学字符串的时候,很多人一开始都挺自信。
能定义变量,能切片,能查找,能替换,路径问题也搞明白了。 可一旦开始接触文件、网页、接口、终端输出,就很容易突然撞上一类特别烦人的问题:
明明是中文,怎么显示成了一堆奇怪符号 明明昨天还能正常打开,今天怎么一读文件就报错 明明内容没坏,为什么换个软件看就全乱了 为什么英文经常没事,中文却老出问题
这类问题背后,绕不开一个关键词:
编码
很多新手一听编码就紧张,觉得这一定是很底层、很抽象、很难啃的东西。 其实你先不用把它想得太吓人。
这一章我们不讲特别底层的计算机原理,也不绕那些太学术的概念。 我们只解决一件事:
把中文乱码这件事,真正讲明白
你只要把这一章的核心逻辑吃透,后面学文件读写、网络请求、爬虫、接口、数据库时,很多莫名其妙的问题都会一下子顺很多。
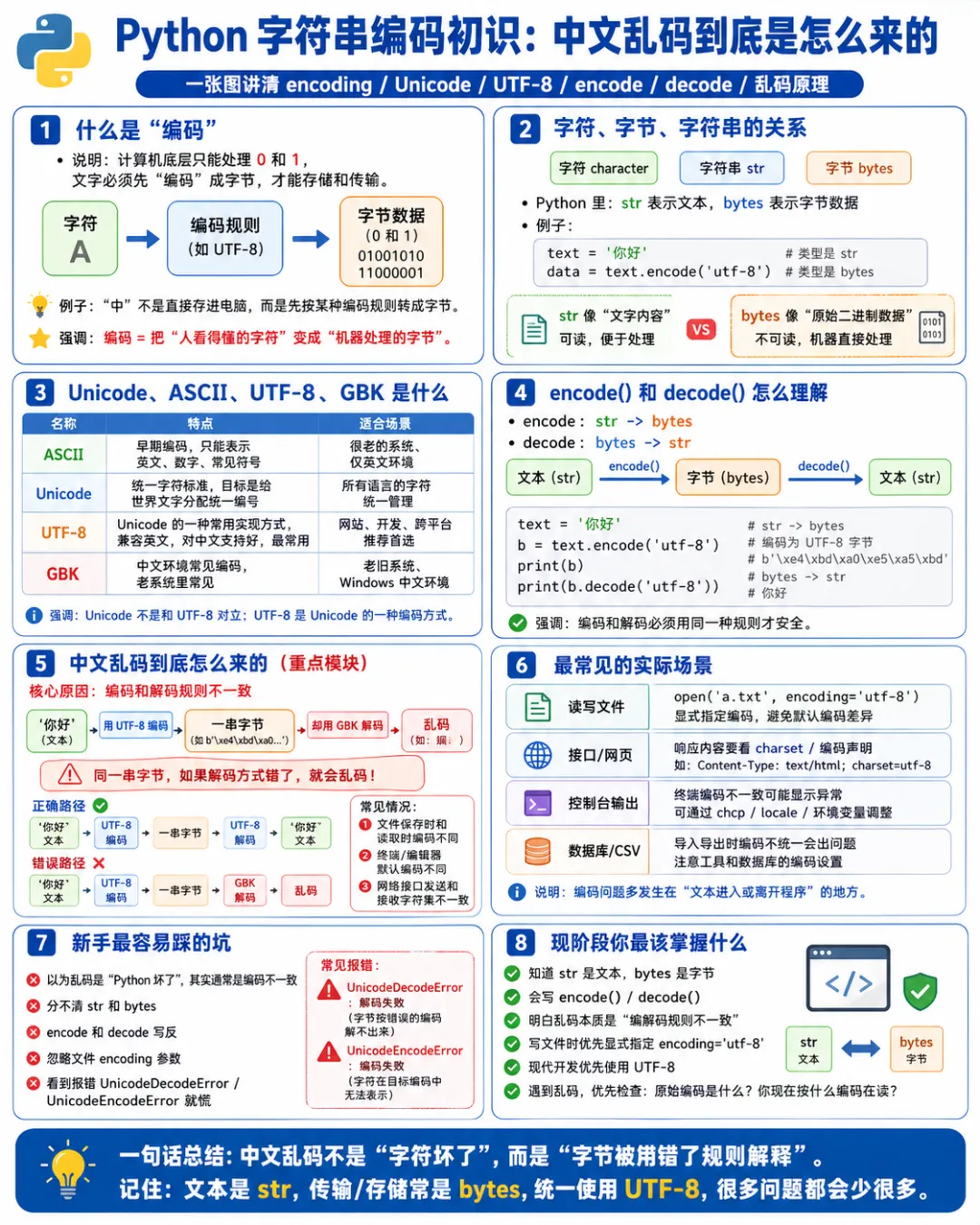
一、先说结论:乱码本质上不是字坏了,而是看错了
这是整章最重要的一句话。
很多人看到乱码时,第一反应是:
完了,文件坏了 完了,数据丢了 完了,中文被程序搞废了
其实很多时候,不是内容坏了,而是:
编码方式和解码方式没对上
你可以先把它理解成一件很生活化的事。
同一段暗号,必须用同一套规则去写、去看。 如果写的时候用甲规则,看的时候却用乙规则,那看到的内容自然会乱。
字符串编码也是一样。
文字本身不能直接存进计算机。 计算机底层只能处理数字和字节。 所以文字在进入计算机之前,必须先按照某种规则转换成字节。这个规则,就叫编码。 而当字节再重新变回文字时,也要按规则还原。这个过程,就叫解码。
如果编码和解码用的是同一套规则,文字就正常。 如果不是同一套规则,轻则乱码,重则直接报错。
二、为什么会有编码这回事
因为计算机不认识中文、英文、日文这些文字本身。 它最终认识的是二进制,也就是一串 0 和 1。
那问题来了:
我们平时写的是 你好、Python、北京、学生成绩,这些都是字符。 怎么才能让计算机存起来、传出去、再读回来呢?
答案就是:
先把字符按某种规则翻译成字节
比如字符 A,要翻译成什么数字 字符 中,要翻译成哪一串字节 字符 好,又要翻译成哪一串字节
这套对应规则,就是编码方案。
所以编码本质上是在做翻译。 它不是额外给你添麻烦,而是计算机和文字世界沟通时,必须经过的一层。
三、字符串和字节,不是一回事
这个点一定要分清。
在 Python 里,你平时写的中文字符串,像这样:
text = '你好,Python'
这叫字符串,也就是 str。
但真正存储、传输、写入文件、发送网络请求时,很多场景面对的并不是字符串,而是字节,也就是 bytes。
比如:
text = '你好'data = text.encode('utf-8')print(text)print(data)print(type(text))print(type(data))
输出大概是:
你好b'\xe4\xbd\xa0\xe5\xa5\xbd'<class 'str'><class 'bytes'>
这里你会看到两个世界:
一个是人能直接看懂的字符串 一个是程序底层更常处理的字节数据
很多编码问题,恰恰就出在这两者来回转换的过程中。
四、encode 是什么
encode() 的作用,就是把字符串按某种编码规则,变成字节。
看例子:
text = '你好'data = text.encode('utf-8')print(data)
输出会是一串字节内容。
你现在不用去死记这些字节长什么样。 你只要先记住这件事:
字符串经过 encode() 之后,就变成了字节
也就是说:
人能看懂的文字 先按规则翻译 变成计算机更适合处理的字节形式
这一步非常常见。
比如写文件、发网络请求、保存数据、跨系统传输时,都可能会遇到类似过程。
五、decode 是什么
和 encode() 相反,decode() 是把字节按某种规则还原成字符串。
看例子:
text = '你好'data = text.encode('utf-8')result = data.decode('utf-8')print(result)
输出:
你好
这个过程可以理解成:
先把中文翻译成字节 再按同一套规则翻译回来
只要前后规则一致,结果就正常。
所以你现在可以先记住一个最核心的组合:
字符串.encode(某种编码)字节.decode(某种编码)
这就是字符串和字节之间最常见的来回转换方式。
六、乱码到底是怎么产生的
现在我们把核心问题说透。
乱码最常见的原因不是编码本身,而是:
编码和解码不匹配
比如你先用 UTF-8 编码:
text = '你好'data = text.encode('utf-8')
这时候 data 这串字节,已经是按 UTF-8 规则生成的了。
如果你再用 UTF-8 解码:
print(data.decode('utf-8'))
当然正常。
可如果你不用 UTF-8 解码,而是换一套别的规则,比如 latin1:
text = '你好'data = text.encode('utf-8')print(data.decode('latin1'))
输出就会变成一串奇怪字符,大概像这样:
ä½ å¥½
你一看就知道,完了,乱码了。
但这里的数据其实没坏。 字节本身也没坏。 只是你拿错规则去解释它了。
所以乱码最本质的逻辑就是:
字节没变 解释方式变了 结果就乱了
七、为什么英文经常不容易乱码,中文却特别容易
这个问题很多人都会纳闷。
为什么英文看起来总是挺稳,中文老出事?
因为英文字符范围相对简单。 很多老编码方案都能兼容常见英文字符。 所以哪怕你编码解码没写得特别严谨,有时也不容易立刻暴露问题。
但中文就不一样。
中文字符多、编码方案更复杂,不同编码之间差异也更明显。 一旦规则没对上,问题通常马上就会显出来。
所以很多人误以为:
英文不会乱码 中文才会乱码
更准确的说法应该是:
英文更容易在不同编码里侥幸看起来还正常 中文更容易把问题暴露出来
这反而说明中文乱码并不是中文特殊,而是编码问题更明显。
八、常见编码有哪些
入门阶段你先记住三个名字就够用了:
UTF-8 GBK ASCII
1. ASCII
这是比较早、也比较简单的一套编码。 它主要覆盖常见英文字符、数字、符号这些内容。
所以如果你写的是纯英文、纯数字,ASCII 还能应付。 但它根本装不下中文。
比如:
text = 'hello'print(text.encode('ascii'))
没问题。
但如果你写:
text = '你好'print(text.encode('ascii'))
通常就会直接报错。 因为 ASCII 根本没有中文对应规则。
2. GBK
这是中文环境里很常见的一套编码。 很多老 Windows 程序、老文本文件、一些旧系统里经常会碰到。
3. UTF-8
这是现在最主流、最推荐、最通用的一套编码。 网页、接口、跨平台项目、现代开发环境里,UTF-8 出现频率极高。
入门阶段你只要牢牢记住一句就非常够用了:
现代 Python 开发里,优先使用 UTF-8
这会帮你避开很多不必要的坑。
九、一个特别关键的理解:编码不是字体
很多新手会把编码和字体混为一谈。
比如看到中文显示怪了,就以为是字体问题。 这两者不是一回事。
字体决定的是:
这个字长什么样,怎么显示出来
编码决定的是:
这个字底层怎么存、怎么传、怎么还原
字体像是外观。 编码像是身份证号和翻译规则。
你就算字体再漂亮,编码规则错了,看到的依然可能是乱码。 反过来,只要编码对了,就算字体普通,内容通常也能正常显示。
所以以后碰到乱码,先想到编码,别第一时间怪字体。
十、一个最经典的乱码案例
看下面这个完整例子:
text = '你好,Python'data = text.encode('utf-8')print('原始字节:', data)print('正确解码:', data.decode('utf-8'))print('错误解码:', data.decode('latin1'))
输出大致会是:
原始字节: b'...'正确解码: 你好,Python错误解码: ä½ å¥½ï¼\x8cPython
虽然乱码具体长什么样,和内容有关。 但核心现象你已经能看到:
同一串字节 用对规则,正常 用错规则,乱码
所以以后你再看到乱码,就别急着慌。 先问自己一个问题:
这段内容原来是用什么编码保存的 我现在是不是拿错规则去读它了
这个思路一旦建立起来,很多问题会一下子清楚很多。
十一、还有一种情况,不是乱码,而是直接报错
有时候规则不匹配,不会出现乱码,而是程序直接报错。
比如:
text = '你好'data = text.encode('utf-8')print(data.decode('ascii'))
这类代码很可能直接抛异常。
为什么?
因为 ASCII 根本解释不了这些字节,它不像 latin1 那样能硬着头皮全接住。 所以程序会明确告诉你:
这个解码方式不适合这段数据
这也说明,编码问题的表现不止一种。
有时候是乱码 有时候是异常 本质都还是同一个原因:
规则没对上
十二、文件为什么最容易出现乱码
因为文件天生就涉及存和读。
你把内容写进文件时,是一次编码。 你再把内容从文件里读出来时,又是一次解码。
如果写的时候和读的时候规则不一致,就特别容易出问题。
比如你用某种编码把中文写进文件, 结果读取时又忘了指定正确编码,或者编辑器默认用另一种规则打开, 那内容就可能乱码。
所以文件乱码不是文件脾气怪, 而是写和读这两个动作之间,编码没统一。
这也是为什么你后面学 open() 时,会频繁看到 encoding='utf-8' 这种写法。
它不是装饰品,而是在明确告诉程序:
请按 UTF-8 处理
十三、为什么很多教程总强调写文件时指定 encoding
因为不写,很多时候就变成了:
交给系统默认规则去猜
而不同电脑、不同系统、不同编辑器、不同环境,默认规则未必一样。 你今天在自己电脑上没事,换个环境就可能出问题。
所以一个特别实用、也特别重要的习惯就是:
读写文本文件时,尽量明确写出编码
比如:
with open('demo.txt', 'w', encoding='utf-8') as f: f.write('你好,Python')
再比如读取:
with open('demo.txt', 'r', encoding='utf-8') as f: content = f.read() print(content)
这样前后一致,就会稳很多。
十四、网页和接口为什么也绕不开编码
因为网页内容、本地文件、接口返回,本质上很多时候都是一串字节传来传去。
浏览器为什么能正常显示中文网页? 因为它知道该按什么规则把字节解释成文字。
接口为什么有时返回中文正常,有时却是一堆乱码? 很多时候也是编码识别没对上。
所以你后面学爬虫、接口请求时,会慢慢发现:
字符串问题到了实战里,最后常常会落到编码上
这也是为什么这一章虽然看起来偏基础,但它其实是很多方向的共同底层知识。
十五、为什么 UTF-8 现在这么重要
因为它兼容性强,跨平台能力好,中文英文都能正常处理,现代开发环境也普遍支持。
你可以先把它理解成现在最通用、最推荐的一套主流方案。
所以入门阶段你只要形成这个习惯,已经能避开很多坑:
能用 UTF-8,就优先用 UTF-8
当然,你以后还是会碰到 GBK、老系统文件、历史数据这些情况。 但大方向上,UTF-8 是最值得优先掌握和使用的。
十六、一个特别容易忽略的点:屏幕上看到正常,不代表编码就没问题
有时程序输出看起来正常, 只是因为你当前环境刚好默认规则和数据匹配。
但一旦换个编辑器、换个终端、换个系统、换台电脑,问题就暴露了。
所以编码这件事,不能只看 我这里现在正常。 更要看:
这个数据以后会不会被别的程序读 会不会跨平台 会不会传给别的系统 会不会被别人打开
这就是为什么专业一点的代码,总喜欢把编码写清楚。 因为靠猜默认值,短期省事,长期容易出坑。
十七、你可以把编码理解成两步翻译
这个理解方式特别适合新手。
第一步,字符变字节 这叫编码
第二步,字节变字符 这叫解码
只要前后翻译规则一致,内容就正常。 一旦前后翻译规则不一致,内容就乱。
你把这套逻辑真正记住,乱码问题就不再神秘了。
以后你不需要死记太多术语。 只要脑子里有这两个动作:
写出去时用了什么规则 读回来时是不是还用同一套规则
很多问题都能顺着找到原因。
十八、一个特别生活化的比喻
你可以把编码想成快递打包规则。
同样一件东西,打包时按某套规则装箱、贴标签。 收件人拆箱时,也得按同一套规则拆。
如果打包规则和拆箱规则一致,拿出来就正常。 如果打包时按甲规则装,拆的时候却按乙规则理解,那里面东西看起来就会乱。
文字进计算机、出计算机,差不多就是这个过程。
这个比喻不够技术,但对初学阶段特别够用。
十九、实际开发里最常见的几种应对思路
第一,优先使用 UTF-8。 第二,读写文件时明确指定编码。 第三,碰到乱码先查编码和解码规则是否一致。 第四,不要把编码问题和字体问题混为一谈。 第五,先分清你现在手里是字符串,还是字节。
尤其是最后一点,特别关键。
很多人一乱,就开始把 str 和 bytes 混着想。 一旦这两者分清,很多逻辑会立刻清楚不少。
二十、一个简单但很实用的判断思路
以后你一旦遇到中文乱码,可以按下面这个脑内流程过一遍。
这段内容原来是字符串,还是字节 如果是字节,它原本是按什么编码生成的 我现在是不是用另一种规则去解码了 如果是文件,是不是写和读的编码不一致 如果是网页或接口,是不是环境默认编码识别错了 是不是本来就该统一改成 UTF-8
你会发现,乱码问题一旦被拆成这些小问题,就没那么可怕了。
二十一、最容易犯的几个错
先说第一个。
把字符串和字节混成一回事。 看到一串内容就觉得都叫文本,结果在 encode() 和 decode() 上完全搞乱。
第二个错,是觉得乱码一定说明文件坏了。 其实很多时候只是解释方式错了。
第三个错,是读写文件时不写编码,全靠默认值运气。 短期可能没事,长期特别容易翻车。
第四个错,是以为只要是中文出问题,就是 Python 不行。 其实 Python 反而已经帮你把很多细节封装得很友好了。真正的问题通常还是编码规则没统一。
第五个错,是一看到编码就想背概念,结果越背越乱。 这一章最重要的不是术语,而是流程:
字符 → 字节 → 字符 前后规则一致才正常
二十二、一个最小练习:先感受编码和解码
你可以自己敲一下这段代码:
text = '你好'data = text.encode('utf-8')print(text)print(data)print(data.decode('utf-8'))
先感受三个层次:
原字符串 编码后的字节 再解码回来的字符串
这一步只要你亲眼跑一遍,很多抽象感会一下子下降很多。
二十三、再做一个乱码演示
再敲一下这个:
text = '你好'data = text.encode('utf-8')print(data.decode('latin1'))
你会看到乱码。
这个例子特别好,因为它把乱码的本质直接摆在你面前了:
不是字坏了 不是 Python 发疯了 而是你拿错规则去读它了
这比你死背一堆定义更有感觉。
二十四、你现在不需要背特别多编码名字
这一点我特别想强调。
入门阶段你不需要把几十种编码方案背得滚瓜烂熟。 你现在最重要的是建立这几个核心认知:
字符串和字节不是一回事 编码是字符串变字节 解码是字节变字符串 规则一致才正常 UTF-8 是现代开发最常见、最推荐的选择 中文乱码大多数时候是规则没对上
只要这几条扎实了,你后面碰到具体问题时,反而更容易查和解决。
二十五、练习题:这一章一定要亲手跑
下面这些练习非常建议你自己试一遍。
1. 把字符串 你好 编码成 UTF-8 字节
text = '你好'data = text.encode('utf-8')print(data)
2. 再把字节解码回字符串
print(data.decode('utf-8'))
3. 故意用错误方式解码,观察乱码现象
print(data.decode('latin1'))
4. 试着把纯英文字符串用 ASCII 编码
text = 'hello'print(text.encode('ascii'))
5. 试着把中文用 ASCII 编码,看看会发生什么
text = '你好'print(text.encode('ascii'))
这题大概率会报错,但这正是重点。 因为它能帮你真正理解:
不是所有编码都能装下所有字符。
6. 模拟读写文本文件时显式指定 UTF-8
with open('demo.txt', 'w', encoding='utf-8') as f: f.write('你好,Python')with open('demo.txt', 'r', encoding='utf-8') as f: print(f.read())
你把这些练习跑完,编码这件事就不会再只是一个听起来吓人的名词。
二十六、本章小结
这一章最重要的,不是记住多少术语,而是把乱码问题的核心逻辑真正想明白。
字符不能直接给计算机存储,所以要先编码成字节。 字节要重新显示成文字,又要再解码回来。 只要编码和解码规则一致,内容就正常。 规则不一致,就可能乱码,甚至直接报错。
你要牢牢记住的几个点是:
字符串和字节不是一回事。encode() 是把字符串变成字节。decode() 是把字节变回字符串。 UTF-8 是现在最常见、最推荐的编码方式。 读写文件时,尽量明确指定编码。 中文乱码大多数时候不是字坏了,而是规则没对上。
学会这一章以后,你对字符串世界的理解会开始更完整。 因为你不再只会操作字符表面,而开始理解它们在计算机里到底是怎么存、怎么传、怎么还原的。
下一章我们继续讲 字符串处理实战:批量清洗文本数据。 到了那里,你会发现,前面学过的 split、replace、strip、查找判断这些东西,一旦放进真实数据清洗场景里,就会真正开始像工具。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
