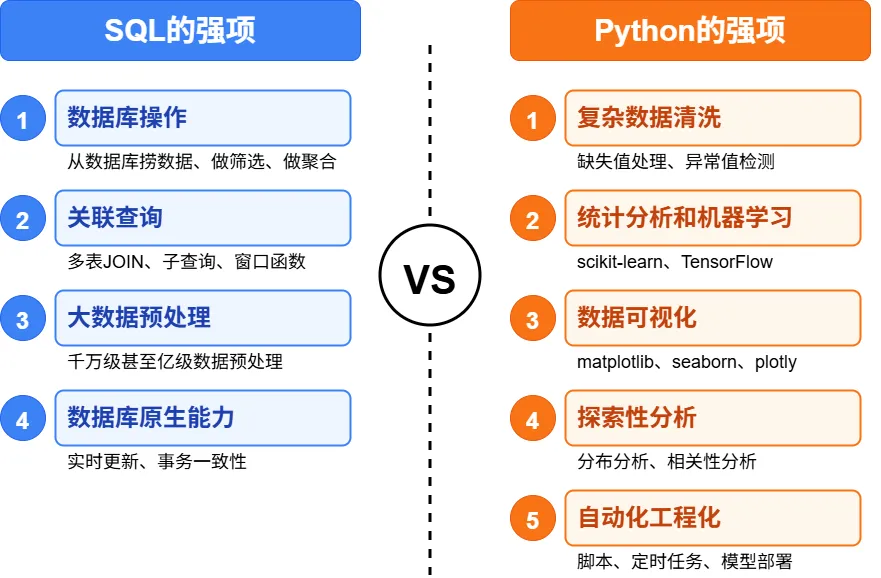
如果你要和数据库打交道,从海量数据里捞东西出来,SQL是当之无愧的主角。它专注于在数据库中快速检索你需要的数据,还能高效完成同类数据的归类、统计等基础处理工作。
具体来说,当你需要从数据库里提取数据、做筛选、做聚合时,SQL的速度优势非常明显。特别是面对百万级甚至千万级的数据量时,SQL的查询效率比Python高出不止一个量级。而且对于多表JOIN、子查询、窗口函数这类操作,SQL的语法设计就是为此量身定做的,写起来直观,跑起来飞快。此外,如果你的数据需要实时更新,或者要保证事务的一致性,这些数据库的原生能力也是SQL的强项。
而当数据从数据库里拿出来,需要做更深入的处理时,就该Python出场了。Python的优势在于它能做那些SQL做起来很费劲,甚至根本做不到的事情。
比如说复杂的数据清洗,缺失值怎么填补、异常值怎么处理、多步转换的逻辑怎么实现,这些用pandas写起来直观多了。再比如统计分析和机器学习,scikit-learn、TensorFlow这些库的能力是SQL完全无法比拟的。数据可视化也是Python的强项,matplotlib、seaborn、plotly让你想画什么图就能画什么图,定制化程度高,而且能快速做探索性分析,看看数据的分布和相关性。至于写脚本、做定时任务、部署模型这些工程化的工作,Python更是当仁不让。























 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
