虚拟内存深度剖析:页表、TLB 与 Linux 内核机制(卷三)
- 2026-06-27 08:45:21
评估大模型集群的有效吞吐,互联带宽是核心约束。现阶段国产 GPU在处理梯度与权重 Offload 时,普遍采用跨 PCIe 调度策略。这种架构在缺乏类似C2C级内存直访机制或者NVLINK/UB/HSL支撑时,会引入显著的 I/O 延迟与协议开销。加速新架构的落地与内存访问优化,是当前国产算力生态的一个落地方向。
接上篇文章 虚拟内存深度剖析:页表、TLB 与 Linux 内核机制(卷二)
内存映射文件(Memory-mapped files)
又过几轮,Alloca 在分析大日志,一直用 read() 循环填缓冲。Kernel 走过来。
Kernel:「有更好的做法。」Alloca:「读文件还能怎样?」Kernel:「别先读进用户缓冲,把文件直接映射进地址空间;像普通内存一样用指针,我来把数据弄给你。」
Alloca:「用指针读文件?不要
read()?」Kernel:「调用mmap():给我 fd、长度、标志。我在你地址空间建新的 VMA(映射区),你在该区间读写就像普通内存,内容由文件供给。」
Alloca 照做,得到地址 0x7f4b00000000,去读首字节——停顿又来了,这次稍长。
Alloca:「这次停得更久?」Kernel:主缺页。
mmap()时我没把文件数据装进内存;文件可能数 GB,我不知道你会 touch 哪几块,只建了 VMA,PTE 仍缺席。你第一次访问该页,MMU 见 present=0,trap 进来,我得从盘读。」Alloca:「mmap也懒?」
Kernel:「对,文件也走按需分页。注意读完我把数据放哪。」Alloca:「哪?」Kernel:页缓存(page cache):内核用物理帧池缓存文件页。
read()或mmap()读文件都会进页缓存。对你这次 mmap,数据进缓存后我装 PTE 直指该页缓存帧——你的虚拟地址直接映射到装文件数据的物理帧。」
Aside:页缓存不是「预留内存」
常见误解:页缓存不是给文件预留的固定池;它只是当前用来装文件数据的物理帧集合。应用需要更多帧且无空闲时,内核可立刻回收干净页缓存帧,因为磁盘上的文件已经是后备副本。所以「内存几乎用满」的机器仍可能顺畅分配:大量「已用」RAM 是可回收缓存,而不是锁死的应用数据。
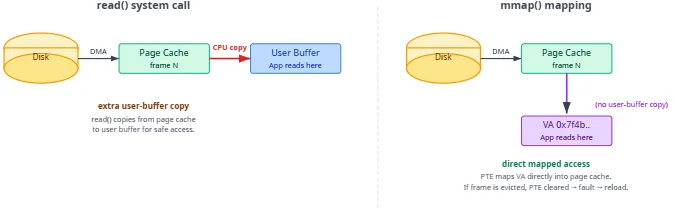
Alloca:「我通过页表直接读页缓存里的文件数据?」Kernel:「是,没有页缓存→用户缓冲的二次拷贝。对比
read():数据仍经 DMA 等进页缓存,但read()还要把页缓存帧拷贝进你的用户缓冲——这一步mmap()省掉。」
Aside:DMA(Direct Memory Access)是什么?
若 CPU 逐字节从盘/网卡搬数据会极浪费周期。DMA 让外设把数据直接搬进 RAM,CPU 可干别的;驱动提交描述目标页与存储区间的 I/O,控制器 DMA 完成后中断 CPU。
Alloca:「
mmap省第二次拷贝;若你回收了我映射着的那帧呢?」Kernel:「回收前我先摘掉指向它的 PTE;VMA 仍在,下次访问无映射→fault,我再装入——对你无缝,不会悬垂指针。」
Alloca:「那文件 I/O 总该用
mmap?」Kernel:「不一定。省一种成本,会引入 fault、页表、TLB 与不同失败形态;是否划算看访问模式。」
Aside:mmap() 并不会自动更快
冷页首次访问仍是 fault:进内核、查 VMA、找/读页缓存页、装 PTE、恢复。若大文件顺序扫一遍,可能每 4KB 一次 fault,开销可主导。
read() 常一次要一大块用户缓冲(64KB、256KB…),内核可据此 readahead;mmap 也可在检测到顺序访问时预读周边页,但控制流仍是隐式、fault 驱动。映射还占页表、增 TLB 压力,unmap/改权限可能 TLB shootdown。若他进程 truncate 映射文件,你 touch 越界页可能 SIGBUS;read() 多返回错误/短读。
mmap 在随机、重复、多进程共享或自然指针遍历场景常诱人;简单顺序流式大缓冲 read() 往往不差甚至更好。「零拷贝」≠「免费」;性能敏感代码只能实测。
此时 Forka 也要读同一日志。
Forka:「我也
mmap同一文件。」她访问 Alloca 刚读过的页——这次没有停顿。Forka:「为何这次快?」
Kernel:「页已在页缓存,Alloca 访问时装入的。我只给你的 PTE 指向同一物理帧。你们读的是同一片物理字节:无盘 I/O、无拷贝。」Alloca:「我们指同一帧?那我写映射区 Forka 能看见吗?」
Kernel:「看
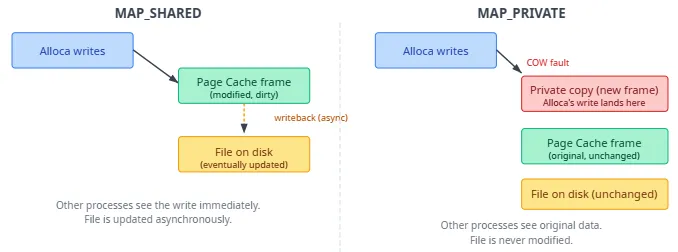
mmap标志。MAP_SHARED:写进共享页缓存帧,她可见;MAP_PRIVATE:首次写走 CoW 得私有页,与fork后类似,不改磁盘文件。」Alloca:MAP_SHARED何时落盘?Kernel:「异步回写;要强制落盘用msync()或fsync()。」
Key Takeaway
mmap() 把文件中一段字节直接映射进进程虚拟地址空间,建立文件后备 VMA;之后对该区间的读写与普通访存相同,由内核缺页路径按需从盘装入。
核心是 page cache:内核管理的物理帧池,缓存最近访问的文件页。缓冲 I/O 下 read/write/mmap 都经页缓存;差别在用户空间如何触及这些字节:
read()拷贝到用户缓冲的原因:所有权——调用返回后内核可换出页缓存页而不影响调用者已拿到的数据。mmap()通过页表抽象:映射页被逐出则 PTE absent,下次访问 fault 透明重装。
Aside:用 Direct I/O 绕过页缓存
默认 read/write/mmap 走页缓存。另可选用 O_DIRECT 打开文件,让存储栈与用户缓冲之间直传,绕过常规页缓存路径;适合想自建应用层缓存、不想内核页缓存插手的场景。但缓冲地址、长度、偏移常需满足文件系统/设备对齐(常见 512B 或 4KB,依实现而定)。
数据库等顺序扫表时,缓冲 I/O 可能把页缓存填满「中间数据」、挤出真正热页;于是它们在用户空间自建缓冲池并用 O_DIRECT 关掉内核页缓存。
代价:失去页缓存提供的 readahead、脏页缓冲/回写、以及进程间共享缓存页等机制;你要自管缓冲、I/O 大小、对齐与调度。多数应用缓冲 I/O 更合适;O_DIRECT 给已有自缓存且需细控内核缓存行为的工作负载。
匿名、文件后备与共享内存
Alloca 已知有些页来自文件、有些来自零页,但还缺一套分类词汇。
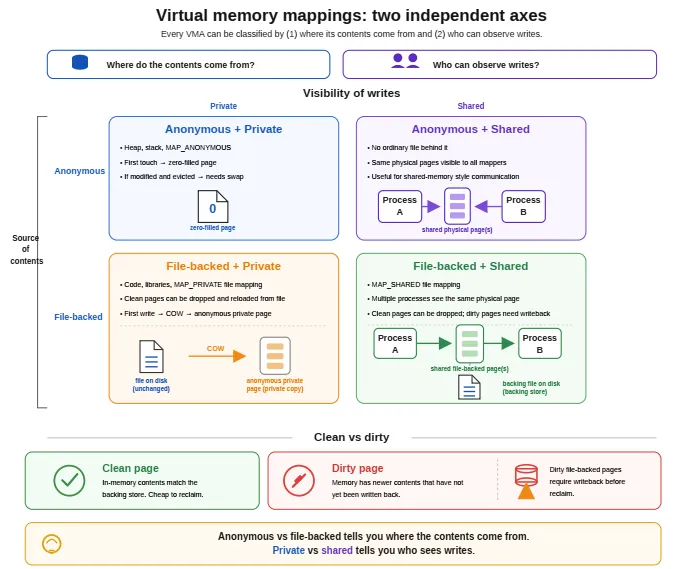
Alloca:「匿名、文件后备、共享……是不同机制还是换名?」Kernel:「是映射类别。每条 VMA 告诉我两件事:数据从哪来,谁能看见你的写。」Alloca:「先看来源。」Kernel:「要么来自文件(如
mmap文件)→ file-backed;要么匿名、无普通文件支撑——堆、栈,或MAP_ANONYMOUS。」Alloca:「第二件事?」Kernel:私有 vs 共享。私有映射写只归你;若源自文件,首次写常 CoW 成私有匿名页,磁盘文件不变。共享映射则多进程映射同一对象可互见写入。」Alloca:「文件/匿名描述内容来源;私有/共享描述写可见性。」Kernel:「对。」
Key Takeaway
匿名内存:无普通文件后备;堆、栈、 MAP_ANONYMOUS等;新页首次 touch 零填;脏页被逐出需 swap(无文件可 reload)。文件后备内存:可执行、共享库、文件映射;干净文件页可丢弃后再从文件装入;脏页须先 writeback。 私有映射:写仅本进程可见;私有文件映射初可共享干净文件页,首次写经 CoW 成匿名私有页。 共享映射:多进程互见写; MAP_SHARED、POSIX 共享内存等。
Aside:tmpfs——文件与匿名的混合体
常说的「共享内存」(shm_open、SysV shm、/dev/shm)与上文「共享映射」不同:后者仅指写对他 mapper 可见;这些 API 常基于 tmpfs。
tmpfs 文件系统内容全在内存+swap,无持久盘文件;可 open/mmap/fstat,重启即失。回收视角更像匿名:脏 tmpfs 页无磁盘文件可 reload,多走 swap;内部仍经 VFS 与页缓存管理,故仍能用熟悉文件 API。两进程 MAP_SHARED 映射 /dev/shm 下同一路径可共享物理帧,作快速 IPC。
页回收:内核如何挑选牺牲页
Alloca 听过「内存满就换冷的」,想知道到底怎么选。
Alloca:「你说选最近少用的页,怎么知道谁冷?」Kernel:「物理帧挂在近似 LRU 的链表上,从最冷端找候选。」Alloca:「链表怎么维护?每次访存都软件跟踪?」
Kernel:「那样太贵。靠硬件:PTE 的 accessed 位,MMU walk 用过该映射时自动置位;我稍后扫、不必每次 trap。」Alloca:「MMU 置位了,可 LRU 是按帧组织的,你要扫所有进程页表?」Kernel:「更糟。我反过来:从 LRU 冷端扫帧,用 rmap(反向映射) 找到指向该帧的 PTE,再看 accessed。」
Alloca:「还有反向映射?」Kernel:「页表是虚拟→物理的正向图;每帧还挂元数据:哪些 VMA/PTE 正映射它。要判断热冷就跟 rmap 找到 PTE 看 accessed。」Alloca:「拼起来是怎样?」Kernel:「回收时从 inactive 尾取候选帧,经 rmap 查映射页的 accessed。未置位→可逐出;置位→可能刚热过也可能只碰一次,于是清 accessed 再给一次机会,下次仍冷再逐。」
Aside:kswapd 守护进程
Linux 常跑后台 kswapd 监视空闲水位;空闲低于阈值即唤醒做后台回收,避免事态紧急。若跟不上,分配路径可能陷入 direct reclaim,表现为分配延迟。
Alloca:「inactive/active 怎么流转?」Kernel:「简化模型:active / inactive 各一头新一尾旧。新 fault 的页常先进 inactive 头侧;随时间被更新页挤向尾端。多次扫描仍见 accessed 的页升入 active;active 过大则尾页降回 inactive。inactive 尾是 eviction 主战场;反复仍冷的页最终被换出。」
Aside:多代 LRU(MGLRU)
两桶模型粗:只能粗辨「扫描时像最近用过」,难刻画温度曲线;万次访问与一次访问在晋升后可能「看起来一样」。混合频率、突发 I/O 时易误杀将用页或久留无用页。
MGLRU 用多代代替两链表,页在新代 fault/访问,不再访问则落入更老代,再访问则刷新回年轻代;回收优先最老代。Linux 6.1 引入;CONFIG_LRU_GEN 编译,CONFIG_LRU_GEN_ENABLED 默认启用;/sys/kernel/mm/lru_gen/enabled 运行时开关。
Alloca:「冷页找到后,类型有差别吗?」Kernel:「先分文件 vs 匿名。干净文件页最便宜:与磁盘一致即可丢帧,下次 fault 从文件装回。脏文件页要先 writeback。
MAP_PRIVATE写先 CoW 成私有匿名副本,无持久 home,逐出像匿名脏页一样常需 swap。」
Alloca:「压力下文件缓存比堆好逐出?」Kernel:「常是,尤其干净缓存。故「空闲内存低」未必病态:大量 RAM 可能是可回收页缓存。危险是各进程热 working set 之和超 RAM,被迫逐出很快又需要的页→**抖动(thrashing)」。」
Alloca:「抖动就是反复换出又 fault 回?」Kernel:「对。CPU 等 fault/盘 I/O 的时间超过有用计算,虚拟内存「内存很充裕」的幻觉就太贵了。」
Key Takeaway
页回收在压力下释放物理帧;是近似 LRU,两类机制使其可行:
Accessed 位:MMU 使用后自动置位;内核周期性读/清以估计冷热而无需每次访存 trap。 Rmap:从帧反查 PTE/VMA,回收只扫候选帧相关 PTE,成本随帧规模而非所有进程虚拟空间总和增长。
Active/Inactive LRU:页在 active/inactive 间迁移;Linux 还按匿名/文件分 LRU。inactive 尾扫描:accessed 置位则清位再给机会;清除则驱逐。持续热的页升 active;active 过大则尾页降 inactive。MGLRU 用多代细化。
逐出成本依页类型:干净文件页最便宜;脏文件页须回写;有私有数据的匿名页一般要 swap(无 swap 时更难逐)。
实务:已用内存不全是坏事,干净页缓存易回收;真正风险是热 working set 超 RAM 导致抖动。
内存访问模式与虚拟内存性能
Alloca 两种结构存同样数据、都在 RAM,顺序扫数组几秒,哈希探测却慢十倍。
Alloca:「PTE 都有,为何哈希慢这么多?」Kernel:「虚拟地址让你以为一样快,其实不然。代价取决于与 TLB、cache、物理布局 的交互。」
Alloca:「数组与哈希差在哪?」Kernel:「顺序扫数组:地址
0x1000, 0x1004…同一 4KB 页内上千次访问,复用同一 TLB 项;跨页才换新项——活跃 TLB 窗口小、复用高。哈希随机探测:页 47→3→201… TLB 层次容量有限,新翻译常挤掉很快又要用的项,硬件反复 page table walk。」
Alloca:「TLB 全 miss 要先 walk 才能读数据?」Kernel:「对。大范围随机访问会为每个想要的字节付大量翻译税。还有预取器:顺序模式 CPU 可预取后续 cache line;哈希无规律,预取帮不上。数组在页内也常能预取;跨 4K 边界预取通常保守(可能 fault/权限)。」
Alloca:「反复 touch 同一批页呢?」Kernel:「热页翻译留在 TLB,帧也更不易被回收——回收策略会偏向少碰的页。」Alloca:「working set 小就赚?」Kernel:「紧 working set 便宜;若摊开成十万页且偶发 touch,TLB 反复重建,压力下还可能被换出到 swap——就不只 TLB miss,还有盘 I/O。」
Alloca:「能控制吗?」Kernel:「注意数据打包:VM 以页为粒度,更紧的布局=同样逻辑工作更少页、更少翻译与 walk。」
Aside:数据布局也改变 TLB 覆盖
编译器为对齐会 padding;结构体数组若每元素因填充从 16B 变 24B,百万元素差数百万字节→更多页→更多 TLB 项与压力。常见技巧:按对齐需求从大到小排字段(8→4→2→1 字节)以减少尾填充。
Key Takeaway
虚拟地址看起来等价,但 CPU TLB 层次容量有限(常见数百到数千项量级,依 CPU 与页大小)。working set 超出可覆盖页数则 miss 增多;次级 TLB 命中比完整 walk 便宜,但 walk 仍可能很贵。
顺序访问:长时间留在少量页上,TLB 项高度复用,预取友好→扫描快。随机访问(哈希探测、链表追逐):频繁换页、TLB 抖动、预取失效,最坏接近「访问即可能 miss+walk」。
时间局部性:反复同一页则翻译与帧都更热;稀疏偶访则不断重建翻译并累积内存压力。
布局影响页数:差结构多 padding 可使数组页数翻倍——同样逻辑对象,一版 fit TLB、一版抖动。VM 以页为粒度,cache 以 cache line 为粒度;高性能代码同时考虑二者及与翻译机制的交互。

