Linux系统监控双侠:vmstat+top详细用法,从系统全局到进程级故障排查
- 2026-07-01 12:32:54
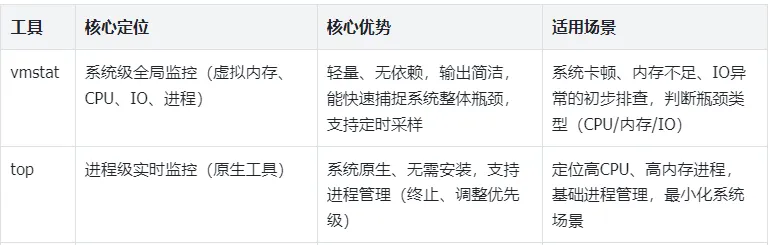
本文约5200字,在Linux运维、开发调试中,vmstat、top是linux系统监控双侠,但各自定位截然不同:vmstat聚焦系统全局资源统计,擅长捕捉CPU、内存、IO、进程的整体趋势,快速定位系统级瓶颈;top聚焦进程级监控,擅长实时跟踪单个进程的资源占用,精准定位“哪个进程在消耗资源”。
本文将详细分析vmstat的完整用法(参数、输出、场景),结合上一篇to的核心用法,重点讲解这二者的协同排查逻辑,一起来学习吧。
我建了一个BSP学习交流群,想学BSP或者已经是BSP开发者可私信我,加入群,一起交流学习,共同进步。
关注公众号, 即可获得与Linux相关的电子书籍以及常用开发工具,文末有文档清单。
一 vmstat与top的核心定位与适用场景
二 vmstat命令
vmstat(Virtual Memory Statistics,虚拟内存统计)是Linux原生轻量监控工具,核心作用是报告系统的虚拟内存、CPU、IO、进程等全局统计信息,无需额外安装,直接输入命令即可使用。它的优势的是“全局视角”,能快速判断系统瓶颈类型,而不是纠结于单个进程。
[1]. vmstat基础用法
vmstat的语法简洁,核心是“选项+采样间隔+采样次数”,常用基础用法如下(所有命令均支持root/普通用户,部分高级选项需root权限):
# 1. 查看系统全局状态快照(单次采样,输出系统启动以来的统计摘要)vmstat# 2. 定时采样监控(核心用法):每2秒采样1次,共采样5次(间隔+次数)vmstat 2 5# 3. 自定义输出单位(避免默认KB单位,更直观)vmstat -S m # 以MB为单位输出(-S 可选k/K/m/M,k=1000,K=1024,m=1000000,M=1048576)vmstat -S M 2 3 # 以MB为单位,每2秒采样1次,共3次# 4. 显示活跃/非活跃内存(区分内存使用状态,排查内存泄漏)vmstat -a 2 3# 5. 显示磁盘IO详细统计(重点排查磁盘瓶颈)vmstat -d# 6. 显示指定磁盘分区的IO统计(如监控/dev/sda1分区)vmstat -p /dev/sda1# 7. 显示系统启动以来的进程创建次数(fork次数)vmstat -f# 8. 显示详细的内存统计报表(适合深入分析内存使用)vmstat -s# 9. 宽格式输出(适配大数字,避免输出换行)vmstat -w# 10. 输出添加时间戳(便于日志记录和分析)vmstat -t 2 3
关键说明:vmstat默认采样间隔为0(单次快照),若只指定间隔(如vmstat 2),则会持续采样,直到按Ctrl+C终止;采样次数建议设置为3-5次,避免单次采样的偶然性,更能反映系统真实状态。vmstat属于procps-ng软件包,主流Linux发行版均预装,若未安装,可通过apt install procps(Ubuntu)安装。
[2]. vmstat输出参数详解
vmstat的输出分为6大模块,按顺序依次是:
进程(procs)、内存(memory)、交换分区(swap)、IO(io)、系统(system)、CPU,每一个参数都对应系统的核心状态,掌握这些参数,才能快速定位系统瓶颈。
先看我ubuntu虚拟机下的一个标准的下输出示例(ubuntu20.04,vmstat 3.3.12,以KB为单位):
root@infinova-virtual-machine:/# vmstatprocs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----r b swpd free buff cache si so bi bo in cs us sy id wa st0 0 0 880696 471600 1968596 0 0 62 196 103 319 4 3 92 1 0
vmstat的输出分为6大模块,按顺序依次是:进程(procs)、内存(memory)、交换分区(swap)、IO(io)、系统(system)、CPU。
>>procs(进程状态统计)—— 判断进程是否阻塞
核心关注“运行队列”和“阻塞队列”,反映进程的整体运行状态,是判断系统是否繁忙的基础,对应输出中第一行的 r 和 b 两个参数。
【 r(run queue)】
含义:采样间隔内,处于可运行状态(正在运行或等待CPU调度)的平均内核线程数;
作用:核心用于判断CPU是否过载,是否有进程排队等待CPU资源;
正常范围:通常不超过CPU核心数(如4核CPU,r值长期≤4);
异常判断:r值长期大于CPU核心数,说明CPU调度不过来,进程排队等待,系统会出现卡顿、响应变慢。
【b(blocked)】
含义:采样间隔内,处于阻塞状态(等待资源,如等待磁盘IO、网络IO、硬件资源、锁资源)的平均内核线程数;
作用:核心用于判断系统是否存在IO瓶颈或资源阻塞;
正常范围:b值长期为0或接近0,属于正常状态;
异常判断:b值长期大于1,说明有大量进程处于阻塞状态,大概率是IO瓶颈(如磁盘读写缓慢、网络卡顿),进程无法获取所需资源,导致系统响应变慢。
>>memory(内存状态统计)—— 判断内存是否充足
反映物理内存的使用情况,包括空闲内存、缓冲、缓存,核心是区分“真正的内存不足”和“缓存占用”,避免误判,对应输出中 swpd、free、buff、cache 四个参数,默认单位为KB。
【swpd(swap used)】
含义:已使用的交换分区(虚拟内存)大小;
作用:核心用于判断物理内存是否充足,是否需要借助磁盘模拟内存;
正常范围:swpd值为0或接近0,说明物理内存充足,无需使用交换分区;
异常判断:swpd值持续增大,说明物理内存不足,系统开始将物理内存中的数据交换到磁盘(swap),会导致系统卡顿(磁盘速度远慢于物理内存)。
【free】
含义:完全空闲的物理内存大小,未被任何进程、缓冲、缓存占用;
作用:快速查看系统裸空闲内存的基础指标;
注意事项:不能仅凭free值过低判断内存不足,因为Linux系统会主动将空闲内存分配给buff和cache,用于优化磁盘读写,这部分内存可随时释放给应用程序。
【buff(buffer)】
含义:用于存储磁盘IO的缓冲区大小,主要存放磁盘元数据、文件系统块、裸设备读写数据等;
作用:优化磁盘读写效率,减少CPU与磁盘的直接交互,将频繁读写的数据暂存到缓冲区,提升IO性能。
【cache(cached)】
含义:用于存储文件内容的缓存大小,主要存放频繁访问的文件、程序镜像、库文件、NFS缓存等;
作用:加速文件读取速度,当应用程序再次访问同一文件时,无需从磁盘读取,直接从缓存中获取,大幅提升访问效率;
关键重点:buff和cache都是“可释放内存”,当应用程序需要内存时,系统会自动释放这部分内存,分配给应用使用。
>>swap(交换分区统计)—— 判断内存是否过载
反映交换分区的读写情况,是判断物理内存是否不足的核心辅助指标,与memory模块的swpd值配合分析,对应输出中 si、so 两个参数。
【si(swap in)】
含义:每秒从交换分区读入物理内存的数据量(单位:块/秒);
作用:反映系统是否在将磁盘中的虚拟内存数据,重新载入物理内存供应用程序使用;
正常范围:si值为0或偶尔出现小数值,属于正常状态;
异常判断:si值持续大于0,说明系统正在频繁将交换分区的数据读入物理内存,物理内存严重不足,出现“内存颠簸”现象,系统性能会大幅下滑。
【so(swap out)】
含义:每秒从物理内存写入交换分区的数据量(单位:块/秒);
作用:反映系统是否因物理内存不足,将不常用的内存数据写入磁盘,释放物理内存;
正常范围:so值为0或偶尔出现小数值,属于正常状态;
异常判断:si和so值持续大于0,说明系统正在频繁进行内存交换(swap thrashing),物理内存严重不足,必须立即排查高内存进程或扩容内存;
小结:当前swap模块si=0、so=0,结合swpd=0,说明系统完全未使用交换分区,物理内存充足,无内存过载、内存颠簸现象。
>>io(磁盘IO统计)—— 判断IO是否存在瓶颈
反映磁盘的读写活动,是排查IO瓶颈的核心模块,与procs模块的b值配合分析,对应输出中 bi、bo 两个参数。
【bi(block in)】
含义:每秒从块设备(磁盘、NFS、SD卡等)读入内存的数据量(单位:块/秒);
作用:核心用于判断磁盘/块设备的读压力,数值越高,说明读操作越频繁;
正常范围:bi值根据业务场景波动,无固定标准,重点看“是否持续过高”;
异常判断:bi值持续过高(如超过1000块/秒),且procs模块的b值持续大于1,说明磁盘IO读压力过大,存在IO瓶颈;若同时CPU模块的wa值过高,可进一步确认是IO瓶颈。
【bo(block out)】
含义:每秒从内存写入块设备(磁盘、NFS、SD卡等)的数据量(单位:块/秒);
作用:核心用于判断磁盘/块设备的写压力,数值越高,说明写操作越频繁;
正常范围:bo值根据业务场景波动,无固定标准,重点看“是否持续过高”;
异常判断:bo值持续过高(如超过1000块/秒),且procs模块的b值持续大于1,说明磁盘IO写压力过大,存在IO瓶颈。
>>system(系统统计)—— 判断系统交互频率
反映系统的中断和上下文切换频率,间接反映系统的繁忙程度,对应输出中 in、cs 两个参数。
【in(interrupts)】
含义:每秒系统产生的中断次数(包括硬件中断和软件中断);硬件中断如网卡、键盘、磁盘、定时器、外设(摄像头、串口)等,软件中断如网络协议栈、定时器等;
作用:反映系统外设、内核的活跃程度,中断次数过高会消耗大量CPU资源;
正常范围:根据系统配置和业务场景波动,无固定标准,重点看“是否持续过高”;
异常判断:in值持续过高(如超过10000次/秒),说明系统中断频繁,会消耗大量CPU资源,可能导致CPU过载(尤其是sy值过高);
【cs(context switch)】
含义:每秒系统的上下文切换次数(包括进程之间切换、进程与内核之间切换);
作用:反映系统进程调度的频繁程度,上下文切换过多会消耗大量CPU资源,导致CPU利用率下降;
正常范围:根据系统配置和业务场景波动,无固定标准,重点看“是否持续过高”;
异常判断:cs值持续过高(如超过20000次/秒),说明系统上下文切换频繁,CPU大量时间消耗在内核调度上,业务进程可用CPU时间减少,导致系统响应变慢。
>>cpu(CPU统计)—— 判断CPU是否过载
与top/htop的CPU统计逻辑一致,所有参数总和为100%,反映CPU的不同占用场景,是判断CPU瓶颈的核心,对应输出中 us、sy、id、wa、st 五个参数。
【us(user)】
含义:用户态CPU占用率,即应用程序(如编译、脚本、业务进程、NFS相关进程等)占用的CPU资源;
作用:核心用于判断应用程序是否消耗过多CPU资源;
正常范围:us值<70%,说明应用程序CPU占用合理;
异常判断:us值长期>80%,说明应用程序消耗过多CPU,需通过top/htop定位具体高CPU进程;
【sy(system)】
含义:内核态CPU占用率,即Linux内核(如进程调度、内存管理、IO操作、文件系统、驱动)占用的CPU资源;
作用:核心用于判断内核操作是否频繁;
正常范围:sy值<20%,说明内核CPU占用合理;
异常判断:sy值长期>30%,说明内核操作频繁,可能是IO瓶颈、驱动问题或上下文切换过多;
【id(idle)】
含义:空闲CPU占用率,即CPU处于空闲状态、未被任何用户态或内核态进程占用的比例;
作用:最直观反映CPU的空闲程度;
正常范围:id值>30%,说明CPU空闲,无过载压力;
异常判断:id值长期<10%,说明CPU严重过载,系统卡顿、响应变慢;
【wa(iowait)】
含义:CPU空闲但在等待IO完成的时间占比,即CPU处于空闲状态,但因等待磁盘、网络IO操作完成,无法执行其他进程;
作用:核心用于判断是否存在IO瓶颈,是IO瓶颈的核心判断指标之一;
正常范围:wa值<5%,说明IO操作流畅,CPU无需等待;
异常判断:wa值长期>10%,说明CPU一直在等待IO操作完成,存在IO瓶颈,需结合io模块的bi/bo、procs模块的b值进一步验证;
【st(steal)】
含义:被虚拟化“偷走”的CPU占用率,仅虚拟机场景有效,指宿主机分配给其他虚拟机的CPU资源,物理机此值通常为0;
作用:判断虚拟机可用CPU资源是否充足;
异常判断:st值长期>5%,说明虚拟机可用CPU资源不足,需向宿主机申请更多CPU资源。
[3]. vmstat高级用法与实操场景
结合实际运维场景,vmstat的高级用法主要用于“精准排查瓶颈、日志记录、批量分析”,常用场景如下:
场景1:排查系统卡顿,定位瓶颈类型(CPU/内存/IO)
# 每1秒采样1次,共10次,以MB为单位,输出时间戳(便于分析)vmstat -S m -t 1 10
排查逻辑:
1.看r和id值:r>CPU核心数、id<10% → CPU瓶颈;
2.看swpd、si、so值:swpd持续增大、si/so>0 → 内存瓶颈;
3.看b、wa、bi/bo值:b>1、wa>10%、bi/bo持续过高 → IO瓶颈。
场景2:监控磁盘IO,定位异常分区
# 查看所有磁盘的IO统计vmstat -d# 查看/dev/sda1分区的详细IO统计(重点监控频繁读写的分区)vmstat -p /dev/sda1
排查逻辑:关注指定磁盘/分区的读写次数、IO等待时间,若某分区的bi/bo值远高于其他分区,说明该分区IO繁忙,需进一步排查该分区上的进程(结合top/htop)。
场景3:记录系统状态,用于后续分析(日志留存)
# 将vmstat输出写入日志文件,每2秒采样1次,持续1小时(共1800次)vmstat -S m -t 2 1800 > /var/log/vmstat.log 2>&1
用途:系统出现间歇性故障时,可通过日志回顾故障发生时的系统状态,定位瓶颈原因。vmstat的日志输出简洁,便于后续通过grep、awk等命令筛选分析。
场景4:排查内存泄漏(结合长期采样)
# 显示活跃/非活跃内存,每5秒采样1次,持续监控vmstat -a 5
排查逻辑:若active内存持续增长,free内存持续减少,且swpd值逐渐增大,说明可能存在内存泄漏(某进程持续占用内存且不释放),需通过top/htop定位该进程。
三 top与vmstat的协同排查逻辑
这二者协同是Linux故障排查的核心逻辑,避免“只看全局不看局部”或“只看局部不看全局”,具体流程如下:
[1].用vmstat排查系统全局瓶颈,判断是CPU、内存还是IO瓶颈;
[2].根据瓶颈类型,用top定位具体进程:CPU瓶颈(r高、id低、us/sy高):top按CPU排序,定位高CPU进程;
内存瓶颈(swpd大、si/so>0):top按内存排序,定位高内存进程;
IO瓶颈(b高、wa高、bi/bo高):top查看进程的IO占用(需按f键添加IO相关列),定位高IO进程。
[3].终止异常进程(k键/F9键)或优化进程(调整优先级、优化代码),缓解资源压力;[4].用vmstat再次采样,验证瓶颈是否缓解。四 实战演练:二者协同排查常见故障
结合3个高频运维场景,讲解vmstat+top的协同排查流程,掌握实际应用技巧,避免纸上谈兵。
场景1:系统卡顿,CPU占用100%(CPU瓶颈)
1.用vmstat定位瓶颈:vmstat 2 3 -> 观察到r=8(4核CPU)、id=2%、us=90% -> 确认CPU瓶颈;-> 发现XXX进程(PID=1234)占用CPU 85%;
3.排查进程:查看XXX进程的用途(top -c -p 1234),发现是某应用程序异常(死循环);
4.解决问题:终止XXX进程(kill -9 1234),重启应用;
5.验证:vmstat再次采样,r=1、id=85%,CPU瓶颈缓解。下一步就是去解决XXX进程的异常问题
场景2:系统响应慢,内存不足(内存瓶颈)
1.用vmstat定位瓶颈:vmstat -S m 2 3 -> 观察到swpd=2048MB、si=100、so=50、free=128MB -> 确认内存瓶颈;
2.用top定位进程:top命令进入交互页面后按下M(查看%MEM), -> 发现XXX进程(PID=5678)占用内存8GB(总内存16GB);
3.排查进程:查看进程的内存使用情况(pmap -x 5678),发现是XXX进程缓存配置过高;
4.解决问题: 降低XXX缓存大小;
场景3:磁盘读写缓慢,IO瓶颈
1.用vmstat定位瓶颈:vmstat 2 3 -> 观察到b=3、wa=25%、bi=1500、bo=800 -> 确认IO瓶颈;
2.用vmstat定位分区:vmstat -p /dev/sda1 -> 发现该分区bi/bo值极高,是IO繁忙分区;
3.用top定位进程:top -c -> 发现dd进程(PID=7890)正在大量读取该分区数据;
4.解决问题:终止dd进程(kill -9 7890),排查dd进程的用途(避免误删正常进程);
5.验证:vmstat再次采样,b=0、wa=2%、bi=50、bo=30,IO瓶颈缓解。
以上为全文内容。
这里是女程序员的笔记本
15年+嵌入式软件工程师兼二胎宝妈
分享读书心得、工作经验,自我成长和生活方式。
希望我的文字能对你有所帮助
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 用Python做科研级画图——分组散点的编码策略
- 计算机二级 vs Python/CAD/编程证书:大学生到底该考哪个?
- 300条Linux命令可以用到“退休”了!
- 工作5年的运维老鸟才摸透的Linux包管理体系,新手看完直接少踩3年坑
- 从 0 到 1,带你吃透 Linux NAPI 高并发收包
- 一行 requests,打通世界:Python 网络请求实战指南
- Quasar Linux RAT(QLNX):专为隐蔽性与持久化设计的无文件化植入程序
- 启航指南——怎么动态地查看Linux中的进程
- Linux面试高频题全整理 看完这篇真的能拿到大厂offer吗太惊喜了
- [远程工作机会] 独立站开发运维,Python开发工程师,短篇小说主编,学科教师,招聘顾问等
