做研究时,你是不是经常遇到这样的困境:
- • 想快速了解某个领域的研究热点,却只能一篇篇手动翻
别慌!今天这篇文章,教你用 Python 批量处理 PDF 文献 + 生成词云图 + 词频统计,一套组合拳,让你 10 分钟摸清一个领域的研究脉络。
适用场景
- • 文献综述:快速了解某领域的高频关键词和研究热点
- • 政策文本分析:分析政府工作报告、白皮书等长文本的政策重点
- • 舆情分析:处理社交媒体评论、新闻报道等大批量文本
一、环境准备
1.1 安装依赖
pip install pdfplumber jieba wordcloud matplotlib numpy
各库作用说明:
| |
|---|
pdfplumber | |
jieba | |
wordcloud | |
matplotlib | |
numpy | |
1.2 中文字体配置(Mac 用户必看)
import matplotlibfrom matplotlib import font_manager# macOS 系统字体路径(推荐用宋体)font_path = '/System/Library/Fonts/Supplemental/Songti.ttc'prop = font_manager.FontProperties(fname=font_path)matplotlib.rcParams['font.family'] = prop.get_name()matplotlib.rcParams['axes.unicode_minus'] = False
Mac 用户注意:系统必须指定中文字体路径,否则词云里中文会变成方块。
二、核心代码:四步搞定文献分析
2.1 第一步:批量提取 PDF 文本
import pdfplumberimport globimport osdef extract_text_from_pdf(pdf_path, max_pages=10): """从单个 PDF 提取文本(可限制页数加速)""" text = "" with pdfplumber.open(pdf_path) as pdf: total = len(pdf.pages) for i in range(min(total, max_pages)): page_text = pdf.pages[i].extract_text() if page_text: text += page_text + "\n" return textdef batch_extract_text(pdf_folder): """批量提取文件夹中所有 PDF""" pdf_files = glob.glob(os.path.join(pdf_folder, "*.pdf")) texts_dict = {} for pdf_path in pdf_files: filename = os.path.basename(pdf_path) text = extract_text_from_pdf(pdf_path) texts_dict[filename] = text return texts_dict# 使用方法pdf_folder = "/path/to/your/papers"texts_dict = batch_extract_text(pdf_folder)
2.2 第二步:中文分词
import jiebafrom collections import Counter# 定义停用词(根据领域可自行添加)STOPWORDS = { '的', '了', '是', '在', '和', '就', '不', '人', '都', '一', '个', '上', '也', '很', '到', '说', '要', '去', '你', '会', '着', '没有', '研究', '分析', '方法', '结果', '本文', '提出', '发展', '问题'}def segment_text(text, stopwords=STOPWORDS): """ 对中文文本分词并过滤 - 过滤停用词 - 过滤纯数字、标点 - 保留 2 个字符以上的词 """ words = jieba.lcut(text) filtered = [ w for w in words if (len(w) >= 2 and w not in stopwords and not w.isdigit()) ] return filtered# 示例all_text = "".join(texts_dict.values()) # 合并所有文献words = segment_text(all_text)word_counts = Counter(words)
2.3 第三步:TF-IDF 关键词提取
除了词频统计,还可以使用 TF-IDF 算法 提取每篇文献的关键词——高频词不一定重要(比如"发展""研究"这类通用词),TF-IDF 能识别出真正有区分度的关键词。
import jieba.analysedef get_keywords_by_tf_idf(text, top_k=20): """ 使用 TF-IDF 算法提取关键词 返回:[(关键词, 权重), ...] """ keywords = jieba.analyse.extract_tags( text, topK=top_k, withWeight=True # 返回权重 ) return keywords# 示例keywords = get_keywords_by_tf_idf(all_text, top_k=30)print(keywords)
2.4 第四步:可视化
词云图
from wordcloud import WordCloudimport matplotlib.pyplot as pltdef plot_wordcloud(word_counts, save_path=None): """生成词云图""" font_path = '/System/Library/Fonts/Supplemental/Songti.ttc' wc = WordCloud( font_path=font_path, width=1200, height=600, background_color='white', max_words=100, max_font_size=100, min_font_size=10, colormap='Blues', # 可选:Blues/Oranges/Greens 等 prefer_horizontal=0.7, ) wc.generate_from_frequencies(word_counts) plt.figure(figsize=(15, 8)) plt.imshow(wc, interpolation='bilinear') plt.axis('off') plt.show() if save_path: wc.to_file(save_path)# 调用plot_wordcloud(word_counts, save_path='wordcloud.png')
词频柱状图
def plot_word_frequency(word_counts, top_n=30, save_path=None): """绘制 Top N 高频词柱状图""" import matplotlib from matplotlib import font_manager font_path = '/System/Library/Fonts/Supplemental/Songti.ttc' prop = font_manager.FontProperties(fname=font_path) matplotlib.rcParams['font.family'] = prop.get_name() top_words = word_counts.most_common(top_n) plt.figure(figsize=(12, 8)) plt.barh( range(len(top_words)), [w[1] for w in top_words], color='steelblue' ) plt.yticks(range(len(top_words)), [w[0] for w in top_words], fontproperties=prop) plt.xlabel('词频') plt.title(f'Top {top_n} 高频词') plt.gca().invert_yaxis() plt.tight_layout() if save_path: plt.savefig(save_path, dpi=150, bbox_inches='tight') plt.show()# 调用plot_word_frequency(word_counts, top_n=30)
三、实战效果演示
以 45篇中非经贸研究文献 为例,演示完整流程的真实效果:
3.1 词云图

3.2 词频统计 Top 25
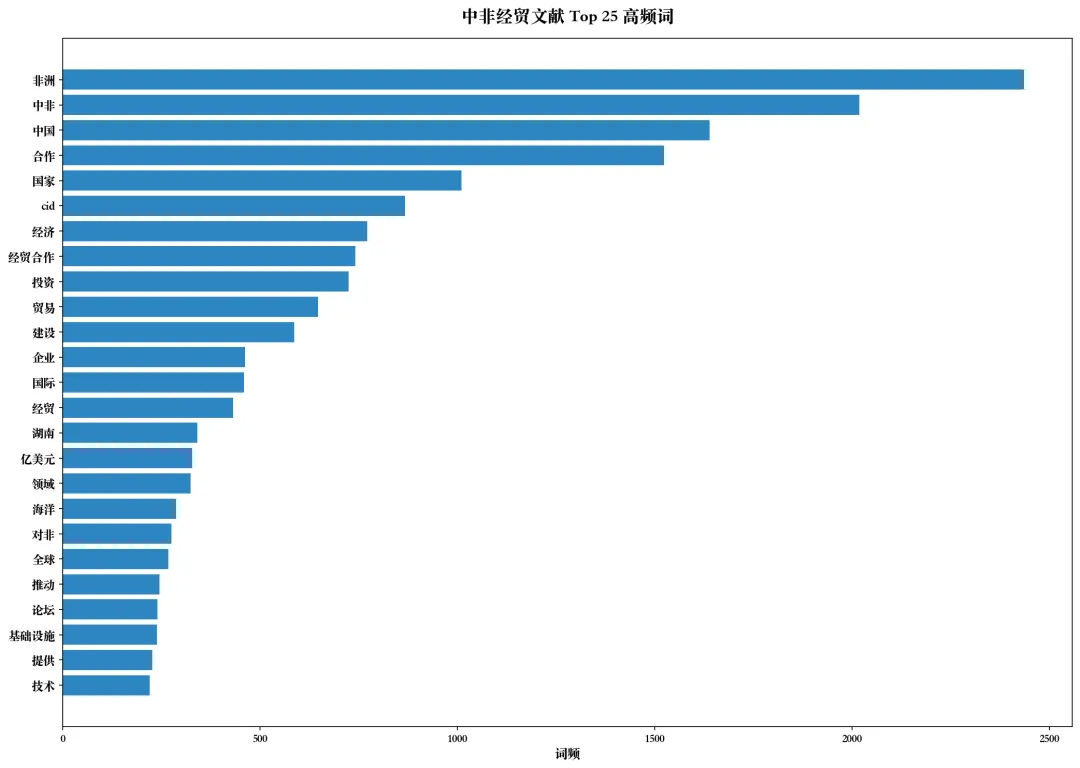
3.3 高频词提取结果(基于45篇真实文献)
| | |
|---|
| 非洲 | |
| 中非 | |
| 中国 | |
| 合作 | |
| 国家 | |
| | |
| 经贸合作 | |
| 投资 | |
| 贸易 | |
| | |
| | |
| | |
| 湖南 | |
| | |
| 基础设施 | |
| 一带一路 | |
| | |
| 标准 | |
| | |
| | |
3.4 研究热点发现
从词频分析可以看出,当前中非经贸研究的 三大核心议题:
- 3. 战略平台(一带一路、基础设施、湖南/博览会)
四、进阶技巧
4.1 自定义停用词表
针对学术文献,建议添加领域专有停用词:
ACADEMIC_STOPWORDS = { # 通用词 '研究', '分析', '方法', '结果', '本文', '提出', # 虚词 '因此', '所以', '因为', '虽然', '但是', '然而', # 程度副词 '非常', '十分', '特别', '尤其', '相当'}STOPWORDS.update(ACADEMIC_STOPWORDS)
4.2 多篇文献对比分析
如果有多篇文献,可以做横向对比——词频热力图:
import numpy as npimport matplotlib.pyplot as pltdef plot_heatmap(texts_dict, top_words=30): """绘制文献-词汇热力图""" filenames = sorted(texts_dict.keys()) # 获取全局高频词 all_text = " ".join(texts_dict.values()) all_words = segment_text(all_text) top_global = [w for w, _ in Counter(all_words).most_common(top_words)] # 构建词频矩阵 matrix = np.zeros((len(filenames), len(top_global))) for i, fname in enumerate(filenames): words = segment_text(texts_dict[fname]) counts = Counter(words) for j, word in enumerate(top_global): matrix[i, j] = counts.get(word, 0) # 绘制热力图 fig, ax = plt.subplots(figsize=(16, 10)) im = ax.imshow(matrix, cmap='YlOrRd', aspect='auto') plt.colorbar(im, ax=ax, label='词频') ax.set_xticks(np.arange(len(top_global))) ax.set_yticks(np.arange(len(filenames))) ax.set_xticklabels(top_global, rotation=45, ha='right') ax.set_yticklabels(filenames) plt.show()
4.3 关键词时序变化
如果文献有时间维度,可以追踪某些关键词随时间的出现频率变化:
def plot_timeline(texts_dict, keywords=['合作', '投资', '一带一路']): """绘制关键词时序变化图""" filenames = sorted(texts_dict.keys()) for kw in keywords: freq = [texts_dict[f].count(kw) for f in filenames] plt.plot(filenames, freq, marker='o', label=kw) plt.xlabel('文献编号') plt.ylabel('出现频次') plt.title('关键词时序变化') plt.legend() plt.xticks(rotation=45, ha='right') plt.show()
注意事项
- 1. PDF 扫描件无法提取文本:如果 PDF 是扫描图片生成的,需要先做 OCR(如使用
pytesseract) - 2. macOS 必须指定中文字体路径:否则词云中文会显示为方块,推荐用
/System/Library/Fonts/Supplemental/Songti.ttc - 3. 英文文献无需分词:可直接用空格分隔,处理逻辑需要微调
- 4. 文献量太大时:建议增加停用词,避免词云过于拥挤;同时可限制每篇提取的页数(
max_pages 参数) - 5. 部分 PDF 可能损坏:代码中有 try-except 保护,单个文件失败不影响整体
结语
这套工具特别适合:
核心就四步:提取文本 → 分词 → 统计 → 可视化,10 行 Python 代码搞定批量文献分析。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
