基于 Python 的印度犯罪数据可视化分析系统技术文档
1. 项目概述
1.1 项目名称
基于 Python 的印度犯罪数据可视化分析系统
1.2 项目定位
本系统面向课程设计、数据分析展示和基础管理场景,围绕 india_crime.csv 数据集构建一个集数据清洗、数据库存储、统计分析、趋势预测、热点推荐、用户认证与后台维护于一体的 Web 可视化平台。
系统既关注“图表展示”,也强调“分析处理逻辑”:
- 在展示层提供中文对照、主题化 UI、本地图片轮播和公告卡片等能力
1.3 建设目标
本项目的核心目标包括:
- 将英文原始犯罪数据清洗后导入 MySQL,形成可复用的结构化分析底座。
- 基于 FastAPI 提供统一的页面路由和数据接口。
- 基于 Bootstrap + ECharts 构建多页面专题分析界面。
- 提供后台管理功能,使系统不仅能“看数据”,还能“管数据”和“管内容”。
2. 技术栈说明
2.1 后端技术栈
| |
|---|
| Web 框架,负责页面路由、接口路由、表单提交与依赖注入 |
| |
| |
| |
| |
| |
| |
| Starlette SessionMiddleware | |
| |
2.2 前端技术栈
| |
|---|
| |
| 柱状图、折线图、热力图、散点图、树图、饼图等可视化呈现 |
| |
| |
2.3 数据库与存储
| |
|---|
| |
| design_117_crime |
| localhost |
| root |
| 123456 |
2.4 当前核心依赖版本
项目 requirements.txt 中已声明的主要版本如下:
fastapi==0.116.1uvicorn==0.24.0sqlalchemy==2.0.23pymysql==1.4.6pandas==3.0.2jinja2==3.1.2
3. 系统总体架构
系统采用“前后端分层但不完全分离”的实现方式:
- 后端使用 FastAPI 同时提供 HTML 页面与 JSON 数据接口
- 页面中的图表由浏览器端 JS 调用
/api/* 接口获取数据后用 ECharts 渲染
整体流程如下:
- 若案件数据表为空,则从 CSV 清洗并导入 MySQL。
- 管理员在后台修改数据或内容后,系统刷新分析缓存,使前台图表同步更新。
4. 项目目录结构
code/├─ app/│ ├─ analytics.py # 分析引擎与统计、预测、推荐逻辑│ ├─ config.py # 配置项与数据库连接参数│ ├─ data_loader.py # CSV 清洗、字段派生、后台表单标准化│ ├─ database.py # 引擎、会话工厂、建库逻辑│ ├─ display.py # 中英对照显示映射│ ├─ main.py # FastAPI 入口│ ├─ models.py # ORM 数据模型│ ├─ security.py # 登录、鉴权、密码校验、会话处理│ ├─ site_data.py # 默认管理员、轮播图、公告初始化│ ├─ web.py # 模板上下文、静态资源版本号、公共页面上下文│ ├─ routers/│ │ ├─ api.py # JSON 分析接口│ │ ├─ auth.py # 登录、注册、退出│ │ ├─ admin.py # 后台管理│ │ └─ pages.py # 前台页面│ ├─ static/│ │ ├─ css/app.css # 全局主题样式│ │ ├─ js/*.js # 各分析页图表脚本│ │ └─ images/hero/ # 本地轮播图与主题图片│ └─ templates/ # Jinja2 页面模板├─ data/│ └─ india_crime.csv # 原始案件数据集├─ tests/│ ├─ test_app.py # 接口、页面、后台流程测试│ └─ browser_acceptance.py # 浏览器级验收脚本├─ run.py # 启动脚本├─ README.md└─ 项目技术文档.md
5. 系统功能模块
5.1 前台分析模块
系统当前包含 7 个核心分析页面:
每个页面都围绕一个主维度深挖,同时通过筛选、热力图、结构图或散点图实现跨维度分析。
5.2 账户模块
5.3 后台管理模块
5.4 内容展示模块
6. 数据集与业务建模
6.1 原始数据集特点
当前系统的数据源为 data/india_crime.csv。该数据集具有以下特点:
- 涵盖城市、罪种、领域、受害者信息、武器、警力与结案状态
- 原始
Date of Occurrence 字段存在日月格式混用问题
因此,系统在导入前必须进行统一清洗和字段标准化。
6.2 核心数据表设计
系统主要包含 4 张业务表。
6.2.1 crime_records
案件主数据表,是系统的分析核心。
| |
|---|
id | |
report_number | |
reported_at | |
occurrence_at | |
occurrence_reference_at | |
occurrence_date_raw | |
occurrence_time_raw | |
city | |
crime_code | |
crime_description | |
crime_domain | |
victim_age | |
age_group | |
victim_gender | |
weapon_used | |
police_deployed | |
case_closed | |
closed_at | |
closure_days | |
report_delay_hours | |
reported_year | |
reported_month | |
reported_month_label | |
reported_weekday | |
occurrence_year | |
occurrence_month | |
occurrence_month_label | |
occurrence_weekday | |
occurrence_hour | |
occurrence_hour_bucket | |
6.2.2 users
用户表,用于登录认证与角色管理。
| |
|---|
id | |
username | |
email | |
password_hash | |
role | 角色,支持 admin、analyst、viewer |
is_active | |
created_at | |
last_login_at | |
6.2.3 site_slides
首页轮播图配置表。
| |
|---|
title | |
subtitle | |
badge | |
image_path | |
cta_text | |
cta_link | |
sort_order | |
is_active | |
6.2.4 site_announcements
顶部警务通报公告表。
| |
|---|
title | |
content | |
level | 公告级别,如 info、warning、danger、success |
is_active | |
created_at | |
7. 数据清洗与标准化逻辑
数据清洗主要由 app/data_loader.py 完成。
7.1 时间字段解析
系统中定义了两类主要时间格式:
DAY_FORMAT = "%d-%m-%Y %H:%M"MONTH_FIRST_FORMAT = "%m-%d-%Y %H:%M"
其中:
Date Reported 和 Time of Occurrence 使用日优先格式解析Date of Occurrence
7.2 混合日期修正策略
parse_occurrence_reference() 的处理逻辑如下:
- 如果两种方式都解析成功,则以
occurrence_at 为锚点,选择与其时间差最小的结果。
这一步的目标是尽量降低原始日期字段格式混乱带来的分析偏差。
7.3 衍生字段计算
系统会为每条案件记录自动派生以下字段:
age_groupclosure_daysreport_delay_hoursreported_yearreported_month_labeloccurrence_month_labeloccurrence_weekdayoccurrence_houroccurrence_hour_bucket
其中时段分桶规则为:
7.4 后台新增与编辑数据的一致性处理
后台新增和编辑案件时,不直接写入原始表单值,而是调用 normalize_record_payload() 进行标准化,再写入数据库。这保证了:
- 后台手工录入的数据与 CSV 批量导入数据采用同一计算口径
- 前台统计逻辑不需要为“手工录入数据”和“原始导入数据”分别处理
8. 数据库初始化与启动流程
8.1 启动入口
系统通过 run.py 启动,核心调用为:
uvicorn.run("app.main:app", host=settings.app_host, port=settings.app_port, reload=False)
8.2 应用启动生命周期
app/main.py 使用 FastAPI 的 lifespan 机制,在应用启动时执行以下操作:
- 初始化分析引擎
analytics_engine.initialize()
8.3 自动建库逻辑
app/database.py 中的 ensure_database_exists() 会先连接 MySQL 服务级地址,再执行:
CREATE DATABASE IF NOT EXISTS design_117_crime CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci
因此系统首次运行时可自动创建数据库。
9. 分析引擎设计
分析逻辑集中在 app/analytics.py 中,由 AnalyticsEngine 统一管理。
9.1 核心职责
分析引擎主要负责:
- 从数据库加载数据到 pandas DataFrame
9.2 缓存机制
系统在启动和后台数据变更后会执行 refresh_cache(),将 crime_records 全表加载为 DataFrame 缓存在内存中。
该设计的优点是:
当管理员在后台对案件数据执行新增、编辑、删除后,会调用 _refresh_analytics_cache(),从而保证前台图表与数据库内容同步。
9.3 通用筛选机制
系统定义了 FilterParams 结构,支持如下筛选条件:
apply_filters() 会基于这些条件过滤 DataFrame,为交叉分析、预测与推荐等页面提供统一入口。
10. 可视化页面功能设计
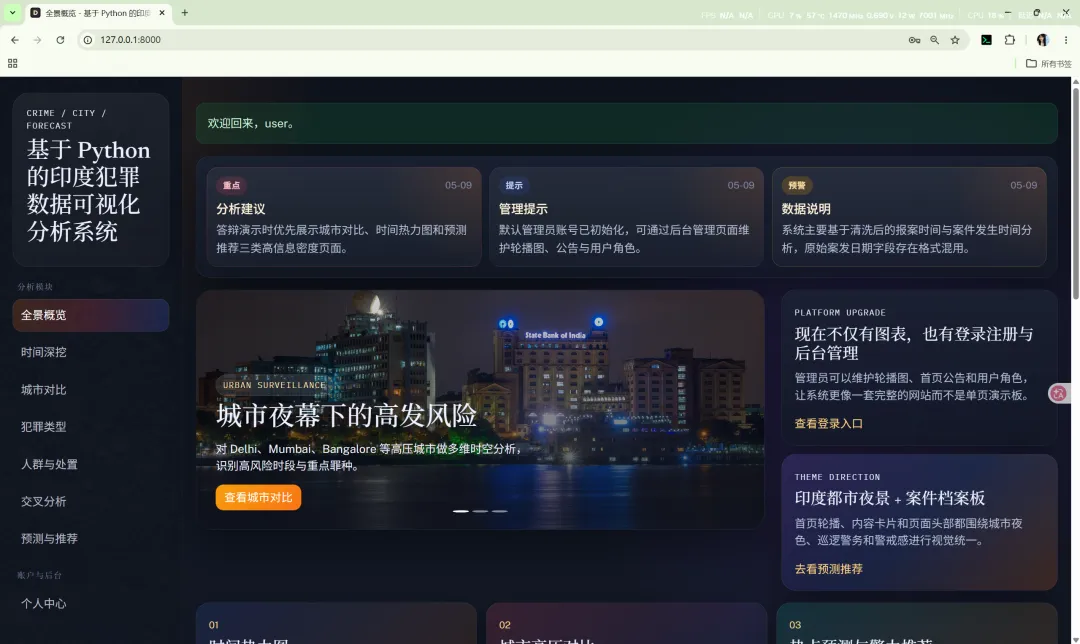
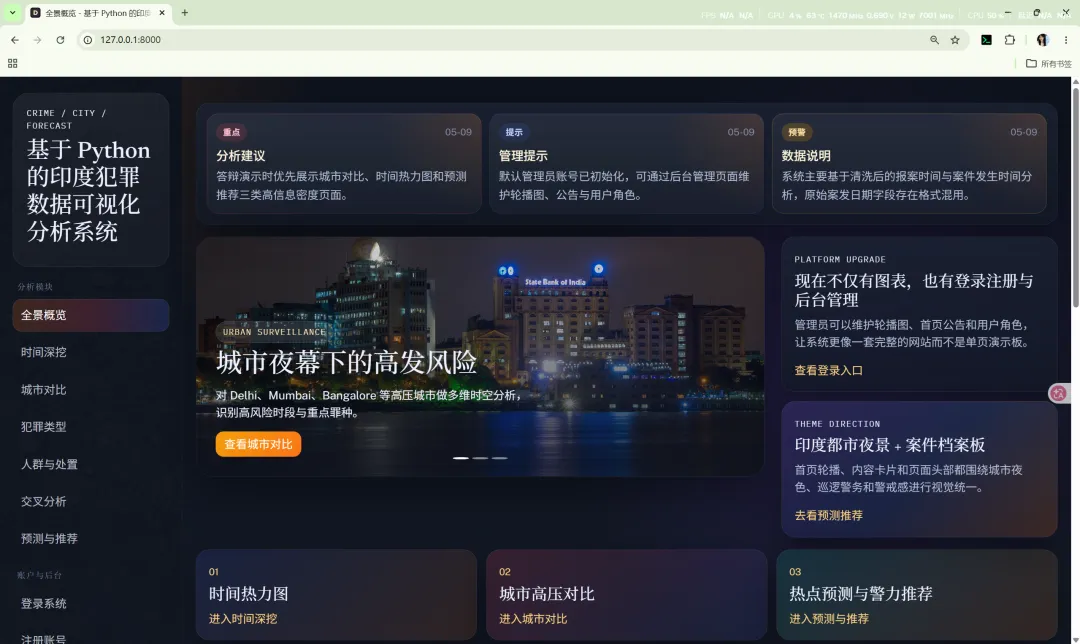
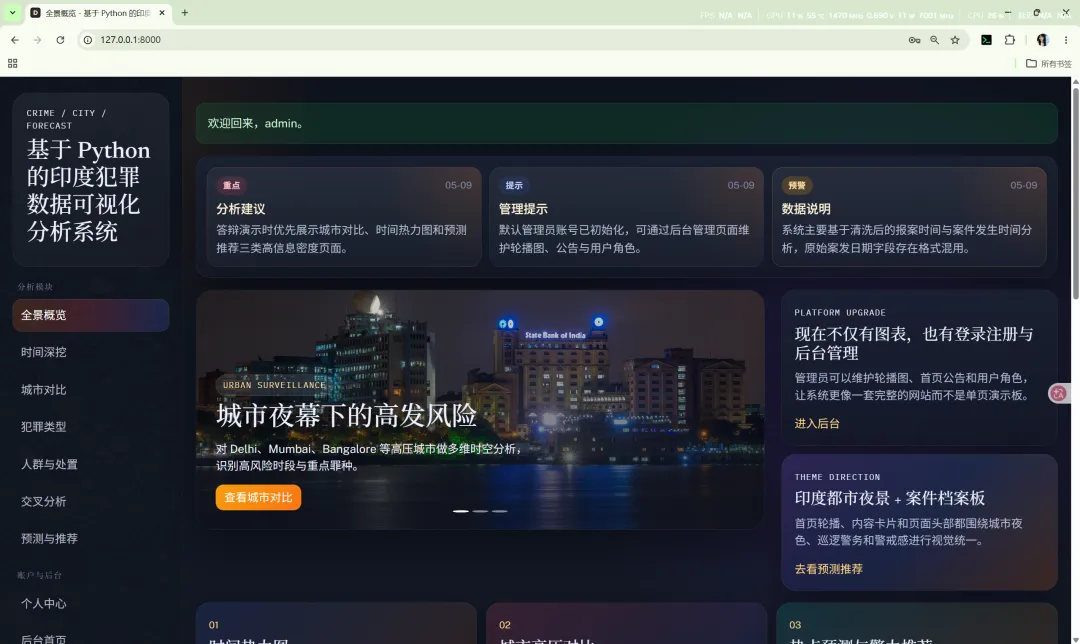
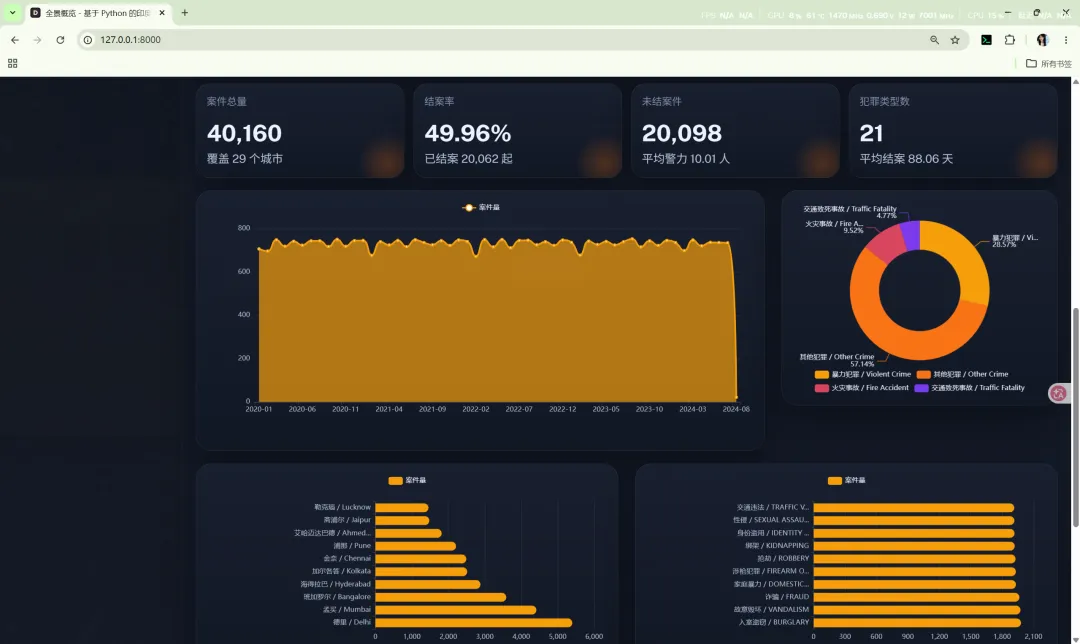
10.1 全景概览
路由:/
主要作用:
核心输出包括:
summarymonthly_trendyearly_trenddomain_distributiontop_citiestop_crimes
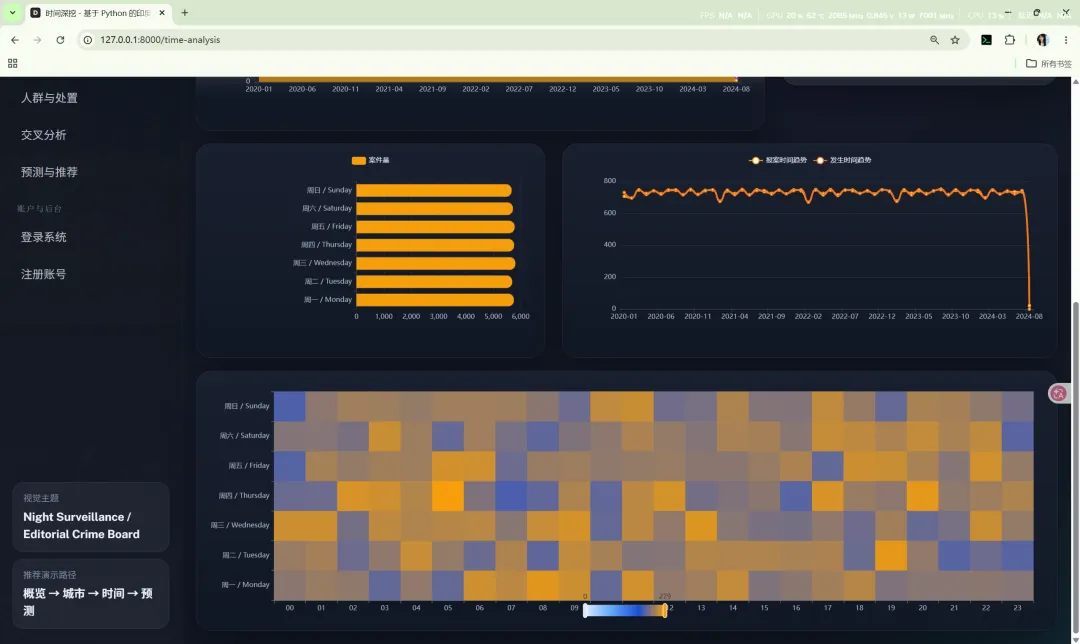
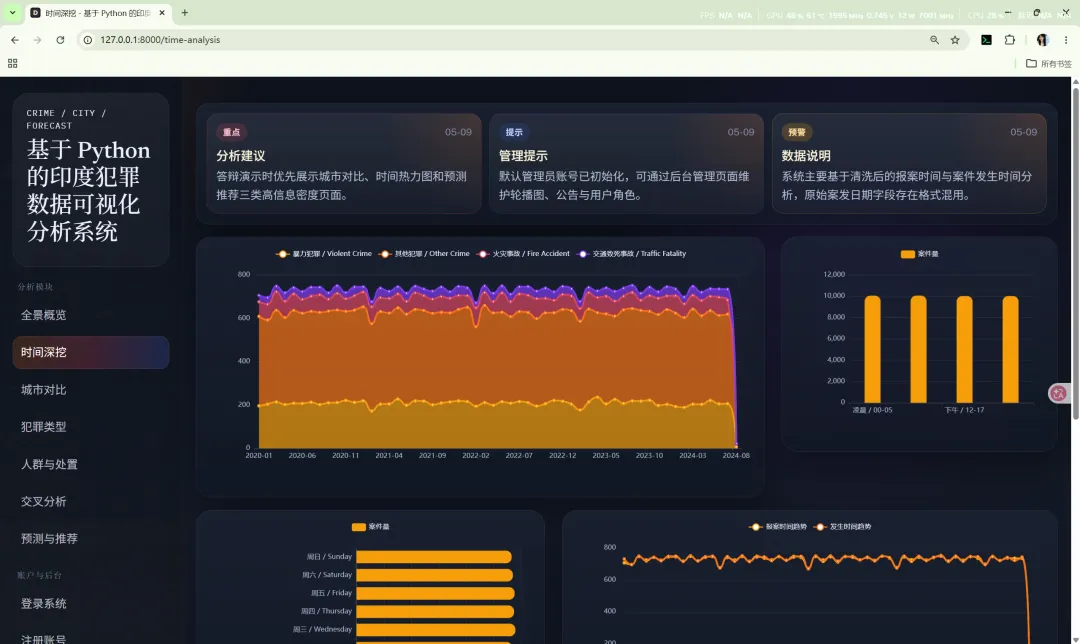
10.2 时间深挖
路由:/time-analysis
主要作用:
核心图表包括:
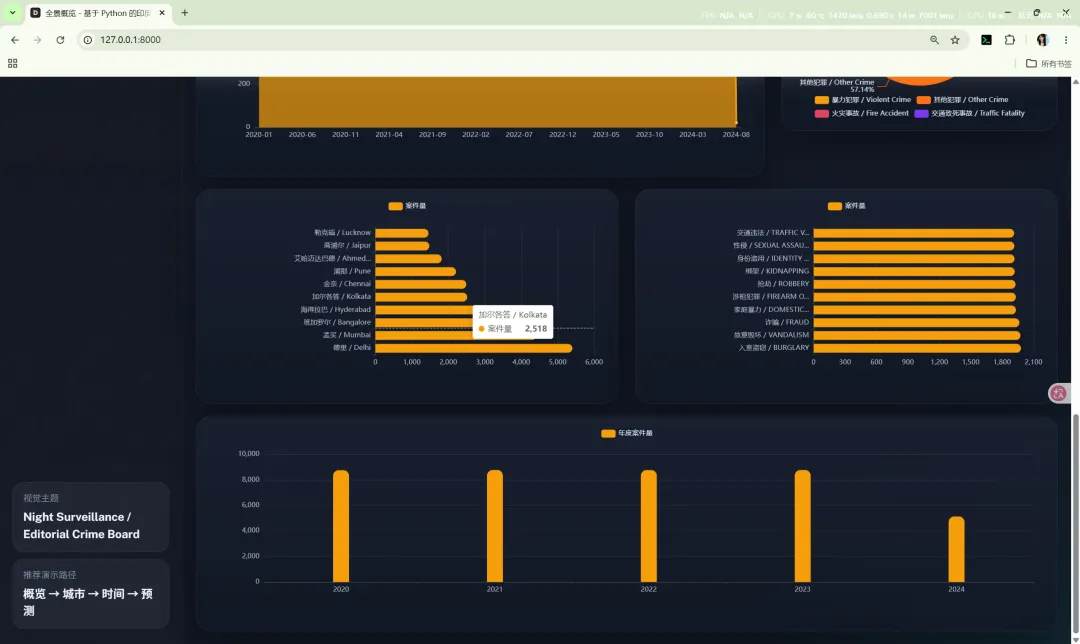
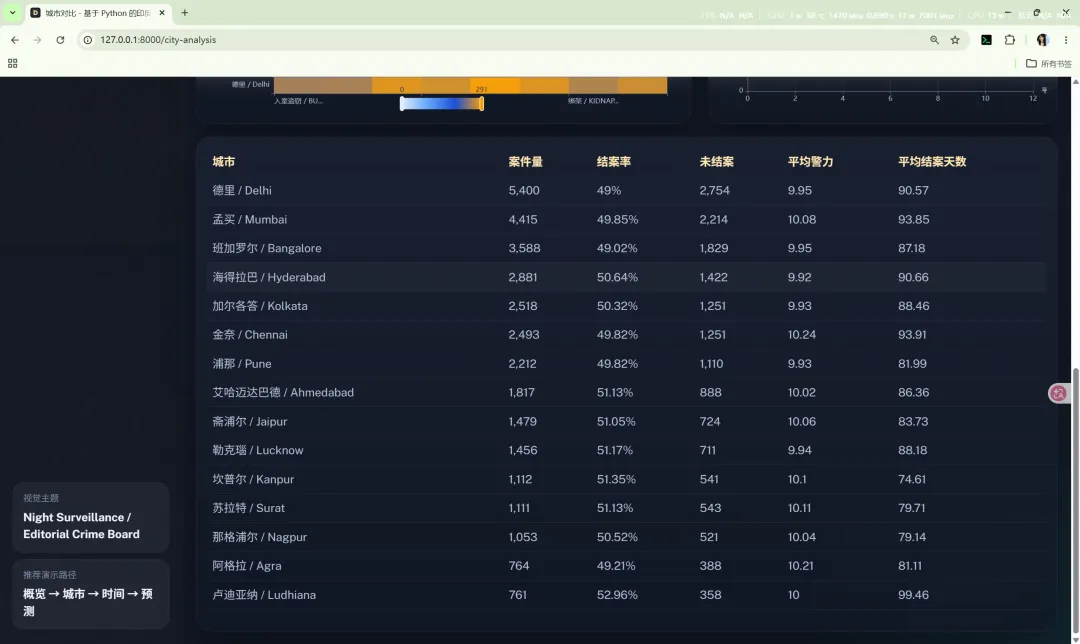
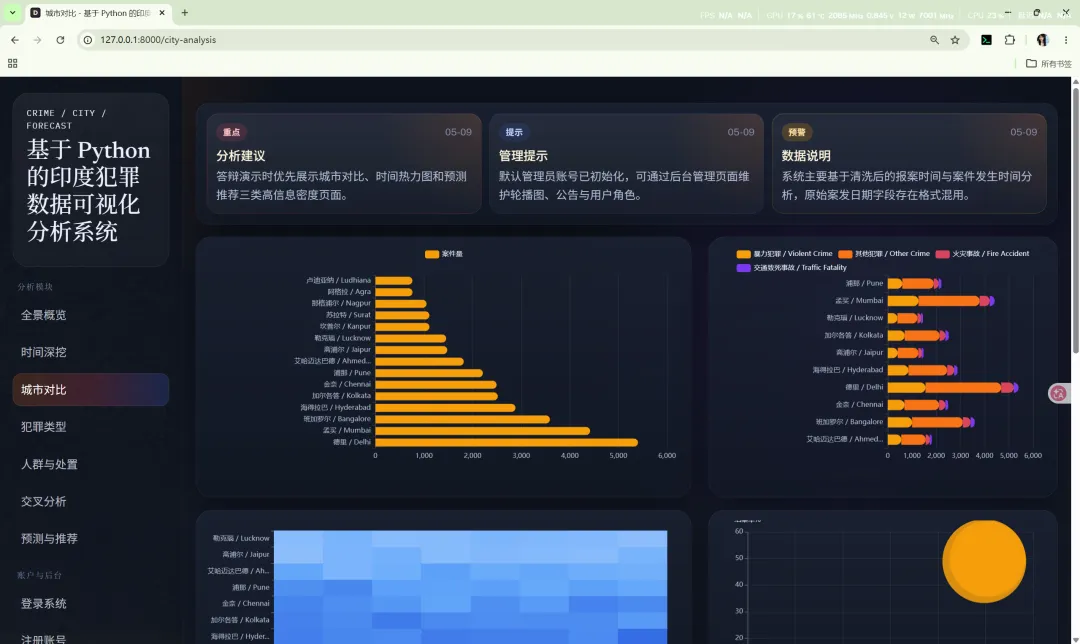
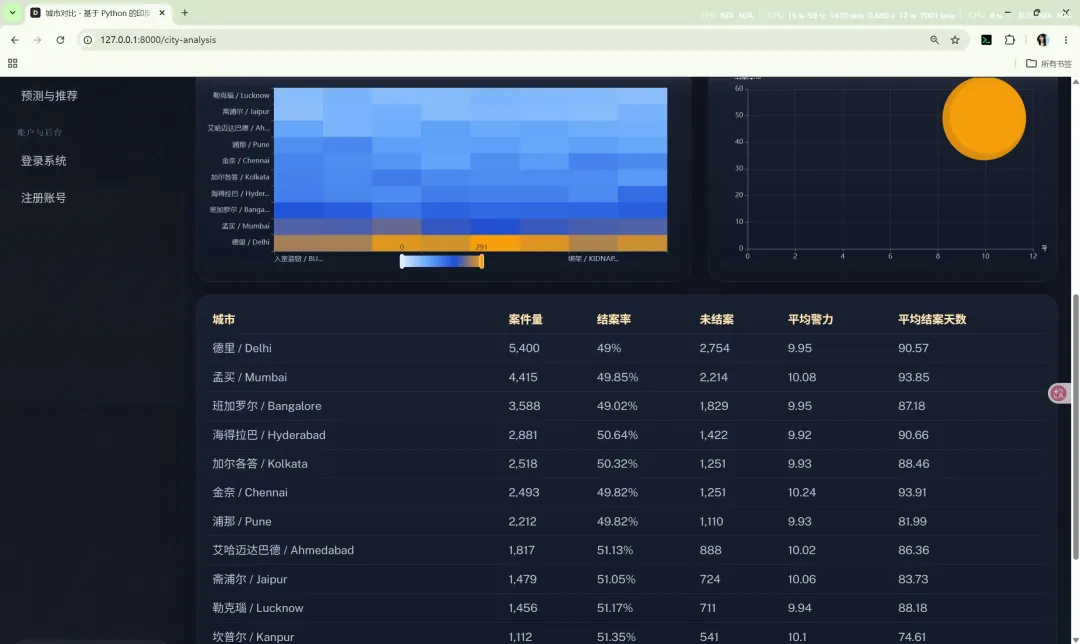
10.3 城市对比
路由:/city-analysis
主要作用:
核心图表包括:
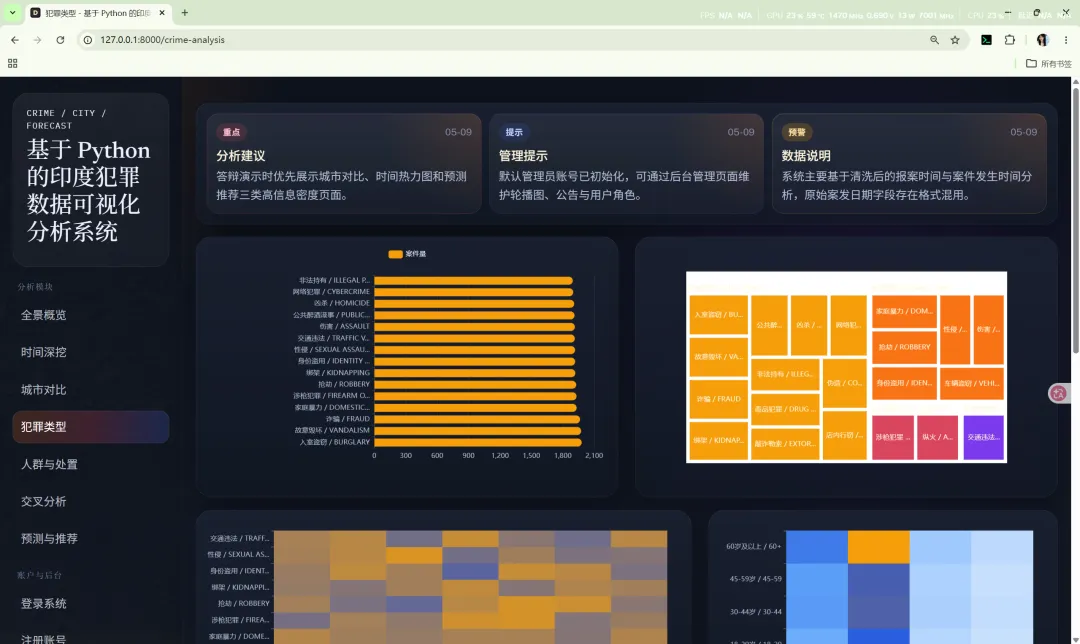
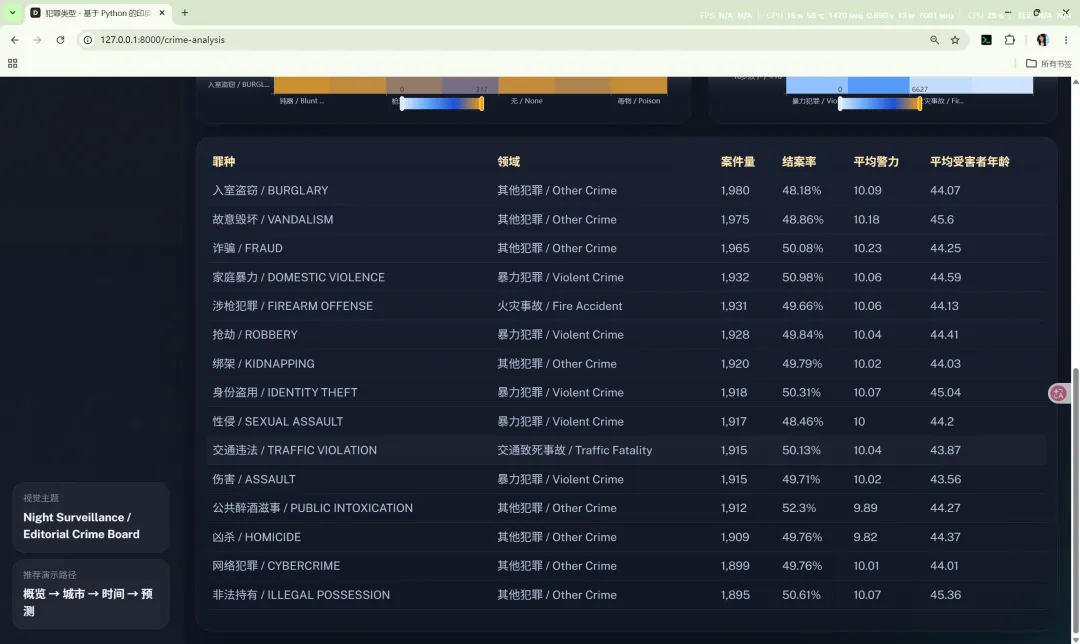
10.4 犯罪类型
路由:/crime-analysis
主要作用:
核心图表包括:
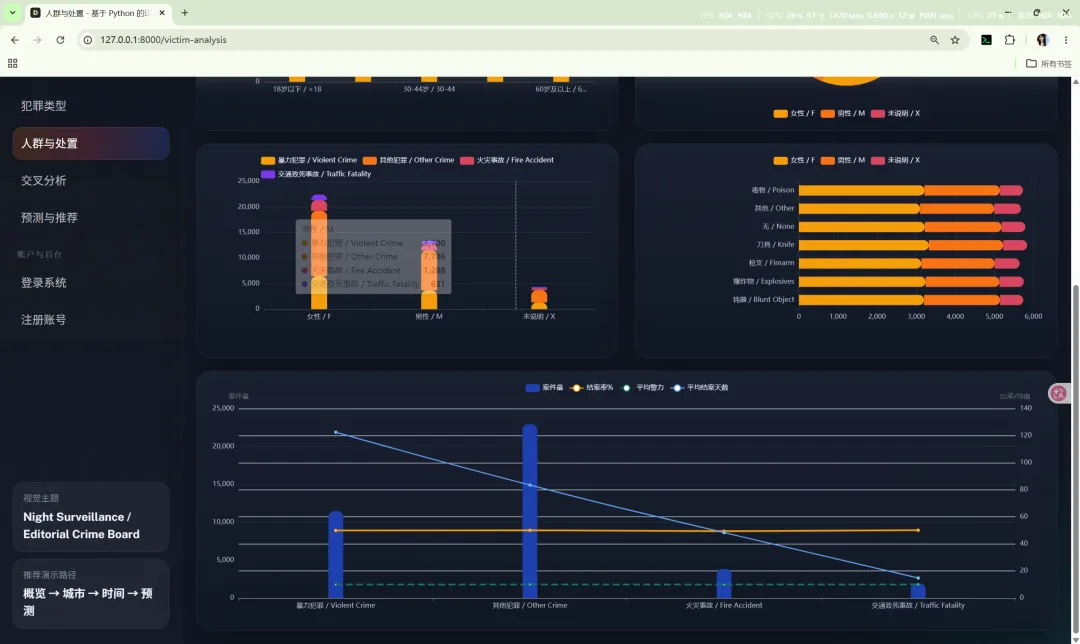
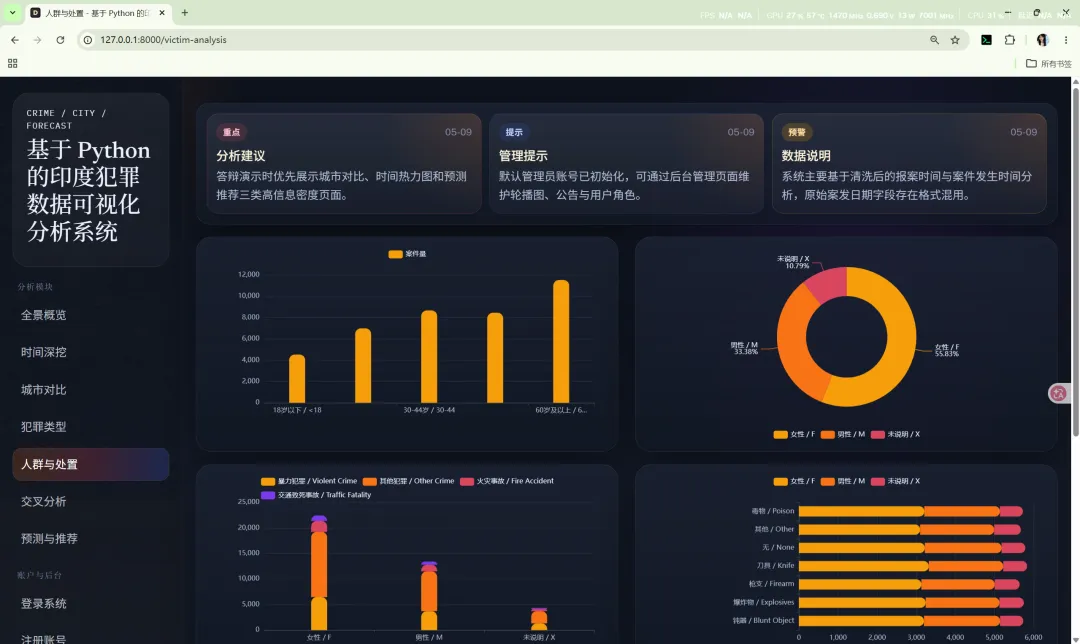
10.5 人群与处置
路由:/victim-analysis
主要作用:
核心图表包括:
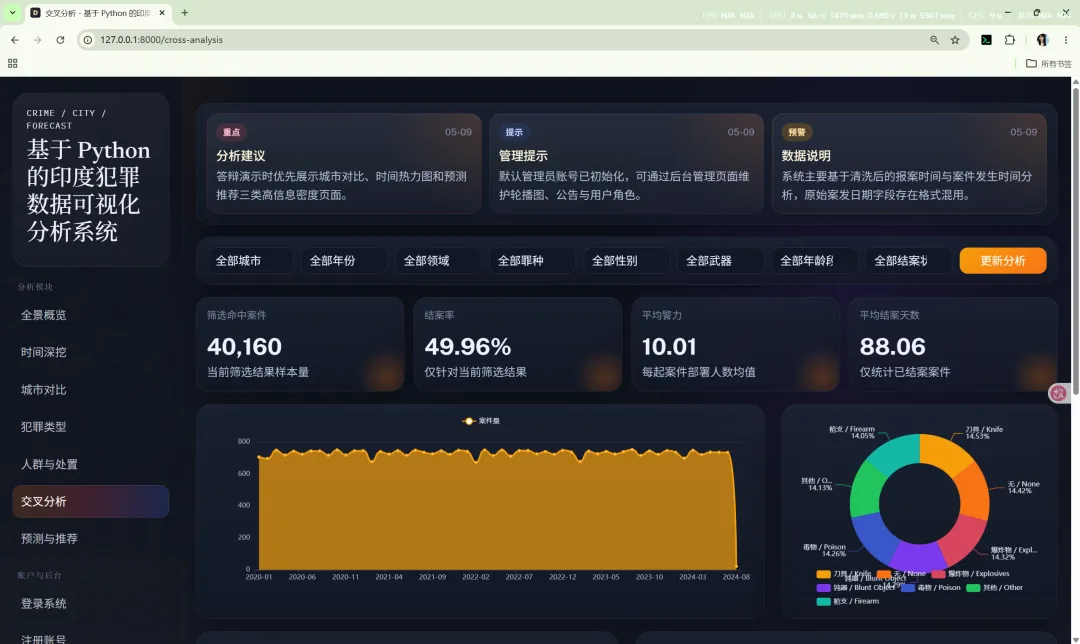
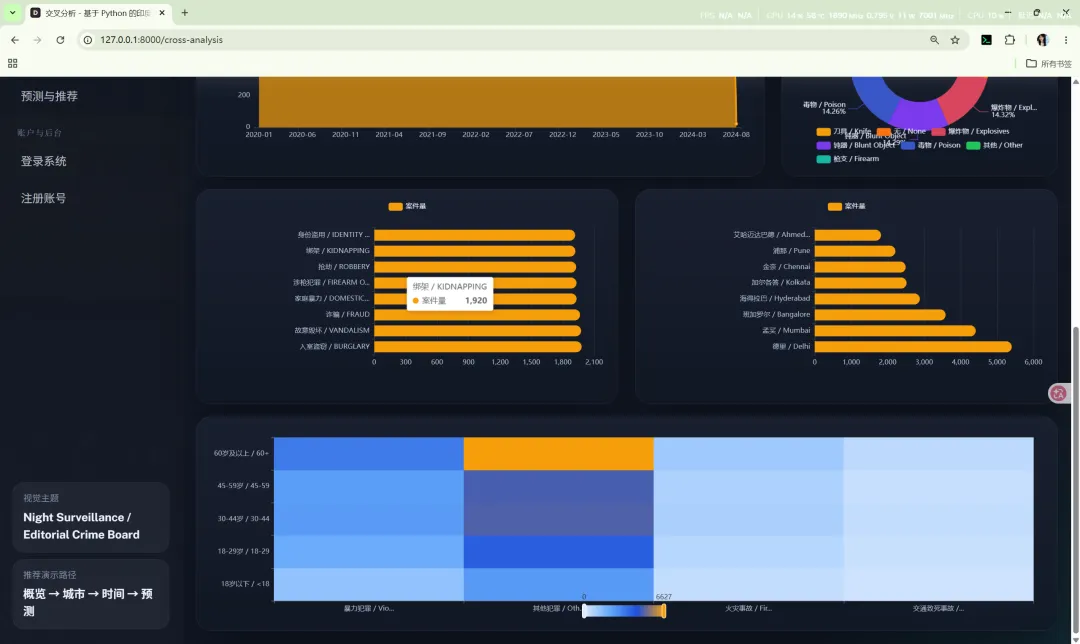
10.6 交叉分析
路由:/cross-analysis
主要作用:
支持的联动筛选维度包括:
当筛选结果为空时,系统会返回空结构和友好提示,而不是让前端报错。
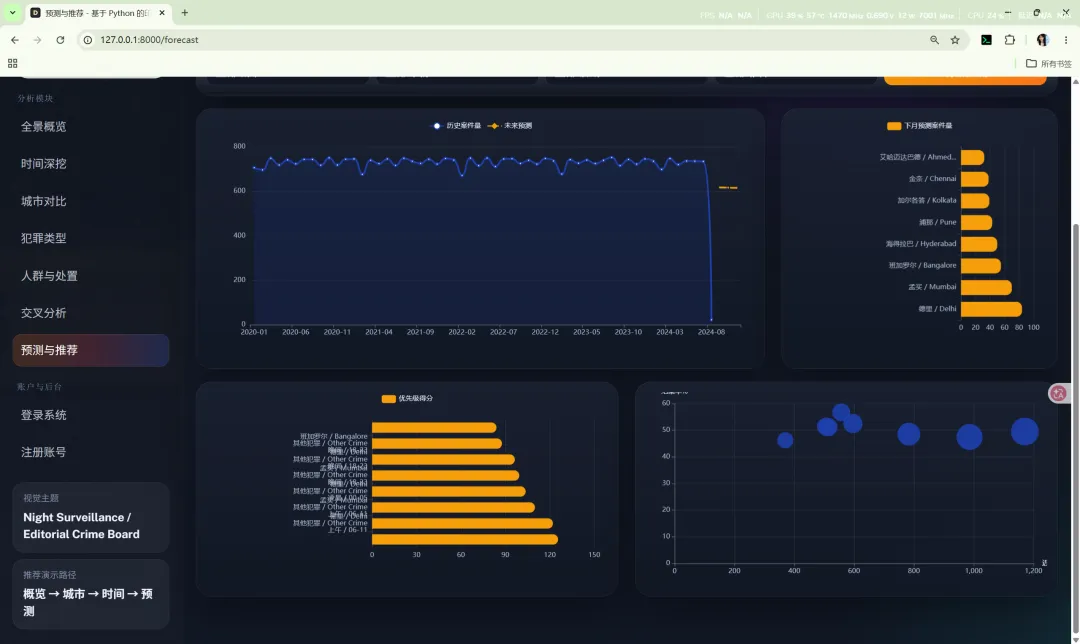
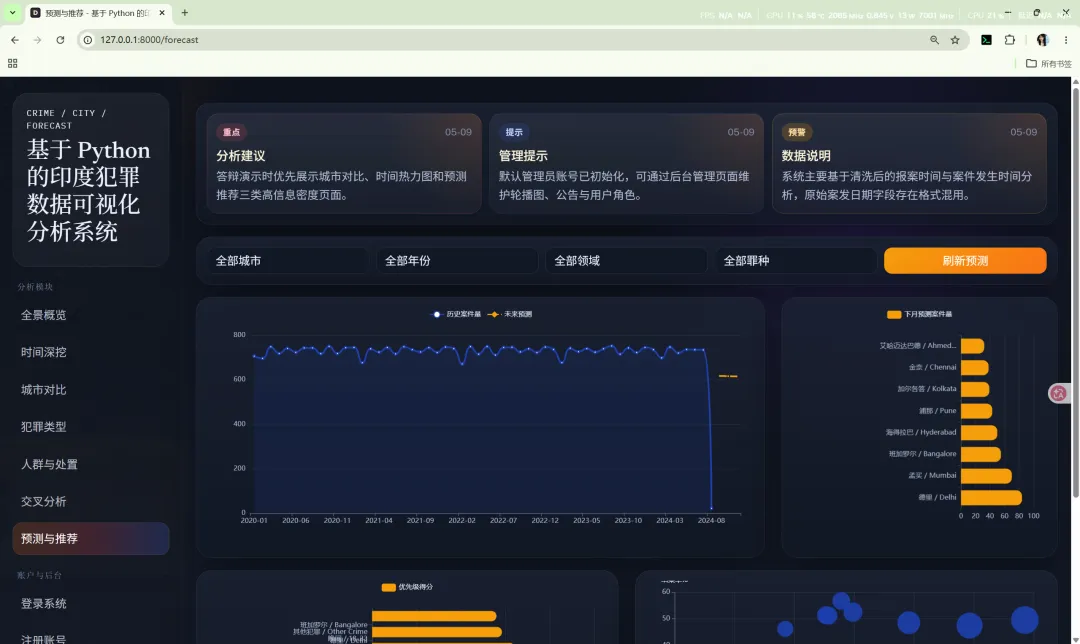
10.7 预测与推荐
路由:/forecast
主要作用:
这一页实际上由两部分数据组成:
- 推荐数据:
recommendations_payload()
11. 预测与推荐算法逻辑
11.1 月度预测逻辑
预测方法采用“线性趋势 + 近期均值”的混合方式。
具体步骤如下:
- 使用
np.polyfit() 拟合一条线性趋势线。 - 对未来值按
0.65 * 趋势值 + 0.35 * 近期均值 做加权融合。
该方法的特点是:
11.2 细分对象展望
若用户已固定某个城市,则系统按领域预测。
若用户未固定城市,则系统按城市预测。
这样可以在“全局看城市”和“城市内部看领域”之间自动切换,更适合展示层面的交互逻辑。
11.3 热点推荐逻辑
推荐逻辑基于最近 12 个月数据,按如下维度分组:
citycrime_domainoccurrence_hour_bucket
对每个组合统计:
并计算优先级分数:
priority_score = cases * 领域权重 * (1.15 - closure_rate)
其中领域权重为:
Violent Crime = 1.35Traffic Fatality = 1.2Fire Accident = 1.1Other Crime = 1.0
11.4 推荐警力计算
系统还会基于平均警力、案件量和结案率生成建议警力:
recommended_police = avg_police + min(6, cases / 120) + max(0, 0.6 - closure_rate) * 10
这不是严格业务规则,而是课程项目中的解释型启发式模型,目的是把统计结果转换成更直观的“治理建议”。
12. 中文化展示实现
由于原始数据库内容以英文为主,系统专门实现了中英对照显示层。
12.1 中文化映射模块
app/display.py 中维护了多组映射字典,包括:
12.2 应用方式
系统中的中文展示并不是修改数据库原值,而是采用“原值存储 + 显示映射”的方式:
- 接口输出和页面显示时转换为“中文 / 英文”双语标签
例如:
12.3 图表与下拉框中文化
系统不仅对图表标题和表格文本做中文化,也对筛选下拉框做了中英对照输出。
接口 filter_options() 会返回:
其中 city_options 的结构为:
[ { "value": "Delhi", "label": "德里 / Delhi" }]
前端 common.js 中的 populateSelect() 会优先渲染 label,从而保证筛选组件也具备中文对照能力。
13. 页面路由与接口设计
13.1 页面路由
| |
|---|
/ | |
/time-analysis | |
/city-analysis | |
/crime-analysis | |
/victim-analysis | |
/cross-analysis | |
/forecast | |
/profile | |
/login | |
/register | |
/admin | |
/admin/users | |
/admin/data | |
/admin/content | |
13.2 JSON 数据接口
| |
|---|
/api/health | |
/api/meta/filters | |
/api/overview | |
/api/time-analysis | |
/api/city-analysis | |
/api/crime-analysis | |
/api/victim-analysis | |
/api/cross-analysis | |
/api/forecast | |
/api/recommendations | |
所有接口统一返回格式:
{ "status": "ok", "data": {}}
这种统一格式可以降低前后端对接成本,避免图表因字段封装不一致而渲染失败。
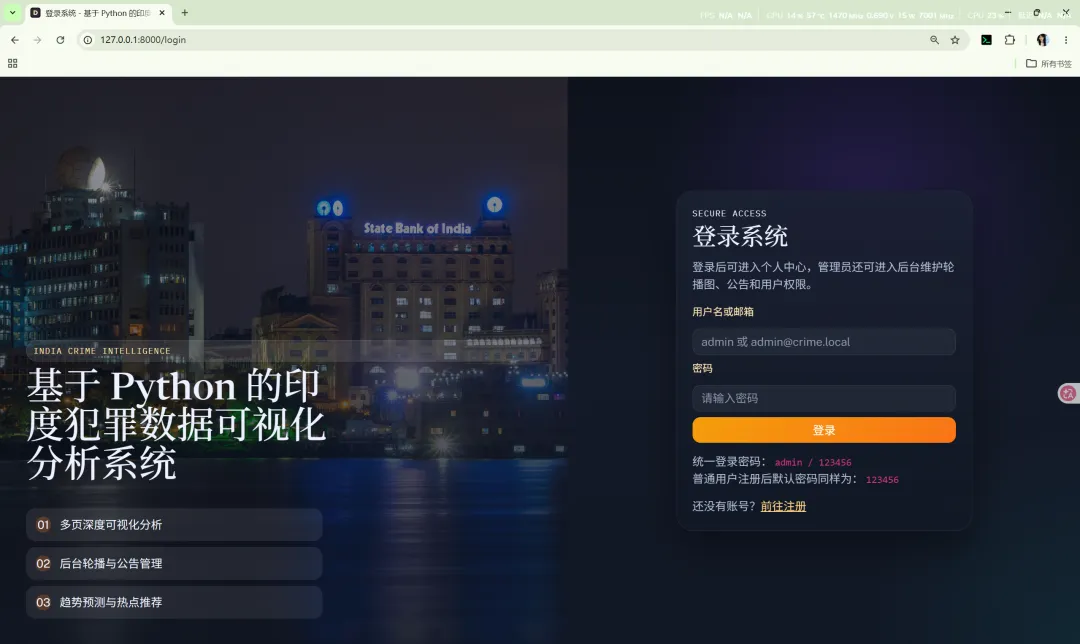
14. 登录认证与权限控制
14.1 会话认证
系统使用 SessionMiddleware 维护登录态,登录成功后在 Session 中写入:
14.2 密码安全
密码通过 passlib 的 pbkdf2_sha256 进行哈希,不以明文形式存储在数据库中。
14.3 当前演示版本的账号策略
为了便于课程演示和后台管理,当前版本约定:
并且系统启动时会执行默认数据初始化逻辑,将现有用户密码统一重置为 123456。这一策略适合课程项目演示,但正式生产环境不建议这样处理。
14.4 权限控制规则
15. 后台管理设计
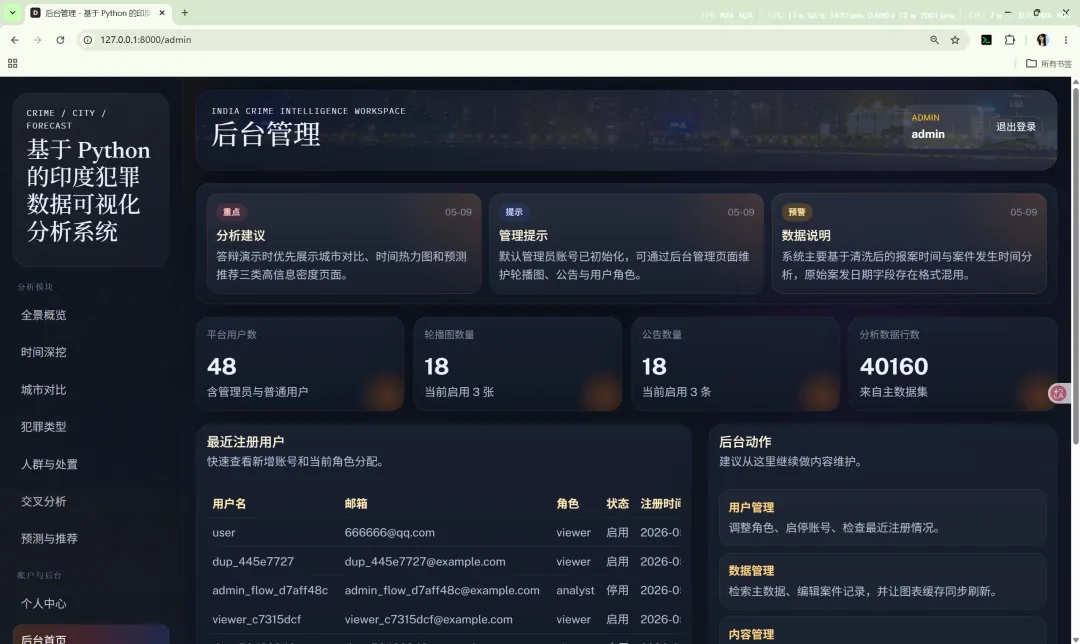
15.1 后台首页
后台首页主要展示:
它的作用是为管理员提供全局管理概览。
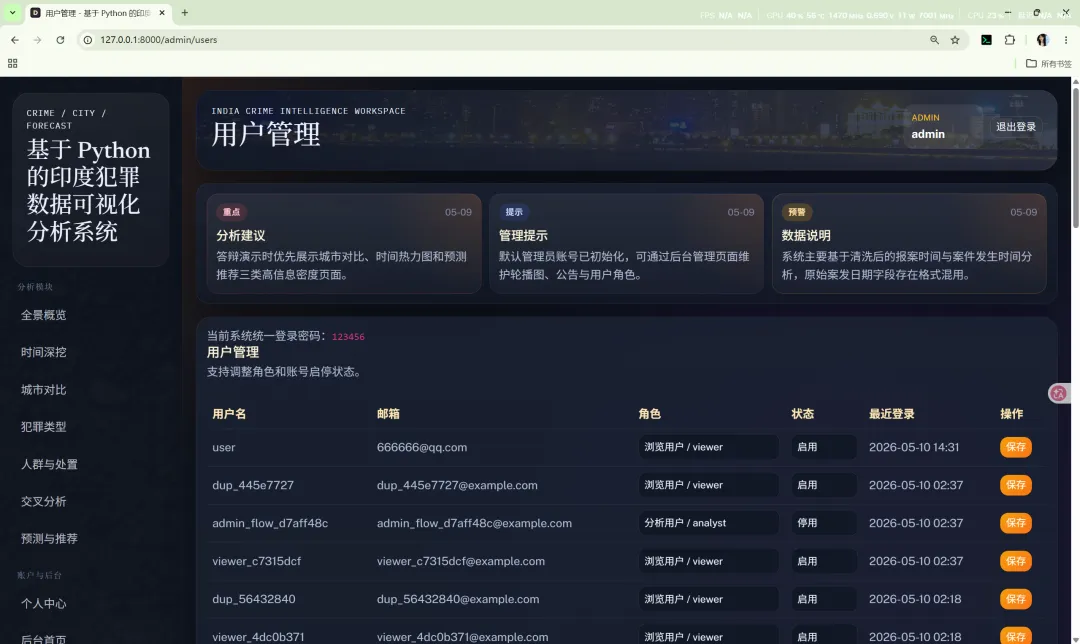
15.2 用户管理
用户管理支持:
角色包括:
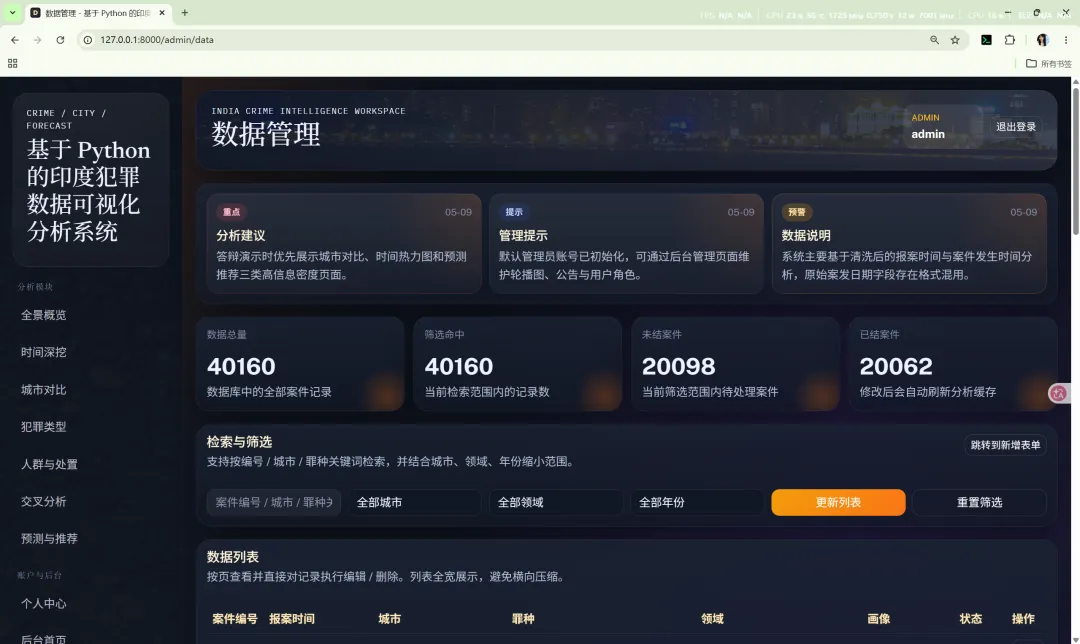
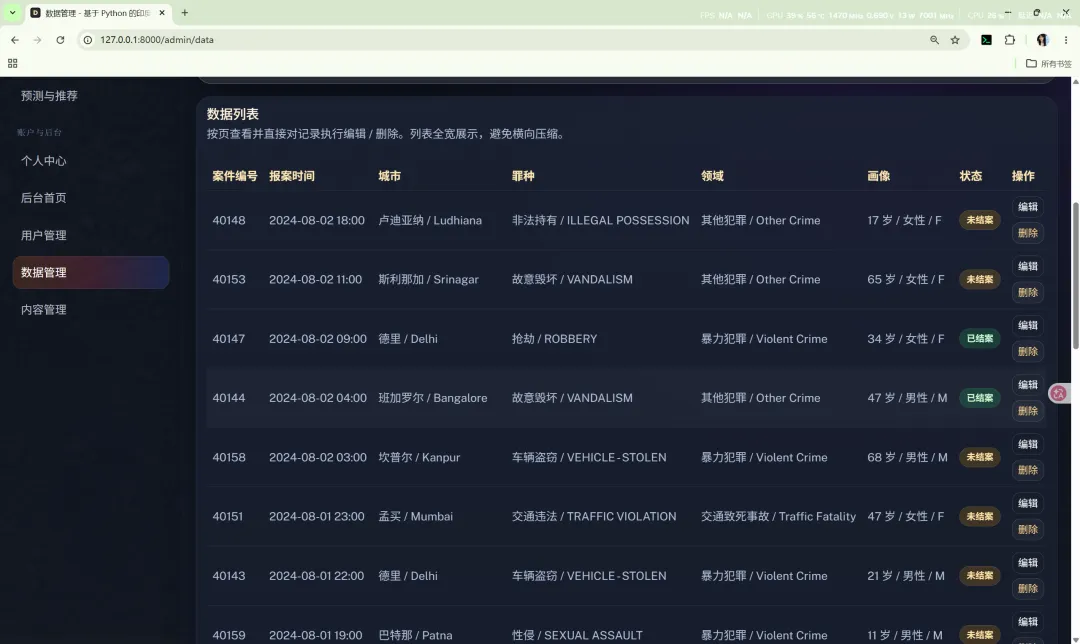
15.3 数据管理
数据管理是系统当前的重要增强模块,支持对案件主数据进行维护。
功能包括:
为了避免数据表与编辑表单并排导致横向滚动,当前实现采用“列表在上、表单在下”的布局。这一设计比侧边栏并列式更适合高列数数据表展示。
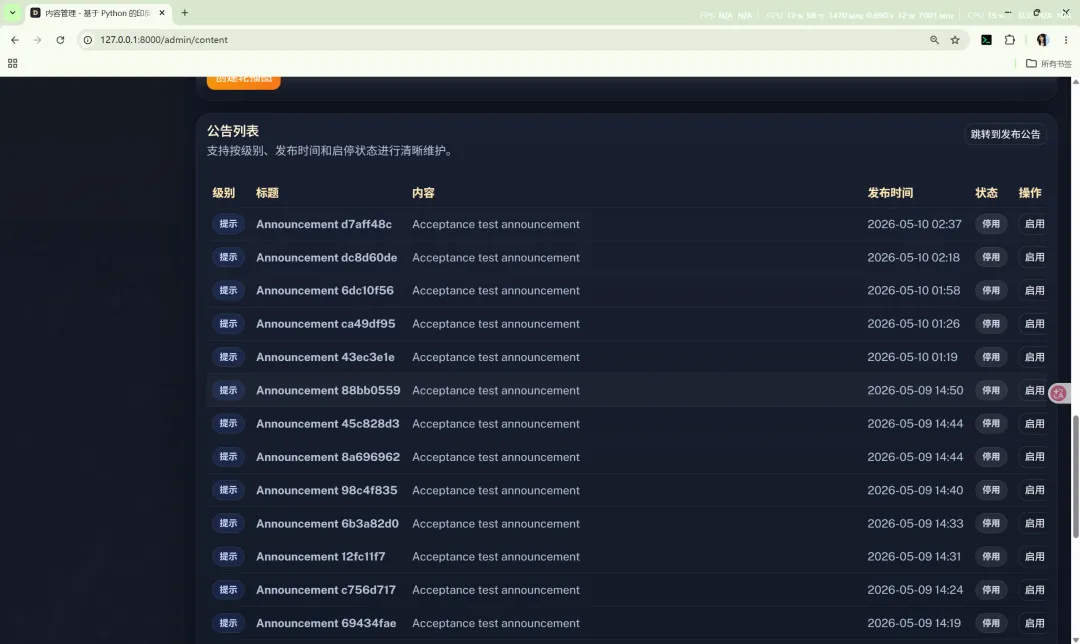
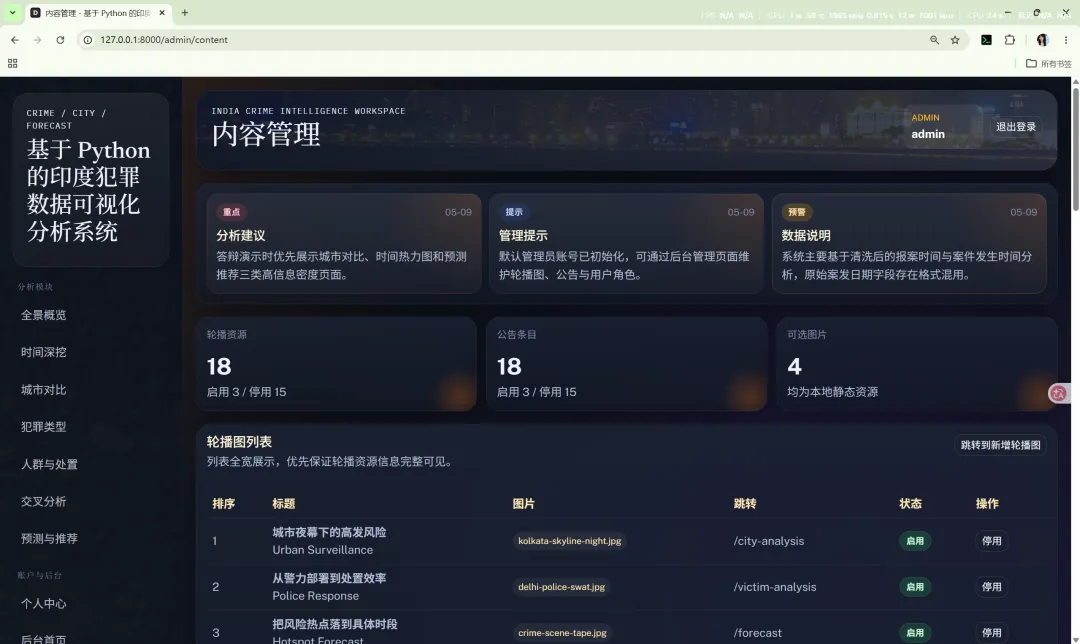
15.4 内容管理
内容管理负责维护首页展示内容,包括:
同样采用“列表在上、表单在下”的结构,使列表宽度完整保留,便于查看。
15.5 本地图片资源管理
首页轮播图和主题图片采用本地静态资源方式展示,图片目录为:
后台在创建轮播图时,图片路径直接来自本地可选资源,从而保证展示稳定,不依赖外链。
16. 前端主题与交互设计
16.1 主题风格
系统采用“印度城市夜景 + 犯罪情报板”的视觉方向,主要表现为:
16.2 顶部警务通报
原先的横向滚动设计已改为卡片分布式布局,主要原因包括:
16.3 下拉菜单可读性优化
针对深色主题下推荐筛选框“白底白字不可读”的问题,系统已统一对 .form-select 与 option 设置黑底白字样式,并启用深色 color-scheme,保证筛选组件在主题下可读。
16.4 静态资源版本号机制
为避免浏览器缓存导致样式更新不生效,系统在 web.py 中根据 app.css 的修改时间生成 asset_version,并在模板中以 ?v=... 的方式引用:
这样每次样式更新后浏览器都会重新拉取最新资源。
17. 测试与验收
17.1 自动化测试
项目当前包含以下测试文件:
tests/test_app.pytests/browser_acceptance.py
17.2 已覆盖测试内容
tests/test_app.py 已覆盖以下内容:
17.3 浏览器级验收
tests/browser_acceptance.py 会:
- 使用本机 Chrome Headless 打开页面
它主要用于验证:
17.4 当前测试意义
这套测试覆盖了:
对于课程设计项目而言,已经具备较完整的功能验收价值。
18. 运行方式与环境要求
18.1 基本环境
18.2 默认配置
系统配置位于 app/config.py,默认值如下:
18.3 启动命令
启动后默认访问:
18.4 可配置环境变量
系统支持通过环境变量覆盖默认配置,例如:
CRIME_APP_HOSTCRIME_APP_PORTCRIME_DB_HOSTCRIME_DB_PORTCRIME_DB_NAMECRIME_DB_USERCRIME_DB_PASSWORDCRIME_SECRET_KEY
19. 兼容性与实现说明
19.1 Python 3.8 兼容
为了适配 Python 3.8,项目中已采用如下策略:
- 使用
Optional[T]、List[T] 等写法,避免 T | None - 模板响应采用兼容旧版 Starlette 的
TemplateResponse(name, context) 调用方式
这使得系统能在较常见的课程实验环境中稳定运行。
19.2 数据一致性策略
系统采用“数据库存原始英文值,接口输出中英对照值”的方式,这样既能保持分析逻辑稳定,也能满足中文展示需求。
19.3 非生产化约定
当前项目以教学、展示和课程设计为目标,因此存在以下非生产化约定:
这些设计是为了优先保证演示效果、开发效率和功能完整性。
20. 后续可扩展方向
如果继续完善,本系统可以扩展为以下方向:
- 将预测算法升级为 ARIMA、Prophet 或机器学习模型
21. 文档结论
本系统已经从单一数据展示页面,演进为一个较完整的课程设计型数据可视化平台,具备以下特征:
- 有稳定的数据底座:CSV 清洗、MySQL 入库、结构化字段派生
- 有主题化的前端展示:中文对照、深色情报风格、本地轮播与公告卡片
从教学和课程答辩角度看,该系统已经不仅是“图表展示项目”,而是一个包含数据治理、可视化分析、预测研判和后台运营能力的完整 Web 应用。

