Python基础篇 - 多线程-GIL与互斥锁
- 2026-06-30 07:47:54


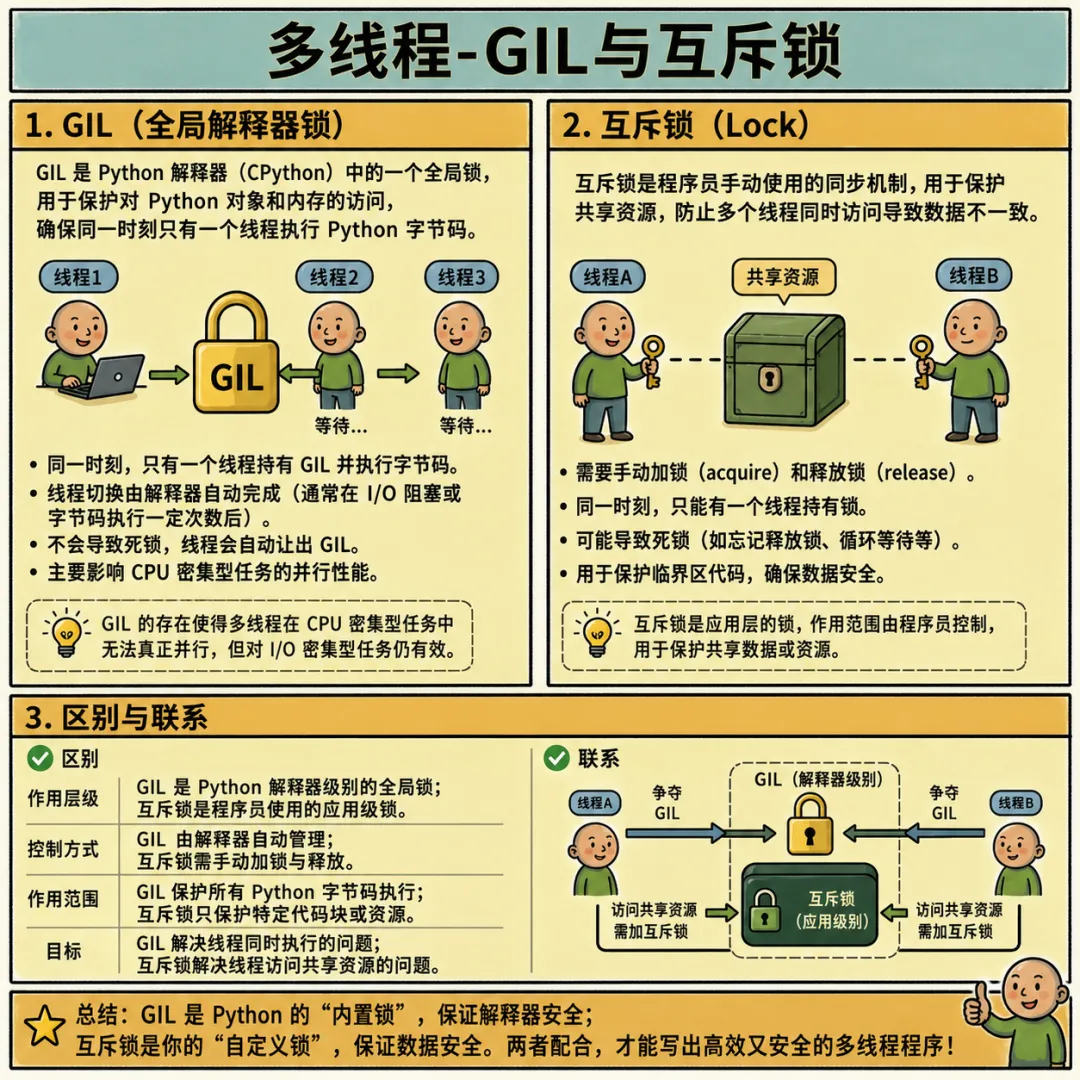
在之前的文章Python基础篇 - 多线程-互斥锁,我们认识了互斥锁,并学习了如何使用它来解决多线程下共享全局变量导致的数据错乱问题。但了解过Python底层原理之后,我们可能会有一个很大的疑问:其实Python内部已经自带了的GIL(也就是所谓的全局解释器锁),保证了同一时刻只能有一个线程在执行代码,那为什么我们在写多线程时,还需要自己手动加互斥锁呢?想要理清这个问题,就得深入了解GIL与互斥锁的区别与联系。
一.什么是GIL?
GIL的全称是(Global Interpreter Lock,全局解释器锁)。由于Python默认的解释器--CPython在内存管理上不是线程安全的,为了防止多个线程同时执行Python字节码破坏内部数据(比如对象的引用计数),于是CPython就引入了GIL全局解释器锁。
简单来说,GIL就像是Python解释器的一个“内部通行证”。在多线程环境下,无论你有多少个核心,任何一个线程想要执行Python代码,都必须先获得GIL这张通行证。因此,在CPython中,同一时刻实际上只有一个线程在真正运行。
二. 既然有了GIL,那为何需要互斥锁?
大家都会想到:既然GIL保证了同一时间只有一个线程在跑,那多线程操作全局变量应该也是安全的。其实不然,回顾我们上篇文章Python基础篇 - 多线程-互斥锁中的示例代码,其中有一行代码:
g_num = g_num + 1这在Python中看似是一行代码,但在底层解释器内会被拆分成好几步(字节码)来执行:
第一步:获取g_num的值
第二步:把获取到的值加1
第三步:把计算后的新值赋给g_num
但GIL并不是等你的这行代码全部执行完才释放。Python解释器在执行了一定数量的字节码或者遇到I/O阻塞(比如示例代码中模拟的time.sleep()、网络请求)时,就会强制释放GIL,让其他线程有机会运行。如果线程A刚执行完获取值和加1,还没来得及赋值,GIL就被释放并被线程B抢走了。线程B拿到了旧数据进行计算,就会覆盖掉线程A的努力,导致数据错乱,也就是说GIL并不能保护全局共享数据的安全。
三. GIL与互斥锁的联系
为了解决上面字节码被中断导致的数据不一致问题,我们就必须使用 互斥锁。当某个线程要更改共享数据时,我们用互斥锁把代码对应的字节码步骤锁起来,确保它们作为一个不可分割的整体执行完毕,这样就确保了共享数据的安全。
简单总结一下它们二者的联系:
1. 保护的对象不同:GIL是Python解释器级别的锁,它保护的是Python底层的解释器状态和内存结构不受破坏;而互斥锁是代码级别的锁,保护的是我们开发者自己定义的共享数据(如全局变量、文件等)。
2. 控制权不同:GIL是Python解释器自动加锁和解锁的,不受开发者控制;但互斥锁是由我们开发者手动通过加锁和放锁来控制的。
3. 两者各有千秋:GIL保证了线程在解释器层面的安全,但无法保证业务逻辑层面(数据操作)的安全。因此,GIL不能替代互斥锁,在编写多线程程序操作共享资源时,互斥锁依然是必不可少的。

总结:今日我们学习了Python基础篇-多线程-GIL与互斥锁。GIL是CPython全局解释器锁,保证同一时刻仅有一个线程执行字节码,导致多线程无法利用多核算力。但是即便存在GIL,多线程修改共享数据仍会因操作非原子性出现数据错乱。互斥锁由开发者手动定义,可锁住临界代码段,保证同一时间仅一个线程操作共享变量。二者作用不同,GIL管控解释器执行,互斥锁保障业务数据线程安全,IO密集适合多线程,CPU密集建议使用多进程规避GIL限制。在Python基础篇,后续我们将持续学习Python基础知识,介绍各种算法,祝每一位study er学习愉快。