在回归数据分析中,很多同学做完回归预测之后,最先关注的往往是 R²、RMSE、MAE 这些数值指标。这些指标当然重要,因为它们能帮助我们快速判断模型整体效果好不好。但是,如果我们只停留在“看指标”这一步,就会遗漏很多更细致的信息。真实值-预测值散点图 出现得非常频繁。它的优点很直接:一眼就能看到模型预测点是不是围绕理想参考线分布,也能看出样本在不同数值区间的误差特征。如果我们再把多个模型放到同一张图里,用统一坐标范围和统一绘图规则进行对比,那么这张图的表达力就会更强。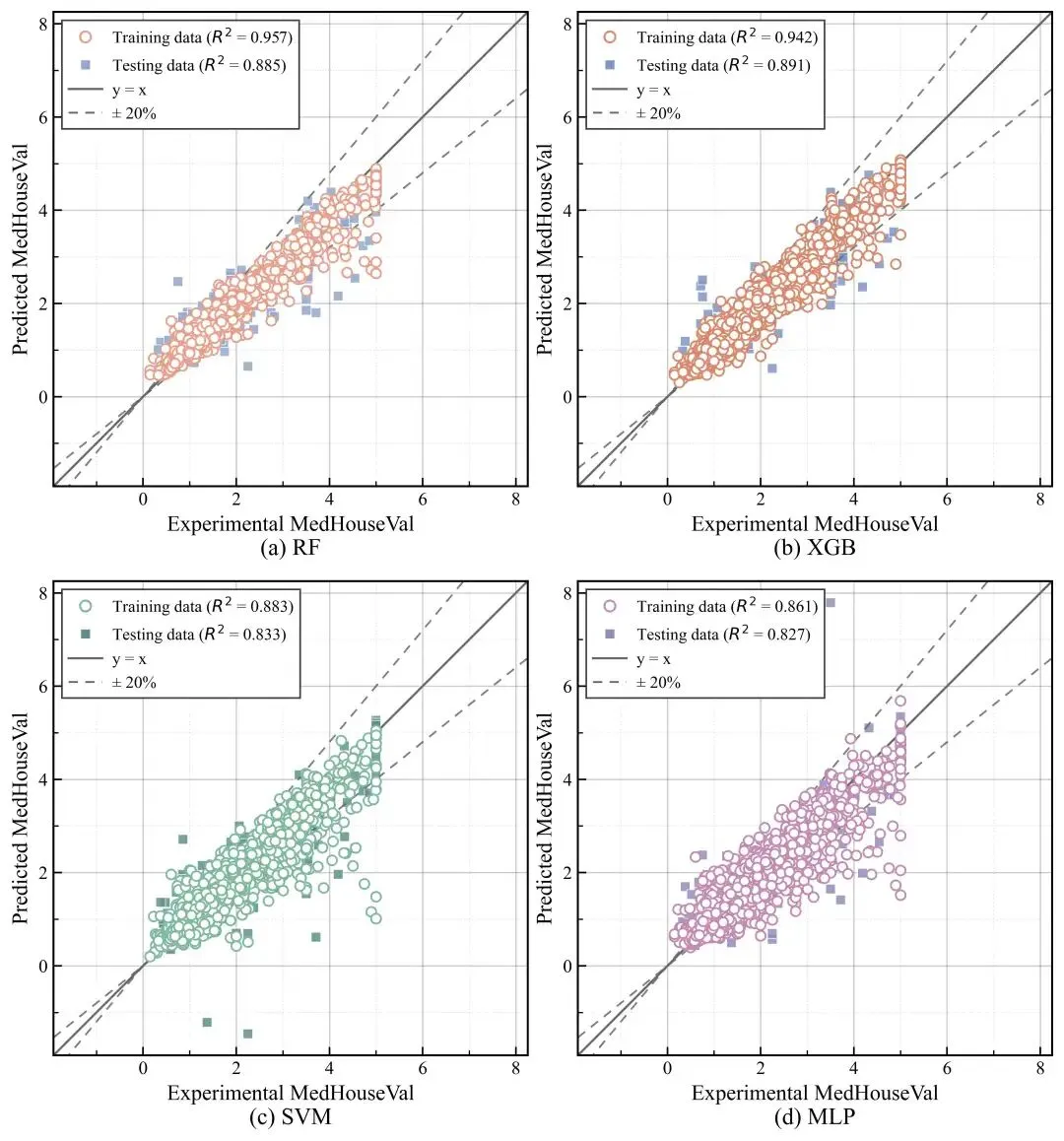
1. 为什么要画四模型散点对比图
从科研展示的角度看,单一模型图通常只能回答“这个模型表现如何”这个问题,而多模型对比图能进一步回答“在同一数据集、同一训练测试划分下,谁更稳、谁更准、谁偏差更小”这类问题。
第一步,读取同一个回归数据集;第二步,划分同一套训练集和测试集;第三步,分别训练 RF、XGB、SVM 和 MLP;第四步,把四个模型的预测结果画成四个子图,并统一坐标范围、参考线、网格、图例和字体样式。
2. 数据读取与训练测试集划分
先读取 回归样本.csv,然后识别目标列。这里目标列默认设置为 MedHouseVal,如果数据表结构稍有变化,也可以自动回退到最后一列作为目标变量。然后使用 train_test_split 划分训练集和测试集,并通过固定随机种子保证每次运行的结果具有可重复性。
from pathlib import Pathimport pandas as pdfrom sklearn.model_selection import train_test_splitBASE_DIR = Path(__file__).resolve().parentDATASET_FILENAME = "回归样本.csv"TARGET_COL = "MedHouseVal"TEST_SIZE = 0.2RANDOM_STATE = 42csv_path = BASE_DIR / DATASET_FILENAMEdata_frame = pd.read_csv(csv_path)target_col = TARGET_COL if TARGET_COL in data_frame.columns else data_frame.columns[-1]X = data_frame.drop(columns=[target_col])y = data_frame[target_col]X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=TEST_SIZE, random_state=RANDOM_STATE,)
这段代码看起来很基础,但在科研作图里非常关键。因为如果你准备做多模型比较,所有模型必须建立在同样的数据切分之上。否则,某个模型指标更高,可能只是因为那次切分里测试集碰巧更“容易”,并不能说明模型本身真的更优。
3. 模型定义与参数设置
定义了四类回归模型:随机森林 RF、梯度提升树 XGB、支持向量回归 SVM 和多层感知机 MLP。这些模型的特点不同,所以参数设置也不一样。为了让代码更清晰,脚本把每个模型的重要参数都整理成了字典,这种写法比直接把参数塞进模型类里更适合科研复现和后期维护。
RF_PARAMS = {"n_estimators": 500,"criterion": "squared_error","max_depth": None,"min_samples_split": 4,"min_samples_leaf": 2,"max_features": "sqrt","bootstrap": True,"oob_score": True,"n_jobs": -1,"random_state": 42,}XGB_PARAMS = {"n_estimators": 500,"learning_rate": 0.03,"max_depth": 4,"min_child_weight": 3,"subsample": 0.85,"colsample_bytree": 0.85,"objective": "reg:squarederror","random_state": 42,"n_jobs": -1,}
RF 的优势是鲁棒性强、对异常值和变量尺度相对不那么敏感,通常适合作为一种稳定的基线模型。XGB 则更偏向精细拟合,往往在结构化表格数据上能取得更好的精度,但也更容易出现参数不合理导致的过拟合。把这两个树模型放在一起比较,通常就能看出“稳定”和“精细”之间的差异。
对于 SVM 和 MLP,脚本使用了 Pipeline + StandardScaler 的方式。这样做的原因是,这两类模型对特征尺度更加敏感。如果各个输入特征的数量级相差很大,那么模型训练过程会受到明显影响。因此,标准化几乎是这类模型的常规操作。
from sklearn.pipeline import Pipelinefrom sklearn.preprocessing import StandardScalerfrom sklearn.svm import SVRfrom sklearn.neural_network import MLPRegressorSVM_MODEL = Pipeline([ ("scaler", StandardScaler()), ("model", SVR(C=120, epsilon=0.05, kernel="rbf", gamma="scale")),])MLP_MODEL = Pipeline([ ("scaler", StandardScaler()), ("model", MLPRegressor( hidden_layer_sizes=(128, 64, 32), activation="relu", solver="adam", max_iter=2500, early_stopping=True, random_state=42, )),])
4. 模型训练后计算训练集和测试集指标
很多同学会直接拿测试集指标作图,这样做并没有错,但如果希望图更有分析深度,仅展示测试集信息是不够的。因为训练集和测试集之间的差异,本身就包含了模型泛化能力的重要线索。脚本中在训练完模型后,同时对训练集和测试集做预测,并分别计算 R² 和 RMSE。
import numpy as npfrom sklearn.metrics import mean_squared_error, r2_scoremodel.fit(X_train, y_train)train_pred = model.predict(X_train)test_pred = model.predict(X_test)r2_train = r2_score(y_train, train_pred)r2_test = r2_score(y_test, test_pred)rmse_train = np.sqrt(mean_squared_error(y_train, train_pred))rmse_test = np.sqrt(mean_squared_error(y_test, test_pred))
这里的逻辑很值得在文章里强调。比如,如果训练集 R² 特别高,而测试集 R² 明显下降,那么就说明模型在训练样本上学得很“满”,但在未知样本上的推广能力一般,这通常是过拟合的一种表现。反过来,如果训练集和测试集 R² 比较接近,那么即使指标不是全场最高,也可能说明模型更加稳定。
图例可以显示训练集和测试集的 R²,而不用额外手工写注释。这是一个很适合科研绘图的思路:尽量让数值结果和图形对象挂钩,避免后续修改模型时忘了同步更新图中文字。
5. 真正让图“有论文感”的,是统一尺度和参考线设计
如果要比较四个模型,仅仅把四张散点图拼在一起还不够。更重要的是让四张图共享同一套视觉规则。脚本里有两个非常关键的设计:第一,统一四个子图的坐标范围;第二,统一加入 y = x 和 ±20% 两类参考线。
先看统一坐标范围的实现。脚本会收集所有模型的训练集和测试集预测值,再和真实值一起计算全局最小值与最大值,最后给四个子图设置完全一致的坐标轴范围。
defbuild_global_limits(y_train, y_test, results): all_true = np.concatenate([y_train.to_numpy(), y_test.to_numpy()]) prediction_arrays = []for result in results.values(): prediction_arrays.append(result["train_pred"]) prediction_arrays.append(result["test_pred"]) all_pred = np.concatenate(prediction_arrays) global_min = min(all_true.min(), all_pred.min()) global_max = max(all_true.max(), all_pred.max()) padding = (global_max - global_min) * 0.05 limit_min = 0if global_min >= 0else global_min - padding limit_max = global_max + paddingreturn limit_min, limit_max
这一步的意义在于,防止每个子图单独缩放以后给读者造成视觉错觉。假设某个模型预测波动很大,但因为坐标轴自动放大,它在图上依然可能显得“挺集中”;另一个模型明明更稳定,却因为坐标轴更紧看起来反而更散。统一坐标范围,就是为了避免这种误导。
另外,y = x 这条线代表理想预测状态,也就是“预测值完全等于实验值”。如果大部分点都靠近这条线,说明模型预测整体较好。±20% 虚线则能帮助我们快速判断样本点落在一个可接受误差区间之内的比例,这种表达在工程材料、地学、环境和土木方向都很常见。
ax.plot(x_line, x_line, color=LINE_COLOR, linewidth=1.3)ax.plot(x_line, 1.2 * x_line, color=LINE_COLOR, linewidth=1.1, linestyle=(0, (5, 4)), alpha=0.85)ax.plot(x_line, 0.8 * x_line, color=LINE_COLOR, linewidth=1.1, linestyle=(0, (5, 4)), alpha=0.85)
6. 让四张图更好看、更易读:配色、图例和版式细节
科研绘图里最容易被忽视的,其实是图形的“可读性”。同样的数据,如果配色、图例、点型和子图排布处理得不好,读者会觉得图很乱;如果这些细节处理得合适,即使没有额外解释,读者也能很快看懂。
首先,每个模型都设置了单独的训练集和测试集颜色,这样四个子图不会显得完全一样。训练集用空心圆,测试集用带填充的方块,这种组合在科研图里很常见,因为它能同时区分“样本类型”和“模型颜色”两层信息。
ax.scatter( y_test, result["test_pred"], s=34, marker="s", c=test_color, edgecolors="white", linewidths=0.5, alpha=0.85, zorder=2,)ax.scatter( y_train, result["train_pred"], s=34, marker="o", facecolors="white", edgecolors=train_color, linewidths=1.1, alpha=1.0, zorder=3,)
其次,图例不是简单写“Training data”和“Testing data”,而是直接把对应的 R² 放进图例文字里。这样读者不需要来回对照图和表,就能马上知道这个子图对应的训练效果和测试效果分别如何。
defcreate_legend_handles(train_color, test_color, r2_train, r2_test):return [ Line2D(..., label=f"Training data ($R^2$ = {r2_train:.3f})"), Line2D(..., label=f"Testing data ($R^2$ = {r2_test:.3f})"), Line2D(..., label="y = x"), Line2D(..., label="± 20%"), ]
最后,脚本还对坐标轴、网格线、边框粗细、字体、子图间距做了统一设置。比如采用 Times New Roman,适合论文风格;主网格和次网格透明度不同,让背景更柔和;坐标轴 set_aspect("equal") 保证横纵比例一致,这样 y = x 看起来才是真正的 45 度线。
7. 小结
这份代码实现的,并不仅仅是一张四模型散点图。更准确地说,它展示了一套比较完整的科研绘图思路:
- 同时计算训练集和测试集指标,让图不只是“看上去不错”,而是真有分析价值。
- 最后通过配色、图例和排版优化,让结果更接近期刊风格。
现在绘图代码都不支持免费获取了,20/篇文章。同时欢迎加入小编科研绘图VIP群,268/年,所有科研绘图相关文章代码免费获取,涵盖机器学习模型(回归和分类)的shap分析、还有各种如皮尔逊分析等相关的图,以及期刊复现图,源代码直接复制或者打开就能绘图。同时进群赠送SHAP科研分析软件6.0(文本版),且免费更新使用。VX:GISyanjiushengya!!
科研软件 | 基于机器学习+SHAP的科研分析软件(文本版,SHAP6.0)

