.08: [[Value(random.gauss(0, std)) for _ in range(nin)] for _ in range(nout)]state_dict = {'wte': matrix(vocab_size, n_embd), 'wpe': matrix(block_size, n_embd), 'lm_head': matrix(vocab_size, n_embd)}for i in range(n_layer): state_dict[f'layer{i}.attn_wq'] = matrix(n_embd, n_embd) state_dict[f'layer{i}.attn_wk'] = matrix(n_embd, n_embd) state_dict[f'layer{i}.attn_wv'] = matrix(n_embd, n_embd) state_dict[f'layer{i}.attn_wo'] = matrix(n_embd, n_embd) state_dict[f'layer{i}.mlp_fc1'] = matrix(4 * n_embd, n_embd) state_dict[f'layer{i}.mlp_fc2'] = matrix(n_embd, 4 * n_embd)params = [p for mat in state_dict.values() for row in mat for p in row] # flatten params into a single list[Value]print(f"num params: {len(params)}")# Define the model architecture: a function mapping tokens and parameters to logits over what comes next# Follow GPT-2, blessed among the GPTs, with minor differences: layernorm -> rmsnorm, no biases, GeLU -> ReLUdef linear(x, w): return [sum(wi * xi for wi, xi in zip(wo, x)) for wo in w]def softmax(logits): max_val = max(val.data for val in logits) exps = [(val - max_val).exp() for val in logits] total = sum(exps) return [e / total for e in exps]def rmsnorm(x): ms = sum(xi * xi for xi in x) / len(x) scale = (ms + 1e-5) ** -0.5 return [xi * scale for xi in x]def gpt(token_id, pos_id, keys, values): tok_emb = state_dict['wte'][token_id] # token embedding pos_emb = state_dict['wpe'][pos_id] # position embedding x = [t + p for t, p in zip(tok_emb, pos_emb)] # joint token and position embedding x = rmsnorm(x) # note: not redundant due to backward pass via the residual connection for li in range(n_layer): # 1) Multi-head Attention block x_residual = x x = rmsnorm(x) q = linear(x, state_dict[f'layer{li}.attn_wq']) k = linear(x, state_dict[f'layer{li}.attn_wk']) v = linear(x, state_dict[f'layer{li}.attn_wv']) keys[li].append(k) values[li].append(v) x_attn = [] for h in range(n_head): hs = h * head_dim q_h = q[hs:hs+head_dim] k_h = [ki[hs:hs+head_dim] for ki in keys[li]] v_h = [vi[hs:hs+head_dim] for vi in values[li]] attn_logits = [sum(q_h[j] * k_h[t][j] for j in range(head_dim)) / head_dim**0.5 for t in range(len(k_h))] attn_weights = softmax(attn_logits) head_out = [sum(attn_weights[t] * v_h[t][j] for t in range(len(v_h))) for j in range(head_dim)] x_attn.extend(head_out) x = linear(x_attn, state_dict[f'layer{li}.attn_wo']) x = [a + b for a, b in zip(x, x_residual)] # 2) MLP block x_residual = x x = rmsnorm(x) x = linear(x, state_dict[f'layer{li}.mlp_fc1']) x = [xi.relu() for xi in x] x = linear(x, state_dict[f'layer{li}.mlp_fc2']) x = [a + b for a, b in zip(x, x_residual)] logits = linear(x, state_dict['lm_head']) return logits# Let there be Adam, the blessed optimizer and its bufferslearning_rate, beta1, beta2, eps_adam = 0.01, 0.85, 0.99, 1e-8m = [0.0] * len(params) # first moment bufferv = [0.0] * len(params) # second moment buffer# Repeat in sequencenum_steps = 1000 # number of training stepsfor step in range(num_steps): # Take single document, tokenize it, surround it with BOS special token on both sides doc = docs[step % len(docs)] tokens = [BOS] + [uchars.index(ch) for ch in doc] + [BOS] n = min(block_size, len(tokens) - 1) # Forward the token sequence through the model, building up the computation graph all the way to the loss keys, values = [[] for _ in range(n_layer)], [[] for _ in range(n_layer)] losses = [] for pos_id in range(n): token_id, target_id = tokens[pos_id], tokens[pos_id + 1] logits = gpt(token_id, pos_id, keys, values) probs = softmax(logits) loss_t = -probs[target_id].log() losses.append(loss_t) loss = (1 / n) * sum(losses) # final average loss over the document sequence. May yours be low. # Backward the loss, calculating the gradients with respect to all model parameters loss.backward() # Adam optimizer update: update the model parameters based on the corresponding gradients lr_t = learning_rate * (1 - step / num_steps) # linear learning rate decay for i, p in enumerate(params): m[i] = beta1 * m[i] + (1 - beta1) * p.grad v[i] = beta2 * v[i] + (1 - beta2) * p.grad ** 2 m_hat = m[i] / (1 - beta1 ** (step + 1)) v_hat = v[i] / (1 - beta2 ** (step + 1)) p.data -= lr_t * m_hat / (v_hat ** 0.5 + eps_adam) p.grad = 0 print(f"step {step+1:4d} / {num_steps:4d} | loss {loss.data:.4f}", end='\r')# Inference: may the model babble back to ustemperature = 0.5 # in (0, 1], control the "creativity" of generated text, low to highprint("\n--- inference (new, hallucinated names) ---")for sample_idx in range(20): keys, values = [[] for _ in range(n_layer)], [[] for _ in range(n_layer)] token_id = BOS sample = [] for pos_id in range(block_size): logits = gpt(token_id, pos_id, keys, values) probs = softmax([l / temperature for l in logits]) token_id = random.choices(range(vocab_size), weights=[p.data for p in probs])[0] if token_id == BOS: break sample.append(uchars[token_id]) print(f"sample {sample_idx+1:2d}: {''.join(sample)}")

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
