Linux 内核三种 I/O Error 详解:从一次 ceph节点瞬间掉盘说起
- 2026-07-02 20:21:05
一、引言
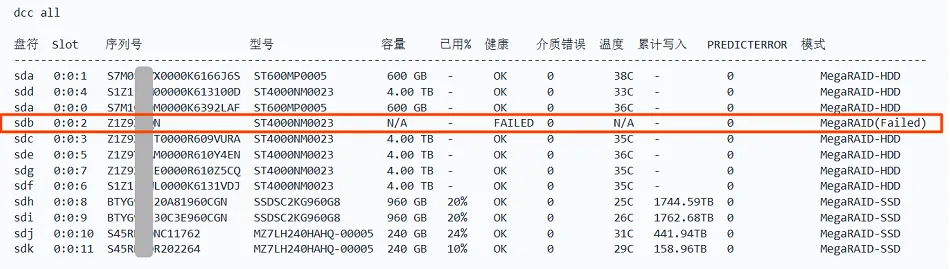
2025 年 5 月 15 日 14:36:06,Ceph 存储集群节点 rg1-ceph028 的内核日志突然刷出一串 I/O error。9 条写请求在同一秒内全部失败,设备 sdb 从系统中彻底消失。
这类日志在 Linux 服务器运维中并不少见,但仔细观察会发现,内核报出的 I/O error 实际上有三种不同的写法,分别对应 I/O 栈的不同层次:
blk_update_request: I/O error,dev sdb,sector 870341128 ←块设备层Buffer I/O error on dev sdb, logical block 108792641 ← 页缓存层EXT4-fs error: metadata I/O error ← 文件系统层
它们看起来都在说"I/O 出错了",但背后的含义、严重程度和故障根源完全不同。本文从这次真实的掉盘事件出发,逐一拆解这三种错误。
👍 文末附一键检索硬盘故障日志命令和硬盘检测工具
二、案例:Ceph 节点ceph028 瞬间掉盘
2.1 环境背景
项目 | 信息 |
主机 | ceph028 |
角色 | Ceph 存储集群节点 |
故障设备 |
|
磁盘配置 | 单盘 RAID 0 |
为什么 Ceph 节点用单盘 RAID 0? 很多服务器的 RAID 控制器不提供 JBOD / 直通模式,或出于管理规范要求通过控制器统一管理磁盘。因此在 Ceph 场景下,常见做法是将每块物理盘配置为独立的单盘 RAID 0 虚拟磁盘,让操作系统看到独立的块设备,同时由控制器统一管理。代价是:物理盘一旦掉盘,对应的虚拟磁盘直接离线,操作系统看到的就是整块设备消失。
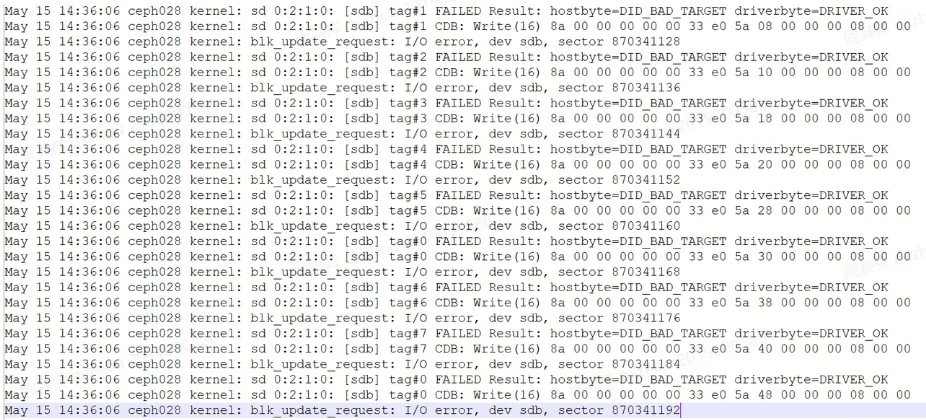
2.2 日志原文
2.3 问题分析
SCSI 返回码:设备彻底消失
每条日志都包含相同的 SCSI 状态:
hostbyte=DID_BAD_TARGET 设备完全不可达driverbyte=DRIVER_OK 驱动侧没有问题,不是驱动 bug
DID_BAD_TARGET 意味着 SCSI 主机适配器(HBA)在物理层面根本找不到这台设备。不是某个扇区坏了,而是整块盘对操作系统来说消失了。
SCSI 地址 0:2:1:0 指向 RAID 虚拟磁盘
0:2:1:0│ │ │ └─ LUN 1│ │ └─── Target ID 2│ └───── Channel 0(RAID 控制器虚拟通道)└─────── Host adapter 0
Channel 0 在 RAID 控制器上代表虚拟磁盘(Virtual Drive)。单盘 RAID 0 的架构下,物理盘掉盘等同于整个虚拟磁盘离线——没有任何冗余可以兜底。
操作特征:同一秒内连续写失败
9 条错误全部是 Write(16):设备掉线时内核正在执行写操作
扇区范围
870341128~870341192,步长 8 个扇区(即 4KB),属于连续顺序写入磁盘偏移量约
870341128 × 512 ≈ 415 GB,属于 BlueStore 数据写入区域所有错误集中在
14:36:06同一秒内,没有任何渐进式退化的过程
这些特征指向同一个结论:物理硬盘在某一瞬间从总线上消失,不是缓慢退化,而是瞬时掉盘。
2.4 故障时间线
14:36:05.xxx sdb 正常运行,有写请求正在传输14:36:06.xxx 物理硬盘瞬间掉盘,RAID 控制器丢失与物理盘的通信14:36:06.xxx 控制器将虚拟磁盘标记为离线14:36:06.xxx SCSI 驱动检测到设备不可达14:36:06.xxx 内核连续打印 9 条 blk_update_request I/O error14:36:06+ 对应的 OSD 进程感知到 I/O 失败
2.5 对 Ceph 的影响
sdb 对应一个 Ceph OSD。单盘 RAID 0 意味着本地没有冗余,盘一掉 OSD 直接失效。但 Ceph 集群本身没有受到影响:
Ceph 采用多副本(或 EC 纠删码)机制,每个 PG 的数据分布在多个 OSD / 多个节点上
单个 OSD 故障不导致数据丢失,其他副本仍然可用
Ceph 检测到 OSD 离线后自动启动 recovery / backfill,从其他副本重建数据
集群整体保持可用,客户端 I/O 不中断,仅该节点上的部分 PG 短暂降级
这正是 Ceph 分布式架构的设计初衷——用软件层面的多副本来容忍单块盘的硬件故障。一块盘瞬间掉线,在单机场景下是灾难性事件,在 Ceph 集群中只是一个需要自动愈合的日常故障。
三、原理:Linux I/O 栈的五层结构
案例中的日志只有块设备层的 blk_update_request,但在更复杂的故障场景中,错误会沿着 I/O 栈向上传播,依次出现三种不同的报错。要理解它们,需要先了解 Linux 处理一次磁盘读写的完整路径:

每一次读写请求从上往下传递,每一层都可能独立报错。报错的位置越低,通常意味着问题越接近硬件,影响范围也越大。
四、三种 I/O Error 逐一拆解
4.1 块设备层:blk_update_request: I/O error
blk_update_request: I/O error, dev sdb, sector 870341128sd 0:2:1:0: [sdb] tag#1 FAILED Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OKsd 0:2:1:0: [sdb] tag#1 CDB: Write(16) 8a 00 00 00 00 00 33 e0 5a 08 00 00 00 08 00 00
来源:Linux 块设备层(源码位于 block/blk-core.c)。一个读写请求提交给设备后设备返回了失败,块设备层发出报告。
关键字段:
dev sdb:出错的设备名sector 870341128:失败的物理扇区号Write(16):操作类型(SCSI 16 字节 CDB 格式的写命令)hostbyte:SCSI 子系统的返回状态码,这是整条日志中最关键的信息
hostbyte 决定了问题的性质:
hostbyte 值 | 含义 | 严重程度 |
| 主机侧传输正常,错误来自设备本身(如扇区损坏) | 视情况而定 |
| 完全无法到达目标设备 | 最严重 |
| 无法建立连接 | 最严重 |
| 传输过程中发生错误 | 中等 |
| 可重试的临时错误 | 较轻 |
打个比方:blk_update_request 就像快递分拣中心发出的通知——"这个包裹发不出去了"。而 hostbyte 告诉你原因:是收件地址不存在(DID_BAD_TARGET),还是暂时联系不上(DID_SOFT_ERROR)。
4.2 页缓存层:Buffer I/O error
Buffer I/O error on dev sdb, logical block 108792641, lost async page write
来源:Linux 的页缓存 / Buffer Cache 层(源码位于 fs/buffer.c)。当块设备层返回错误后,错误沿着栈向上传递,页缓存层发现"我缓存的这个页底层告诉我读写失败了",于是发出报告。
关键字段:
logical block:文件系统的逻辑块号(注意:和上面的物理扇区号不是同一个概念,中间隔了一层映射)lost async page write:异步写入的数据在刷盘时丢失了async page read:读取失败
本质:Buffer I/O error 是块设备层错误的上层回声。块设备层是第一个发现"包裹丢了"的分拣中心,页缓存层是发现"我存的这批货怎么还没发出去"的仓库管理员。问题的根源不在仓库,但仓库会告诉你受影响的是哪些货物。
4.3 文件系统层:metadata I/O error
EXT4-fs error (device sdb): ext4_ext_find_extent:900: inode #268435512:comm ceph-osd: metadata I/O error
或在 XFS 上:
XFS (sdb): xfs_do_force_shutdown(0x1) called from line 1254 of file fs/xfs/xfs_buf.c
来源:具体文件系统的实现代码(ext4、XFS、btrfs 等)。文件系统尝试读写自身的元数据结构(超级块、inode 表、extent 树、日志等)时遇到 I/O 失败。
为什么元数据特别重要:普通数据块坏了,丢的是一个文件的内容。元数据坏了,文件系统可能无法正确追踪哪些文件存在、存储在哪里、哪些空间可用。在 ext4 上,元数据错误通常触发 remount read-only;在 XFS 上,通常触发 shutdown。两种情况都意味着文件系统上的业务立即中断。
打个比方:普通数据是一封封信,元数据是邮局的分拣目录。信丢了只丢一封信,目录坏了整邮局都瘫痪。
五、三种错误的关系:因果链
这三种错误很少孤立出现。硬件故障发生后,错误会沿着 I/O 栈从底层向顶层逐层传播,形成一条因果链:
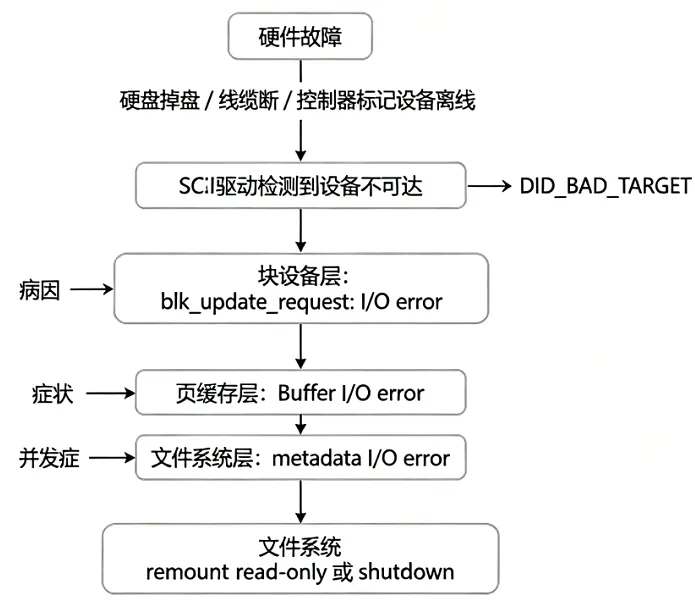
用一个比喻:
硬盘掉盘相当于仓库大楼倒塌了。
块设备层的
blk_update_request是门卫的报告:"我联系不上仓库了。" —— 这是病因。页缓存层的
Buffer I/O error是仓库管理员的报告:"存放在那个仓库的货物找不到了。" —— 这是症状。文件系统层的
metadata I/O error是管理层的报告:"公司的资产账本在那个仓库里,现在账本读不出来,整个资产管理系统要暂停运作。" —— 这是并发症。
三个层面都在说同一件事——仓库出问题了——但各自关注的维度不同。
回到 ceph028 的案例:这次事件中日志只出现了块设备层的 blk_update_request,没有后续的 Buffer I/O error 和 metadata I/O error。这可能是因为 RAID 控制器快速将虚拟磁盘标记为离线,错误直接在最底层被截断了,后续的上层报错可能出现在更晚的日志中,也可能因为 OSD 进程自身的 I/O 错误处理机制而没有继续传播到文件系统层。
六、到底哪个更严重?
"层次越低越严重"——这个结论大多数时候是对的,但不绝对。严重程度取决于故障的根源。
场景一:设备完全掉线(本案情况)
hostbyte=DID_BAD_TARGET
设备从系统中完全消失,块设备层、页缓存层、文件系统层的报错都是连锁反应。全盘数据不可访问,软件层面无能为力。严重程度:★★★★★
场景二:设备在,但元数据区域损坏
hostbyte=DID_OK→ metadata I/O error→ 文件系统损坏
设备还活着,但元数据区域的扇区出了问题。可能通过 fsck / xfs_repair 恢复,也可能无法修复。严重程度:★★★★
场景三:设备在,普通数据扇区损坏
hostbyte=DID_OK→ Buffer I/O error→ 但元数据完好,文件系统正常
损坏的是某个具体文件的内容,文件系统本身不受影响。严重程度:★★★
场景四:偶发传输错误
hostbyte=DID_SOFT_ERROR内核自动重试成功
线缆接触不良等临时故障,内核自动重试后恢复。严重程度:★
场景 | hostbyte | 块设备层 | 页缓存层 | 文件系统层 | 可修复性 | 严重程度 |
设备掉线 | DID_BAD_TARGET | I/O error | Buffer I/O error | metadata I/O error | 不可修复 | ★★★★★ |
元数据区域损坏 | DID_OK | 无/有 | Buffer I/O error | metadata I/O error | 可能修复 | ★★★★ |
普通数据扇区坏 | DID_OK | Medium error | Buffer I/O error | 无 | 文件丢失 | ★★★ |
偶发传输错误 | DID_SOFT_ERROR | 自动恢复 | 通常无 | 无 | 自动恢复 | ★ |
关键结论:设备掉线是最严重的情况。元数据损坏虽然也会影响文件系统,但设备还活着就意味着还有修复的可能。一旦设备本身消失了,软件层面的一切修复手段都失去了意义。在 ceph028 的案例中,正是这种最严重的情况——但得益于 Ceph 的分布式多副本架构,集群将这个"最严重"的单机故障降级为了一个可自动恢复的日常事件。
七、排查指南
一键日志检索:所有和硬盘硬件错误相关的日志匹配检索,非常实用,配合作业平台实现一键诊断
cat /var/log/messages |egrep "metadata I/O error|FAILURE PREDICTION|Predictive Failure|Drive Fault|target reset FAILED|Controller encountered a fatal error and was reset|Buffer I/O error|Check failed|Diagnostics failed|Offline uncorrectable|Currently unreadable" |grep -v euid |tail -n 50
dcc硬盘诊断工具:硬盘彻底损坏,raid离线