做嵌入式 Linux 项目,最怕的不是系统报错,而是设备“卡住、重启、无响应”。这种问题往往发生在客户现场、长时间运行后,甚至只在某一批硬件上复现。它不像普通功能 bug 那样容易断点调试,更多时候考验的是工程团队有没有一套可落地的排查闭环。
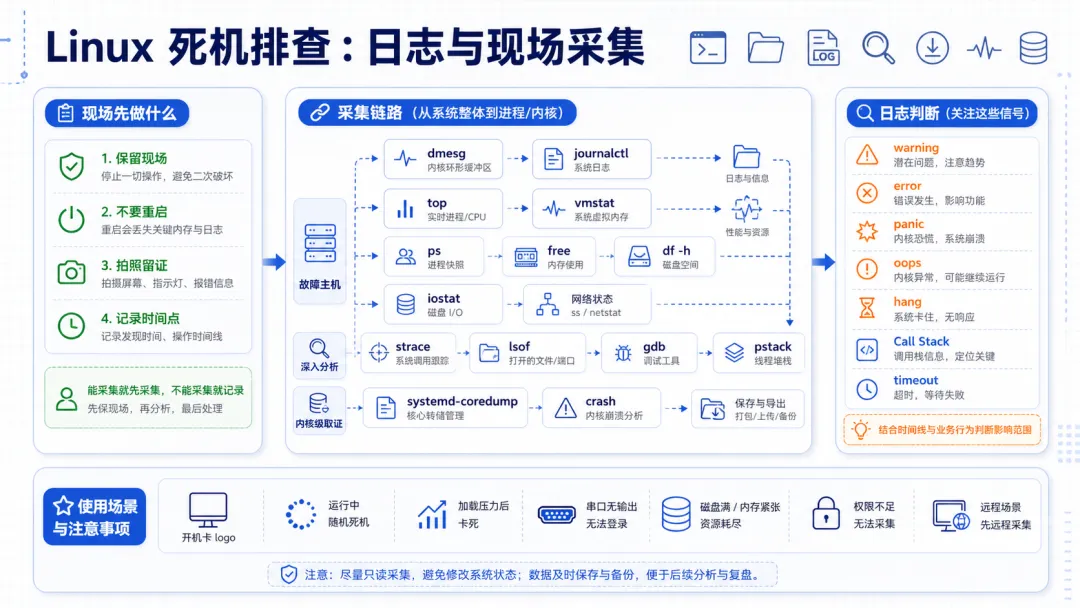
死机排查不能只靠经验猜测,也不能一上来就怀疑内核。更稳妥的做法,是先保护现场,再收集证据,随后从日志、内核、驱动、硬件和复现条件几个方向逐层收敛。
1 系统死机排查要先建立闭环
遇到系统卡死,第一步不是马上断电重启,而是判断设备到底处于什么状态:串口还有没有输出,网络能不能 ping 通,SSH 是否还能登录,业务线程是否只是阻塞,还是整个内核已经失去调度能力。
这里有一个很实用的判断:如果串口、网络、按键中断都没有响应,大概率已经进入内核级异常或硬件级挂死;如果系统还能登录,只是业务无响应,优先看进程、锁、IO 等用户态问题。这个边界判断越早做清楚,后面就越少走弯路。
1.1 先保护现场,再动手分析
很多现场问题之所以难查,是因为第一反应就是重启设备。重启确实能恢复业务,但也会抹掉最有价值的上下文。工程上更推荐先记录串口输出、LED 状态、电源电流、网络连接、关键进程状态,再决定是否重启。
常见证据包括 dmesg、journalctl、/var/log/、core dump、pstore、/proc、/sys,以及串口完整日志。对于量产设备,还应提前打开内核 panic、Oops、watchdog、pstore/ramoops 等机制,否则问题真正出现时只能靠猜。
1.2 把“能否复现”作为分水岭
能稳定复现的问题,通常可以通过二分法、压力测试、驱动裁剪、接口替换快速收敛。不能稳定复现的问题,则要靠日志留存、现场监控和长期运行数据。经验上,死机排查最忌讳只看最后一条日志,因为真正的诱因可能在几分钟甚至几小时前就已经出现。
因此,排查闭环应该包含现象识别、现场保护、证据采集、软硬件判断、内核驱动分析、复现验证和回归测试。没有闭环,修复往往只是“这次看起来好了”。
2 日志、内核和调用栈是定位根因的主线
Linux 死机问题的核心证据,一般藏在日志、内核异常和调用栈里。warning、error、Oops、Panic、Call Trace、backtrace 这些信息不是噪声,而是系统给出的方向。
2.1 必须把日志采全
基础日志至少包括 dmesg -T、journalctl -k -b -1、/var/log/、coredumpctl、/proc、/sys 和串口日志。如果系统有 BMC、IPMI 或独立监控芯片,也要一起采集。只看应用日志,很容易把内核死锁、驱动异常、电源抖动误判成业务逻辑问题。
调用栈分析时,不要只盯着最后一个函数。要看锁、等待队列、中断上下文、工作队列、内存分配路径,以及是否出现 hung_task、soft lockup、RCU stall。这些信息能帮助判断问题是死锁、长时间关中断、内存破坏,还是驱动在错误上下文里做了不该做的事。
2.2 工具链要组合使用
GDB、KGDB、pstack、perf、strace、ftrace、top、ps、vmstat、iostat 都有各自边界。比如 strace 适合看用户态系统调用卡在哪里,perf 适合看热点和调度行为,ftrace 适合追内核路径,KGDB 更适合低频、可控的内核级调试。
现场项目里不要指望一个工具解决所有问题。更可靠的方式是先用轻量工具缩小范围,再用重工具确认根因。工具使用顺序不当,也会改变系统时序,甚至让问题消失。
3 硬件、驱动和复现验证决定修复是否可靠
嵌入式系统的死机,很多时候并不是单纯的软件问题。电源纹波、温度、EMI、时钟、DDR 稳定性、外设总线异常,都可能通过驱动路径表现为内核卡死。
3.1 驱动排查要盯住边界条件
重点关注 HAL、GPIO、UART、SPI、I2C、PWM、中断、DMA、锁、资源泄漏、probe/remove 和版本差异。驱动代码最容易出问题的地方,往往不是主流程,而是异常路径:设备不存在、超时返回、重复初始化、并发关闭、卸载过程中仍有中断上报。
例如 I2C/SPI 外设偶发无响应时,不能只在驱动里无限重试。要确认总线是否被拉死、时钟是否异常、DMA 是否越界、锁是否在中断上下文被错误使用。驱动层如果没有超时、复位和降级策略,最终就会把一个外设问题放大成系统级死机。
3.2 修复必须经过复现和长稳验证
真正有效的修复,不是改完代码跑一次通过,而是能解释现象、能稳定复现、能证明修复有效。常用方法包括最小化环境、二分法、压力测试、时间线对齐、日志对照、单变量修改和稳定复现脚本。
修复后还要做长稳运行,例如 24 小时、72 小时甚至 168 小时压力测试,同时监控 CPU、内存、IO、网络、中断、温度、电源和 watchdog 状态。对工业控制、边缘设备、网关和开发板这类场景来说,短时间功能正常不等于系统可靠。
4 总结
Linux 死机排查的关键,不是背多少命令,而是建立证据驱动的工程闭环:先保护现场,再采集证据;先区分软硬件边界,再深入内核和驱动;先复现问题,再验证修复。
系统稳定性从来不是靠一次“灵感修复”换来的,而是靠日志、工具、硬件测量、驱动边界和长期验证一点点打磨出来的。对嵌入式团队来说,这套方法越早沉淀,后续现场问题的恢复速度和量产可靠性就越有保障。