如何用 Python 自动归整提资资料,提升效率?
在审计工作收资阶段,你是否也遇到这样的问题,我们精心设计了收资清单,但当收到提资资料时,文件夹套着文件夹,压缩包嵌着压缩包,且zip`、 `.rar`、'.7Z'等各种压缩格式层出不穷,手动解压成百上千个文件,让你血压瞬间升高。解决思路
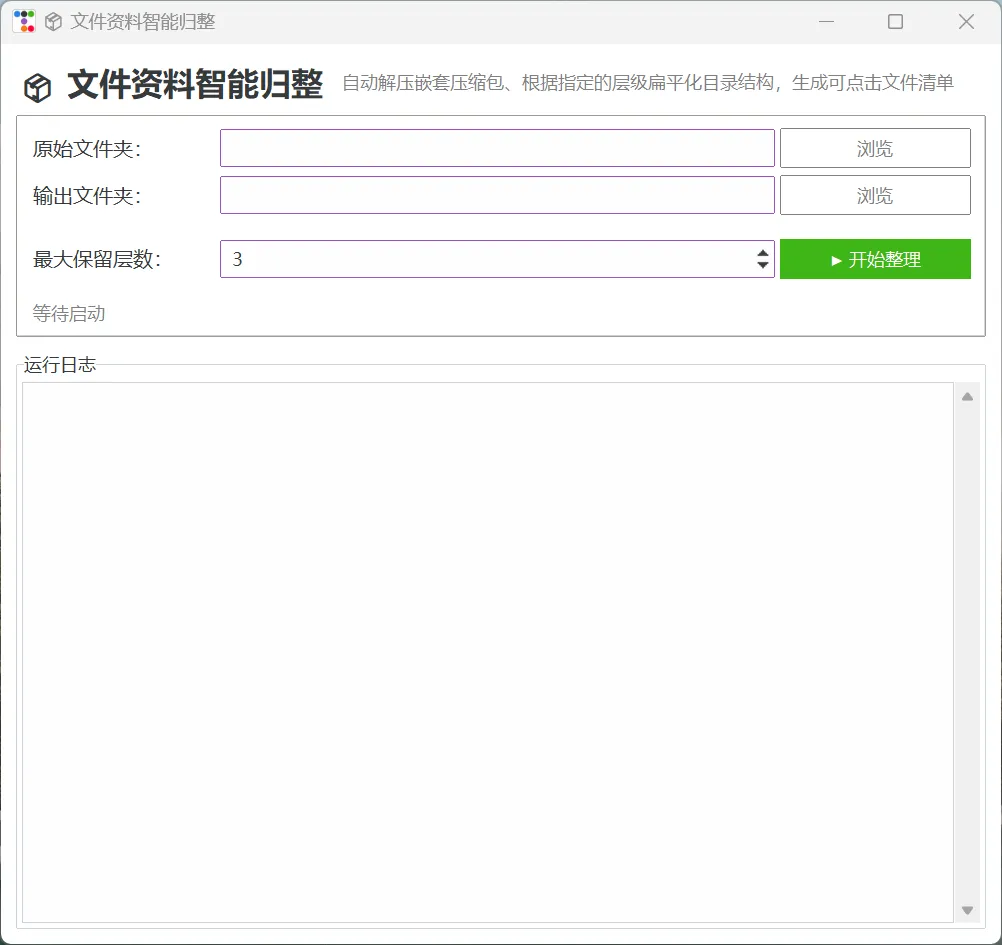
重复的事让脚本来做,为此,我设计了一个 Python 脚本,一是以提资资料的现有结构为基础,同时考虑目录的可读性,脚本设置一个最大保留层数(默认 3 层),超过该层级的文件会被上提到父目录,并按路径自动重命名,从而构建标准化的文件夹结构。二是全递归解压,脚本设置防止死循环判断,无论原始资料如何嵌套、如何复杂,通过递归一次性解压全部文档,解压成功后自动删除压缩包,若失败则提示失败信息并保留压缩文件以备后期检查。三是整理完成后,脚本在输出目录生成一个 `文件清单.html`,通过相对路径获取文件地址,双击即可在浏览器中打开浏览,避免回到文件夹中一个个地寻找查看。应用示例
以某专项审计审前调查资料为例,该提资资料超10GB,包含87 个一级文件夹,一级文件夹下有53 个压缩包,最深嵌套 7 层。若采用人工检查方式,想必仅解压这些压缩文件就会让你血压飙升、腱鞘发炎。但在采用自动化脚本程序后,整个处理过程不足五分钟(主要是解压大型文件所耗),程序归整处理后自动生成html文件目录(请忽略版主生硬的马赛克)。为方便不具备python基础的朋友使用,版主设计一个可扩展的脚本合集 GUI 框架。该框架通过定义统一的接口,实现动态加载放置在项目中的脚本文件,目前我们第一个《文件资料归整处理》脚本已成功加入,你可以关注本公众号并在后台回复关键词 “文件资料智能归整”获取exe可执行文件。“把重复性的整理交给脚本,把思考性的判断留给自己”——这是我做审计数字化的出发点。如果你也在审前调查中被类似问题困扰,不妨试试,然后告诉我是否好用。若你在审计过程中有一些可固化的思路和模型,也请你告诉我,或许下一篇脚本的选题可能就来自你的留言。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
