别让图片请求卡死 GPU:一行 Python 字典换来 16% 吞吐提升的启示
一台 H100 明明还有余量,线上多模态服务却开始排队。工程师盯着显存、算子、量化、批大小看了半天,发现真正拖住吞吐的不是 GPU,而是一个单线程调度循环里的 Python 开销。
这件事很反直觉。很多团队做大模型推理优化时,默认会把注意力放在 CUDA、注意力算子、KV Cache、量化格式、并行策略上。那些当然重要,但多模态模型把图片、视频、文档截图一起塞进请求之后,瓶颈不再只发生在显卡上。图片特征要编码,要跨进程传递,要被调度器识别,要和文本 token 拼到同一个批次里。任何一段主机侧路径变慢,GPU 都会等。
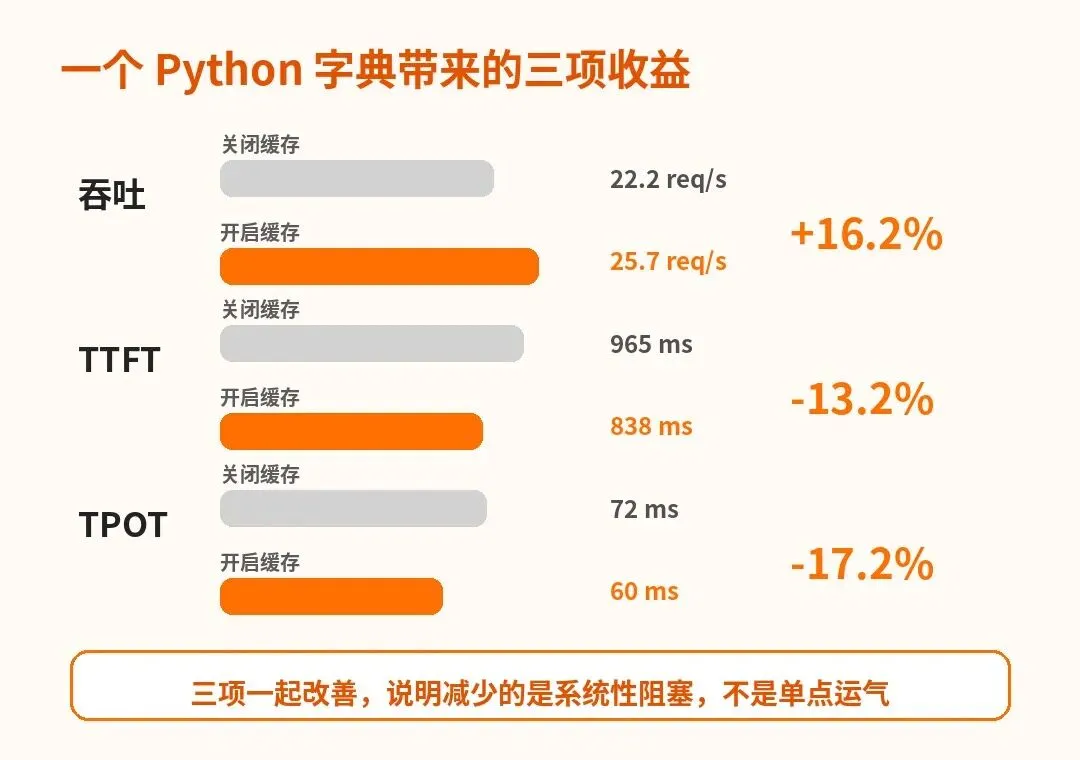
Modal 在 5 月 4 日公开了一次很典型的优化:他们在 SGLang 的多模态调度路径里,用一个 Python 字典缓存 CUDA 共享内存句柄,目标工作负载吞吐从 22.2 req/s 提到 25.7 req/s,提升 16.2%;首 token 平均延迟从 965ms 降到 838ms,下降 13.2%;每 token 平均延迟从 72ms 降到 60ms,下降 17.2%。这个改动已经合入 SGLang v0.5.10。
这不是“Python 字典很神奇”的故事。真正值得拆的是:多模态推理正在把一批过去不显眼的工程细节推到台前。只会调 batch size、只会换更快 GPU 的团队,很容易在 VLM 服务里花大钱买到很一般的吞吐。

别急着怀疑显卡,先看调度器有没有让它空等
大模型推理的黄金规则很朴素:不要让 GPU 等 CPU。
文本模型时代,很多服务路径相对清爽。请求进来,分词,排队,prefill,decode,KV Cache 复用,输出。复杂当然复杂,但输入大多是 token ID,天然有稳定标识。多模态请求变了。图片会被预处理成张量,视觉编码器会产出特征,特征要和文本上下文一起进入模型。调度器不只是把一串 token 放进批次,它还要理解“这个请求携带了哪张图片的哪段特征”。
Modal 的案例里,目标模型是 Qwen2.5-VL-3B-Instruct,硬件是 H100,服务框架是 SGLang。团队用 py-spy 对正在跑的调度器做采样,30 秒拿到大约 3000 个样本。火焰图里,一个叫 process_input_requests 的函数吃掉了大约 13% 的调度器 CPU 时间。继续往下钻,hash_feature 成了可疑点。再往下看,reconstruct_on_target_device 和 torch.UntypedStorage._new_shared_cuda 占了明显时间。
这几个函数名背后,是一个很现实的问题:SGLang 为了让 tokenizer worker 和 scheduler 之间高效共享 GPU 张量,会用 CUDA 进程间通信。不同进程不能像同一个 Python 函数里那样随便传 GPU 指针。它们需要拿到一组元数据:这块张量来自哪个 GPU 内存池、句柄是什么、偏移量在哪里。调度器每次处理多模态输入时,都要把这些信息恢复成自己能识别的对象。
问题出在“每次都恢复”。如果同一个内存池的句柄反复出现,调度器没必要每次都调用底层 CUDA 共享内存重建。把句柄映射缓存起来,下次直接查字典,主机侧开销就降下来了。
听起来太小了,对吧?但调度器是门卫。门卫慢 3%,不是单个请求慢 3% 那么简单。它会卡住整批请求进入 GPU 的节奏。尤其是高并发服务里,GPU 的计算窗口是一段一段被调度器喂出来的。门卫每磨蹭 1ms,后面的 prefill 和 decode 都可能晚 1ms。
这也是很多推理团队误判瓶颈的根源:他们看 GPU 利用率不满,就以为“模型还可以加 batch”;看显存没打满,就以为“硬件没吃满”。可真实原因可能是 CPU 侧调度没把活及时送过去。GPU 不满不是因为它弱,而是因为它饿。
多模态比文本推理更容易踩中主机侧开销
VLM 请求天然比纯文本请求更难批处理。
文本请求的长度差异已经够麻烦了。有人发 50 个 token,有人发 5000 个 token,prefill 和 decode 阶段要动态调度。多模态再加一层:图片尺寸不同、图片数量不同、视觉 token 数不同、预处理耗时不同、特征张量大小不同。一个请求可能只有一张截图,另一个请求可能带 8 张发票扫描件。它们都叫“多模态请求”,但对调度器来说完全不是一类东西。
这会带来三个工程后果。
热路径里多一次“看似便宜”的操作,都会被并发放大
单次 _new_shared_cuda 调用看起来不一定贵。可它处在调度器热路径里,而且调度器通常是单线程循环。热路径里的成本不能按单次函数调用理解,要按“每秒请求数 × 每个请求图片数 × 每张图片特征块数 × 调度周期”理解。
假设线上每秒 25 个请求,每个请求平均 2 张图片,每张图片产生若干共享张量标识。如果每个标识都要走一次底层句柄重建,哪怕单次只多出几百微秒,累积到调度循环里也会把批次提交节奏打乱。Modal 这次看到的 process_input_requests 占 13% 调度器 CPU 时间,就是这种放大效应的直接证据。
这类问题很难靠“加机器”解决。你可以多开副本摊薄流量,但每个副本里的调度器热路径仍然低效。更糟的是,多副本会增加缓存碎片、路由复杂度和冷启动成本。真正的修法是把热路径里的重复工作拿掉。
图片特征没有 token ID,缓存设计必须自己补上
文本 token 有词表 ID。缓存、哈希、匹配都比较自然。图片特征没有这么好的先天条件。系统必须自己给图片特征建立可识别的 ID,才能在 KV Cache、批处理、跨进程共享里追踪它。
Modal 提到的 hash_feature 就处在这条链路上。它的目标不是做业务层图片去重,而是让调度器能低成本识别多模态特征。这里一旦实现粗糙,就会变成所有请求都绕不开的税。
很多团队上线 VLM 时只关心“图片能不能进模型”。但生产系统真正该问的是:图片进模型之后,系统怎么识别它、复用它、跨进程传它、在调度器里追踪它?这些问题没有处理好,模型能跑起来,也跑不经济。
VLM 的吞吐瓶颈经常不是模型本身,而是服务框架还在补课
SGLang 和 vLLM 都在快速补多模态能力。SGLang 的 GitHub 星标已经超过 2.7 万,vLLM 超过 7.9 万,两个项目都在持续更新。PyPI 近期下载数据也能看出推理框架的采用热度:sglang 最近一个月下载量约 2.86 亿,vllm 最近一个月约 936 万。这个数字不能等同于生产部署量,里面有镜像构建、自动化任务、重复下载等噪声,但它能说明一个事实:开源推理框架已经成为大模型生产栈的核心依赖。
问题也在这里。框架越热,越容易被不同场景拉扯。文本、图片、视频、工具调用、长上下文、结构化输出、投机解码,每条路线都要改调度器。多模态不是在成熟文本推理栈上“加一个输入类型”那么简单,它会重写请求生命周期。
Modal 这次优化只改了一个很小的点,却拿到了两位数收益。这说明多模态推理栈里还有大量低垂果实。不是每个团队都要去改 SGLang 源码,但每个做 VLM 服务的人都该意识到:框架默认值不等于生产最优值,官方 benchmark 不等于你的业务负载。
一行缓存背后的真正原则:别在热路径里重复证明同一件事
把 CUDA 共享内存句柄放进 Python dict,本质是一个缓存。
缓存并不高级。高级的是知道该缓存什么、在哪里缓存、什么时候缓存会害人。这次优化缓存的是“句柄到已重建对象”的映射。它适合缓存,因为同一内存池句柄会反复出现,重建动作成本高,映射关系相对稳定,且处在调度器热路径。
很多推理系统慢,不是因为缺少复杂算法,而是因为热路径里充满重复证明:
同一段配置每次请求都解析;同一个 tokenizer 模板每次都重新拼;同一类图片预处理参数每次都算;同一个工具 schema 每次都编译;同一个共享内存句柄每次都重建。
这些动作放在低频路径里没什么。放进调度器、解码循环、批处理组装、KV Cache 查询,就会变成吞吐税。
工程上可以用一个简单规则判断:如果某个函数同时满足“每个请求都会走”“单线程或串行执行”“输出由少量稳定输入决定”“失败会拖住批处理”,它就应该被重点审查。不要等 GPU profiler 告诉你答案。GPU profiler 只能告诉你显卡在干什么,它不能告诉你显卡为什么没活干。
这也是 py-spy 在这类问题上好用的原因。它不需要侵入服务,不需要重编译,不需要把线上路径改得面目全非。对 Python 调度器采样 30 秒,就能看到 CPU 时间花在哪里。很多团队一上来就打开 Nsight Compute,分析 warp stall、memory coalescing、kernel occupancy。那些工具很强,但如果瓶颈在 Python 调度器里,先看 CUDA 反而会绕远路。
如果你在做 VLM 服务,应该这样排查
下面这套流程适合已经能跑通 VLM 推理、但吞吐和延迟不稳定的团队。它不是论文式优化,而是线上排障顺序。
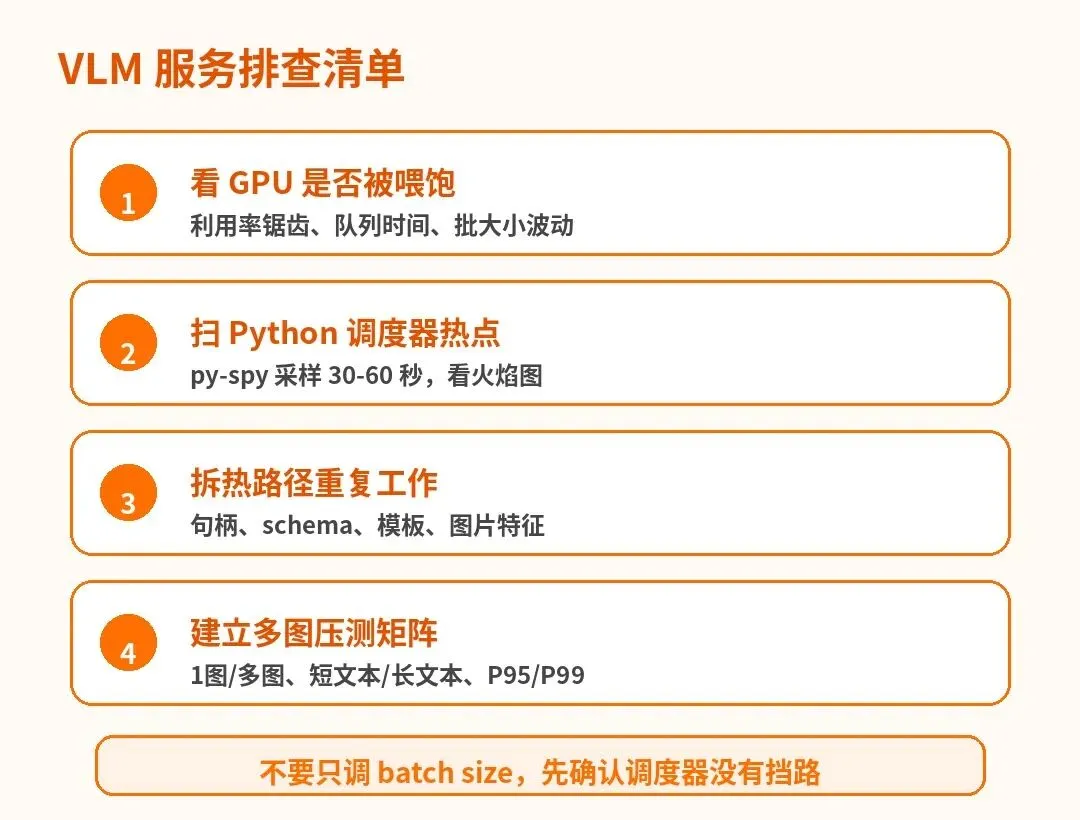
看 GPU 是否真的被喂饱
不要只看平均 GPU 利用率。平均值会掩盖“周期性空等”。你需要看更细的时间窗口:每 100ms 或 1s 的利用率波动、prefill/decode 间隔、批大小变化、队列长度变化。
如果现象是 GPU 利用率锯齿明显、请求队列有积压、CPU 某个进程单核打满,优先怀疑调度器或预处理路径。特别是 VLM 服务里,tokenizer worker、image processor、scheduler 之间的交接很容易成为瓶颈。
实操上可以同时采集四类指标:
- 请求入口 QPS、排队时间、超时率;
- 调度器循环耗时、每轮处理请求数、批大小;
- GPU 利用率、显存占用、prefill/decode 时间;
- 预处理耗时、图片尺寸分布、每请求图片数量。
这四类指标放在同一条时间轴上,问题会清楚很多。GPU 空等发生时,如果调度器循环也变慢,就不要再盲目调 CUDA 参数。
用 py-spy 先扫 Python 热点
如果推理框架的调度器是 Python 写的,py-spy 是低成本入口。Modal 的做法就是对运行中的 SGLang scheduler 采样 30 秒,拿火焰图看 process_input_requests 这种热点函数。
可执行命令大致长这样:
py-spy record -p <scheduler_pid> -o scheduler.svg --duration 30
采样时要用真实流量或尽量接近真实的压测流量。不要用单请求测试骗自己。很多多模态瓶颈只有在并发、批处理、跨进程共享同时发生时才暴露。
看火焰图时,重点找三类函数:
- 调度器组 batch、处理输入、查询缓存的函数;
- 图片特征哈希、张量重建、跨进程共享相关函数;
- 反复做字符串、JSON、模板、schema 处理的函数。
如果某个函数占调度器 CPU 时间超过 5%,就值得追。超过 10%,基本不用犹豫。Modal 的 process_input_requests 大约 13%,已经足够解释吞吐不佳。
把热路径拆成“必须做”和“重复做”
优化不是见到热点就缓存。要先判断它为什么热。
有些热是必须的,比如模型前向、必要的 token 采样、不可避免的队列管理。有些热是重复做同一件事,比如同一个共享句柄反复重建、同一份 schema 反复编译、同一张图片在重试中反复预处理。
排查时可以给每个热点函数写三列:输入是否稳定、输出是否可复用、复用是否有一致性风险。三列都通过,才考虑缓存。
以这次共享内存句柄为例,输入是句柄和偏移,输出是调度器可用的共享对象。句柄来自内存池,重复出现概率高。缓存后如果生命周期管理正确,就能避免每次调用 _new_shared_cuda。收益来自减少主机侧重复 book-keeping,而不是改变模型计算。
反过来,某些图片预处理结果就不能乱缓存。用户上传图片可能带权限边界,缓存键可能撞,图像增强参数可能随请求变化,缓存生命周期可能造成显存泄漏。缓存本身不是答案,热路径里的稳定重复工作才是答案。
小优化为什么能带来 10% 以上收益
很多人看到“Python dict”会低估这次优化,因为它不像新算子、新量化、新 speculative decoding 那样有技术光环。
但线上推理系统的效率,常常由最窄的串行段决定。Amdahl 定律在这里很残酷:如果调度器里某段串行开销挡住批处理提交,哪怕 GPU 计算再快,整体吞吐也会被它拖住。Modal 的数据里,吞吐提升 16.2%,TTFT 下降 13.2%,TPOT 下降 17.2%,说明被移除的不只是一个局部函数成本,而是调度节奏上的阻塞。
TTFT 下降尤其值得看。首 token 延迟包含请求进入系统、预处理、调度、prefill 等链路。共享句柄缓存能影响 TTFT,意味着它发生在请求早期路径,并且会推迟请求进入 GPU 的时间。TPOT 也下降,说明 decode 阶段的批处理节奏同样受益。调度器更快,批次形成更顺,GPU 空等减少,每个 token 的平均产出时间自然下降。
这里有一个对工程团队很有用的判断:如果某个优化同时改善吞吐、TTFT 和 TPOT,它大概率不是单点运气,而是减少了系统性阻塞。单纯调大 batch size 往往会改善吞吐但伤害 TTFT;单纯减少输出长度会改善 TPOT但不一定改善吞吐。三者一起改善,通常意味着热路径被打通了。
不要把这篇文章读成“都去改 SGLang 源码”
大多数团队不需要自己维护推理框架分支。直接升级到包含改动的 SGLang v0.5.10,或者关注框架版本变更,就能吃到一部分红利。
但如果你的业务已经把 VLM 放到生产环境,光升级不够。你还需要建立自己的性能基线。原因很简单:Modal 的目标工作负载是 Qwen2.5-VL-3B-Instruct、H100、多模态流量、特定调度路径。你的模型可能是 7B、32B,图片可能来自文档扫描、网页截图、视频抽帧,硬件可能是 L40S、A100 或国产卡。优化方向相同,不代表收益数字相同。
更可靠的做法是建立一套版本升级前后的固定压测:
- 固定模型、固定服务参数、固定并发曲线;
- 固定图片数量分布,比如 1 张、3 张、8 张三组;
- 固定图片分辨率分布,比如 720p、1080p、长截图三组;
- 同时记录吞吐、TTFT、TPOT、队列时间、调度器 CPU、GPU 利用率;
- 每次升级 SGLang、vLLM、Transformers、CUDA、驱动都跑同一套。
没有这套基线,团队会陷入玄学调参。今天改 batch size,明天换 quantization,后天调 tokenizer worker 数量,线上波动一来,没人知道到底是哪次改动造成的。
一个可以直接照抄的 VLM 压测矩阵
为了让这件事能落地,可以把 VLM 服务压测分成 4 个场景。
场景一:短文本加单图。模拟用户上传一张截图问问题。这个场景看 TTFT 和图片预处理成本,适合发现入口链路瓶颈。
场景二:长文本加单图。模拟代码截图、网页截图、文档页问答。这个场景会把文本上下文和视觉 token 混在一起,适合观察 prefill 压力。
场景三:短文本加多图。模拟票据批量识别、商品对比、界面状态分析。这个场景最容易暴露图片特征管理、跨进程共享、调度器 book-keeping 的成本。
场景四:长文本加多图。模拟真实企业文档、复杂代理任务、带上下文的视觉分析。这是压力最大也最接近生产事故的场景。
每个场景至少跑 3 档并发,比如 4、16、64。每档跑 10 分钟,不要只跑 30 秒。记录 P50、P95、P99,而不是只看平均值。多模态服务的平均值经常骗人,真正杀用户体验的是 P95 后面的长尾。
如果你只能加一个指标,我建议加“调度器每轮循环耗时”。这个指标比单看 GPU 利用率更能解释问题。调度器循环稳定,GPU 才可能稳定。调度器抖,GPU 再贵也会跟着抖。

这次优化给开发者的三个判断
小模型不代表服务简单
Qwen2.5-VL-3B-Instruct 不是巨型模型。很多团队会以为 3B 级别 VLM 更容易服务化,事实没这么简单。小模型计算压力低,反而更容易把系统瓶颈暴露到 CPU、调度器、预处理、网络和队列上。
当模型足够大时,GPU 计算本身可能盖住很多主机侧低效。模型变小、请求变多、延迟目标更激进后,主机侧每一点浪费都会变明显。所以“换小模型降成本”后,别忘了重新做端到端剖析。你省下的 GPU 计算,可能被调度器开销吃回去一部分。
多模态代理会放大这个问题
Modal 提到用户会用大 VLM 支撑能看见应用界面的多模态编码代理。这个方向正在变热:代理不再只读代码和日志,还要看浏览器截图、设计稿、终端截图、报错弹窗。一次任务可能连续发几十张图。
这类负载和普通聊天完全不同。它的请求更密集,图片更多,重复上下文更多,长尾更明显。代理还会重试、分支、并行调用工具。VLM 服务一旦调度器卡住,上层代理就会误判为工具慢、页面慢、模型慢,进而触发更多重试,把系统拖得更糟。
所以做多模态代理基础设施时,VLM 推理不是“接一个视觉模型接口”那么简单。它需要和任务队列、截图缓存、上下文压缩、重试策略一起设计。否则你会在上层做很多补丁,掩盖底层推理服务不稳定。
开源推理框架会继续卷到细枝末节
过去一年,大家关注的是大块能力:PagedAttention、连续批处理、KV Cache、量化、并行、投机解码。接下来,很多收益会来自更细的工程路径:调度器热循环、跨进程共享、前处理流水线、schema 编译缓存、多模态特征复用。
这对使用者是好事,也是提醒。好事是框架升级会持续带来免费性能;提醒是你必须知道自己依赖的框架到底改了什么。SGLang v0.5.10 的一个小优化可能让你的 VLM 服务延迟下降,也可能对你的负载没明显影响。你不测,就不知道。
可执行建议:今天就能做的 6 件事
把 VLM 服务跑稳,不需要一上来就写 CUDA。更现实的动作是下面 6 件。
一,给线上服务补齐 TTFT、TPOT、队列时间、调度器循环耗时。没有这些指标,所有优化都是猜。
二,用 py-spy 对调度器采样。不要等事故发生。找一个高峰期或压测窗口,采 30 到 60 秒,看看 Python 时间花在哪里。
三,把图片输入按数量和分辨率分桶。不要只统计平均图片数。多图请求和长截图请求往往贡献了大部分长尾。
四,升级 SGLang 时单独跑多模态压测。不要用纯文本 benchmark 代表 VLM。纯文本跑得漂亮,多图请求照样可能崩。
五,检查热路径里的重复工作。重点看 schema、模板、图片特征、共享内存句柄、tokenizer 配置、图像预处理参数。能安全缓存的,放到热路径外。
六,给上层代理设置视觉请求预算。不要让代理无限截图、无限重试、无限多图提交。推理服务再快,也经不起上层乱用。
真正的结论
多模态推理的难点,不只是“模型能看图”。生产环境真正要解决的是:图片进入系统后,如何被预处理、识别、共享、调度、缓存,并且不让 GPU 等它。
Modal 这次优化的价值,不在于它用了 Python dict,而在于它提醒所有做 VLM 的团队:性能事故可能藏在最不起眼的主机侧 book-keeping 里。吞吐提升 16.2%、TTFT 下降 13.2%、TPOT 下降 17.2%,背后不是玄学,而是热路径少做了重复工作。
未来几个月,VLM 服务会进入更多代理、文档、客服、研发工具和数据处理场景。真正能把成本压下来的团队,不会只盯着模型榜单和 GPU 型号。他们会盯调度器,盯火焰图,盯每一段热路径里的重复工作。
一句话:别让图片请求卡死 GPU。VLM 推理优化的下一块硬骨头,正在 CPU 调度器里。

