网上信息又多又杂,想要高效提取数据,爬虫就是最实用的工具。Python简单好用,各类工具库齐全,写爬虫一点都不难。今天就从基础原理讲起,用实战代码带你一步步入门,轻松学会从简单到复杂的爬虫开发。
1、基础知识
①HTTP 请求
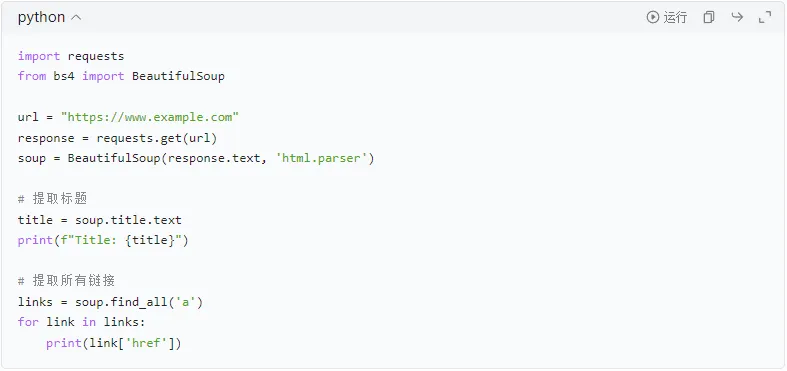
在开始爬虫前,先了解HTTP请求很重要。Python中有许多库可以发送HTTP请求,其中requests库就是一个很好的选择。
②HTML 解析
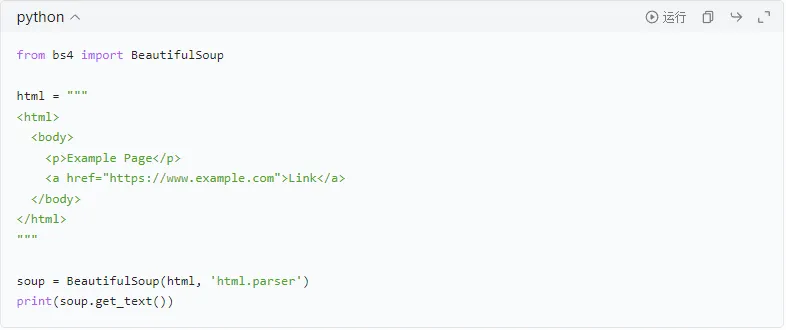
使用BeautifulSoup库可以方便地解析HTML文档,提取需要的信息。
2、静态网页爬取
①简单示例
爬取静态网页的基本步骤包括发送HTTP请求、解析HTML并提取信息。
②处理动态内容
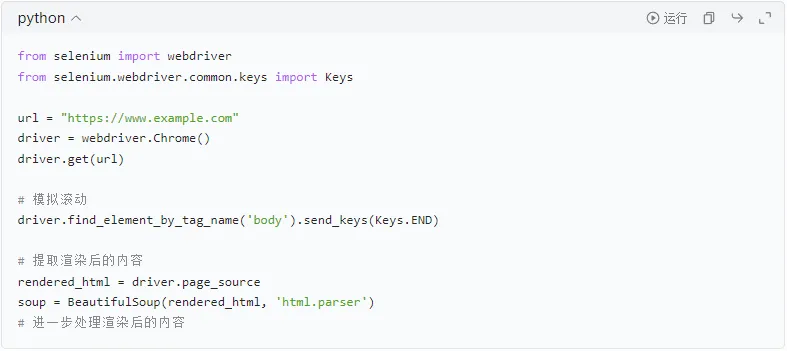
对于使用JavaScript渲染的网页,可以使用Selenium库模拟浏览器行为。
3、数据存储
①存储到文件
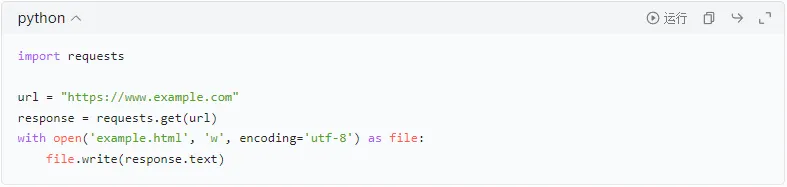
将爬取的数据存储到本地文件的方法。
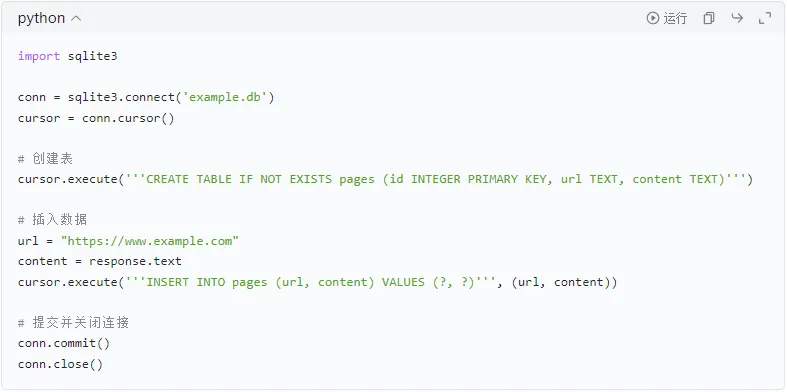
②存储到数据库
使用数据库存储爬取的数据,例如使用SQLite。
4、处理动态网页
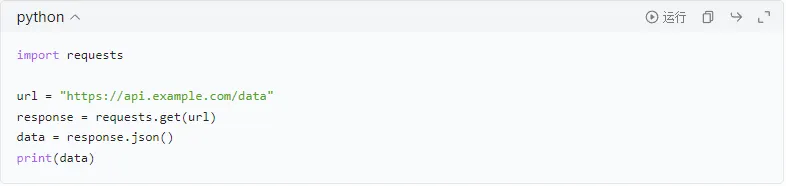
①使用API
有些网站提供API接口,直接请求API可以获得数据,不需要解析HTML。
②使用无头浏览器
使用Selenium库模拟无头浏览器,适用于需要JavaScript渲染的网页。
5、高级主题
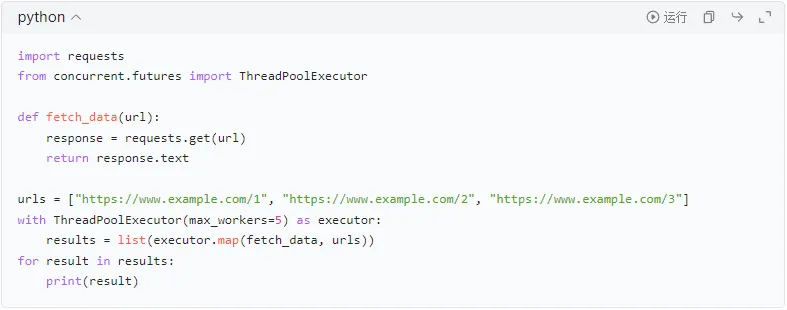
①多线程和异步
使用多线程或异步操作可以提高爬虫的效率,特别是在爬取大量数据时。
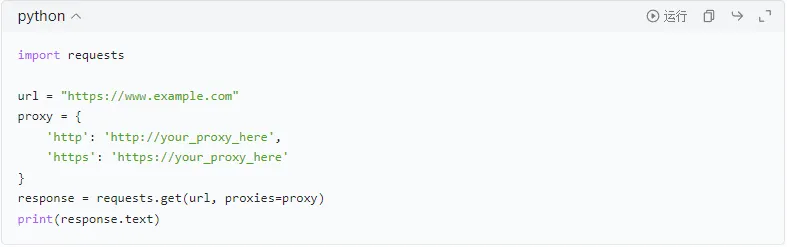
②使用代理
为了防止被网站封禁IP,可以使用代理服务器。
6、防反爬虫策略
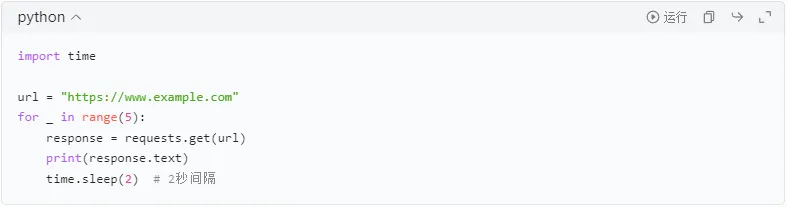
①限制请求频率
设置适当的请求间隔,模拟人类操作,避免过快爬取。
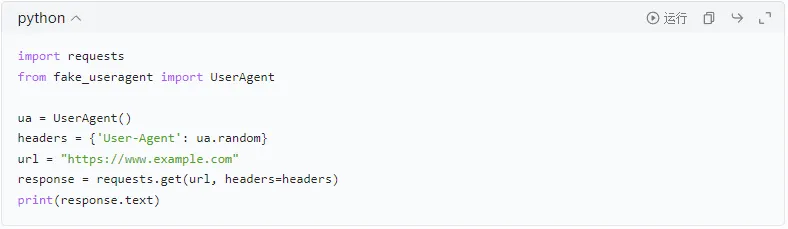
②使用随机User-Agent
随机更换User-Agent头部,降低被识别为爬虫的概率。
👆希望对大家有帮助!轻松掌握爬虫技能,安全合规地探索网络数据。