# pip install pandas numpy matplotlib seaborn scikit-learn torch lifelines scipyimport osimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScaler, LabelEncoderfrom sklearn.metrics import roc_auc_score, brier_score_lossfrom sklearn.inspection import permutation_importanceimport torchimport torch.nn as nnimport torch.optim as optimfrom torch.utils.data import DataLoader, TensorDatasetfrom lifelines import CoxPHFitter, KaplanMeierFitterfrom lifelines.statistics import logrank_testfrom lifelines.utils import concordance_indeximport scipy.stats as statsfrom scipy.interpolate import interp1dimport warningswarnings.filterwarnings('ignore')# 设置中文字体和路径plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS']plt.rcParams['axes.unicode_minus'] = False# 创建结果目录results_dir = os.path.expanduser("~/Desktop/Results模型-DeepSurv")os.makedirs(results_dir, exist_ok=True)
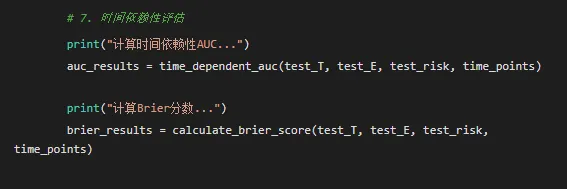
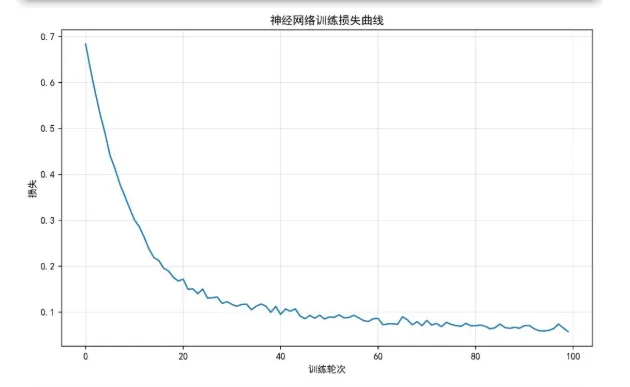
def prepare_data(self, data, features, time_col='时间', event_col='结局'):"""准备生存数据""" X = data[features].copy()# 处理分类变量for col in X.columns:if X[col].dtype == 'object': le = LabelEncoder() X[col] = le.fit_transform(X[col].astype(str))# 处理缺失值 X = X.fillna(X.median())# 获取生存数据 T = data[time_col].values E = data[event_col].valuesreturn X, T, E def create_survival_labels(self, T, E):"""创建多时间点生存标签""" n_samples = len(T) n_times = len(self.time_points) labels = np.zeros((n_samples, n_times))for i, time_point in enumerate(self.time_points):for j in range(n_samples):if T[j] <= time_point and E[j] == 1: labels[j, i] = 0 # 事件发生elif T[j] > time_point: labels[j, i] = 1 # 生存else: labels[j, i] = 1 # 删失,假设生存return labels def fit(self, data, features, time_col='时间', event_col='结局', epochs=100, batch_size=32):"""训练神经网络模型""" X, T, E = self.prepare_data(data, features, time_col, event_col)# 标准化特征 X_scaled = self.scaler.fit_transform(X)# 创建生存标签 y = self.create_survival_labels(T, E)# 转换为PyTorch张量 X_tensor = torch.FloatTensor(X_scaled) y_tensor = torch.FloatTensor(y)# 创建数据加载器 dataset = TensorDataset(X_tensor, y_tensor) dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)# 训练模型 self.model.train() losses = []for epoch in range(epochs): epoch_loss = 0for batch_X, batch_y in dataloader: self.optimizer.zero_grad() outputs = self.model(batch_X) loss = self.criterion(outputs, batch_y) loss.backward() self.optimizer.step() epoch_loss += loss.item() losses.append(epoch_loss / len(dataloader))if epoch % 20 == 0:print(f'Epoch {epoch}/{epochs}, Loss: {epoch_loss / len(dataloader):.4f}') self.is_fitted = True self.training_loss = lossesreturn losses def predict_risk(self, data, features):"""预测风险评分"""if not self.is_fitted: raise ValueError("模型尚未训练,请先调用fit方法") X, _, _ = self.prepare_data(data, features) X_scaled = self.scaler.transform(X) self.model.eval() with torch.no_grad(): X_tensor = torch.FloatTensor(X_scaled) outputs = self.model(X_tensor)# 使用所有时间点的平均风险作为综合风险评分 risk_scores = torch.sigmoid(outputs).mean(dim=1).numpy()return risk_scores def predict_survival_prob(self, data, features, time_points=None):"""预测生存概率"""if time_points is None: time_points = self.time_points risk_scores = self.predict_risk(data, features)# 将风险评分转换为生存概率 survival_probs = 1 - risk_scoresreturn survival_probsdef time_dependent_auc(T, E, risk_scores, time_points):"""计算时间依赖性AUC""" auc_results = {}for time_point in time_points: try:# 创建该时间点的标签 y_true = ((T <= time_point) & (E == 1)).astype(int)# 只考虑在时间点之前有风险的患者 at_risk = (T >= time_point) | ((T <= time_point) & (E == 1))if len(np.unique(y_true[at_risk])) > 1: auc = roc_auc_score(y_true[at_risk], risk_scores[at_risk]) auc_results[time_point] = aucprint(f"{time_point}个月AUC: {auc:.3f}")else: auc_results[time_point] = 0.5print(f"{time_point}个月AUC: 0.500 (无法计算)") except Exception as e:print(f"时间点{time_point}个月AUC计算失败: {e}") auc_results[time_point] = np.nanreturn auc_resultsdef calculate_brier_score(T, E, risk_scores, time_points):"""计算Brier分数""" brier_scores = {}for time_point in time_points: try:# 创建观测结果 observed = ((T <= time_point) & (E == 1)).astype(int) at_risk = (T >= time_point) | ((T <= time_point) & (E == 1))# 将风险评分转换为生存概率 predicted_survival = 1 - risk_scoresif len(observed[at_risk]) > 0: brier_score = brier_score_loss(observed[at_risk], predicted_survival[at_risk]) brier_scores[time_point] = brier_scoreprint(f"{time_point}个月Brier分数: {brier_score:.3f}")else: brier_scores[time_point] = np.nan except Exception as e:print(f"时间点{time_point}个月Brier分数计算失败: {e}") brier_scores[time_point] = np.nanreturn brier_scoresdef create_visualizations(eval_results, model, features, test_data, results_dir):"""创建所有可视化图表"""
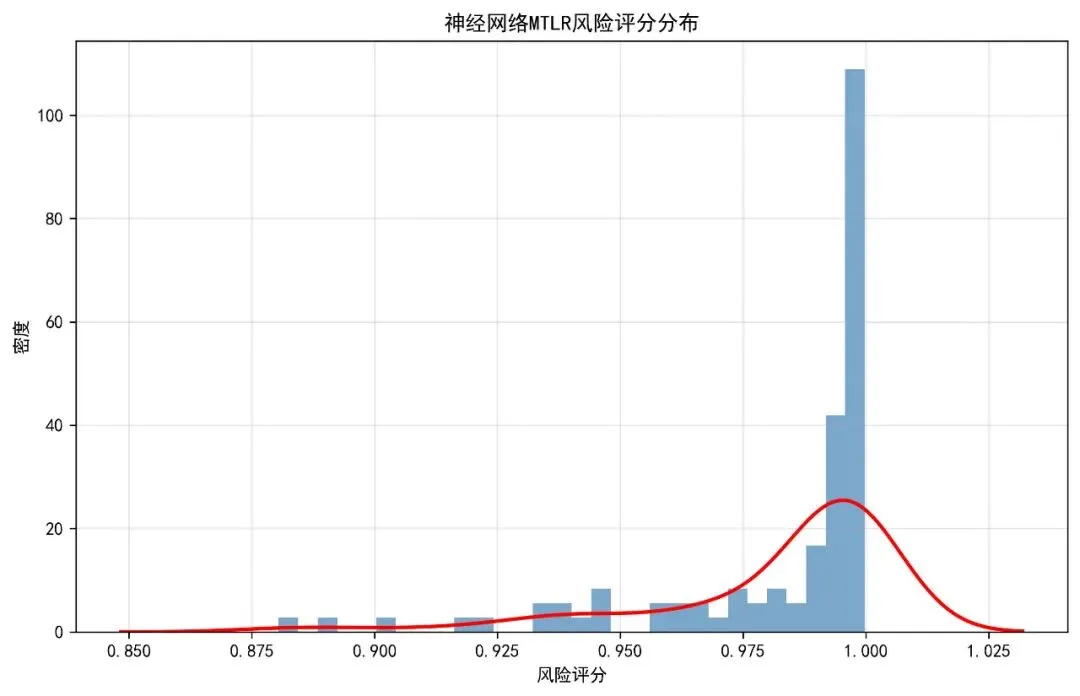
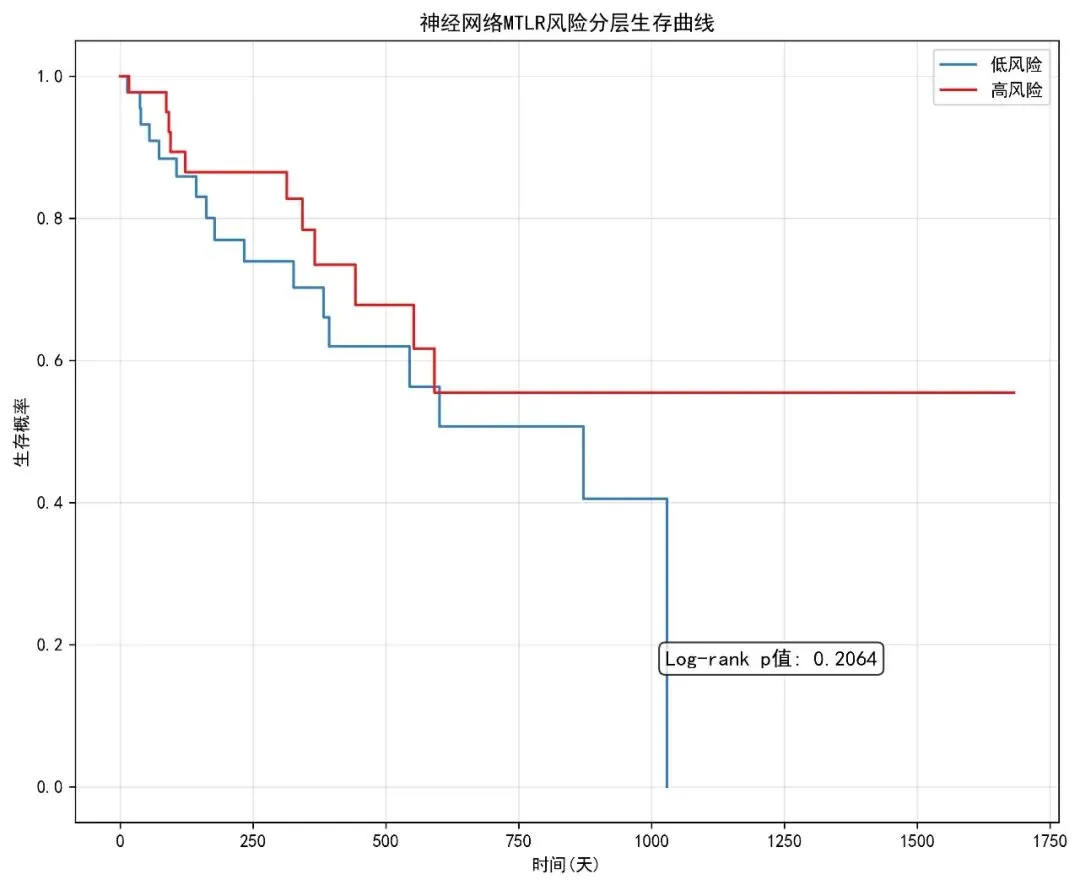
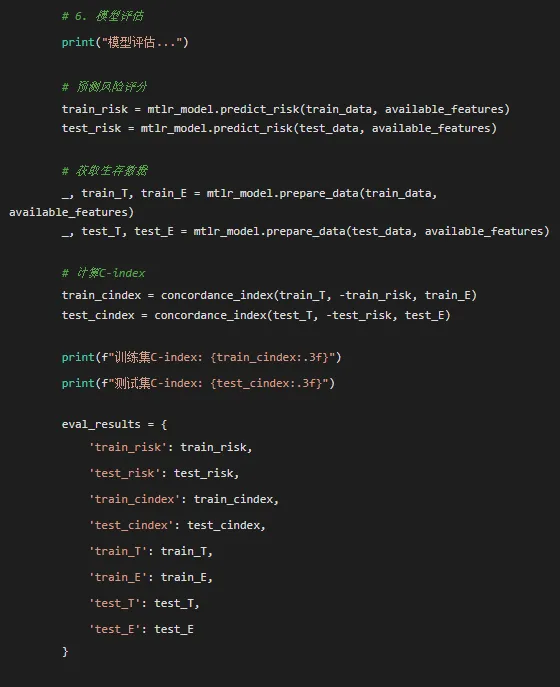
def generate_report(eval_results, model, time_points, auc_results, brier_results, results_dir):"""生成综合报告"""# 性能指标汇总 performance_data = {'指标': ['训练集C-index', '测试集C-index'],'值': [eval_results['train_cindex'], eval_results['test_cindex']] }for t in time_points: performance_data['指标'].append(f'{t}个月AUC') performance_data['值'].append(auc_results.get(t, np.nan))for t in time_points: performance_data['指标'].append(f'{t}个月Brier分数') performance_data['值'].append(brier_results.get(t, np.nan)) performance_df = pd.DataFrame(performance_data) performance_df.to_csv(os.path.join(results_dir, '性能指标.csv'), index=False, encoding='utf-8-sig')

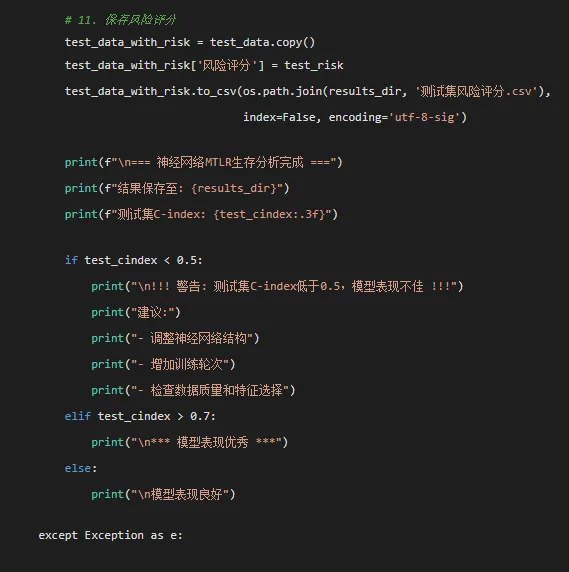
# 生成文本报告 with open(os.path.join(results_dir, '分析报告.txt'), 'w', encoding='utf-8') as f: f.write("神经网络MTLR生存模型分析报告\n") f.write("=" * 50 + "\n\n") f.write(f"模型类型: 神经网络MTLR\n") f.write(f"隐藏层维度: {model.hidden_dim}\n") f.write(f"时间点: {model.time_points}\n") f.write(f"学习率: 0.001\n\n") f.write("性能指标:\n") f.write(f"训练集C-index: {eval_results['train_cindex']:.3f}\n") f.write(f"测试集C-index: {eval_results['test_cindex']:.3f}\n")for t in time_points: f.write(f"{t}个月AUC: {auc_results.get(t, 'N/A')}\n") f.write(f"{t}个月Brier分数: {brier_results.get(t, 'N/A')}\n") f.write("\n关键结论:\n")if eval_results['test_cindex'] > 0.7: f.write("模型表现出优秀的预测能力\n")elif eval_results['test_cindex'] > 0.6: f.write("模型表现出良好的预测能力\n")else: f.write("模型预测能力有待改进\n") f.write("\n模型特点:\n") f.write("- 使用浅层神经网络结构\n") f.write("- 多任务学习框架,同时预测多个时间点\n") f.write("- 能够捕捉复杂的非线性关系\n") f.write("- 对特征交互有较好的建模能力\n")
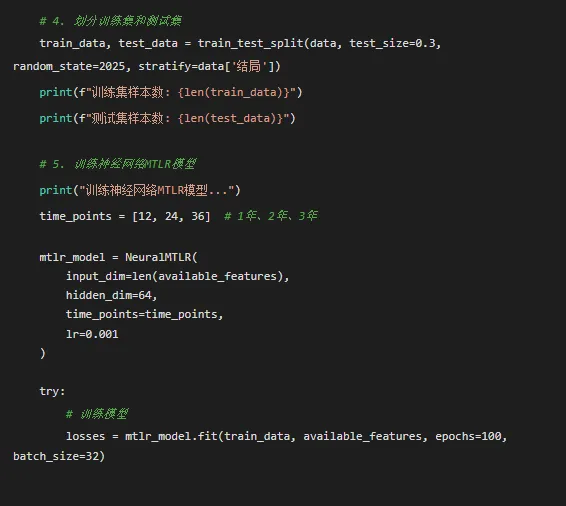
# 2. 数据预处理print("数据预处理...")# 处理分类变量 categorical_cols = data.select_dtypes(include=['object']).columnsfor col in categorical_cols: le = LabelEncoder() data[col] = le.fit_transform(data[col].astype(str))# 确保数值类型 data['时间'] = pd.to_numeric(data['时间'], errors='coerce') data['结局'] = pd.to_numeric(data['结局'], errors='coerce')# 移除缺失值 data = data.dropna()print(f"处理后数据维度: {data.shape}")# 3. 选择特征 feature_candidates = ['指标1', '指标2', '指标3', '指标4', '指标5', '指标6', '指标7'] available_features = [f for f in feature_candidates if f in data.columns]print(f"可用特征: {available_features}")