一、业务场景
前两天听一个出纳同学说了这样一个情况,很多公司每天出资金汇总日报之前,需要先把内部往来款核对清楚。公司数量可能不多,就十几家到几十家,但往来款需要人工一家一家排列组合地查,且每天要赶在下班前查完,是个不小的工作量。
尤其对于还在用Excel做日记账的中小企业来说。
大型公司通常在资金模块里有资金归集和划拨的专用模块,自带对账功能或唯一业务识别号,不太需要这个。但中小企业没有这些系统,各家财务各记各的Excel,每天的往来款核对全靠人肉,A公司的出纳问B公司的出纳"你今天记了我那笔吗",B公司出纳翻半天表格说"等一下我找找",一来一回又加班了。
出纳同学想要的效果:把所有公司的日记账往文件夹里一扔,几秒钟,当天的往来款谁对上了谁没对上、差多少钱,一眼看清楚。
做了个demo简单模拟下这个场景,仅作为学习参考哦。
二、收集日记账文件
把所有日记账放到桌面的一个文件夹里。每家公司日记账格式统一(一般也是同一个模板),关键列:日期、对方公司、费用分类、收支方向、金额、摘要。
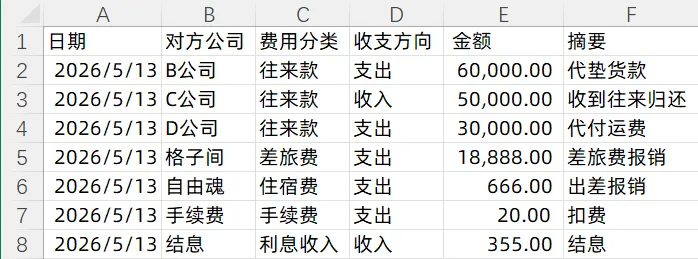
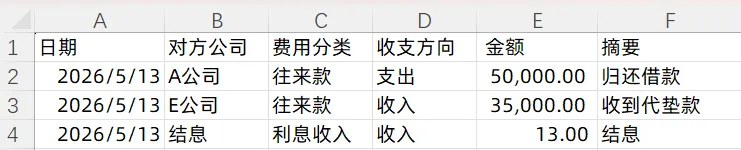
假设这是各公司某天的日记账内容:
A公司.xlsx:
B公司.xlsx:
C公司.xlsx:
D公司.xlsx:
E公司.xlsx:
三、处理步骤
第一步:读取文件夹,把所有公司日记账拼成一张总表
遍历文件夹里所有Excel文件,每个文件筛出"费用分类=往来款"且"日期=今天"的行,加一列"本方公司",全部拼到一起。
第二步:按收支方向拆成支出清单和收入清单
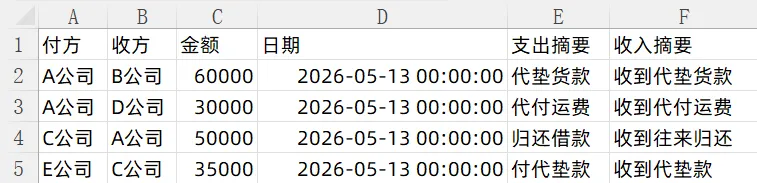
支出清单:从总表里筛"收支方向=支出"。本公司是付钱的人,对方公司是收钱的人。加ID和配对状态。
收入清单:从总表里筛"收支方向=收入"。本公司是收钱的人,对方公司是付钱的人。列名映射后和支出清单结构统一。
第三步:逐笔配对
遍历支出清单每一行,去收入清单里找同时满足五个条件的:付方相同、收方相同、金额相同、日期相同、配对状态=未匹配。找到了就配对成功,双方标记已匹配。
逐笔走一遍:
支出ID=1:付方A、收方B、金额60,000、日期3/12 → 收入ID=2匹配。双方标记已匹配。
支出ID=2:付方A、收方D、金额30,000、日期3/12 → 收入ID=4匹配。双方标记已匹配。
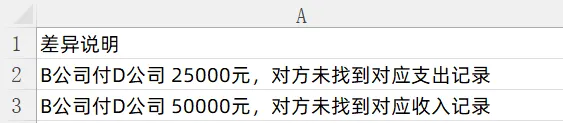
支出ID=3:付方B、收方D、金额50,000、日期3/12 → 收入清单里B→D有ID=5,但金额25,000,不匹配。支出ID=3保持未匹配。
支出ID=4:付方C、收方A、金额50,000、日期3/12 → 收入ID=1匹配。双方标记已匹配。
支出ID=5:付方E、收方C、金额35,000、日期3/12 → 收入ID=3匹配。双方标记已匹配。
遍历结束。支出ID=3未匹配,收入ID=5未匹配。
第四步:输出结果
勾稽成功4对:
勾稽差异2笔:
B付了D5万,D只记了收B 2.5万。几秒直接定位,马上找B和D的财务核实,不用等到月末翻历史账。
四、这次先放参考代码(仅供学习参考)
import pandas as pdimport osfrom datetime import date# ==================== 1. 设置 ====================today = date.today() # 当天日期,也可手动指定如 pd.Timestamp('2026-03-12')folder_path = r"C:\Users\admin\Desktop\各公司日记账"# ==================== 2. 读取文件夹所有日记账,拼总表 ====================all_records = []for file_name in os.listdir(folder_path): if file_name.endswith('.xlsx'): file_path = os.path.join(folder_path, file_name) df = pd.read_excel(file_path) self_company = file_name.replace('.xlsx', '') # 只筛当天 + 往来款 df_filtered = df[ (df['费用分类'] == '往来款') & (pd.to_datetime(df['日期']).dt.date == today) ].copy() if len(df_filtered) == 0: continue df_filtered['本方公司'] = self_company all_records.append(df_filtered)if len(all_records) == 0: print(f"{today} 无往来款记录,无需勾稽。") exit()df_all = pd.concat(all_records, ignore_index=True)# ==================== 3. 拆支出清单和收入清单 ====================# 支出清单:收支方向=支出,本公司→付方,对方公司→收方expense_df = df_all[df_all['收支方向'] == '支出'][['本方公司', '对方公司', '金额', '日期', '摘要']].copy()expense_df.columns = ['付方', '收方', '金额', '日期', '摘要']expense_df.insert(0, 'ID', range(1, len(expense_df) + 1))expense_df['配对状态'] = '未匹配'# 收入清单:收支方向=收入,对方公司→付方,本公司→收方income_df = df_all[df_all['收支方向'] == '收入'][['对方公司', '本方公司', '金额', '日期', '摘要']].copy()income_df.columns = ['付方', '收方', '金额', '日期', '摘要']income_df.insert(0, 'ID', range(1, len(income_df) + 1))income_df['配对状态'] = '未匹配'income_df['配对ID'] = None# ==================== 4. 逐笔配对 ====================matched_pairs = []for idx, exp_row in expense_df.iterrows(): if expense_df.at[idx, '配对状态'] == '已匹配': continue match = income_df[ (income_df['付方'] == exp_row['付方']) & (income_df['收方'] == exp_row['收方']) & (income_df['金额'] == exp_row['金额']) & (income_df['日期'] == exp_row['日期']) & (income_df['配对状态'] == '未匹配') ] if len(match) > 0: match_idx = match.index[0] expense_df.at[idx, '配对状态'] = '已匹配' income_df.at[match_idx, '配对状态'] = '已匹配' income_df.at[match_idx, '配对ID'] = exp_row['ID'] matched_pairs.append({ '付方': exp_row['付方'], '收方': exp_row['收方'], '金额': exp_row['金额'], '日期': exp_row['日期'], '支出摘要': exp_row['摘要'], '收入摘要': income_df.at[match_idx, '摘要'] })matched_df = pd.DataFrame(matched_pairs)# ==================== 5. 整理差异 ====================unmatched_expense = expense_df[expense_df['配对状态'] == '未匹配'].copy()unmatched_expense['差异说明'] = unmatched_expense.apply( lambda row: f"{row['付方']}付{row['收方']}{row['金额']:.0f}元,对方未找到对应收入记录", axis=1)unmatched_income = income_df[income_df['配对状态'] == '未匹配'].copy()unmatched_income['差异说明'] = unmatched_income.apply( lambda row: f"{row['收方']}收{row['付方']}{row['金额']:.0f}元,对方未找到对应支出记录", axis=1)unmatched_all = pd.concat([unmatched_expense, unmatched_income], ignore_index=True)# ==================== 6. 保存结果 ====================output_path = fr"C:\Users\admin\Desktop\往来款勾稽检查_{today}.xlsx"with pd.ExcelWriter(output_path, engine='openpyxl') as writer: matched_df.to_excel(writer, sheet_name='勾稽成功', index=False) unmatched_all.to_excel(writer, sheet_name='勾稽差异', index=False)# ==================== 7. 打印摘要 ====================print("=" * 50)print(f"往来款逐笔勾稽检查 - {today}")print("=" * 50)print(f"涉及公司: {df_all['本方公司'].nunique()} 家")print(f"支出笔数: {len(expense_df)}")print(f"收入笔数: {len(income_df)}")print(f"勾稽成功: {len(matched_df)} 对")print(f"勾稽差异: {len(unmatched_all)} 笔")print()if len(unmatched_all) > 0: print("差异明细:") for _, row in unmatched_all.iterrows(): print(f" ✗ {row['差异说明']}")else: print("✓ 全部勾稽通过。")print(f"\n结果已保存至: {output_path}")
五、使用说明
每天下班前,把各公司当天的日记账Excel扔进"各公司日记账"文件夹,运行脚本。输出文件带日期,方便归档。结果里勾稽成功的多看一眼摘要,以防特殊情况;差异表里哪家付了多少钱对方没记、哪家收了多少钱对方没记,一目了然,直接找对应公司的财务补记。文件路径这些根据实际情况改一下即可。
本文章仅为学习参考,不可在生产场景使用。学习用的文件需先行获得授权,或使用个人自有文件进行学习。
六、其他情况
1. 对方公司写法不一致
代码用收付方名称匹配对方公司名,写法不一致会判为差异。但实际工作中,出纳都是从银行流水里批量复制信息到日记账,对方公司名通常就是银行流水里的全称,理论上一致。出纳主管也可以统一要求写全称。偶尔手误写错一两笔,代码正好把差异报出来,反而帮助发现了录入错误。
2. 同一天同一家公司多笔同金额
极端情况下同一天A付B两笔5万,代码按顺序匹配,存在错配可能。但即使错配,差异报告也能定位到具体的两家公司。知道是A和B之间的问题,两家出纳拉出当天的明细单独对一下就行,范围已经从几十家缩小到两家,工作量可控。
3. 跨天未达账
代码只查当天,银行转账隔天到账的情况可能误报为差异。但往来款日清本身就是基本要求,钱出去了就应该当天记账,报差异是合理的,查出来正好督促日清习惯。
4. 费用分类漏标或标错
往来款全靠"费用分类=往来款"筛选,标错了就漏查。这种情况正好能查出日记账分类错误,属于需要纠正的错误。
5. 多账号及内转场景
有些公司银行账户比较多,出纳会按账号分开记日记账,且内转较多。这时候把收付方从公司名称换成银行账号就行。银行流水里账号、户名、金额这些信息都是现成的。代码逻辑完全不变,付方填付款账号,收方填收款账号,一样能逐笔勾稽。
6. 公司数量多、数据量大
往来款理论上发生在母子公司之间,一家公司不太可能和体系内几百家都有频繁往来。实际场景中,几十家公司、每天几百到几千条明细是常态,几秒到几十秒就能跑完。
真到了几百上千家公司、每天十几万、几十万条明细的规模,说明业务体量已经远超表格日记账能承载的上限。
亲,该上系统了。