诸位,在上一章《Python学习|RS Python入门02:列表、字典与流程控制:像元集合的编队【五】简单语句》中,我们学习了如何用循环让程序重复干活。但也许你可能已经发现:如果一段重复操作特别复杂,比如对一景遥感影像做辐射定标、大气校正、裁剪、计算NDVI……每次循环都写一遍这几十行代码,既臃肿又难维护。
这时候,我们来介绍一个新的工具,函数就登场了。
函数是什么?简单说,就是把一段有特定功能的代码打包,给它起个名字。以后想用这段功能,只需要“喊”它的名字就行,不用再把代码重新写一遍。
生活中,函数就像“菜谱”一样,想象你学会了做“西红柿炒鸡蛋”。只要记住这个名字,以后随时需要,就照菜谱做一遍,而不是每次都重新研究怎么切西红柿、怎么打鸡蛋。
遥感中的函数就像预处理流程一样重复使用。
在遥感数据处理中,函数可以把常用操作封装起来,大大提高工作效率:
1.1 定义和调用函数
大家学编程,最耳熟能详的便是hello world语句吧,好今天便继续来到这个语句,当然我们呢通过函数实现而非直接print他。
首先让我们来定义一个Hello函数,如下
def say_hello(): print("诸君,欢迎来到GeoPyLab!") print("请保证你的思维时刻在线~")
好了我们应该如何去调用呢?
至此我们便可以得到如下的运行结果:
下面我们来观察一下定义到调用一个函数的一些关键点:
def 是关键词,表示定义二字,这是固定格式,熟记即可
say_hello是函数名,这个自己起,要见名知意,不要过于复杂,当然也要保证自己函数的可读性,即就是要保证别人拿到你的代码能够看明白你的目的是什么
() 用来放参数,倘若没有参数就空着
: 表示函数体开始,下面便要开始定义你的函数内容
函数内部的代码要缩进
定义函数时,函数体内的代码不会立即执行只有调用函数时,函数体内的代码才会运行
1.2 带参数的函数,即可给函数提供数据
很多时候,函数需要外部数据才能工作。比如写一个计算 NDVI 的函数,它需要知道红波段和近红外波段的数值。
下面我们便开始进一步了解一些内容,我们先来定义一个计算NDVI的函数,具体计算公式我们不再展开赘述。
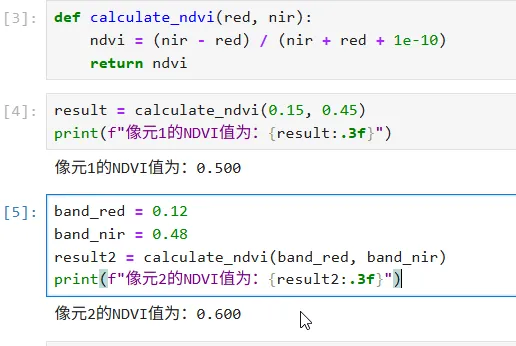
def calculate_ndvi(red, nir): ndvi = (nir - red) / (nir + red + 1e-10) return ndvi
好的我们下一步便开始在调用函数时传入一些数据:
result = calculate_ndvi(0.15, 0.45)print(f"像元1的NDVI值为:{result:.3f}")
当然了,我们也可以直接传入一些变量:
band_red = 0.12band_nir = 0.48result2 = calculate_ndvi(band_red, band_nir)print(f"像元2的NDVI值为:{result2:.3f}")
运行之后我们便可以得到如下的结果:
总是我们可以看到两种函数均可完成参数的传入,在实际编程的过程中我们可以择优进行选取使用哪种方式。
好的,诸位我们来看一些关键点:
red, nir 是形参,即形式参数,就像菜谱里的鸡蛋 需要3 个一样
-0.15, 0.45是实参,也就是实际给的数据一样
return是返回值,也就是把计算结果送出来,函数的出口便在此处
2.1 带默认参数的函数,即可省去重复输入
有些参数大部分情况都一样,可以设置默认值。下面我们来看一个关于植被指数计算的函数例子,我们定义一个计算EVI的函数,在其中我们可以使用一些默认参数:
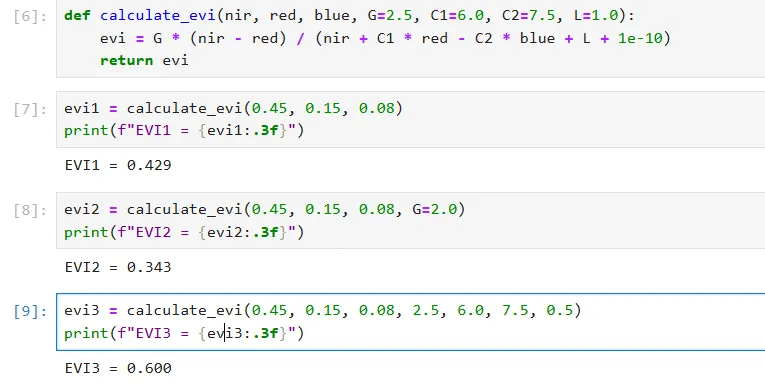
def calculate_evi(nir, red, blue, G=2.5, C1=6.0, C2=7.5, L=1.0): evi = G * (nir - red) / (nir + C1 * red - C2 * blue + L + 1e-10) return evi
至此我们便完成了EVI计算的定义,诸位,下面便开始不同方式的调用:
首先我们只传入必要的参数,其他值均为函数定义时的默认值:
evi1 = calculate_evi(0.45, 0.15, 0.08)print(f"EVI1 = {evi1:.3f}")
当然我们也可以在调用函数时,手动修改一些默认参数的值:
evi1 = calculate_evi(0.45, 0.15, 0.08)print(f"EVI1 = {evi1:.3f}")
同样我们也可以按参数位置去逐个修改函数参数:
evi3 = calculate_evi(0.45, 0.15, 0.08, 2.5, 6.0, 7.5, 0.5)print(f"EVI3 = {evi3:.3f}")
运行上述结果我们便可以看到即便是传入的近红外、红外、蓝波段的数值一样,但是由于参数的不同我们得到的结果是不相同的:
在此向诸位提个小小的注意事项,就是在定义函数时带默认值的参数必须放在没有默认值的参数后面。
2.2 关键字参数,即便是打乱顺序也能传
如下我们来通过一个简单的小例子来对其进行说明:
def describe_image(name, sensor, resolution, date): print(f"影像名称:{name}") print(f"传感器:{sensor}") print(f"分辨率:{resolution}米") print(f"获取日期:{date}")
我们可以正常按位置进行传参:
describe_image("影像001", "Landsat-8", 30, "2024-07-15")
当然也可以不按参数位置进行传参,这里便需要加上形参的名称:
describe_image(date="2024-07-15", name="影像002", resolution=10, sensor="Sentinel-2")
运行上述内容便可以得到如下的结果:
也就是说,关键字参数是为了让代码更易读,也更方便只修改某几个参数。
2.3 可变参数,处理不确定数量的输入
诸位,在有时候编程的过程中,你不知道用户会传几个值,比如要计算多个波段的平均值。
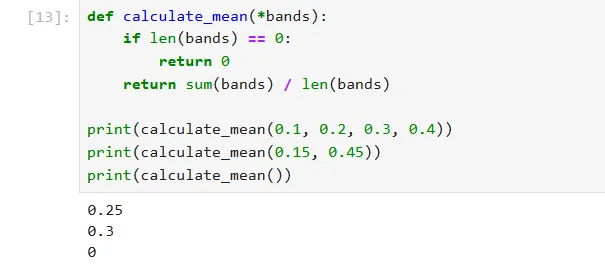
首先我们来看*args ,其可以接收任意多个位置参数,将其打包成元组,如下我们要计算某一像元多个波段的平均值:
def calculate_mean(*bands): if len(bands) == 0: return 0 return sum(bands) / len(bands)print(calculate_mean(0.1, 0.2, 0.3, 0.4))print(calculate_mean(0.15, 0.45))print(calculate_mean())
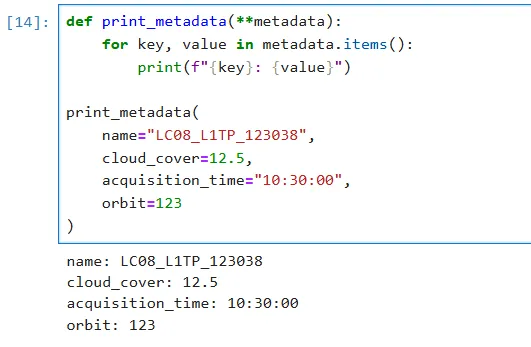
当然也可以使用**kwargs 接收任意多个关键字参数,将其传入的参数打包成字典,如下我们打印某一影像元数据:
def print_metadata(**metadata): for key, value in metadata.items(): print(f"{key}: {value}")print_metadata( name="LC08_L1TP_123038", cloud_cover=12.5, acquisition_time="10:30:00", orbit=123)
便可得到如下的结果:
3.1 实战练习,二者结合批量计算 NDVI
首先我们假设有三景影像的波段均值,想批量计算 NDVI,不需要写三次公式,只需要定义函数,将其结合循环便可以实现批量循环处理:
首先我们来定义NDVI计算函数:
def ndvi(red, nir): return (nir - red) / (nir + red + 1e-10)
而后我们来传入一些影像参数与波段值:
images = [ ("Landsat_01", 0.12, 0.38), ("Landsat_02", 0.14, 0.42), ("Sentinel_01", 0.10, 0.35), ("Sentinel_02", 0.11, 0.40),]
接下来我们便可以使用for循环对其进行批量运算:
for name, r, n in images: value = ndvi(r, n) print(f"{name:12} red={r:.3f} nir={n:.3f} 经过计算其NDVI = {value:.3f}")
运行上述内容,我们便可以得到如下的结果:
3.2 条件筛选,进一步结合找出植被覆盖度高的影像
诸位,我们可以使用函数与循环结合,借助NDVI来招数植被覆盖较高的影像,首先我们定义这个函数:
def classify_vegetation(ndvi_value): if ndvi_value < 0: return "水体/非植被" elif ndvi_value < 0.2: return "裸土/稀疏植被" elif ndvi_value < 0.4: return "中等植被覆盖" elif ndvi_value < 0.6: return "高植被覆盖" else: return "极高植被覆盖"
for name, r, n in images: value = ndvi(r, n) category = classify_vegetation(value) print(f"{name} NDVI={value:.3f} -> {category}")
运行上述内容,我们便可以得到如下的结果:
3.3 批量保存处理结果
我们先来模拟一个影像批处理过程:
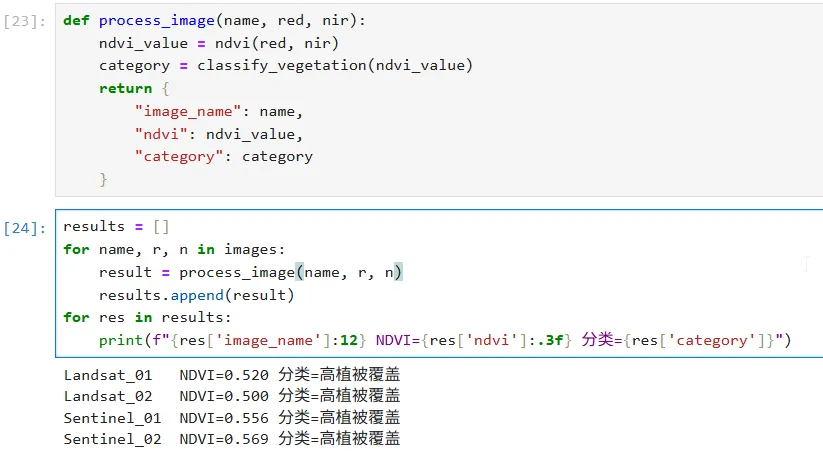
def process_image(name, red, nir): ndvi_value = ndvi(red, nir) category = classify_vegetation(ndvi_value) return { "image_name": name, "ndvi": ndvi_value, "category": category }
而后我们创建结果并使用循环逐个保存:
results = []for name, r, n in images: result = process_image(name, r, n) results.append(result)for res in results: print(f"{res['image_name']:12} NDVI={res['ndvi']:.3f} 分类={res['category']}")
即可得到如下的结果:
好了,经过上面的一些函数应用,诸位应该已经明白了函数的一些简便方法,下面我么来进行遥感影像批处理演示:
1. 定义各种植被指数的计算函数
2. 定义植被检查函数
3. 批量处理多景影像
4. 生成结果报告
好的,我们按上面的内容逐步完成:
首先我们先来定义一些植被指数的计算函数,如下:
import mathdef ndvi(red, nir, epsilon=1e-10): return (nir - red) / (nir + red + epsilon)def ndwi(green, nir, epsilon=1e-10): return (green - nir) / (green + nir + epsilon)def evi(nir, red, blue, G=2.5, C1=6.0, C2=7.5, L=1.0, epsilon=1e-10): return G * (nir - red) / (nir + C1 * red - C2 * blue + L + epsilon)def savi(red, nir, L=0.5, epsilon=1e-10): return ((nir - red) / (nir + red + L + epsilon)) * (1 + L)def msavi2(red, nir, epsilon=1e-10): numerator = 2 * nir + 1 - math.sqrt((2 * nir + 1) ** 2 - 8 * (nir - red)) denominator = 2 + epsilon return numerator / denominator
而后进一步定义植被检查函数,具体用于判读此处为何种地物:
def classify_vegetation(ndvi_value): if ndvi_value < 0: return "非植被" elif ndvi_value < 0.2: return "稀疏植被" elif ndvi_value < 0.4: return "中等植被" elif ndvi_value < 0.6: return "茂密植被" else: return "植被全覆盖"def water_detection(ndwi_value, threshold=0): return ndwi_value > threshold
当计算与判读均已完成之后,我们下一步便是要进行影像的读取:
def process_single_image(image_id, bands, metadata=None): result = { "image_id": image_id, "indices": {}, "classification": {}, "metadata": metadata or {} } blue = bands.get('blue', 0) green = bands.get('green', 0) red = bands.get('red', 0) nir = bands.get('nir', 0) result["indices"]["NDVI"] = ndvi(red, nir) result["indices"]["NDWI"] = ndwi(green, nir) result["indices"]["EVI"] = evi(nir, red, blue) result["indices"]["SAVI"] = savi(red, nir) result["indices"]["MSAVI2"] = msavi2(red, nir) ndvi_val = result["indices"]["NDVI"] result["classification"]["veg_type"] = classify_vegetation(ndvi_val) result["classification"]["is_water"] = water_detection(result["indices"]["NDWI"]) return result
当然我们在实际应用中都是批量去生成、运行计算的,故而我们使用for循环进一步撰写批量运行处理函数:
def batch_process_images(image_dataset): all_results = [] for idx, (img_id, bands, metadata) in enumerate(image_dataset, 1): print(f"\n[{idx}/{len(image_dataset)}] 处理影像: {img_id}") print(f" 波段值: B={bands.get('blue',0):.3f} G={bands.get('green',0):.3f} " f"R={bands.get('red',0):.3f} NIR={bands.get('nir',0):.3f}") result = process_single_image(img_id, bands, metadata) all_results.append(result) print(f" NDVI = {result['indices']['NDVI']:.3f}") print(f" 植被类型: {result['classification']['veg_type']}") print(f" 是否水体: {'是'if result['classification']['is_water'] else'否'}") return all_results
而后我们便要对处理的结果做一些总结,以显示我们所要处理的目的:
def generate_report(results): water_count = sum(1 for r in results if r['classification']['is_water']) veg_stats = {} for r in results: veg_type = r['classification']['veg_type'] veg_stats[veg_type] = veg_stats.get(veg_type, 0) + 1 print(f"\n影像总数: {len(results)}") print(f"包含水体影像数: {water_count}") print("\n植被覆盖统计:") for veg_type, count in veg_stats.items(): print(f" {veg_type}: {count} 景") print("\n" + "-" * 60) print(f"{'影像ID':<15}{'NDVI':<8}{'NDWI':<8}{'EVI':<8}{'植被分类':<15}") print("-" * 60) for r in results: idx = r['indices'] print(f"{r['image_id']:<15}{idx['NDVI']:<8.3f}{idx['NDWI']:<8.3f} " f"{idx['EVI']:<8.3f}{r['classification']['veg_type']:<15}")
最后我们便要做的是函数的调用,我们模拟一些数据来测试我们的函数是否正确运行:
if __name__ == "__main__": test_dataset = [ ("LC08_20240715", {"blue": 0.08, "green": 0.12, "red": 0.15, "nir": 0.45}, {"sensor": "Landsat-8", "cloud": 5.2}), ("LC08_20240801", {"blue": 0.09, "green": 0.13, "red": 0.18, "nir": 0.42}, {"sensor": "Landsat-8", "cloud": 8.1}), ("S2A_20240720", {"blue": 0.07, "green": 0.10, "red": 0.12, "nir": 0.48}, {"sensor": "Sentinel-2", "cloud": 2.3}), ("S2A_20240805", {"blue": 0.10, "green": 0.15, "red": 0.22, "nir": 0.35}, {"sensor": "Sentinel-2", "cloud": 15.6}), ("LC08_20240820", {"blue": 0.20, "green": 0.18, "red": 0.16, "nir": 0.20}, {"sensor": "Landsat-8", "cloud": 0.5}), ] results = batch_process_images(test_dataset) generate_report(results)
好了诸位,我们逐个运行上述代码便可以得到如下的结果:
至此,诸位,我们便已完成了整个函数流程的学习,同样,我们也完成了整个遥感影像的处理流程。
函数是 Python 中实现代码复用的核心工具。通过 def 关键字,我们可以将一段具有特定功能的代码封装起来,给它起一个名字,然后反复调用。
当然诸位,本章的知识较为零碎,故而会刚开始实操可能会有的云里雾里,不过诸位,相信你们可以做到的。
好的,下面我们来做一个简短的知识梳理,帮助诸位更好的理解本章的内容。
好相信诸位已经跃跃欲试了吧,展示一下吧,下面来做两个思考:
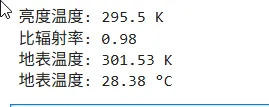
写一个函数,接收两个参数 temperature和 emissivity,返回地表温度计算公式T = brightness_temp / emissivity的结果。
def land_surface_temperature(brightness_temp, emissivity): T = brightness_temp / emissivity return Tbt = 295.5em = 0.98lst = land_surface_temperature(bt, em)print(f"亮度温度: {bt} K")print(f"比辐射率: {em}")print(f"地表温度: {lst:.2f} K")print(f"地表温度: {lst - 273.15:.2f} °C")
好的,通过上述的代码运行,我们便可以得到如下的结果:
2. 写一个函数 batch_ndvi,接收一个影像列表,为了简化诸位的思考,假设该列表为每个元素是红波段和近红外波段的列表,而后返回所有 NDVI 值列表,并用循环调用它。
def ndvi(red, nir): epsilon = 1e-10 return (nir - red) / (nir + red + epsilon)def batch_ndvi(image_list): results = [] for item in image_list: name, red, nir = item value = ndvi(red, nir) results.append((name, value)) print(f"{name}: 红={red:.3f}, 近红={nir:.3f} -> NDVI={value:.4f}") return resultsimages_with_names = [ ["Landsat_01", 0.12, 0.38], ["Landsat_02", 0.14, 0.42], ["Sentinel_01", 0.10, 0.35], ["Sentinel_02", 0.11, 0.40], ["GF1_01", 0.13, 0.37],]result = batch_ndvi(images_with_names)print("\nNDVI 值列表:")for name, value in result: print(f" {name}: {value:.4f}")
我们通过上述两个小练习,应该更好的理解了函数这个工具。如果你觉得“原来Python也能讲得这么遥感”,点个关注,后续系列推文将第一时间推送:
你在处理遥感数据时,遇到过哪些让循环“卡住”的场景?是千万级像元的遍历太慢,还是海量文件的批处理总报错?评论区聊聊,下期可能就针对你的痛点来讲解
用Python讲遥感,我们不讲噱头,只讲干货。
附赠可运行的 Notebook 源码,自行上传即可上手。本公众号后台回复【RS Python入门02-6】即可获取本节 Notebook 源码。