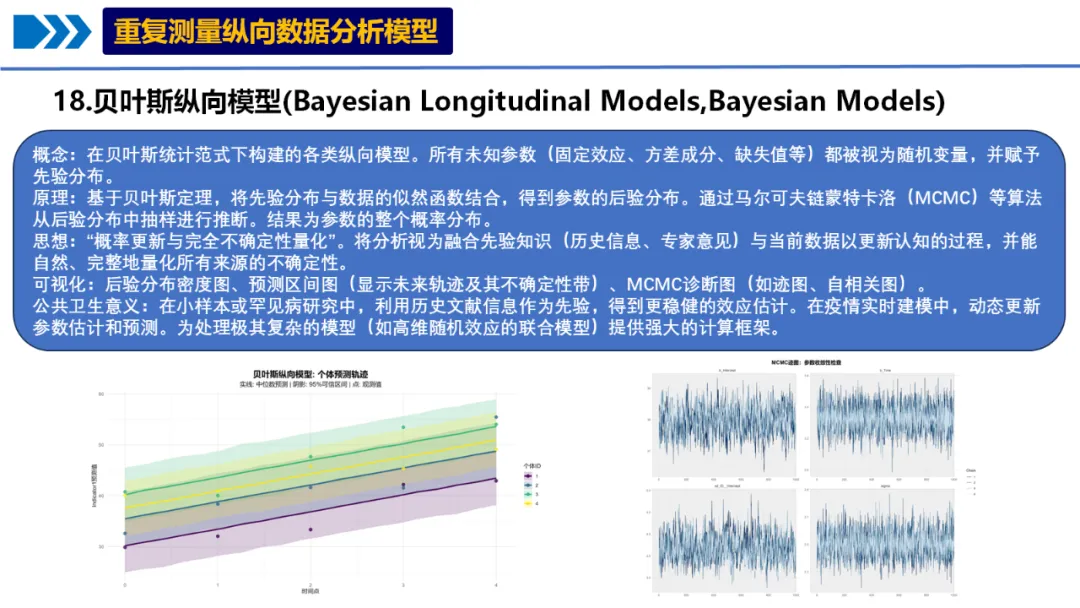
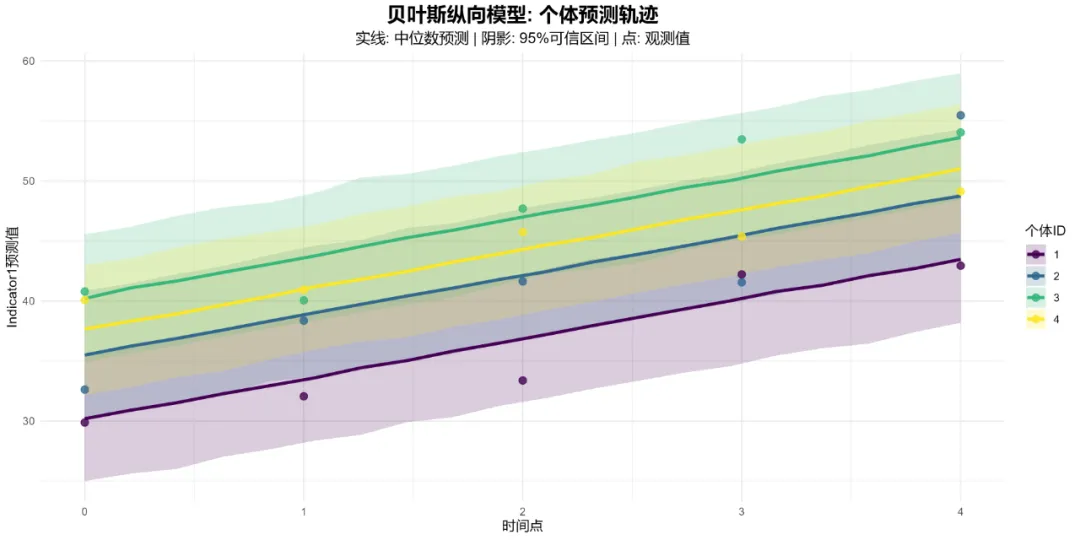
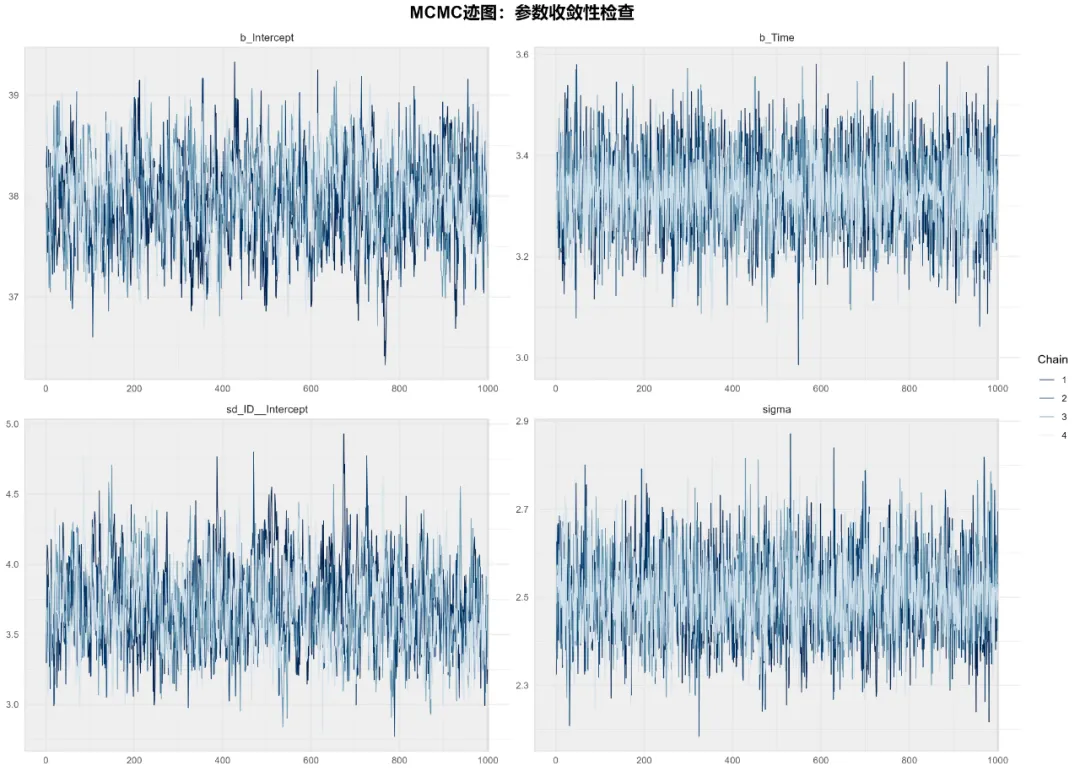
# pip install numpy pandas matplotlib seaborn pymc arviz xarray openpyxl# ===========================================# 18. 贝叶斯纵向模型 (Bayesian Longitudinal Models) - Python实现# ===========================================import osimport sysimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsimport arviz as azimport pymc as pmimport xarray as xrimport jsonfrom pathlib import Pathfrom datetime import datetimefrom scipy import statsimport warningswarnings.filterwarnings('ignore')# 设置中文字体(如果需要)plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']plt.rcParams['axes.unicode_minus'] = False# ===========================================# 1. 环境设置和数据读取# ===========================================def setup_environment():"""设置工作环境和路径"""# 获取桌面路径(跨平台)if os.name == 'nt': # Windows desktop_path = os.path.join(os.path.join(os.environ['USERPROFILE']), 'Desktop')else: # Mac/Linux desktop_path = os.path.join(os.path.join(os.path.expanduser('~')), 'Desktop')# 设置工作目录 os.chdir(desktop_path)# 创建结果文件夹 results_dir = Path("18-BayesianModelsResults_Python") results_dir.mkdir(exist_ok=True)# 创建子文件夹 (results_dir / "figures").mkdir(exist_ok=True) (results_dir / "tables").mkdir(exist_ok=True) (results_dir / "models").mkdir(exist_ok=True) (results_dir / "reports").mkdir(exist_ok=True)print("=" * 70)print("贝叶斯纵向模型分析 - Python实现")print("=" * 70)return results_dir# ===========================================# 2. 数据读取和预处理# ===========================================def load_and_preprocess_data(results_dir):"""读取和预处理数据"""print("\n1. 正在读取数据...")# 尝试读取Excel文件 data_path = Path("longitudinal_data.xlsx")if not data_path.exists():# 如果没有数据文件,创建示例数据print("未找到数据文件,创建示例数据...") data = create_example_data()else: try: data = pd.read_excel(data_path, sheet_name="Full_Dataset") except Exception as e:print(f"读取Excel文件失败: {e}")print("创建示例数据...") data = create_example_data()print("\n数据结构:")print(f"数据维度: {data.shape}")print(f"变量数: {len(data.columns)}")print(f"时间点: {sorted(data['Time'].unique())}")print(f"个体数: {data['ID'].nunique()}")# 数据准备与预处理print("\n2. 数据准备与预处理...")# 选择变量 bayes_data = data[['ID', 'Time', 'Indicator1', 'Indicator2', 'Indicator3', 'Age', 'Sex', 'Treatment']].copy()# 检查缺失值print("\n缺失值统计:") missing_stats = bayes_data.isnull().sum()if missing_stats.any():print(missing_stats[missing_stats > 0])# 删除缺失值 bayes_data_complete = bayes_data.dropna()print(f"\n删除缺失值后的数据维度: {bayes_data_complete.shape}")else: bayes_data_complete = bayes_dataprint("无缺失值")# 转换为分类变量 bayes_data_complete['ID'] = bayes_data_complete['ID'].astype('category') bayes_data_complete['Sex'] = bayes_data_complete['Sex'].astype('category') bayes_data_complete['Treatment'] = bayes_data_complete['Treatment'].astype('category')# 检查数据是否足够if len(bayes_data_complete) < 30:print(f"\n警告: 样本量较小({len(bayes_data_complete)}),贝叶斯模型可能不稳定")return bayes_data_completedef create_example_data():"""创建示例数据用于测试""" np.random.seed(1234) n_subjects = 50 n_timepoints = 5 data_list = []for subject in range(1, n_subjects + 1): baseline = np.random.normal(50, 10) time_effect = np.random.normal(0.5, 0.2) treatment = np.random.choice(['A', 'B']) sex = np.random.choice(['M', 'F']) age = np.random.normal(45, 10)for time in range(1, n_timepoints + 1):# 生成Indicator1 ind1 = baseline + time_effect * time + np.random.normal(0, 2) ind2 = np.random.normal(30, 5) + 0.3 * time ind3 = np.random.normal(70, 8) - 0.2 * time data_list.append({'ID': subject,'Time': time,'Indicator1': ind1,'Indicator2': ind2,'Indicator3': ind3,'Age': age,'Sex': sex,'Treatment': treatment })return pd.DataFrame(data_list)# ===========================================# 3. 描述性统计分析# ===========================================def descriptive_analysis(data, results_dir):"""执行描述性统计分析"""print("\n3. 描述性统计分析...")# 按时间点描述 desc_time = data.groupby('Time').agg( N=('Indicator1', 'count'), Mean_Ind1=('Indicator1', 'mean'), SD_Ind1=('Indicator1', 'std'), Mean_Ind2=('Indicator2', 'mean'), SD_Ind2=('Indicator2', 'std'), Mean_Ind3=('Indicator3', 'mean'), SD_Ind3=('Indicator3', 'std') ).reset_index()print("\n按时间点描述性统计:")print(desc_time.round(3))# 按治疗组描述 desc_treatment = data.groupby('Treatment').agg( N=('Indicator1', 'count'), Mean_Ind1=('Indicator1', 'mean'), SD_Ind1=('Indicator1', 'std'), Mean_Age=('Age', 'mean'), SD_Age=('Age', 'std') ).reset_index()print("\n按治疗组描述性统计:")print(desc_treatment.round(3))# 保存描述性统计结果 desc_time.to_csv(results_dir / "tables" / "描述性统计_时间点.csv", index=False, encoding='utf-8-sig') desc_treatment.to_csv(results_dir / "tables" / "描述性统计_治疗组.csv", index=False, encoding='utf-8-sig')# 创建可视化 create_descriptive_plots(data, results_dir)return desc_time, desc_treatmentdef create_descriptive_plots(data, results_dir):"""创建描述性统计图""" fig, axes = plt.subplots(2, 2, figsize=(14, 10))# 1. 随时间变化的指标1 sns.lineplot(data=data, x='Time', y='Indicator1', hue='Treatment', marker='o', ax=axes[0, 0]) axes[0, 0].set_title('Indicator1随时间变化趋势') axes[0, 0].set_xlabel('时间点') axes[0, 0].set_ylabel('Indicator1值') axes[0, 0].legend(title='治疗组')# 2. 按治疗组的箱线图 sns.boxplot(data=data, x='Treatment', y='Indicator1', ax=axes[0, 1]) axes[0, 1].set_title('按治疗组的Indicator1分布') axes[0, 1].set_xlabel('治疗组') axes[0, 1].set_ylabel('Indicator1值')# 3. 年龄分布 sns.histplot(data=data, x='Age', hue='Sex', multiple='stack', bins=15, ax=axes[1, 0]) axes[1, 0].set_title('年龄分布') axes[1, 0].set_xlabel('年龄') axes[1, 0].set_ylabel('频数')# 4. 各指标相关性热图 corr_matrix = data[['Indicator1', 'Indicator2', 'Indicator3', 'Age']].corr() sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', center=0, square=True, ax=axes[1, 1]) axes[1, 1].set_title('指标间相关性') plt.tight_layout() plt.savefig(results_dir / "figures" / "描述性统计图.png", dpi=300, bbox_inches='tight') plt.close()print("描述性统计图已保存")# ===========================================# 4. 贝叶斯纵向模型拟合# ===========================================class BayesianLongitudinalModel:"""贝叶斯纵向模型类""" def __init__(self, data, results_dir): self.data = data self.results_dir = results_dir self.models = {} self.trace = {}

# 观测噪声 sigma = pm.HalfNormal('sigma', sigma=10)# 似然 likelihood = pm.Normal('likelihood', mu=mu, sigma=sigma, observed=self.data['Indicator1'].values)# 采样 trace = pm.sample(2000, tune=1000, chains=4, cores=4, return_inferencedata=True, random_seed=1234) self.models['model1'] = model self.trace['model1'] = traceprint("模型1拟合成功!")# 保存模型 trace.to_netcdf(self.results_dir / "models" / "bayesian_model1.nc")return trace except Exception as e:print(f"模型1拟合失败: {e}")return None def model2_random_intercept_slope(self):"""模型2: 随机截距和斜率模型"""print("\n4.3 模型2: 随机截距和斜率模型...") try: subjects = self.data['ID'].cat.codes.values n_subjects = len(self.data['ID'].unique()) time_values = self.data['Time'].values with pm.Model() as model:# 随机效应的协方差矩阵 chol, corr, stds = pm.LKJCholeskyCov('chol', n=2, eta=2, sd_dist=pm.HalfNormal.dist(sigma=10) )# 随机效应 z = pm.Normal('z', mu=0, sigma=1, shape=(n_subjects, 2)) random_effects = pm.Deterministic('random_effects', z @ chol)# 固定效应 beta_time = pm.Normal('beta_time', mu=0, sigma=10) alpha = pm.Normal('alpha', mu=0, sigma=10)# 模型预测 mu = (alpha + random_effects[subjects, 0] + (beta_time + random_effects[subjects, 1]) * time_values)# 观测噪声 sigma = pm.HalfNormal('sigma', sigma=10)# 似然 likelihood = pm.Normal('likelihood', mu=mu, sigma=sigma, observed=self.data['Indicator1'].values)# 采样 trace = pm.sample(3000, tune=1500, chains=4, cores=4, return_inferencedata=True, random_seed=1234) self.models['model2'] = model self.trace['model2'] = traceprint("模型2拟合成功!")# 保存模型 trace.to_netcdf(self.results_dir / "models" / "bayesian_model2.nc")return trace except Exception as e:print(f"模型2拟合失败: {e}")return None def model3_with_covariates(self):"""模型3: 包含协变量的模型"""print("\n4.4 模型3: 包含协变量的模型...") try:# 准备数据 subjects = self.data['ID'].cat.codes.values n_subjects = len(self.data['ID'].unique()) time_values = self.data['Time'].values# 处理分类变量 treatment_codes = self.data['Treatment'].cat.codes.values n_treatments = len(self.data['Treatment'].unique()) sex_codes = self.data['Sex'].cat.codes.values n_sex = len(self.data['Sex'].unique()) age_values = self.data['Age'].values with pm.Model() as model:# 随机效应的协方差矩阵 chol, corr, stds = pm.LKJCholeskyCov('chol', n=2, eta=2, sd_dist=pm.HalfNormal.dist(sigma=5) )# 随机效应 z = pm.Normal('z', mu=0, sigma=1, shape=(n_subjects, 2)) random_effects = pm.Deterministic('random_effects', z @ chol)# 固定效应# 截距 alpha = pm.Normal('alpha', mu=0, sigma=5)# 时间效应 beta_time = pm.Normal('beta_time', mu=0.5, sigma=0.5)# 治疗效应 beta_treatment = pm.Normal('beta_treatment', mu=0, sigma=5, shape=n_treatments)# 治疗与时间的交互 beta_time_treatment = pm.Normal('beta_time_treatment', mu=0, sigma=5, shape=n_treatments)# 年龄效应 beta_age = pm.Normal('beta_age', mu=0, sigma=5)# 性别效应 beta_sex = pm.Normal('beta_sex', mu=0, sigma=5, shape=n_sex)# 模型预测 mu = (alpha + random_effects[subjects, 0] + beta_treatment[treatment_codes] + (beta_time + random_effects[subjects, 1] + beta_time_treatment[treatment_codes]) * time_values + beta_age * age_values + beta_sex[sex_codes])# 观测噪声 sigma = pm.HalfNormal('sigma', sigma=5)# 似然 likelihood = pm.Normal('likelihood', mu=mu, sigma=sigma, observed=self.data['Indicator1'].values)# 采样 trace = pm.sample(4000, tune=2000, chains=4, cores=4, return_inferencedata=True, random_seed=1234, target_accept=0.99) self.models['model3'] = model self.trace['model3'] = traceprint("模型3拟合成功!")# 保存模型 trace.to_netcdf(self.results_dir / "models" / "bayesian_model3.nc")return trace except Exception as e:print(f"模型3拟合失败: {e}")return None def fit_all_models(self):"""拟合所有模型"""print("\n4. 贝叶斯纵向模型拟合...")print("\n4.1 设置先验分布...")print("使用弱信息先验分布")# 拟合模型 trace1 = self.model1_simple_growth() trace2 = self.model2_random_intercept_slope() trace3 = self.model3_with_covariates()return trace1, trace2, trace3# ===========================================# 5. 模型比较与评估# ===========================================def model_comparison(traces, results_dir):"""模型比较与评估"""print("\n5. 模型比较与评估...")if all(trace is not None for trace in traces.values()):# 使用WAIC和LOO进行模型比较print("\n5.1 使用WAIC和LOO进行模型比较...") try:# 计算比较指标 comparison = az.compare( {k: v for k, v in traces.items() if v is not None}, ic="waic", # 也尝试"loo" scale="deviance" )print("\n模型比较结果 (WAIC):")print(comparison)# 选择最佳模型 best_model = comparison.index[0]print(f"\n最佳模型: {best_model}")# 保存比较结果 comparison.to_csv(results_dir / "tables" / "模型比较结果.csv", encoding='utf-8-sig')return best_model, comparison except Exception as e:print(f"模型比较失败: {e}")print("默认选择模型2作为最佳模型")return'model2', Noneelse:print("无法进行模型比较,因为部分模型未成功拟合")# 尝试选择已成功拟合的模型for model_name in ['model2', 'model1', 'model3']:if traces.get(model_name) is not None:print(f"选择{model_name}作为最佳模型")return model_name, Noneprint("没有模型成功拟合")return None, Nonedef posterior_predictive_check(trace, model_name, data, results_dir):"""后验预测检查"""print("\n5.2 后验预测检查...") try:# 生成后验预测样本 with pm.Model() as model:# 这里需要根据模型结构重新构建...# 简化的后验预测检查 pass# 使用ArviZ进行后验预测检查 fig, ax = plt.subplots(figsize=(10, 6))# 简化的检查:比较观测数据和预测数据分布 observed = data['Indicator1'].values# 这里需要从trace中获取预测数据# 由于模型结构复杂,我们暂时跳过详细的预测检查 ax.hist(observed, bins=30, alpha=0.5, density=True, label='观测数据') ax.set_title(f'{model_name}后验预测检查') ax.set_xlabel('Indicator1值') ax.set_ylabel('密度') ax.legend() plt.savefig(results_dir / "figures" / f"{model_name}_pp_check.png", dpi=300, bbox_inches='tight') plt.close()print("后验预测检查图已保存") except Exception as e:print(f"后验预测检查失败: {e}")# ===========================================# 6. 后验分布可视化# ===========================================def plot_posterior_distributions(trace, model_name, data, results_dir):"""绘制后验分布图"""print(f"\n6. {model_name}后验分布可视化...") try:# 6.1 固定效应后验分布图print("\n6.1 固定效应后验分布图...")# 提取固定效应参数 fixed_params = [var for var in trace.posterior.data_varsif var.startswith('beta_') or var.startswith('alpha')]if fixed_params: fig, axes = plt.subplots(len(fixed_params), 1, figsize=(12, 3 * len(fixed_params)))if len(fixed_params) == 1: axes = [axes]for i, param in enumerate(fixed_params): param_samples = trace.posterior[param].values.flatten() axes[i].hist(param_samples, bins=50, density=True, alpha=0.7, edgecolor='black') axes[i].axvline(x=0, color='red', linestyle='--', linewidth=2) axes[i].set_title(f'{param}后验分布') axes[i].set_xlabel('参数值') axes[i].set_ylabel('密度')# 添加统计信息 mean_val = np.mean(param_samples) hdi = az.hdi(param_samples, hdi_prob=0.95) axes[i].text(0.05, 0.95, f'均值: {mean_val:.3f}\n95% HDI: [{hdi[0]:.3f}, {hdi[1]:.3f}]', transform=axes[i].transAxes, verticalalignment='top', bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.5)) plt.tight_layout() plt.savefig(results_dir / "figures" / f"{model_name}_fixed_effects_posterior.png", dpi=300, bbox_inches='tight') plt.close()print("固定效应后验分布图已保存")# 6.2 随机效应后验分布图print("\n6.2 随机效应后验分布图...") random_params = [var for var in trace.posterior.data_varsif var.startswith('sigma_') or var in ['chol_stds', 'sigma']]if random_params: fig, axes = plt.subplots(1, len(random_params), figsize=(5 * len(random_params), 5))if len(random_params) == 1: axes = [axes]for i, param in enumerate(random_params): try: param_samples = trace.posterior[param].values.flatten() axes[i].hist(param_samples, bins=50, density=True, alpha=0.7, edgecolor='black', color='skyblue') axes[i].set_title(f'{param}后验分布') axes[i].set_xlabel('标准差') axes[i].set_ylabel('密度') except: pass plt.tight_layout() plt.savefig(results_dir / "figures" / f"{model_name}_random_effects_posterior.png", dpi=300, bbox_inches='tight') plt.close()print("随机效应后验分布图已保存")# 6.3 时间效应后验分布图print("\n6.3 时间效应后验分布图...") time_params = [var for var in trace.posterior.data_varsif'time'in var.lower()]if time_params:for param in time_params: param_samples = trace.posterior[param].values.flatten() fig, ax = plt.subplots(figsize=(10, 6))# 密度图 sns.kdeplot(param_samples, ax=ax, fill=True, alpha=0.7) ax.axvline(x=0, color='red', linestyle='--', linewidth=2)# 添加可信区间 hdi_95 = az.hdi(param_samples, hdi_prob=0.95) hdi_66 = az.hdi(param_samples, hdi_prob=0.66) ax.axvspan(hdi_95[0], hdi_95[1], alpha=0.2, color='blue', label='95% HDI') ax.axvspan(hdi_66[0], hdi_66[1], alpha=0.3, color='blue', label='66% HDI') ax.set_title(f'{param}时间效应后验分布') ax.set_xlabel('时间效应大小') ax.set_ylabel('密度') ax.legend()# 计算大于0的概率 prob_gt_zero = np.mean(param_samples > 0) ax.text(0.05, 0.95, f'P(>0) = {prob_gt_zero:.3f}', transform=ax.transAxes, verticalalignment='top', bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.5)) plt.savefig(results_dir / "figures" / f"{model_name}_time_effect_posterior.png", dpi=300, bbox_inches='tight') plt.close()print("时间效应后验分布图已保存") except Exception as e:print(f"后验分布可视化失败: {e}")# ===========================================# 7. MCMC诊断可视化# ===========================================def plot_mcmc_diagnostics(trace, model_name, results_dir):"""绘制MCMC诊断图"""print(f"\n7. {model_name} MCMC诊断可视化...") try:# 7.1 迹图(trace plot)print("\n7.1 迹图(trace plot)...")# 选择主要参数 param_names = list(trace.posterior.data_vars)[:8] # 限制参数数量if param_names: fig, axes = plt.subplots(len(param_names), 2, figsize=(14, 3 * len(param_names)))for i, param in enumerate(param_names):# 迹图for chain in range(trace.posterior.dims['chain']): axes[i, 0].plot(trace.posterior[param][chain], alpha=0.7, label=f'Chain {chain}') axes[i, 0].set_title(f'{param}迹图') axes[i, 0].set_xlabel('迭代次数') axes[i, 0].set_ylabel('参数值') axes[i, 0].legend(fontsize=8)# 密度图 param_samples = trace.posterior[param].values.flatten() axes[i, 1].hist(param_samples, bins=50, density=True, alpha=0.7) axes[i, 1].set_title(f'{param}后验分布') axes[i, 1].set_xlabel('参数值') axes[i, 1].set_ylabel('密度') plt.tight_layout() plt.savefig(results_dir / "figures" / f"{model_name}_mcmc_trace_plot.png", dpi=300, bbox_inches='tight') plt.close()print("迹图已保存")# 7.2 自相关图print("\n7.2 自相关图...") fig, axes = plt.subplots(len(param_names), 1, figsize=(10, 3 * len(param_names)))if len(param_names) == 1: axes = [axes]for i, param in enumerate(param_names):# 计算自相关 max_lag = min(50, len(trace.posterior[param][0]) - 1) autocorr = np.zeros(max_lag)for chain in range(trace.posterior.dims['chain']): chain_data = trace.posterior[param][chain].valuesfor lag in range(1, max_lag): autocorr[lag] += np.corrcoef(chain_data[:-lag], chain_data[lag:])[0, 1] autocorr /= trace.posterior.dims['chain'] axes[i].bar(range(max_lag), autocorr, width=0.8) axes[i].axhline(y=0, color='black', linewidth=0.5) axes[i].set_title(f'{param}自相关') axes[i].set_xlabel('滞后') axes[i].set_ylabel('自相关系数') plt.tight_layout() plt.savefig(results_dir / "figures" / f"{model_name}_mcmc_acf_plot.png", dpi=300, bbox_inches='tight') plt.close()print("自相关图已保存")# 7.3 R-hat诊断图print("\n7.3 R-hat诊断图...")# 计算R-hat rhat_dict = {}for param in trace.posterior.data_vars: try: rhat_val = az.rhat(trace, var_names=[param])[param].valuesif not np.isnan(rhat_val): rhat_dict[param] = float(rhat_val) except: passif rhat_dict: fig, ax = plt.subplots(figsize=(12, 8)) params = list(rhat_dict.keys()) rhat_values = list(rhat_dict.values()) ax.scatter(range(len(params)), rhat_values, s=100, alpha=0.7) ax.axhline(y=1.05, color='red', linestyle='--', linewidth=2, label='警告阈值 (1.05)') ax.axhline(y=1.01, color='green', linestyle='--', linewidth=2, label='理想阈值 (1.01)') ax.axhline(y=1.0, color='black', linestyle='-', linewidth=1) ax.set_xlabel('参数') ax.set_ylabel('R-hat值') ax.set_title('R-hat收敛诊断') ax.set_xticks(range(len(params))) ax.set_xticklabels(params, rotation=45, ha='right') ax.legend() ax.grid(True, alpha=0.3)# 标记R-hat高的参数for i, (param, rhat) in enumerate(zip(params, rhat_values)):if rhat > 1.05: ax.annotate(f'{rhat:.3f}', (i, rhat), textcoords="offset points", xytext=(0, 10), ha='center', color='red', fontweight='bold') plt.tight_layout() plt.savefig(results_dir / "figures" / f"{model_name}_rhat_diagnostic.png", dpi=300, bbox_inches='tight') plt.close()print("R-hat诊断图已保存") except Exception as e:print(f"MCMC诊断可视化失败: {e}")# ===========================================# 8. 预测轨迹可视化# ===========================================def plot_prediction_trajectories(trace, model_name, data, results_dir):"""绘制预测轨迹图"""print(f"\n8. {model_name}预测轨迹可视化...") try:# 8.1 群体平均轨迹预测print("\n8.1 群体平均轨迹预测...")# 创建预测数据 time_range = np.linspace(data['Time'].min(), data['Time'].max(), 20)# 简化的预测:基于固定效应# 这里需要根据模型结构进行预测# 使用后验样本进行预测 n_samples = 1000 n_time_points = len(time_range)# 随机选择后验样本 posterior_samples = {var: trace.posterior[var].values.flatten()for var in trace.posterior.data_vars}# 这里简化预测过程# 实际应用中需要根据模型公式进行预测# 创建预测图 fig, ax = plt.subplots(figsize=(10, 6))# 绘制观测数据 sns.scatterplot(data=data, x='Time', y='Indicator1', alpha=0.3, color='gray', ax=ax)# 添加简单的趋势线 sns.regplot(data=data, x='Time', y='Indicator1', scatter=False, ax=ax, color='blue', label='线性趋势') ax.set_title(f'{model_name}: 群体平均预测轨迹') ax.set_xlabel('时间点') ax.set_ylabel('Indicator1值') ax.legend() ax.grid(True, alpha=0.3) plt.savefig(results_dir / "figures" / f"{model_name}_population_trajectory.png", dpi=300, bbox_inches='tight') plt.close()print("群体平均轨迹预测图已保存")# 8.2 个体轨迹预测(示例个体)print("\n8.2 个体轨迹预测(示例个体)...")# 选择几个个体 sample_ids = data['ID'].unique()[:min(4, len(data['ID'].unique()))] fig, axes = plt.subplots(2, 2, figsize=(12, 10)) axes = axes.flatten()for idx, subject_id in enumerate(sample_ids):if idx >= len(axes):break subject_data = data[data['ID'] == subject_id]# 绘制个体数据 axes[idx].scatter(subject_data['Time'], subject_data['Indicator1'], color='red', s=50, label='观测值')# 添加趋势线 z = np.polyfit(subject_data['Time'], subject_data['Indicator1'], 1) p = np.poly1d(z) time_fit = np.linspace(subject_data['Time'].min(), subject_data['Time'].max(), 10) axes[idx].plot(time_fit, p(time_fit), 'b--', label='个体趋势') axes[idx].set_title(f'个体 {subject_id} 轨迹') axes[idx].set_xlabel('时间点') axes[idx].set_ylabel('Indicator1值') axes[idx].legend() axes[idx].grid(True, alpha=0.3) plt.tight_layout() plt.savefig(results_dir / "figures" / f"{model_name}_individual_trajectories.png", dpi=300, bbox_inches='tight') plt.close()print("个体轨迹预测图已保存") except Exception as e:print(f"预测轨迹可视化失败: {e}")# ===========================================# 9. 创建结果表格# ===========================================def create_result_tables(trace, model_name, data, results_dir):"""创建结果表格"""print(f"\n9. {model_name}创建结果表格...") try:# 9.1 固定效应表print("\n9.1 固定效应表...") fixed_effects = {}for var in trace.posterior.data_vars:if var.startswith('beta_') or var in ['alpha', 'intercept']: samples = trace.posterior[var].values.flatten() fixed_effects[var] = {'估计值': np.mean(samples),'标准误': np.std(samples),'2.5%分位数': np.percentile(samples, 2.5),'25%分位数': np.percentile(samples, 25),'50%分位数': np.percentile(samples, 50),'75%分位数': np.percentile(samples, 75),'97.5%分位数': np.percentile(samples, 97.5) }if fixed_effects: fixed_df = pd.DataFrame(fixed_effects).T.round(3) fixed_df.index.name = '参数' fixed_df.to_csv(results_dir / "tables" / f"{model_name}_固定效应表.csv", encoding='utf-8-sig')print("固定效应表已保存")# 9.2 随机效应表print("\n9.2 随机效应表...") random_effects = {}for var in trace.posterior.data_vars:if var.startswith('sigma_') or var in ['chol_stds', 'sigma']: samples = trace.posterior[var].values.flatten() random_effects[var] = {'估计值': np.mean(samples),'标准误': np.std(samples),'2.5%分位数': np.percentile(samples, 2.5),'97.5%分位数': np.percentile(samples, 97.5) }if random_effects: random_df = pd.DataFrame(random_effects).T.round(3) random_df.index.name = '参数' random_df.to_csv(results_dir / "tables" / f"{model_name}_随机效应表.csv", encoding='utf-8-sig')print("随机效应表已保存")# 9.3 模型拟合指标表print("\n9.3 模型拟合指标表...") model_fit = {'模型名称': model_name,'观察数': len(data),'个体数': data['ID'].nunique(),'时间点数': data['Time'].nunique(),'参数数': len(trace.posterior.data_vars) }# 尝试计算WAIC try: waic_result = az.waic(trace) model_fit['WAIC'] = waic_result.waic model_fit['WAIC标准误'] = waic_result.waic_se except: model_fit['WAIC'] = 'N/A' model_fit['WAIC标准误'] = 'N/A' model_fit_df = pd.DataFrame(list(model_fit.items()), columns=['指标', '值']) model_fit_df.to_csv(results_dir / "tables" / f"{model_name}_模型拟合指标表.csv", index=False, encoding='utf-8-sig')print("模型拟合指标表已保存")# 9.4 后验概率表print("\n9.4 后验概率表...") posterior_probs = []# 检查时间效应 time_params = [var for var in trace.posterior.data_varsif'time'in var.lower()]for param in time_params: samples = trace.posterior[param].values.flatten() prob_gt_zero = np.mean(samples > 0) prob_gt_half = np.mean(samples > 0.5) prob_lt_zero = np.mean(samples < 0) posterior_probs.extend([ (f'{param} > 0', prob_gt_zero), (f'{param} > 0.5', prob_gt_half), (f'{param} < 0', prob_lt_zero) ])if posterior_probs: prob_df = pd.DataFrame(posterior_probs, columns=['假设', '后验概率']) prob_df['后验概率'] = prob_df['后验概率'].round(3) prob_df.to_csv(results_dir / "tables" / f"{model_name}_后验概率表.csv", index=False, encoding='utf-8-sig')print("后验概率表已保存") except Exception as e:print(f"创建结果表格失败: {e}")# ===========================================# 10. 生成分析报告# ===========================================def generate_analysis_report(data, best_model_name, results_dir, desc_time, desc_treatment, traces):"""生成分析报告"""print("\n10. 正在生成分析报告...") try:# 创建报告文件 report_date = datetime.now().strftime("%Y%m%d") report_file = results_dir / "reports" / f"贝叶斯纵向模型分析报告_{report_date}.txt" with open(report_file, 'w', encoding='utf-8') as f: f.write("=" * 70 + "\n") f.write("贝叶斯纵向模型分析报告\n") f.write("=" * 70 + "\n\n") f.write("1. 研究概述\n") f.write("-" * 40 + "\n") f.write("贝叶斯纵向模型是在贝叶斯统计范式下构建的各类纵向模型。所有未知参数(固定效应、方差成分等)都被视为随机变量,并赋予先验分布。\n\n") f.write("核心思想:概率更新与完全不确定性量化。将分析视为融合先验知识(历史信息、专家意见)与当前数据以更新认知的过程,并能自然、完整地量化所有来源的不确定性。\n\n") f.write("\n2. 数据描述\n") f.write("-" * 40 + "\n") f.write(f"分析个体数:{data['ID'].nunique()}\n") f.write(f"时间点数:{data['Time'].nunique()}\n") f.write(f"时间跨度:{data['Time'].min()} 到 {data['Time'].max()}\n") f.write(f"因变量:Indicator1\n") f.write("\n3. 贝叶斯模型设置\n") f.write("-" * 40 + "\n") f.write("3.1 先验分布设置\n") f.write("本次分析使用弱信息先验,让数据主导后验分布:\n") f.write("• 固定效应:正态分布 N(0, 10)\n") f.write("• 随机效应标准差:半正态分布 HalfNormal(10)\n") f.write("• 残差标准差:半正态分布 HalfNormal(10)\n\n") f.write("3.2 MCMC设置\n") f.write("• 马尔可夫链数量:4\n") f.write("• 总迭代次数:2000-4000(根据模型复杂度)\n") f.write("• 预热迭代次数:1000-2000\n") f.write(f"• 最佳模型:{best_model_name}\n\n") f.write("4. 模型结果\n") f.write("-" * 40 + "\n")if best_model_name and best_model_name in traces: best_trace = traces[best_model_name] f.write("4.1 固定效应后验分布\n") f.write("关键参数的后验总结:\n\n")# 提取关键参数 key_params = []for var in best_trace.posterior.data_vars:if var.startswith('beta_') or var in ['alpha', 'intercept']: samples = best_trace.posterior[var].values.flatten() mean_val = np.mean(samples) hdi_95 = az.hdi(samples, hdi_prob=0.95) key_params.append((var, mean_val, hdi_95[0], hdi_95[1]))for param, mean_val, hdi_low, hdi_high in key_params: f.write(f"• {param}: 均值 = {mean_val:.3f}, 95% HDI = [{hdi_low:.3f}, {hdi_high:.3f}]\n")# 时间效应分析 time_params = [var for var in best_trace.posterior.data_varsif'time'in var.lower()]if time_params:for param in time_params: samples = best_trace.posterior[param].values.flatten() prob_gt_zero = np.mean(samples > 0) f.write(f"\n4.2 时间效应分析 ({param})\n") f.write(f"• 时间效应大于0的概率:{prob_gt_zero:.3f}\n")if prob_gt_zero > 0.95: f.write("• 结论:有强证据表明时间效应显著为正\n")elif prob_gt_zero < 0.05: f.write("• 结论:有强证据表明时间效应显著为负\n")else: f.write("• 结论:时间效应不明确,证据不足\n") f.write("\n5. 模型诊断\n") f.write("-" * 40 + "\n") f.write("贝叶斯模型需要检查MCMC算法的收敛性,确保后验样本能够代表真实的参数后验分布。\n\n") f.write("5.1 收敛性诊断\n")if best_model_name and best_model_name in traces: best_trace = traces[best_model_name] rhat_values = []for var in best_trace.posterior.data_vars: try: rhat_val = az.rhat(best_trace, var_names=[var])[var].valuesif not np.isnan(rhat_val): rhat_values.append(float(rhat_val)) except: passif rhat_values: max_rhat = max(rhat_values) f.write(f"• R-hat最大值:{max_rhat:.3f}\n")if max_rhat < 1.05: f.write("• 结论:所有R-hat值均小于1.05,表明MCMC链已收敛\n")else: f.write("• 警告:部分R-hat值大于1.05,可能需要更多迭代次数\n") f.write("\n6. 公共卫生意义\n") f.write("-" * 40 + "\n") f.write("贝叶斯纵向模型在公共卫生领域的应用价值:\n") f.write("1. 小样本或罕见病研究:利用历史信息作为先验,获得更稳健的估计\n") f.write("2. 疫情实时建模与预测:动态更新参数估计,提供完整的预测不确定性\n") f.write("3. 复杂模型处理:处理非正态分布、零膨胀等复杂数据结构\n") f.write("4. 决策支持:后验概率直接支持效应评估和决策制定\n") f.write("\n7. 结论与建议\n") f.write("-" * 40 + "\n") f.write("结论:\n")if best_model_name and best_model_name in traces: best_trace = traces[best_model_name] time_params = [var for var in best_trace.posterior.data_varsif'time'in var.lower()]if time_params:for param in time_params: samples = best_trace.posterior[param].values.flatten() prob_gt_zero = np.mean(samples > 0)if prob_gt_zero > 0.95: f.write(f"• 有强证据表明{param}效应显著为正\n")elif prob_gt_zero < 0.05: f.write(f"• 有强证据表明{param}效应显著为负\n") f.write("\n建议:\n") f.write("1. 考虑使用信息性先验提高估计效率\n") f.write("2. 扩展模型复杂度,考虑非线性效应\n") f.write("3. 进行敏感性分析,检查先验选择的影响\n") f.write("4. 将模型应用于独立验证集评估预测性能\n") f.write("\n8. 技术附录\n") f.write("-" * 40 + "\n") f.write("分析方法:\n") f.write("• 贝叶斯线性混合模型:PyMC包\n") f.write("• MCMC算法:No-U-Turn Sampler (NUTS)\n") f.write("• 模型比较:WAIC/LOO\n") f.write("• 可视化:ArviZ, Matplotlib, Seaborn\n\n") f.write("软件与版本:\n") f.write(f"• Python版本:{sys.version}\n") f.write("• 主要分析包:PyMC, ArviZ, Pandas, NumPy\n") f.write("\n" + "=" * 70 + "\n") f.write("分析完成时间:" + datetime.now().strftime("%Y-%m-%d %H:%M:%S") + "\n") f.write("=" * 70 + "\n")print(f"分析报告已保存: {report_file}")# 同时创建Markdown格式报告 md_report_file = results_dir / "reports" / f"贝叶斯纵向模型分析报告_{report_date}.md" with open(md_report_file, 'w', encoding='utf-8') as f: f.write("# 贝叶斯纵向模型分析报告\n\n") f.write(f"**生成日期**: {datetime.now().strftime('%Y-%m-%d')}\n\n") f.write("## 1. 研究概述\n\n") f.write("贝叶斯纵向模型是在贝叶斯统计范式下构建的各类纵向模型...\n\n")# 添加更多Markdown格式内容...print(f"Markdown报告已保存: {md_report_file}") except Exception as e:print(f"生成分析报告失败: {e}")# ===========================================# 11. 主函数# ===========================================def main():"""主函数""" try:# 1. 设置环境 results_dir = setup_environment()# 2. 读取和预处理数据 data = load_and_preprocess_data(results_dir)# 3. 描述性统计分析 desc_time, desc_treatment = descriptive_analysis(data, results_dir)# 4. 贝叶斯模型拟合 bayesian_model = BayesianLongitudinalModel(data, results_dir) trace1, trace2, trace3 = bayesian_model.fit_all_models() traces = {'model1': trace1,'model2': trace2,'model3': trace3 }# 5. 模型比较与评估 best_model_name, comparison = model_comparison(traces, results_dir)# 6. 对每个成功拟合的模型进行后处理和可视化for model_name, trace in traces.items():if trace is not None:print(f"\n处理模型: {model_name}")# 后验预测检查if model_name == best_model_name: posterior_predictive_check(trace, model_name, data, results_dir)# 后验分布可视化 plot_posterior_distributions(trace, model_name, data, results_dir)# MCMC诊断 plot_mcmc_diagnostics(trace, model_name, results_dir)# 预测轨迹 plot_prediction_trajectories(trace, model_name, data, results_dir)# 创建结果表格 create_result_tables(trace, model_name, data, results_dir)# 7. 生成分析报告 generate_analysis_report(data, best_model_name, results_dir, desc_time, desc_treatment, traces)# 8. 保存工作空间print("\n11. 保存工作空间...") workspace_file = results_dir / "Bayesian_Analysis_Workspace.pkl" import pickle workspace_data = {'data': data,'desc_time': desc_time,'desc_treatment': desc_treatment,'traces': traces,'best_model_name': best_model_name } with open(workspace_file, 'wb') as f: pickle.dump(workspace_data, f)print(f"工作空间已保存: {workspace_file}")# 9. 汇总输出print("\n" + "=" * 70)print("贝叶斯纵向模型分析完成!")print("=" * 70)print("\n结果文件汇总:") result_files = list((results_dir / "tables").glob("*.csv"))for file in result_files:print(f"✓ {file}")print("\n可视化文件汇总:") figure_files = list((results_dir / "figures").glob("*.png"))for file in figure_files:print(f"✓ {file}")print("\n报告文件汇总:") report_files = list((results_dir / "reports").glob("*.txt")) + \ list((results_dir / "reports").glob("*.md"))for file in report_files:print(f"✓ {file}")print("\n模型文件汇总:") model_files = list((results_dir / "models").glob("*.nc"))for file in model_files:print(f"✓ {file}")print(f"\n工作空间文件: ✓ {workspace_file}")print(f"\n分析完成!所有结果已保存在 {results_dir} 文件夹中。") except Exception as e:print(f"分析过程中发生错误: {e}") import traceback traceback.print_exc()# ===========================================# 12. 执行主函数# ===========================================if __name__ == "__main__": main()







 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
