搭 Agent 离不开框架,但真正让你开发顺手的,往往是那些不起眼的工具库。
框架负责编排 Agent 的运行流程,但 Agent 要真正落地,你还得处理一堆脏活累活:调不同的 LLM API、计算 Token 防超限、从 LLM 的自由文本里提取结构化数据、给 Agent 加上重试和容错、调试时看清内部状态、在终端里把运行过程展示得漂漂亮亮……
这些事情,每一个都有专门的库替你搞定。今天介绍 6 个在 AI Agent 开发中出场率极高的 Python 工具库,它们不是框架,但几乎每个靠谱的 Agent 项目里都有它们的身影。
LiteLLM —— 一个接口搞定 100+ 大模型
做 Agent 开发最头疼的事情之一,就是各家大模型的 API 格式五花八门。OpenAI 一套、Anthropic 一套、Gemini 一套、Azure 又是一套……光是处理不同 Provider 的认证方式、请求格式和错误类型,就能写出一堆 if-else。
LiteLLM 的解决方案非常暴力但有效:把所有大模型的 API 统一成 OpenAI 的格式。不管是 Claude、Gemini、Bedrock 还是 Azure,调用方式完全一样。
from litellm import completion
# 调 OpenAI
response = completion(
model="openai/gpt-4o",
messages=[{"role": "user", "content": "你好"}]
)
# 切 Anthropic?只改 model 参数就行
response = completion(
model="anthropic/claude-sonnet-4-20250514",
messages=[{"role": "user", "content": "你好"}]
)
# 切 Gemini?还是只改 model 参数
response = completion(
model="gemini/gemini-2.0-flash",
messages=[{"role": "user", "content": "你好"}]
)
但这只是冰山一角。LiteLLM 真正的价值在于生产级的路由能力:
自动 Fallback。主模型挂了或者触发限流?一行配置自动切到备用模型,Agent 不会中断。
费用追踪。按 key/团队/用户维度自动统计 Token 消耗和费用,再也不用月底对着账单发呆。
负载均衡。多个部署之间分配请求,支持 RPM/TPM 限制。
代理模式(AI Gateway)。部署一个 LiteLLM 代理服务,团队里所有人都通过统一的 OpenAI 格式访问所有模型。Netflix 的工程师说,用 LiteLLM 之后,新模型发布一天内就能让全团队用上,以前这得花好几个小时。
GitHub Stars:40K+ | 安装:pip install litellm
tiktoken —— Token 计数,快到离谱
做 Agent 不能不关心 Token。上下文窗口多大、一次调用花了多少 Token、距离超限还有多少余量——这些信息决定了 Agent 的行为策略。
tiktoken 是 OpenAI 官方开源的 BPE 分词器,专门用来快速计算 Token 数量。它用 Rust 写了核心计算逻辑,速度比同类分词器快 3-6 倍。
import tiktoken
# 获取 GPT-4 的编码器
enc = tiktoken.encoding_for_model("gpt-4o")
# 计算一段文本的 Token 数
text = "请帮我分析这份季度报告中的关键数据"
tokens = enc.encode(text)
print(f"Token 数量: {len(tokens)}")
# 计算一组消息的 Token 数(更接近实际 API 调用)
messages = [
{"role": "system", "content": "你是一个数据分析助手"},
{"role": "user", "content": text}
]
# 每条消息大约有 4 个 Token 的额外开销
total = sum(len(enc.encode(m["content"])) + 4for m in messages)
print(f"总 Token: {total}")
在 Agent 开发中,tiktoken 的典型使用场景:
上下文窗口管理。在发送请求前计算 Token 数,如果快超限了就自动压缩或裁剪历史对话。
费用预估。调用 API 之前先算 Token,在预算范围内选择合适的模型。
智能截断。Agent 的对话历史不断增长,用 tiktoken 精确计算每条消息的长度,保留最重要的部分。
几乎所有主流 Agent 框架底层都在用 tiktoken 来做 Token 计算。它是基础设施级别的东西。
GitHub Stars:17.7K+ | 安装:pip install tiktoken
Instructor —— 让 LLM 老老实实输出结构化数据
LLM 天生擅长生成流畅的自然语言,但它吐出来的东西经常不符合你期望的格式。你让它返回 JSON,它给你 JSON 外面裹一圈 Markdown;你让它返回数字,它返回"大约二十五"。
Instructor 就是来解决这个问题的。它基于 Pydantic,让你用 Python 类型注解定义你想要的数据结构,然后自动确保 LLM 的输出严格符合这个结构。
import instructor
from pydantic import BaseModel, Field
classActionPlan(BaseModel):
"""Agent 的行动计划"""
thought: str = Field(description="思考过程")
action: str = Field(description="要执行的动作")
confidence: float = Field(description="置信度 0-1")
# 创建客户端
client = instructor.from_provider("openai/gpt-4o")
# 一次调用,直接拿到结构化数据
plan = client.chat.completions.create(
response_model=ActionPlan,
messages=[{"role": "user", "content": "用户说不想续费了,该怎么办?"}]
)
print(plan.thought) # "用户有流失风险,需要挽留"
print(plan.action) # "提供限时优惠方案"
print(plan.confidence) # 0.85
Instructor 的核心机制是"验证 + 重试":如果 LLM 的输出不符合 Pydantic 模型的定义,Instructor 会自动把验证错误反馈给 LLM,让它重新生成。这个循环非常有效,实际使用中结构化输出的成功率能从 85-95% 提升到 97-99.5%。
在 Agent 开发中,Instructor 的用处太广了:
工具调用的参数解析。Agent 需要从用户的自然语言中提取出精确的函数参数。
多步推理的结构化输出。让 Agent 每一步都返回规范的思考-行动-观察三元组。
信息抽取。从非结构化文本中提取人名、日期、金额等结构化信息。
Instructor 支持 15+ LLM 提供商,包括 OpenAI、Anthropic、Gemini、Ollama 等。月下载量超过 300 万,被 OpenAI、Google、Microsoft 内部团队使用。
GitHub Stars:12.8K+ | 安装:pip install instructor
Rich —— 终端输出好看得不像话
如果你在命令行里调试 Agent,一定会对这个问题深有体会:Agent 的运行过程输出又多又杂,文本、JSON、错误信息、工具调用结果搅在一起,看得人眼花。
Rich 是 Python 终端美化的王者。它能把你的终端输出变成一个像样的界面:彩色文本、表格、进度条、树形结构、Markdown 渲染、语法高亮……全都有。
from rich.console import Console
from rich.table import Table
from rich.panel import Panel
from rich.live import Live
import time
console = Console()
# 漂亮的 Agent 运行日志
console.print(Panel("[bold cyan]Agent 启动[/]", title="AI Agent"))
# 用表格展示工具调用结果
table = Table(title="工具调用记录")
table.add_column("步骤", style="cyan")
table.add_column("工具", style="magenta")
table.add_column("耗时", justify="right")
table.add_column("状态")
table.add_row("1", "web_search", "1.2s", "[green]成功[/]")
table.add_row("2", "read_file", "0.3s", "[green]成功[/]")
table.add_row("3", "write_file", "0.5s", "[red]失败[/]")
console.print(table)
# 实时进度展示
with Live(console=console, refresh_per_second=4) as live:
for step in range(5):
live.update(f"[bold]思考中...[/] 步骤 {step+1}/5")
time.sleep(0.5)
live.update("[bold green]任务完成![/]")
在 Agent 开发中,Rich 的典型用法:
Agent 运行过程可视化。用 Rich 的 Live 组件实时展示 Agent 的思考过程和工具调用。
调试信息展示。用 Tree 组件展示嵌套的 Agent 对话历史,用 Table 展示 Token 使用统计。
CLI 工具美化。如果你的 Agent 有命令行界面,Rich 能让它看起来专业得多。
很多 AI 相关的库都内置了 Rich 作为依赖,包括 Instructor、Pydantic AI、LangChain 等。它是 Agent 开发工具链里"用了就回不去"的那种库。
GitHub Stars:50K+ | 安装:pip install rich
Tenacity —— 给 Agent 加上"不死之身"
LLM 调用太不稳定了。网络超时、触发限流(429)、模型过载(503)、响应格式错误……一个健壮的 Agent 必须能应对这些情况,而不是一遇到错误就挂掉。
Tenacity 是 Python 里最优雅的重试库。它的 API 用装饰器风格,非常 Pythonic,而且功能远不止"重试 N 次"那么简单。
from tenacity import (
retry, stop_after_attempt, wait_exponential,
retry_if_exception_type, before_sleep_log
)
import openai
import logging
# Agent 调用 LLM 的标准重试策略
@retry(
stop=stop_after_attempt(3), # 最多重试 3 次
wait=wait_exponential(multiplier=1, max=10), # 指数退避:1s, 2s, 4s...
retry=retry_if_exception_type(
(openai.RateLimitError, openai.APITimeoutError, openai.APIConnectionError)
),
before_sleep=before_sleep_log(logging.getLogger(), logging.WARNING)
)
defcall_llm(messages):
"""带自动重试的 LLM 调用"""
response = openai.chat.completions.create(
model="gpt-4o",
messages=messages
)
return response.choices[0].message.content
# 直接用,不用关心重试逻辑
result = call_llm([{"role": "user", "content": "分析一下这段代码"}])
Tenacity 的几个杀手级特性:
条件重试。不是所有错误都应该重试。429 限流值得重试,401 认证错误重试也没用。Tenacity 让你精确控制哪些错误触发重试。
指数退避。连续重试之间等待时间指数增长(1秒、2秒、4秒……),避免雪崩式重试把 API 打爆。
重试前回调。每次重试前可以执行自定义逻辑,比如记录日志、发送告警。
上下文感知。可以在重试逻辑中访问之前的异常信息,做更智能的决策。
注意到了吗?Instructor 内部就用了 Tenacity 做验证失败后的自动重试。这两个库经常一起出现。
GitHub Stars:6K+ | 安装:pip install tenacity
Logfire —— 看透 Agent 的一切
Agent 的调试是出了名的难。一个 Agent 跑起来,内部可能在同时做多轮对话、调用好几个工具、维护一堆状态。出了 bug 你根本不知道是哪一步出了问题。
Logfire 是 Pydantic 团队开发的可观测性平台。它的理念很简单:让你的 Agent 变得"透明可见"——每一步在做什么、调了哪个 LLM、花了多少 Token、返回了什么结果,全部清清楚楚。
from pydantic_ai import Agent
import logfire
# 一行开启 Logfire
logfire.configure()
# Pydantic AI 自动集成,无需额外配置
agent = Agent('openai:gpt-4o', instruments=True)
# 每次运行都会自动记录到 Logfire 面板
result = agent.run_sync("帮我分析这份数据")
但 Logfire 不只是 Pydantic AI 的配套工具。它是一个通用的 OpenTelemetry 可观测性平台,可以和任何框架配合使用:
LLM 调用追踪。每次 LLM 调用的输入、输出、延迟、Token 消耗都被完整记录。
工具调用监控。Agent 调了什么工具、参数是什么、返回了什么结果、耗时多久。
成本分析。自动统计每个 Agent、每个用户的 Token 消耗和对应费用。
异常诊断。当 Agent 出错时,可以在 Logfire 面板里看到完整的调用链,快速定位问题。
性能优化。找出 Agent 运行中的瓶颈——是 LLM 响应太慢?工具执行太久?还是上下文太长?
如果你已经用过 LangFuse 或 LangSmith,可以把 Logfire 理解为同类型的工具,但它的特别之处在于与 Python 生态的深度融合——Pydantic 模型的验证过程、FastAPI 请求、SQL 查询,甚至 Python 函数的执行时间,都可以一行代码接入 Logfire 的追踪体系。
对于需要上生产的 Agent 系统,可观测性不是可选项,而是必备品。Logfire 是目前 Python 生态里与 Agent 开发集成度最高的选择。
官网:logfire.pydantic.dev | 安装:pip install logfire
小结
| | |
|---|
| 统一 100+ 大模型 API,自动 Fallback 和费用追踪 | |
| | |
| | |
| | |
| | |
| | |
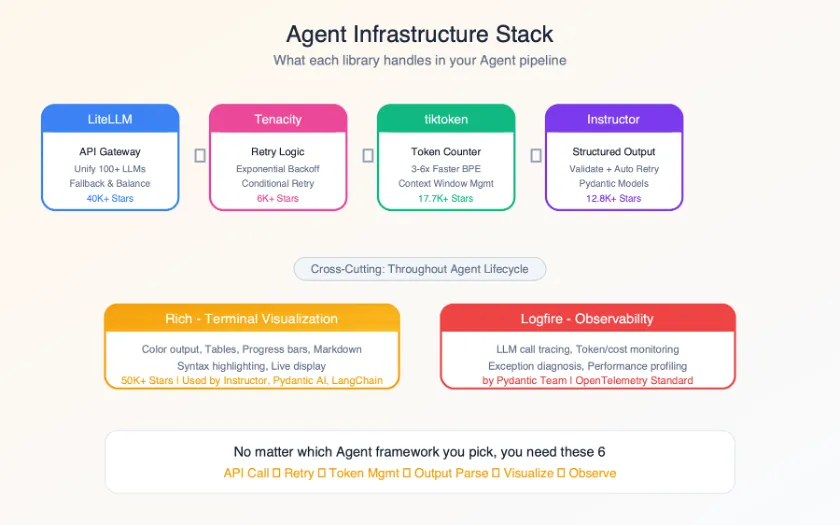
这 6 个库的组合几乎覆盖了 Agent 开发中除了框架之外的所有"基础设施"需求:LiteLLM 管模型调用、tiktoken 管 Token 计算、Instructor 管输出解析、Tenacity 管容错重试、Rich 管终端展示、Logfire 管可观测性。
框架选哪个可以吵三天三夜,但这些工具库,不管你用什么框架,大概率都绕不开。
参考资料:各库官方文档、GitHub 仓库、PyPI 页面

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
