microGPT代码详解:200行纯Python无库实现GPT训练与推理
- 2026-07-03 06:21:36
 「200行代码剥离GPT算法核心」
「200行代码剥离GPT算法核心」
作者Andrej Karpathy 是人工智能领域极具影响力的研究者、工程师与科普者,深耕大语言模型与计算机视觉领域多年,以“将复杂AI技术拆解为极简本质”而闻名。他曾担任特斯拉AI总监,主导自动驾驶系统的计算机视觉与机器学习研发,推动了自动驾驶技术的迭代升级;同时也是OpenAI早期核心成员,深度参与了早期大语言模型的研发工作,见证并推动了生成式AI的起步与发展。
本次的 microGPT 更是其十年技术积累的集大成之作,用200行纯Python代码剥离了GPT的核心算法,让普通人也能直观理解大语言模型的底层逻辑。他还通过视频、博客等形式,用通俗的语言讲解AI核心原理,成为无数AI学习者的入门引路人。

这是一篇关于作者全新艺术项目microGPT的极简指南——一个仅 200行纯Python、零外部依赖的单文件脚本,就能完成一个GPT的训练与推理。参考https://karpathy.github.io/2026/02/12/microgpt/
这份文件包含了实现GPT所需的全部算法核心:文档数据集、分词器、自动微分引擎、类GPT‑2的神经网络架构、Adam优化器、训练循环与推理循环。除此之外的一切,都只是为了效率。作者已经无法再将它简化分毫。
这个脚本是作者过往多个项目(micrograd、makemore、nanoGPT等)的集大成之作,也是作者十年来执念于将大语言模型剥离到最本质要素的结晶。作者觉得它美得令人心动。它甚至能完美地排版成三栏。
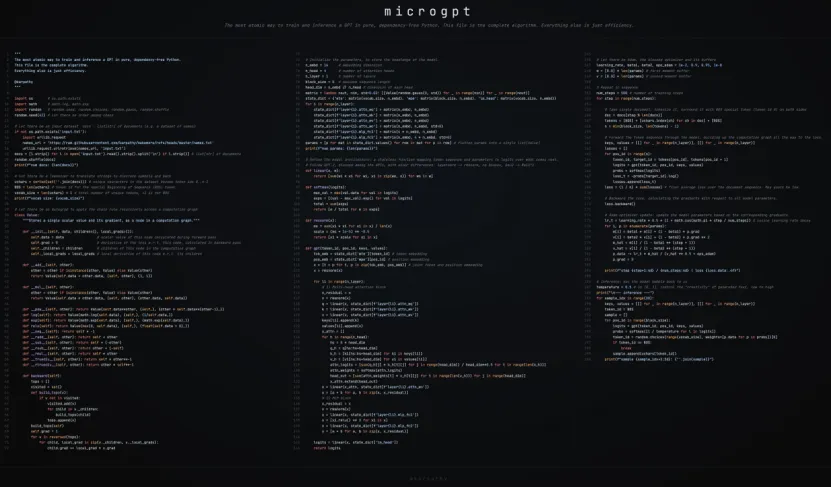
microGPT用纯Python、零依赖训练与推理GPT的最原子方式。
这一个文件,就是完整的算法。其余一切,都只是效率。
完整源码 GitHub Gist:microgpt.py
网页版:karpathy.ai/microgpt.html
但是不要小看这两百行,由于高度浓缩,蕴含的信息量非常大,相当于把反向传播、计算图、自动微分,注意力机制(著名论文《All you need is attention》),optimizer(这里是Adam,不是SGD),(交叉熵)损失函数,残差连接,层归一化,Tokenizer ,词嵌入,KV cache等等重要概念一网打尽(参考Andrej Karpathy's microGPT Architecture — Complete Guide - DEV Community)。
更不提softmax,linear计算,激活函数,MLP等等常规概念。
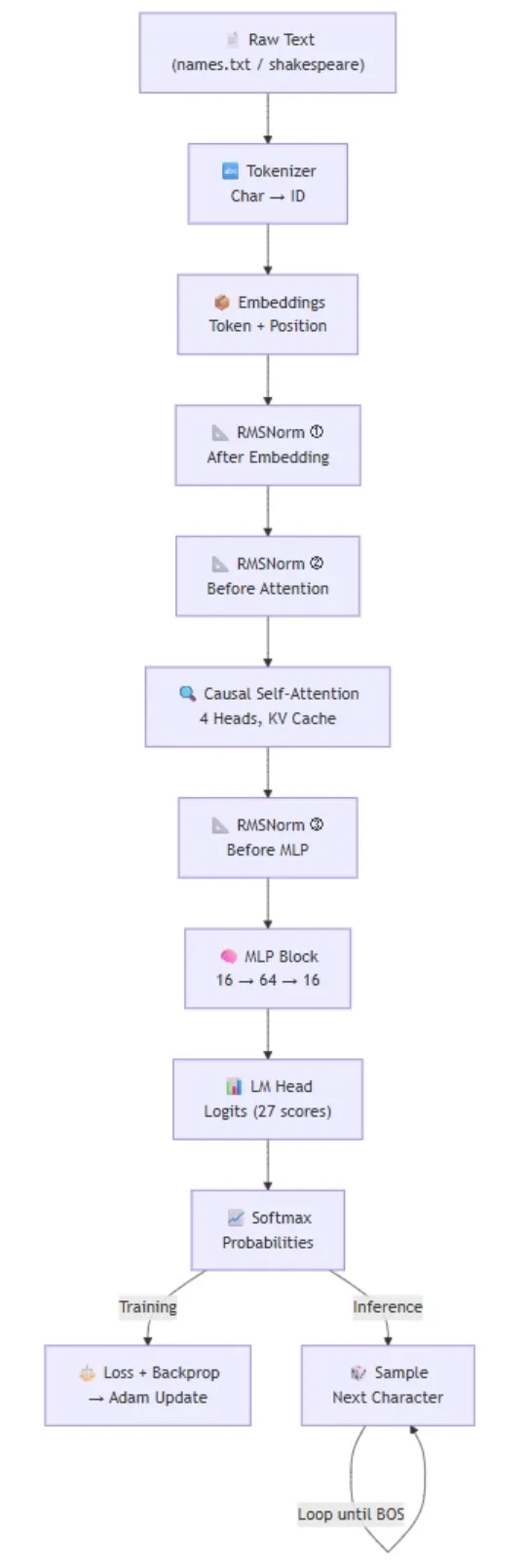
大语言模型的燃料是文本流,可按文档划分。工业级场景里每份文档通常是一张网页,而在 microGPT 中,作者用更简单的例子:32,000个名字,一行一个。
# 定义输入数据集 docs:字符串列表,每份文档是一个名字if not os.path.exists('input.txt'):import urllib.requestnames_url = 'https://raw.githubusercontent.com/karpathy/makemore/refs/heads/master/names.txt'urllib.request.urlretrieve(names_url, 'input.txt')docs = [l.strip() for l in open('input.txt').read().strip().split('\n') if l.strip()]random.shuffle(docs)print(f"num docs: {len(docs)}")
数据集长这样,每个名字就是一份文档(一个doc,一个文档,就是一个名字):
emma
olivia
ava
isabella
sophia
charlotte
mia
amelia
harper
...(后续约32,000个名字)
一个文档是一个名字,那么单个 Token 是模型可识别的最小离散单位(文档中即单个字符或特殊标识 BOS),比如[BOS, e, m, m, a, BOS]是六个Token。
模型的目标是学习数据中的模式,然后生成共享统计规律的全新、合理的文档。先剧透一下:脚本跑完后,模型会“幻想”出像这样的新名字:
sample 1: kamon
sample 2: ann
sample 3: karai
sample 4: jaire
sample 5: vialan
sample 6: karia
sample 7: yeran
sample 8: anna
sample 9: areli
sample 10: kaina
sample 11: konna
sample 12: keylen
sample 13: liole
sample 14: alerin
sample 15: earan
sample 16: lenne
sample 17: kana
sample 18: lara
sample 19: alela
sample 20: anton
看起来不算惊人,但从 ChatGPT 这类模型的视角看,你和它的对话不过是一份长相奇特的“文档”。当你用提示词初始化这份文档时,模型给出回复,本质上只是一次统计式文档补全。
神经网络只认数字,不认字符。作者需要把文本转成整数 token ID,再转回来。
工业级分词器(如 GPT‑4 用的 tiktoken)为效率会处理字符块,但最简单的分词器就是:给数据集中每个唯一字符分配一个整数(token ID)。
# 分词器:字符串 ↔ 离散符号互转uchars = sorted(set(''.join(docs))) # 数据集中所有唯一字符,成为 0~n-1 的 tokenBOS = len(uchars) # 特殊 token:序列开始(Begin of Sequence)vocab_size = len(uchars) + 1 # 总词表大小,+1 是 BOSprint(f"vocab size: {vocab_size}")
这里收集所有唯一字符(这里就是小写字母 a–z),排序后按索引分配 ID。这些整数本身没有任何语义,换成表情符号也完全可以。
额外加一个特殊 token BOS,作为分隔符,告诉模型“一份新文档从这里开始/到这里结束”。训练时每份文档会被BOS 包裹:
[BOS, e, m, m, a, BOS]
模型会学到:BOS 开启一个新名字,另一个 BOS 结束它。最终词表大小为 27(26个小写字母 + 1个BOS)。
在模型训练与推理过程中,token_id、pos_id、target_id 是三个核心输入参数,贯穿整个流程,其含义与作用如下:
token_id(token标识符):当前输入模型的token对应的整数ID,本质是字符的编码(由分词器分配,如字符'e'对应某个固定整数)。模型通过该ID获取对应的token嵌入向量,从而识别“当前输入的是什么字符”,是模型感知输入内容的核心参数,训练与推理场景中均会用到。
pos_id(位置标识符):当前token在序列中的位置索引(从0开始计数)。模型通过该ID获取对应的位置嵌入向量,从而感知字符在序列中的顺序(如名字“emma”中,第一个'm'和第二个'm'的pos_id不同),确保模型能捕捉到文本的顺序特征,训练与推理场景中含义完全一致。
target_id(目标标识符):仅用于训练场景,指当前token的下一个token对应的整数ID,是模型需要预测的目标字符编码。也就是target_id是预测出的token的token_id。模型通过对比预测结果与target_id,计算损失值,进而通过反向传播优化参数,实现“学习预测下一个字符”的核心训练目标。
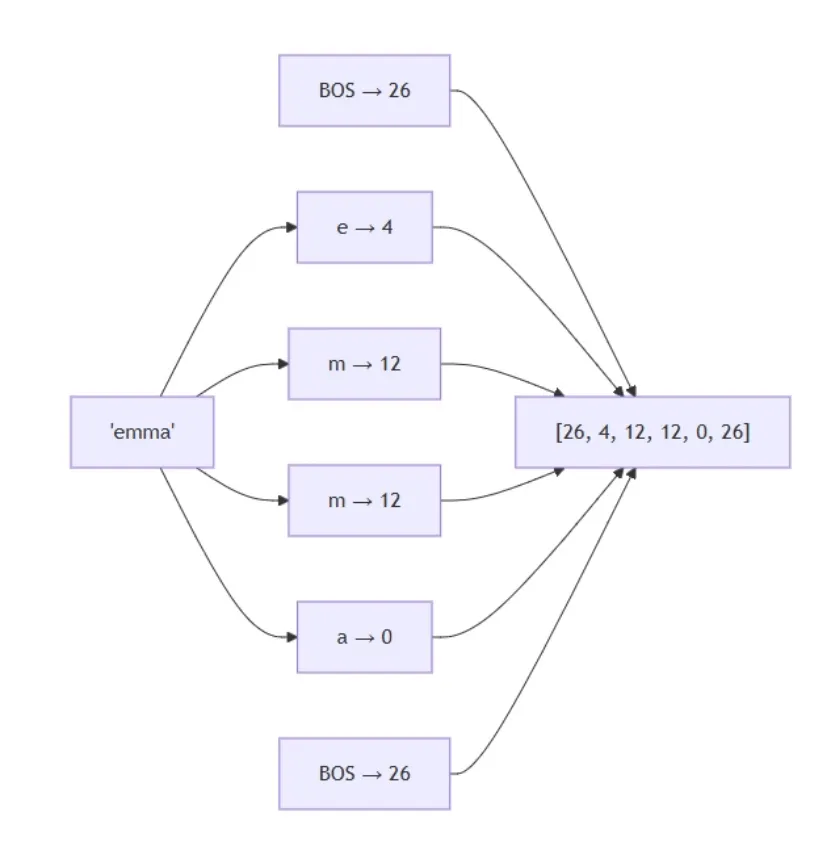
三者协同作用:token_id告诉模型“输入是什么”,pos_id告诉模型“输入在什么位置”,target_id告诉模型“应该预测什么”,共同支撑模型的训练与推理流程。
训练神经网络需要梯度:对每个参数,作者要知道“把它微微上调一点,损失会上升还是下降、幅度多大”。
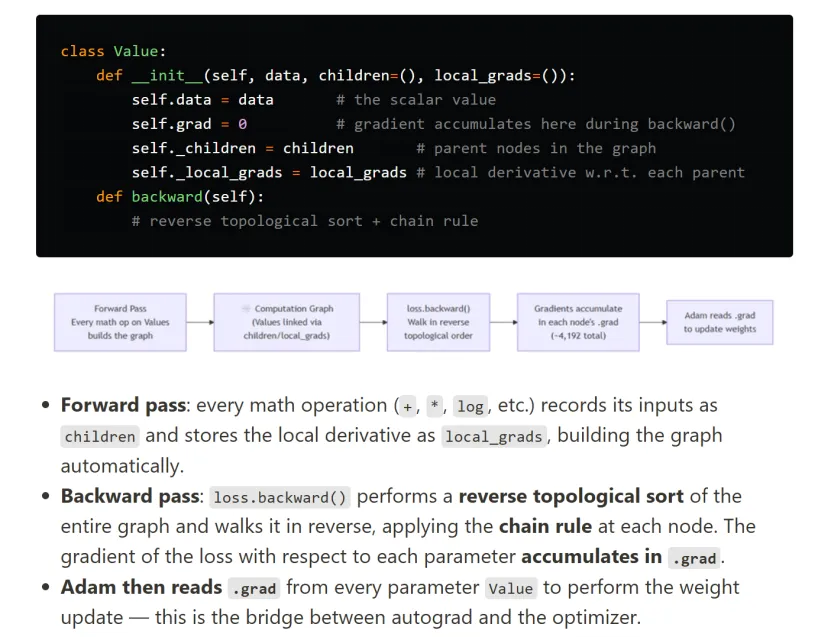
autograd 是深度学习框架中实现自动求导功能的核心模块,主要作用是追踪张量(tensor)的所有运算操作,记录运算的计算图,从而自动计算张量的梯度,无需开发者手动推导和编写求导公式。简单来说,autograd 是负责 “记录运算、管理计算图、提供求导能力” 的一整套机制。backward 是 autograd 模块提供的一个具体方法(函数) ,主要用途是触发梯度计算和反向传播过程。它会基于 autograd 记录的计算图,从指定的损失函数(或目标张量)开始,反向计算各个可训练参数的梯度,并将梯度结果存储在对应参数的 grad 属性中。
但是本文中,autograd只用于(或者说只用到)backward,所以可以认为backward就是autograd自动微分。
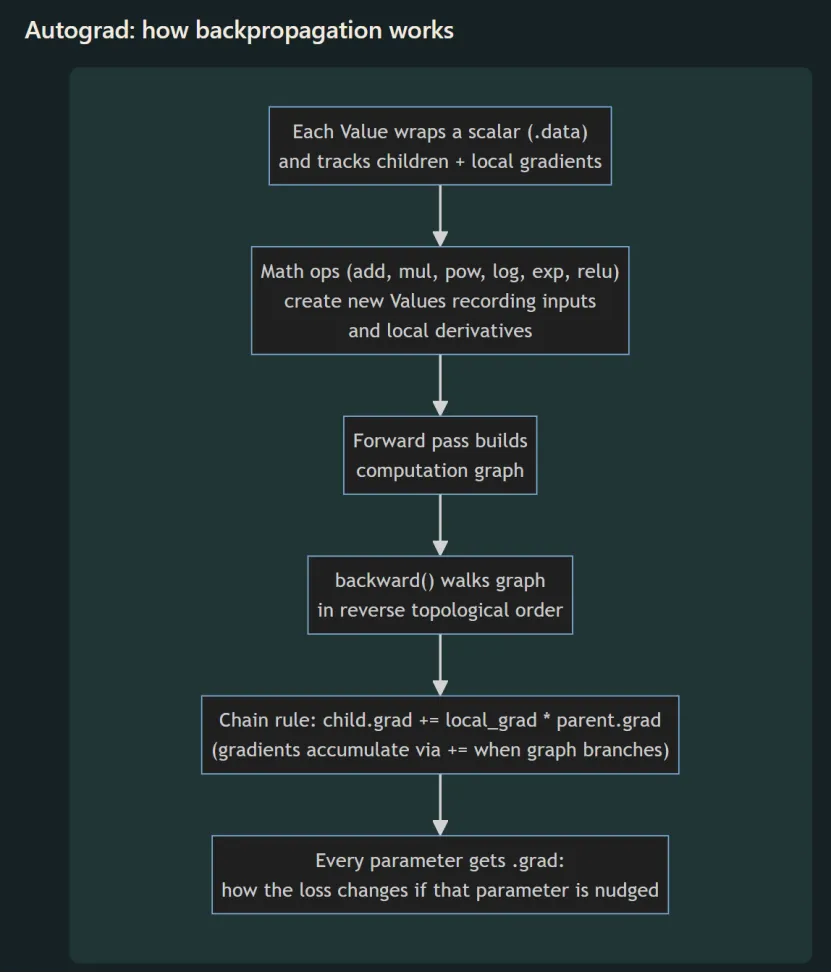
计算图有很多输入(模型参数与输入 token),最终汇聚成一个标量输出:损失。反向传播从这个唯一输出开始,沿图反向遍历,用微积分链式法则计算损失对每个输入的导数。
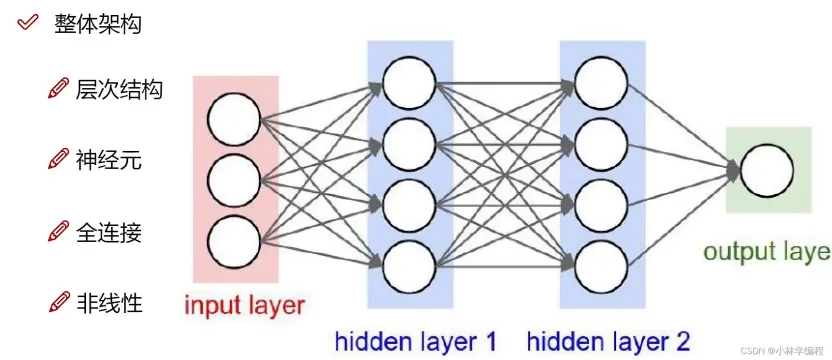
这就是一个神经网络计算图,每个Value实例的children是指向它的那些节点,比如绿色输出层的绿色节点,它的children是layer2的那四个蓝色节点;backward反向传播时,每个节点遍历自己的children列表中的节点,更新节点的grad梯度值,递归进行(注意到build_topo函数自己调用了自己)。
工业界用 PyTorch 自动完成,而这里作者用一个 Value 类从零实现:
class Value:__slots__ = ('data', 'grad', '_children', '_local_grads')def __init__(self, data, children=(), local_grads=()):self.data = data # 前向计算的标量值self.grad = 0 # 损失对该节点的导数,反向时计算self._children = children # 计算图中的子节点self._local_grads = local_grads # 本节点对子节点的局部导数# 加法def __add__(self, other):other = other if isinstance(other, Value) else Value(other)return Value(self.data + other.data, (self, other), (1, 1))# 乘法def __mul__(self, other):other = other if isinstance(other, Value) else Value(other)return Value(self.data * other.data, (self, other), (other.data, self.data))# 幂次def __pow__(self, other):return Value(self.data**other, (self,), (other * self.data**(other-1),))def log(self): return Value(math.log(self.data), (self,), (1/self.data,))def exp(self): return Value(math.exp(self.data), (self,), (math.exp(self.data),))def relu(self): return Value(max(0, self.data), (self,), (float(self.data > 0),))# 运算符重载def __neg__(self): return self * -1def __radd__(self, other): return self + otherdef __sub__(self, other): return self + (-other)def __rsub__(self, other): return other + (-self)def __rmul__(self, other): return self * otherdef __truediv__(self, other): return self * other**-1def __rtruediv__(self, other): return other * self**-1# 反向传播def backward(self):topo = []visited = set()def build_topo(v):if v not in visited:visited.add(v)for child in v._children:build_topo(child)topo.append(v)build_topo(self)self.grad = 1for v in reversed(topo):for child, local_grad in zip(v._children, v._local_grads):child.grad += local_grad * v.grad
作者知道这部分数学与算法密度最高(karpathy似乎不认为注意力机制部分算法和数学密度最高),作者为此做过一段2.5小时的视频讲解,叫做micrograd 视频。
简单说:
每个 Value 包装一个标量 .data,并记录它是怎么算出来的。
把每个运算看作一块乐高:输入→输出(前向),并知道输出相对每个输入的变化率(局部梯度)。
自动微分只需要这些信息,剩下的全是链式法则,把乐高块串起来。
每次对 Value 对象做加减乘除等运算,都会生成新 Value,记住它的输入(_children)与该运算的局部导数(_local_grads)。
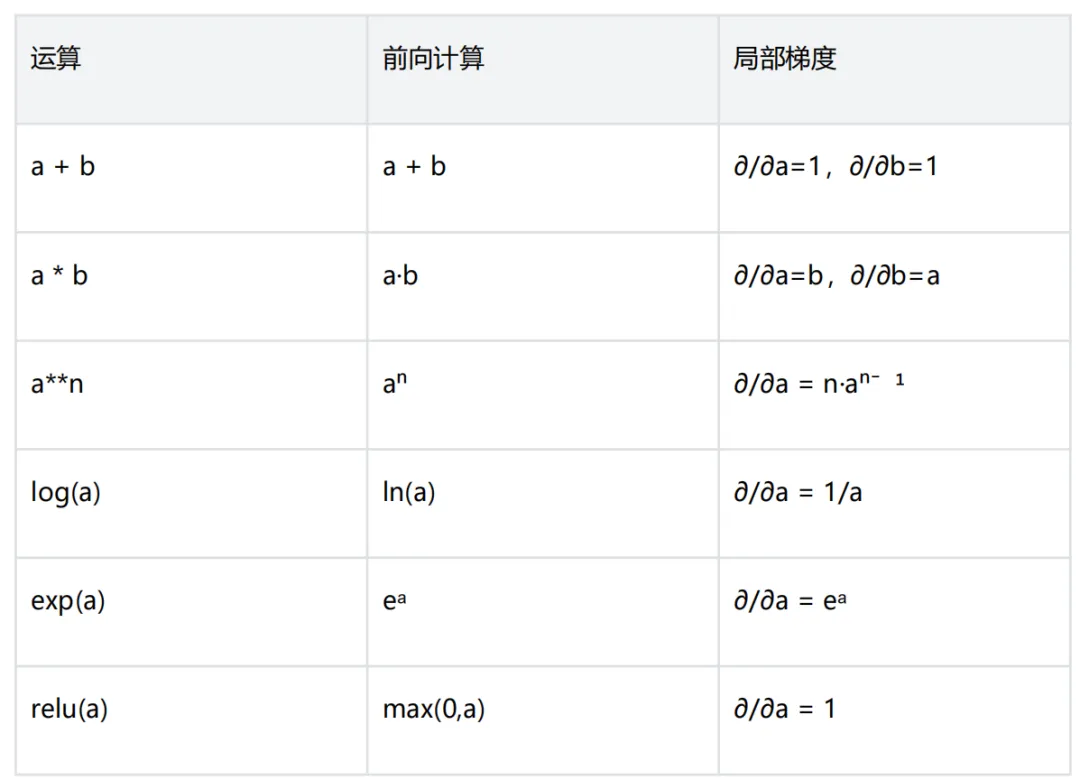
backward() 按逆拓扑序遍历整张图(从损失出发,到参数结束),每一步应用链式法则:
若损失为 L,节点 v 有子节点 c,局部导数 ∂v/∂c,则:
∂L/∂c += ∂v/∂c · ∂L/∂v
如果你不熟悉微积分,这看起来有点吓人,但本质上就是两个数相乘,非常直观。
可以这样理解:
如果汽车速度是自行车的2倍,自行车是步行的4倍,那么汽车是步行的 2×4=8 倍。链式法则就是这个道理:沿路径把变化率相乘。
在损失节点设 self.grad = 1,因为 ∂L/∂L=1。之后链式法则就会沿着所有路径把局部梯度一路乘回参数。
注意这里是+= 累加,不是赋值。当一个值在图中被多次使用(分支),梯度会沿每条分支独立回流,必须求和。这是多元链式法则的结果:若 c 通过多条路径影响 L,总导数是各路径贡献之和。
backward() 完成后,图中每个 Value 的 .grad 都存着 ∂L/∂v,告诉我们微调该值会如何影响最终损失。
而且,注意到,这里的backward最多的操作只涉及乘法(为了简化,连截距bias都去掉了)
具体示例
a = Value(2.0)b = Value(3.0)c = a * b # c = 6.0L = c + a # L = 8.0L.backward()print(a.grad) # 4.0(dL/da = b + 1 = 3 + 1,两条路径)print(b.grad) # 2.0(dL/db = a = 2)
这和 PyTorch 的 .backward() 结果完全一致,只是 microGPT 用标量,PyTorch 用张量(标量数组)——算法完全相同,只是更小巧、更简单,当然也更慢。
参数就是模型的“知识”,是一大堆被包装成 Value 的浮点数,初始随机,训练中不断优化。
n_embd = 16 # 嵌入维度n_head = 4 # 注意力头数n_layer = 1 # 层数block_size = 16 # 最大序列长度head_dim = n_embd // n_head # 每个头的维度# 矩阵初始化:高斯随机matrix = lambda nout, nin, std=0.08: [[Value(random.gauss(0, std)) for _ in range(nin)]for _ in range(nout)]state_dict = {'wte': matrix(vocab_size, n_embd), # token 嵌入'wpe': matrix(block_size, n_embd), # 位置嵌入'lm_head': matrix(vocab_size, n_embd)# 语言模型头}for i in range(n_layer):state_dict[f'layer{i}.attn_wq'] = matrix(n_embd, n_embd)state_dict[f'layer{i}.attn_wk'] = matrix(n_embd, n_embd)state_dict[f'layer{i}.attn_wv'] = matrix(n_embd, n_embd)state_dict[f'layer{i}.attn_wo'] = matrix(n_embd, n_embd)state_dict[f'layer{i}.mlp_fc1'] = matrix(4 * n_embd, n_embd)state_dict[f'layer{i}.mlp_fc2'] = matrix(n_embd, 4 * n_embd)params = [p for mat in state_dict.values() for row in mat for p in row]print(f"num params: {len(params)}")
所有参数初始化为小高斯随机数。state_dict 按 PyTorch 风格组织成命名矩阵:嵌入表、注意力权重、MLP 权重、输出投影。所有参数展平成单列表 params,方便优化器遍历。

这个超小模型一共4192 个参数。对比一下:GPT‑2 有 15 亿,现代大模型有数千亿。
模型是一个无状态函数:输入一个 token、位置、参数、之前位置缓存的键值对,输出词表上的 logit(得分),表示模型认为下一个 token 最可能是什么。
作者沿用 GPT‑2 并小幅简化:
RMSNorm 代替 LayerNorm
无偏置
ReLU 代替 GeLU
先看三个小辅助函数:
# 线性层:矩阵-向量乘法def linear(x, w):return [sum(wi * xi for wi, xi in zip(wo, x)) for wo in w]# Softmax:logits → 概率分布def softmax(logits):max_val = max(val.data for val in logits)exps = [(val - max_val).exp() for val in logits]total = sum(exps)return [e / total for e in exps]# RMSNorm:均方根归一化def rmsnorm(x):ms = sum(xi * xi for xi in x) / len(x)scale = (ms + 1e-5) ** -0.5return [xi * scale for xi in x]
linear:基础线性变换,神经网络的核心积木。
softmax:把任意范围的原始得分转成 [0,1] 且和为 1 的概率分布;先减最大值保证数值稳定,防止 exp 溢出。
rmsnorm:重缩放向量,让激活值稳定流动,防止训练中爆炸或消失,是 GPT‑2 所用 LayerNorm 的简化版。
现在是模型本体:
def gpt(token_id, pos_id, keys, values):# 嵌入:token + 位置tok_emb = state_dict['wte'][token_id]pos_emb = state_dict['wpe'][pos_id]x = [t + p for t, p in zip(tok_emb, pos_emb)]x = rmsnorm(x)for li in range(n_layer):# 1)多头注意力块x_residual = xx = rmsnorm(x)q = linear(x, state_dict[f'layer{li}.attn_wq'])k = linear(x, state_dict[f'layer{li}.attn_wk'])v = linear(x, state_dict[f'layer{li}.attn_wv'])keys[li].append(k)values[li].append(v)x_attn = []for h in range(n_head):hs = h * head_dimq_h = q[hs:hs+head_dim]k_h = [ki[hs:hs+head_dim] for ki in keys[li]]v_h = [vi[hs:hs+head_dim] for vi in values[li]]# 缩放点积注意力attn_logits = [sum(q_h[j] * k_h[t][j] for j in range(head_dim)) / head_dim**0.5for t in range(len(k_h))]attn_weights = softmax(attn_logits)head_out = [sum(attn_weights[t] * v_h[t][j] for t in range(len(v_h)))for j in range(head_dim)]x_attn.extend(head_out)x = linear(x_attn, state_dict[f'layer{li}.attn_wo'])x = [a + b for a, b in zip(x, x_residual)] # 残差# 2)MLP 块x_residual = xx = rmsnorm(x)x = linear(x, state_dict[f'layer{li}.mlp_fc1'])x = [xi.relu() for xi in x]x = linear(x, state_dict[f'layer{li}.mlp_fc2'])x = [a + b for a, b in zip(x, x_residual)] # 残差logits = linear(x, state_dict['lm_head'])return logits
函数一次处理一个 token(token_id)、在特定时间步(pos_id),并利用之前迭代缓存的 keys/values(即 KV Cache)。
state_dict 是模型的“参数档案”,专门存储模型训练过程中所有需要更新、保存的参数(比如之前提到的梯度对应的参数),是模型训练后保存、后续加载复用的核心。它只存“可训练参数”(如模型的权重、嵌入表等,就是我们说的“需要按梯度调整的参数”),不存梯度、loss值等临时数据。
KV Cache在模型训练(模型训练流程)和推理(模型推理)的核心逻辑中,每次调用gpt()函数前定义,代码原文如下:
`keys, values = [[] for _ in range(n_layer)], [[] for _ in range(n_layer)]`
KV Cache变量含义与作用(对应KV缓存):
- keys:列表类型,用于存储「所有Transformer解码层」的K(键)矩阵,是KV缓存中“K(键)”的具体载体,每次前向传播(gpt()函数调用)时,会将当前token的K向量(k = linear(x, state_dict[f'layer{li}.attn_wk']))追加到对应层的keys列表中,实现K的缓存积累。
- values:列表类型,用于存储「所有Transformer解码层」的V(值)矩阵,是KV缓存中“V(值)”的具体载体,每次前向传播时,会将当前token的V向量(v = linear(x, state_dict[f'layer{li}.attn_wv']))追加到对应层的values列表中,实现V的缓存积累。
这两个变量是“临时缓存”,仅在单次前向传播(训练步骤)或单次推理(生成样本)中存在,随每次调用gpt()函数动态更新(追加新的K、V向量)。
与state_dict(模型参数)不同:keys和values是临时缓存变量,不存储、不持久化,仅用于当前步骤的注意力计算,推理/训练结束后自动释放,完美对应之前提到的“KV缓存是临时变量”的特点。
1.嵌入
模型不能直接处理原始 token ID(如 5),只能处理向量。
给每个可能 token 分配一个学习到的向量
token 嵌入 + 位置嵌入,让模型同时知道“这是什么”和“它在哪”
现代大模型常改用 RoPE 等相对位置编码,省略显式位置嵌入。
2.注意力块
当前 token 被投影为三个向量:
lQ(Query):我在找什么?
lK(Key):我包含什么?
lV(Value):被选中时我提供什么?
比如名字“emma”中,模型在第二个 m 预测下一个字符时,可能学会查询“最近出现过哪些元音”。前面的 e 会有匹配度很高的 key,获得高注意力权重,它的元音信息就流入当前位置。
K、V 存入 KV 缓存,让过去位置可被访问。

每个注意力头计算查询与所有缓存键的缩放点积,softmax 得权重,再对值加权求和。所有头输出拼接后经 attn_wo 投影。
强调:注意力块是唯一让 t 位置 token 能看到 0~t−1 历史 token 的地方。注意力是 token 之间的通信机制。
3.MLP块
两层前馈网络:升维到 4×嵌入维度 → ReLU → 降维回来。
这是模型逐位置思考的主要地方。与注意力不同,MLP 计算完全局部于当前时间 t。
4.残差连接
注意力与 MLP 块都把输出加回输入(x = [a + b for ...]),让梯度直接流通,让深层模型可训练。
5.输出
最终隐状态经lm_head 投影到词表大小,得到每个 token 的 logit。本例中就是 27 个数,值越高,模型越认为该 token 是下一个。
你可能注意到:作者训练时也用 KV 缓存,这并不常见。人们通常把 KV 缓存和推理绑定。但 KV 缓存概念上始终存在,即便在训练中。工业实现里,它只是被隐藏在高度向量化、同时处理所有位置的注意力计算中。
因为 microGPT 一次只处理一个 token(无批次、无时间并行),我们显式构建 KV 缓存。与常规推理不同,这里缓存的 K、V 是计算图中的活 Value 节点,我们会对它们反向传播。
把所有部分串起来。训练循环反复做:
1.取一份文档
2.对其 token 序列前向跑模型
3.计算损失
4.反向传播得梯度
5.更新参数

图| Full Training Pipeline — End to End©【深蓝 AI】编译
更加具体的训练循环描述如下,来自:microgpt: A 200-Line Pure Python GPT — The Daily Compress
Training loop logic
Pick a document, tokenize it, wrap with BOS on both sides (e.g. "emma" → [BOS, e, m, m, a, BOS])
↓
Feed tokens through model one at a time, building KV cache; at each position compute cross-entropy loss: -log p(correct next token)
↓
Average per-position losses into single scalar loss
↓
loss.backward() backpropagates through entire computation graph, giving every parameter a .grad
↓
Adam optimizer updates each parameter using momentum (m) and adaptive learning rate (v), with bias correction and linear LR decay
↓
Reset all gradients to 0 for next step
训练的输入与输出说明:训练过程的核心输入分为两部分,一是模型参数(初始为随机高斯浮点数,存储在state_dict中,包括嵌入表、注意力权重、MLP权重等),二是预处理后的训练数据(即32033个名字文档,经分词后转化为token序列,每个序列用BOS token首尾包裹,例如“emma”转化为[BOS, e, m, m, a, BOS]);训练的输出是不断优化的模型参数(通过Adam优化器更新,逐步降低损失),同时每一步会输出当前训练步数和平均损失值,用于监控训练进度和模型学习效果,最终得到一组能捕捉名字统计规律的最优参数。
1.取一份文档
2.对其 token 序列前向跑模型
3.计算损失
4.反向传播得梯度
5.更新参数
# Adam 优化器learning_rate, beta1, beta2, eps_adam = 0.01, 0.85, 0.99, 1e-8m = [0.0] * len(params) # 一阶矩缓冲v = [0.0] * len(params) # 二阶矩缓冲num_steps = 1000 # 训练步数for step in range(num_steps):# 取文档、分词、用 BOS 包裹doc = docs[step % len(docs)]tokens = [BOS] + [uchars.index(ch) for ch in doc] + [BOS]n = min(block_size, len(tokens) - 1)# 前向:构建计算图直到损失keys, values = [[] for _ in range(n_layer)], [[] for _ in range(n_layer)]losses = []for pos_id in range(n):# 关键参数解释:# token_id:当前输入模型的token对应的整数ID(即当前字符的编码),用于模型获取对应嵌入向量# target_id:当前token的下一个token对应的整数ID(即模型需要预测的目标字符编码)# pos_id:当前token在序列中的位置索引(从0开始),用于模型获取对应位置嵌入,让模型感知字符顺序token_id, target_id = tokens[pos_id], tokens[pos_id + 1]logits = gpt(token_id, pos_id, keys, values)probs = softmax(logits)loss_t = -probs[target_id].log()losses.append(loss_t)loss = (1 / n) * sum(losses) # 平均损失# 反向:算所有参数梯度loss.backward()# Adam 更新lr_t = learning_rate * (1 - step / num_steps) # 线性学习率衰减for i, p in enumerate(params):m[i] = beta1 * m[i] + (1 - beta1) * p.gradv[i] = beta2 * v[i] + (1 - beta2) * p.grad ** 2m_hat = m[i] / (1 - beta1 ** (step + 1))v_hat = v[i] / (1 - beta2 ** (step + 1))p.data -= lr_t * m_hat / (v_hat ** 0.5 + eps_adam)p.grad = 0print(f"step {step+1:4d} / {num_steps:4d} | loss {loss.data:.4f}")
分词:每份文档用 BOS 首尾包裹,如“emma”→[BOS,e,m,m,a,BOS],模型任务是根据前文预测下一个 token。
前向与损失:逐个喂 token,构建 KV 缓存。每位置输出 27 个 logit,转概率。逐位置损失是正确下一个 token 的负对数概率:−log p(target),这就是交叉熵损失。
loss_t = -probs[target_id].log()
losses.append(loss_t)
loss = (1 / n) * sum(losses) # 平均损失
这是预测下一个token(也就是字符),是所有27个字符中每一个的可能性,其中只有一个字符是target,也就是监督学习的标签。下一个token是所有27个字符的概率,取对数log后取负,累加起来求平均,就是预测是否准确的loss。
直观理解:损失衡量预测错误程度——模型对真实下一个 token 有多“意外”。概率 1.0 → 不意外,损失 0;概率接近 0 → 极度意外,损失趋近 +∞。对整份文档所有位置损失取平均,得到单标量损失。
反向传播:一次 loss.backward() 就从损失出发,经 softmax、模型、反向遍历整个计算图,直到每个参数。之后每个参数的 .grad 就告诉作者怎么调它能降低损失。
这里讲解一下,loss值(预测值与标签值之间差异的某种变体)是如何通过梯度反向传播逐层传回直到输入层的?loss值会决定loss节点的grad值,如下图。参考https://mp.weixin.qq.com/s/bHooecIBox8ZA3bdjDCKBg

lAdam 优化:比普通梯度下降更聪明。维护每个参数的两个滑动平均:
m:最近梯度均值(动量,像滚球)
v:最近梯度平方均值(自适应学习率)
m_hat/v_hat 是偏差校正,因为 m/v 初始为 0,需要预先调整一下。学习率随训练线性衰减。更新后重置 .grad=0,准备下一步。
Adam 优化 (或者说任何优化器) 都是在训练步的上一步和下一步之间,对原始梯度进行某种形式的微调,微调后的梯度代替原始梯度,进行下一步的反向传播(也就是参数调整)。不同的微调形式定义不同的优化算法或者说优化器。
1000 步内,损失从约 3.3(随机猜 27 个 token:−log(1/27)≈3.3)降到约 2.37。越低越好,理论最小值 0(完美预测)。模型显然已经学会名字的统计规律。10000步,loss是2.1409。
推理的输入与输出说明:推理过程的输入包括三部分,一是训练完成后冻结的模型参数(即训练阶段得到的最优参数,不再更新),二是初始输入token(固定为BOS token,用于告知模型开始生成新文档),三是温度参数(控制生成结果的随机性,取值范围(0,1]);推理的输出是模型生成的全新、合理的名字序列,生成过程中会动态缓存每一步的keys和values(KV Cache),每一步输出一个token,直到生成BOS token(表示名字生成结束)或达到最大序列长度(block_size=16),最终输出20个不同的生成样本。
训练完成后,冻结参数,循环前向采样,把生成的 token 喂回作下一个输入:
temperature = 0.5 # (0,1],控制生成“创意度”print("\n--- inference (new, hallucinated names) ---")for sample_idx in range(20):keys, values = [[] for _ in range(n_layer)], [[] for _ in range(n_layer)]# 推理阶段初始token_id设为BOS(序列开始标识),告知模型开始生成新文档token_id = BOSsample = []# pos_id:推理时当前生成token的位置索引(从0开始),与训练时含义一致,用于获取位置嵌入for pos_id in range(block_size):logits = gpt(token_id, pos_id, keys, values)probs = softmax([l / temperature for l in logits])# 采样得到下一个token的ID,作为下一轮输入的token_idtoken_id = random.choices(range(vocab_size), weights=[p.data for p in probs])[0]if token_id == BOS:breaksample.append(uchars[token_id])print(f"sample {sample_idx+1:2d}: {''.join(sample)}")
每个样本以BOS开始,告诉模型“开始新名字”。模型输出 27 个 logit(Logits是模型最后一层没经过 Softmax 归一化的原始打分值,是一堆无界、可正可负的原始分数,还不是概率),softmax把logits(复数是因为有27个logit)转概率,按概率随机采样一个 token。该 token 再喂回作下一个输入,重复直到模型输出 BOS(表示“结束”)或达到最大序列长度20。
temperature控制随机性:softmax 前把 logit 除以 temperature。
1.0:按模型学习到的分布直接采样
更低(如 0.5):分布更尖锐,模型更保守,更倾向选最可能的 token
趋近 0:总是选概率最高的 token(贪心解码)
更高:分布更平坦,生成更多样,但可能更不连贯
python train.py在作者的 MacBook 上跑约 1 分钟。你会看到每步损失打印:
num docs: 32033
vocab size: 27
num params: 4192
step 1 / 1000 | loss 3.3660
step 2 / 1000 | loss 3.4243
step 3 / 1000 | loss 3.1778
step 4 / 1000 | loss 3.0664
step 5 / 1000 | loss 3.2209
step 6 / 1000 | loss 2.9452
...
损失从约 3.3(随机)稳步降到约 2.37。数值越低,网络对下一个 token 的预测越准。训练结束时,训练序列的统计规律知识就浓缩在模型参数里。固定这些参数,作者就能生成全新的、“幻想”出来的名字。
win上运行大概是下图效果:

step越多,loss越低。
建议按以下顺序逐层剥开代码,像剥洋葱一样:

作者建了一个 Gist 叫 build_microgpt.py(https://gist.github.com/karpathy/8627fe009c40f57531cb18360106ce95),在修订历史里可以看到所有这些版本及每一步的 diff。作者认为这是逐段理解代码的好方式:一次只加一个组件。但遗憾的是,本文受限于网络访问环境,未能找到train0-4文件,否则是很好的材料。
microGPT 包含训练与运行 GPT 的全部算法本质。但它和 ChatGPT 这类工业级 LLM 之间,还有一长串差异。这些都不改变核心算法与整体结构,但决定了能否规模化可用。
1. 数据
工业级用万亿级 token 的互联网文本(网页、书籍、代码等),去重、过滤质量、精心混合领域。
2. 分词器
不用单字符,而用子词分词器(如 BPE),把高频共现字符序列合并成单个 token。常见词如“the”成一个 token,罕见词拆成片段。词表约 100K,效率更高。
3. 自动微分
microGPT 用纯 Python 标量 Value;工业系统用张量(多维数组),在 GPU/TPU 上并行跑亿次浮点运算。PyTorch 等框架自动处理张量自动微分,CUDA 内核(如 FlashAttention)融合多操作提速。数学完全一样,只是并行处理大量标量。
4. 架构
microGPT 仅 4192 参数;GPT‑4 级模型数千亿。整体 Transformer 结构非常相似,只是更宽(嵌入维度 10k+)、更深(100+ 层)。现代 LLM 还加入更多积木并调整顺序:如 RoPE 替代显式位置嵌入、GQA 减少 KV 缓存、门控线性激活替代 ReLU、MoE 层等。但注意力(通信)+ MLP(计算)+ 残差的核心结构完好保留。
5. 训练
非一步一个文档,而是用大批次(每步数百万 token)、梯度累积、混合精度(float16/bfloat16)、精细调参。训练顶尖模型需要数千 GPU 跑数月。
6. 优化
microGPT 只用带线性衰减的 Adam;优化自成一门学科。模型用低精度(bfloat16/fp8)在 GPU 集群训练,引入数值挑战。优化器设置(学习率、权重衰减、beta、预热/衰减策略)必须精调,且与模型大小、批次大小、数据集相关。缩放定律(如 Chinchilla)指导如何在固定算力预算下分配模型大小与训练 token 数。细节出错会浪费数百万美元算力,团队会先做大量小实验预测最优配置。
7. 后训练
训练出来的基座模型(“预训练模型”)只是文档补全器,不是聊天机器人。变成 ChatGPT 分两步:
SFT(监督微调):把文档换成精标对话,继续训练,算法不变。
RL(强化学习):模型生成回复,经人类/裁判模型/算法打分,模型从反馈中学习。本质仍是训练文档,只是文档由模型自己生成的 token 构成。
8. 推理
给百万用户服务需要专属工程栈:请求批处理、KV 缓存管理与分页(vLLM 等)、 speculative decoding 提速、量化(int8/int4 替代 float16)减内存、多 GPU 分布式。本质仍是逐 token 预测,只是大量工程优化让它更快。
所有这些都是重要工程与研究贡献,但只要你懂了 microGPT,就懂了算法本质。
模型真的“理解”吗?
哲学问题,但计算机层面讲:没有魔法。它只是一个巨大数学函数,把输入 token 映射为下一个 token 的概率分布。训练中参数被调整,让正确下一个 token 概率更高。这算不算“理解”由你定义,但机制完全包含在这 200 行里。
为什么它有效?
模型有成千上万可调参数,优化器每步微调节它们让损失下降。多步之后,参数收敛到能捕捉数据统计规律的数值。对名字来说,就是:常以辅音开头、“qu”常一起出现、很少三个辅音连在一起等。模型不学显式规则,而是学到反映这些规则的概率分布。
和 ChatGPT 是什么关系?
ChatGPT 就是同一核心循环(预测下一个 token → 采样 → 重复)的巨量级缩放,外加后训练让它能对话。你和它聊天时,系统提示、你的消息、它的回复都只是序列中的 token。模型逐词补全文档,和 microGPT 补全名字完全一样。
“幻觉”是怎么回事?
模型按概率分布采样生成 token,它没有“真”的概念,只知道基于训练数据哪些序列统计上合理。microGPT“幻想”出“karia”这样的名字,和 ChatGPT 自信说出错误事实是同一现象:都是统计上合理、但并非真实的补全。
为什么这么慢?
microGPT 在纯 Python 里一次只处理一个标量,一步训练要数秒。同样数学在 GPU 上并行处理数百万标量,速度快若干数量级。
能让它生成更好的名字吗?
可以。训练更久(加大 num_steps)、模型更大(n_embd/n_layer/n_head)、用更大数据集。这些就是规模化时同样关键的旋钮。模型更大和训练集更大,会产生涌现现象,量变引起质变。
换数据集会怎样?
模型会学习数据里的任何模式。换成城市名、宝可梦名、英语单词、短诗,模型就会学着生成这些,其余代码完全不用改。
审编|阿蓝




· 计划周期:深蓝学院将以3个月为一个周期,建立工程师&学术研究者的「同好社群」
· 覆盖方向:自动驾驶、具身智能(人形、四足、轮式、机械臂)、视觉、无人机、大模型、医学人工智能……16个热门领域
扫码添加阿蓝
选择想要加入的交流群即可
(按照提交顺序邀请,请尽早选择)
👇

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- python计算城市多中心度和分散度【代码修订】
- Linux C基础——” Makefile “ 文件管理大师你拜访过嘛?
- 【python3.7.0】python3.7.0setup安装包下载python 软件安装教程(附完整使用说明)
- 硬核 GIS | Python 批量抓取高德 POI:攻克坐标偏移,实现 WGS84 无缝对接!
- 百易云 task.create.php SQL注入漏洞
- 186G福利放送!2026数据分析/Python/Excel/数据库资料最新合集(从零到实战处理数据)持续更新中...
- Python语法速查图,新手一定要存!
- 嵌入式Linux开发利器:Yocto Project
- 10元手机魔改为Linux桌面服务器【超低成本的家用服务器】
- 查看python安装位置
