摘要:在Linux服务器运维中,有一种场景极具迷惑性:系统响应骤降,CPU和内存指标却一片“祥和”。真正的元凶,往往是被忽视的磁盘IO。当大量读写请求堵塞在I/O通道,即便处理器再强劲,系统也只能陷入低效等待。本文直击痛点,不讲空话:先详解iostat与iotop两款核心工具的关键指标与实用技巧;再给出三个可直接落地的Shell脚本(自动定位高IO进程、持续记录瓶颈日志、实现阈值告警联动)。助你从“凭经验猜测”转向“靠数据说话”,真正掌控磁盘性能命脉。
一、先摸清“堵点”:两款命令行工具
1.iostat:看整体“路况”
(1)安装(sysstat包):
执行指令# yum install sysstat -y# CentOS/RHEL
# 在Ubuntu/Debian系统中使用以下命令进行安装
执行指令# apt install sysstat -y
(2)常用命令:
iostat -x 1 3# 每秒刷新一次,共3次,显示扩展信息
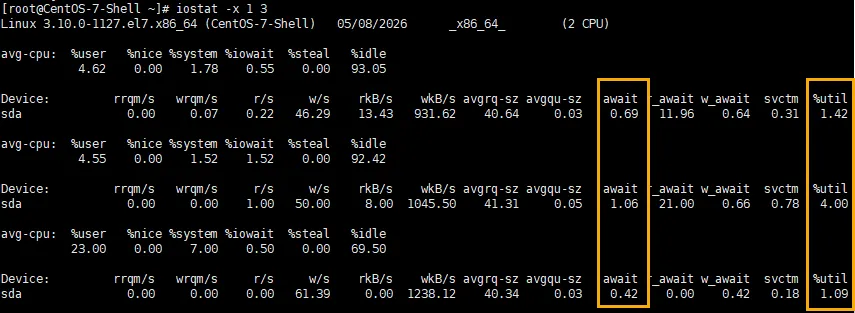
重点看两列:
%util:磁盘繁忙程度。超过80%说明磁盘快忙不过来了。
await:I/O请求的平均等待时间(毫秒)。数值越大,响应越慢。
备注:比如如果发现数据库服务器的%util长期100%,await超过50ms,就该考虑换SSD或优化查询了。
2.iotop:看谁在“抢道”
如果说iostat看的是整体拥堵,iotop就像路口的监控摄像头,能直接拍到是哪个进程在疯狂读写。
(1)安装:
yum install iotop -y# 或 apt install iotop
(2)运行:
iotop -o# 只显示有IO活动的进程
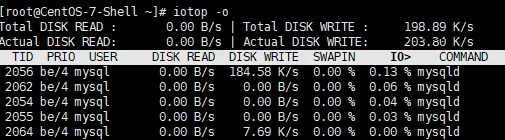
按下方向键进行排序,可以清晰看到:可能是某个日志进程在疯狂写盘,或是数据库在做全表扫描。找到“元凶”后,结合kill或调整业务逻辑即可缓解。
二、实战脚本:让监控自动化
光用手敲命令不够高效。下面三个脚本,能帮你把IO监控融入日常工作,高效的管理Linux系统。
1.一键检查磁盘健康(发现繁忙盘)
(1)编写脚本程序check_disk.sh
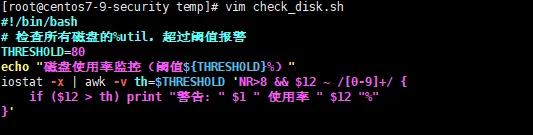
真实代码如下:
#!/bin/bash
# 检查所有磁盘的%util,超过阈值报警
THRESHOLD=80
echo "磁盘使用率监控(阈值${THRESHOLD}%)"
iostat -x | awk -v th=$THRESHOLD 'NR>8 && $12 ~ /[0-9]+/ {
if($12 > th) print "警告: " $1 " 使用率 " $12 "%"
}'
(2)授权后运行脚本程序check_disk.sh

备注:保存为check_disk.sh,执行后可直接告诉你是哪块盘(如sda)压力过大。
2.定位“罪魁祸首”进程
(1)编写脚本iotop.sh
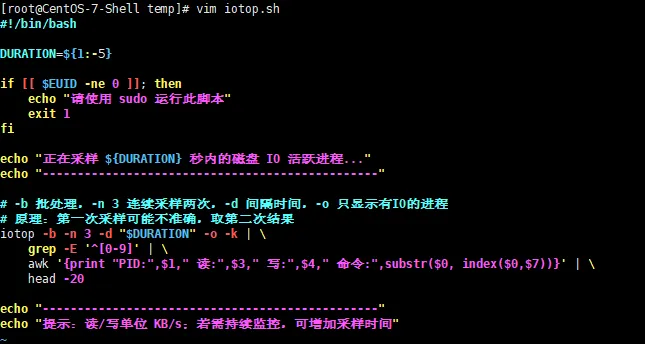
真实代码如下:
#!/bin/bash
DURATION=${1:-5}
if [[ $EUID -ne 0 ]]; then
echo"请使用 sudo 运行此脚本"
exit1
fi
echo "正在采样 ${DURATION} 秒内的磁盘 IO 活跃进程..."
echo "------------------------------------------------"
# -b 批处理,-n 3 连续采样两次,-d 间隔时间,-o 只显示有IO的进程
# 原理:第一次采样可能不准确,取第二次结果
iotop -b -n 3 -d "$DURATION" -o -k | \
grep-E '^[0-9]' | \
awk'{print "PID:",$1," 读:",$3," 写:",$4," 命令:",substr($0, index($0,$7))}' | \
head-20
echo "------------------------------------------------"
echo "提示:读/写单位 KB/s;若需持续监控,可增加采样时间"
(2)授权后运行脚本iotop.sh
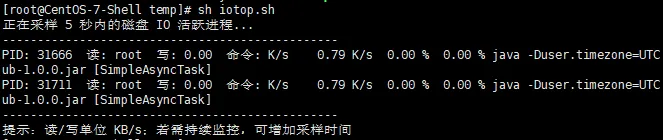
备注:此脚本适合于系统突慢时快速抓取,把结果记入日志供后续分析。
3.连续记录IO日志 + 自动触发告警
(1)编写IO监控脚本io_alert.sh
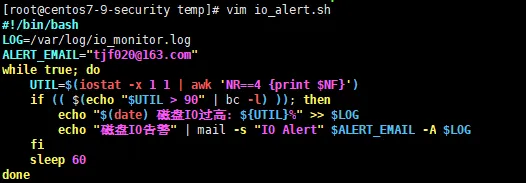
真实脚本如下:
#!/bin/bash
LOG=/var/log/io_monitor.log
ALERT_EMAIL="tjf020@163.com"
while true; do
UTIL=$(iostat-x 1 1 | awk 'NR==4 {print $NF}')
if(( $(echo "$UTIL > 90" | bc -l) )); then
echo"$(date) 磁盘IO过高: ${UTIL}%" >> $LOG
echo"磁盘IO告警" | mail -s "IO Alert" $ALERT_EMAIL -A $LOG
fi
sleep60
done
(2)授权后运行IO监控脚本io_alert.sh
查看结果如下:

备注:用nohup ./io_alert.sh &放在后台跑,就能24小时监控,异常时自动留痕并发邮件。
三、提升效率的思路
1.先看整体,再查进程:
先用iostat确定系统是否IO瓶颈,再用iotop找到具体进程,避免被假象误导。
2.定时任务收日志:
将脚本1放入crontab(如每5分钟执行),长期收集数据,用于排查“下午三点准时慢”这类间歇性问题。
四、总结
磁盘IO问题就像堵车:iostat判断整条路是否拥堵,iotop找出“加塞”的进程。配合自动化的Shell脚本,你不仅能快速响应故障,还能提前预警。建议在日常工作中,把这三个脚本稍作修改融入自己的巡检体系,可以更高效的使用Linux系统。