在分布式系统中,最核心的挑战就是如何让多个节点对同一个值达成一致。想象一下,你和几个朋友要在不同城市同时决定晚上吃什么,怎么确保大家最后决定的是同一家餐厅?这就是分布式一致性问题。
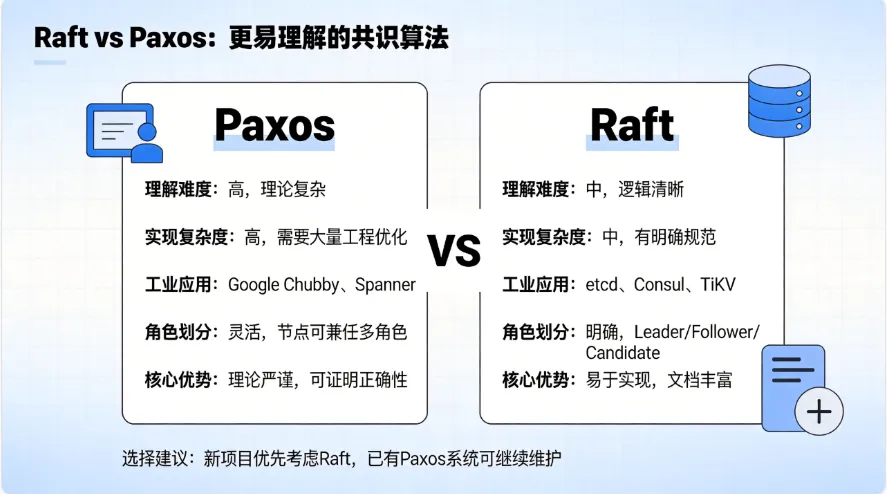
Paxos算法由Leslie Lamport在1990年提出,是解决分布式共识问题的经典算法。虽然理论有些复杂,但咱们可以通过一个简单的例子来理解。
- • Proposer(提案者):提出具体的值(比如"晚上吃火锅")
import random
import time
from typing importList, Optional, Tuple
classPaxosNode:
"""Paxos算法节点实现"""
def__init__(self, node_id: int, all_nodes: List[int]):
self.node_id = node_id
self.all_nodes = all_nodes
self.current_term = 0
self.promised_proposal_id = 0
self.accepted_proposal_id = 0
self.accepted_value = None
self.is_leader = False
defprepare_phase(self, proposal_id: int) -> List[Tuple[int, Optional[str]]]:
"""准备阶段:获取多数派承诺"""
print(f"节点{self.node_id}: 开始准备阶段,提案ID={proposal_id}")
responses = []
for node_id inself.all_nodes:
if node_id == self.node_id:
continue
# 模拟网络请求
if proposal_id > self.promised_proposal_id:
self.promised_proposal_id = proposal_id
response = (self.accepted_proposal_id, self.accepted_value)
responses.append(response)
print(f"节点{self.node_id}: 承诺提案{proposal_id},返回历史({self.accepted_proposal_id}, {self.accepted_value})")
else:
print(f"节点{self.node_id}: 拒绝提案{proposal_id},已承诺更高ID={self.promised_proposal_id}")
return responses
defaccept_phase(self, proposal_id: int, value: str, responses: List[Tuple[int, Optional[str]]]) -> bool:
"""接受阶段:尝试让多数派接受提案"""
print(f"节点{self.node_id}: 开始接受阶段,提案({proposal_id}, {value})")
accept_count = 1# 自己的一票
# 分析响应,决定最终值
highest_proposal_id = 0
chosen_value = None
for accepted_id, accepted_val in responses:
if accepted_id > highest_proposal_id and accepted_val isnotNone:
highest_proposal_id = accepted_id
chosen_value = accepted_val
# 如果已经有被接受的值,必须使用那个值
final_value = chosen_value if chosen_value else value
# 尝试获得多数派接受
for node_id inself.all_nodes:
if node_id == self.node_id:
continue
# 模拟接受请求
if proposal_id >= self.promised_proposal_id:
self.accepted_proposal_id = proposal_id
self.accepted_value = final_value
accept_count += 1
print(f"节点{self.node_id}: 接受提案({proposal_id}, {final_value})")
if accept_count > len(self.all_nodes) // 2:
print(f"节点{self.node_id}: 提案({proposal_id}, {final_value})获得多数派接受!")
returnTrue
returnFalse
# 模拟一个简单的Paxos集群
defsimulate_paxos():
nodes = [PaxosNode(i, [0, 1, 2, 3, 4]) for i inrange(5)]
# 节点2尝试成为leader并提议一个值
proposer = nodes[2]
proposal_id = 100# 假设这是全局唯一的提案ID
print("=== Paxos算法模拟开始 ===\n")
# 准备阶段
responses = proposer.prepare_phase(proposal_id)
# 接受阶段
success = proposer.accept_phase(proposal_id, "order_123:减库存", responses)
if success:
print(f"\n✓ 共识达成:所有节点一致同意对order_123减库存")
else:
print(f"\n✗ 共识失败:需要重试或等待")
print("\n=== Paxos算法模拟结束 ===")
# 运行模拟
if __name__ == "__main__":
simulate_paxos()
- 1. 多数派原则:必须获得超过半数节点的同意才能形成决议
- 2. 提案编号唯一性:每个提案有全局唯一的ID,保证优先级
- 3. 安全性:一旦一个值被选定,后续所有提案都必须使用这个值
Raft算法由Diego Ongaro和John Ousterhout在2014年提出,相比Paxos更易于理解和实现。Raft将共识问题分解为三个子问题:
- • Leader选举:选出一个leader节点负责协调
- • 日志复制:leader将操作日志复制到其他节点
import asyncio
import random
import time
from enum import Enum
from typing importList, Optional, Dict
import logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(message)s')
classState(Enum):
"""节点状态枚举"""
FOLLOWER = "follower"
CANDIDATE = "candidate"
LEADER = "leader"
classRaftNode:
"""Raft节点实现"""
def__init__(self, node_id: int, all_nodes: List[int]):
self.node_id = node_id
self.all_nodes = all_nodes
# Raft状态
self.state = State.FOLLOWER
self.current_term = 0
self.voted_for: Optional[int] = None
self.log: List[Dict] = []
self.commit_index = 0
self.last_applied = 0
# 选举相关
self.election_timeout = random.uniform(1.5, 3.0)
self.last_heartbeat = time.time()
self.votes_received = 0
# Leader状态(仅Leader有效)
self.next_index: Dict[int, int] = {}
self.match_index: Dict[int, int] = {}
asyncdeffollower_loop(self):
"""Follower主循环:等待心跳,超时则发起选举"""
logging.info(f"节点{self.node_id}: 当前是follower,任期{self.current_term}")
whileself.state == State.FOLLOWER:
elapsed = time.time() - self.last_heartbeat
if elapsed > self.election_timeout:
logging.info(f"节点{self.node_id}: 心跳超时,转换为candidate")
self.state = State.CANDIDATE
break
await asyncio.sleep(0.1)
asyncdefcandidate_loop(self):
"""Candidate主循环:发起选举,争取成为leader"""
self.current_term += 1
self.voted_for = self.node_id
self.votes_received = 1# 自己的一票
logging.info(f"节点{self.node_id}: 开始选举,任期{self.current_term}")
# 向其他节点请求投票
vote_tasks = []
for node_id inself.all_nodes:
if node_id != self.node_id:
# 模拟发送RequestVote RPC
task = self.request_vote_rpc(node_id)
vote_tasks.append(task)
# 等待投票结果
if vote_tasks:
results = await asyncio.gather(*vote_tasks, return_exceptions=True)
for result in results:
ifisinstance(result, bool) and result:
self.votes_received += 1
# 检查是否获得多数票
majority = len(self.all_nodes) // 2 + 1
ifself.votes_received >= majority:
logging.info(f"节点{self.node_id}: 获得{self.votes_received}票,当选leader")
self.state = State.LEADER
self.become_leader()
else:
logging.info(f"节点{self.node_id}: 仅获得{self.votes_received}票,选举失败")
self.state = State.FOLLOWER
self.last_heartbeat = time.time()
asyncdefrequest_vote_rpc(self, target_node_id: int) -> bool:
"""模拟发送RequestVote RPC"""
# 模拟网络延迟
await asyncio.sleep(random.uniform(0.05, 0.15))
# 简单模拟:如果目标节点是follower且没有投过票,就同意
# 实际中需要比较日志的新旧程度
return random.random() > 0.3# 70%概率同意
defbecome_leader(self):
"""成为leader后的初始化"""
logging.info(f"节点{self.node_id}: 成为leader,开始发送心跳")
# 初始化next_index和match_index
for node_id inself.all_nodes:
if node_id != self.node_id:
self.next_index[node_id] = len(self.log) + 1
self.match_index[node_id] = 0
asyncdefleader_loop(self):
"""Leader主循环:发送心跳,处理客户端请求"""
whileself.state == State.LEADER:
# 发送心跳
for node_id inself.all_nodes:
if node_id != self.node_id:
awaitself.send_heartbeat(node_id)
await asyncio.sleep(0.5) # 心跳间隔
asyncdefsend_heartbeat(self, target_node_id: int):
"""发送心跳"""
# 模拟心跳发送
pass
asyncdefsimulate_raft():
"""模拟Raft集群"""
node_ids = [1, 2, 3, 4, 5]
nodes = [RaftNode(node_id, node_ids) for node_id in node_ids]
print("=== Raft算法模拟开始 ===\n")
# 启动所有节点
tasks = []
for node in nodes:
if node.state == State.FOLLOWER:
task = asyncio.create_task(node.follower_loop())
tasks.append(task)
# 模拟运行一段时间
await asyncio.sleep(2)
# 取消所有任务
for task in tasks:
task.cancel()
print("\n=== Raft算法模拟结束 ===")
# 运行模拟
if __name__ == "__main__":
asyncio.run(simulate_raft())
| | |
| | |
| | |
| | |
| | 明确,Leader/Follower/Candidate |
在分布式系统中,当多个节点需要同时访问某个共享资源时,就需要分布式锁来保证互斥访问。比如电商系统中的库存扣减,如果多个订单同时扣减同一商品库存,没有锁保护就会导致超卖。
- • 避免死锁:锁必须有超时机制,防止客户端故障导致锁无法释放
Redis是分布式锁最常用的实现方案,咱们来看一个完整的Python实现:
import redis
import uuid
import time
import threading
from typing importOptional
from contextlib import contextmanager
classRedisDistributedLock:
"""Redis分布式锁实现"""
def__init__(self, redis_client, lock_key: str, expire_time: int = 30):
"""
初始化分布式锁
Args:
redis_client: Redis客户端实例
lock_key: 锁的键名
expire_time: 锁的过期时间(秒)
"""
self.redis = redis_client
self.lock_key = lock_key
self.expire_time = expire_time
self.identifier = str(uuid.uuid4()) # 唯一标识锁持有者
self.renew_thread = None
self.stop_renew = threading.Event()
defacquire(self, timeout: float = 10.0, retry_interval: float = 0.1) -> bool:
"""
获取分布式锁
Args:
timeout: 获取锁的超时时间(秒)
retry_interval: 重试间隔(秒)
Returns:
bool: 是否成功获取锁
"""
start_time = time.time()
while time.time() - start_time < timeout:
# 使用SET NX EX命令原子性地获取锁
success = self.redis.set(
self.lock_key,
self.identifier,
ex=self.expire_time,
nx=True# 只在key不存在时设置
)
if success:
print(f"✓ 成功获取锁 {self.lock_key},持有者: {self.identifier}")
self._start_renew_thread()
returnTrue
# 获取失败,等待后重试
time.sleep(retry_interval)
print(f"✗ 获取锁 {self.lock_key} 超时")
returnFalse
defrelease(self) -> bool:
"""
释放分布式锁
Returns:
bool: 是否成功释放锁
"""
self._stop_renew_thread()
# 使用Lua脚本保证原子性:先验证值再删除
lua_script = """
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end
"""
result = self.redis.eval(lua_script, 1, self.lock_key, self.identifier)
if result == 1:
print(f"✓ 成功释放锁 {self.lock_key}")
returnTrue
else:
print(f"✗ 释放锁失败:锁可能已被他人持有或已过期")
returnFalse
def_start_renew_thread(self):
"""启动锁续期线程"""
ifself.renew_thread isnotNone:
return
self.stop_renew.clear()
defrenew_lock():
renew_interval = self.expire_time / 3# 每隔1/3过期时间续期一次
whilenotself.stop_renew.is_set():
time.sleep(renew_interval)
ifself.stop_renew.is_set():
break
# 续期锁
lua_script = """
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("expire", KEYS[1], ARGV[2])
else
return 0
end
"""
success = self.redis.eval(
lua_script,
1,
self.lock_key,
self.identifier,
self.expire_time
)
if success:
print(f"🔁 锁 {self.lock_key} 续期成功")
else:
print(f"⚠️ 锁 {self.lock_key} 续期失败,可能已失去锁")
break
self.renew_thread = threading.Thread(target=renew_lock, daemon=True)
self.renew_thread.start()
def_stop_renew_thread(self):
"""停止锁续期线程"""
ifself.renew_thread isnotNone:
self.stop_renew.set()
self.renew_thread.join(timeout=1.0)
self.renew_thread = None
@contextmanager
deflock(self, timeout: float = 10.0):
"""
上下文管理器,方便使用with语句
Example:
with redis_lock.lock():
# 临界区代码
print("安全地操作共享资源")
"""
acquired = self.acquire(timeout)
ifnot acquired:
raise TimeoutError(f"获取锁 {self.lock_key} 超时")
try:
yieldself
finally:
self.release()
# 使用示例
defdemo_distributed_lock():
"""分布式锁使用演示"""
# 创建Redis客户端
r = redis.Redis(host='localhost', port=6379, db=0)
# 创建分布式锁实例
stock_lock = RedisDistributedLock(r, "lock:product:1001", expire_time=10)
# 模拟多个线程同时扣减库存
defreduce_stock(thread_id: int):
"""扣减库存函数"""
with stock_lock.lock():
print(f"线程{thread_id}: 开始扣减库存")
# 模拟耗时操作
time.sleep(1)
current_stock = r.get("stock:product:1001")
if current_stock:
new_stock = int(current_stock) - 1
r.set("stock:product:1001", new_stock)
print(f"线程{thread_id}: 库存扣减完成,剩余{new_stock}")
else:
print(f"线程{thread_id}: 库存不存在")
# 初始化库存
r.set("stock:product:1001", 100)
# 启动多个线程模拟并发扣减
threads = []
for i inrange(5):
t = threading.Thread(target=reduce_stock, args=(i,))
threads.append(t)
t.start()
# 等待所有线程完成
for t in threads:
t.join()
# 打印最终库存
final_stock = r.get("stock:product:1001")
print(f"\n最终库存: {final_stock.decode() if final_stock else'无库存'}")
if __name__ == "__main__":
demo_distributed_lock()
| | |
| 死锁 | | |
| 锁误删 | 客户端A的锁过期后,客户端B获取锁,然后A又误删B的锁 | |
| 锁续期 | | |
| 脑裂问题 | | |
分布式缓存是提升系统性能的利器,但设计不当会导致缓存穿透、雪崩、击穿等问题。咱们来一一拆解这些挑战。
这是最常用的缓存模式,应用代码直接控制缓存的读写:
import redis
import json
from typing importOptional, Any
import hashlib
import time
classCacheAsidePattern:
"""Cache-Aside模式实现"""
def__init__(self, redis_client):
self.redis = redis_client
defget_user(self, user_id: int) -> Optional[dict]:
"""
获取用户信息,使用Cache-Aside模式
Args:
user_id: 用户ID
Returns:
用户信息字典,如果不存在则返回None
"""
cache_key = f"user:{user_id}"
# 1. 先查缓存
cached_data = self.redis.get(cache_key)
if cached_data:
print(f"缓存命中 user:{user_id}")
return json.loads(cached_data)
# 2. 缓存未命中,查询数据库
print(f"缓存未命中,查询数据库 user:{user_id}")
user_data = self._query_database(user_id)
if user_data:
# 3. 将查询结果写入缓存
self.redis.setex(
cache_key,
3600, # 1小时过期
json.dumps(user_data)
)
print(f"数据写入缓存 user:{user_id}")
return user_data
defupdate_user(self, user_id: int, user_data: dict):
"""
更新用户信息
Args:
user_id: 用户ID
user_data: 新的用户数据
"""
# 1. 先更新数据库
self._update_database(user_id, user_data)
# 2. 删除缓存(而不是更新)
cache_key = f"user:{user_id}"
self.redis.delete(cache_key)
print(f"数据库更新完成,缓存已删除 user:{user_id}")
# 可选:延迟双删,解决并发问题
time.sleep(0.1)
self.redis.delete(cache_key)
def_query_database(self, user_id: int) -> Optional[dict]:
"""模拟数据库查询"""
# 模拟数据库查询延迟
time.sleep(0.05)
# 模拟数据库数据
mock_db = {
1: {"id": 1, "name": "张三", "email": "zhangsan@example.com"},
2: {"id": 2, "name": "李四", "email": "lisi@example.com"},
}
return mock_db.get(user_id)
def_update_database(self, user_id: int, user_data: dict):
"""模拟数据库更新"""
time.sleep(0.03)
print(f"数据库更新: user:{user_id} -> {user_data}")
defsearch_products(self, keyword: str, page: int = 1, page_size: int = 20) -> dict:
"""
商品搜索,演示缓存键的设计
Args:
keyword: 搜索关键词
page: 页码
page_size: 每页大小
Returns:
搜索结果
"""
# 构建缓存键:包含所有影响结果的参数
cache_key = self._build_cache_key("search", {
"keyword": keyword,
"page": page,
"page_size": page_size
})
# 尝试从缓存获取
cached_result = self.redis.get(cache_key)
if cached_result:
print(f"搜索缓存命中: {keyword}")
return json.loads(cached_result)
# 缓存未命中,执行搜索
print(f"搜索缓存未命中,执行搜索: {keyword}")
result = self._execute_search(keyword, page, page_size)
# 写入缓存,设置较短的过期时间(搜索数据变化较快)
self.redis.setex(cache_key, 300, json.dumps(result))
return result
def_build_cache_key(self, prefix: str, params: dict) -> str:
"""
构建缓存键,避免键冲突
Args:
prefix: 键前缀
params: 参数字典
Returns:
缓存键字符串
"""
# 对参数排序,确保相同的参数生成相同的键
sorted_params = sorted(params.items())
param_str = json.dumps(sorted_params, sort_keys=True)
# 使用MD5生成固定长度的键
hash_str = hashlib.md5(param_str.encode()).hexdigest()
returnf"{prefix}:{hash_str}"
def_execute_search(self, keyword: str, page: int, page_size: int) -> dict:
"""模拟搜索执行"""
time.sleep(0.1)
# 模拟搜索结果
offset = (page - 1) * page_size
products = [
{"id": i, "name": f"{keyword}商品{i}", "price": 100 + i}
for i inrange(offset, offset + page_size)
]
return {
"total": 1000,
"page": page,
"page_size": page_size,
"products": products
}
# 使用布隆过滤器防止缓存穿透
classBloomFilter:
"""简易布隆过滤器实现"""
def__init__(self, size: int = 10000, hash_functions: int = 3):
self.size = size
self.hash_functions = hash_functions
self.bit_array = [0] * size
defadd(self, item: str):
"""添加元素"""
for i inrange(self.hash_functions):
hash_val = self._hash(item, i) % self.size
self.bit_array[hash_val] = 1
defcontains(self, item: str) -> bool:
"""检查元素是否存在(可能有误判)"""
for i inrange(self.hash_functions):
hash_val = self._hash(item, i) % self.size
ifself.bit_array[hash_val] == 0:
returnFalse
returnTrue
def_hash(self, item: str, seed: int) -> int:
"""简单的哈希函数"""
returnhash(f"{item}_{seed}") & 0xffffffff
defdemo_cache_patterns():
"""缓存模式演示"""
r = redis.Redis(host='localhost', port=6379, db=0)
cache_system = CacheAsidePattern(r)
print("=== Cache-Aside模式演示 ===\n")
# 第一次查询,缓存未命中
user1 = cache_system.get_user(1)
print(f"查询结果: {user1}\n")
# 第二次查询,缓存命中
user1_cached = cache_system.get_user(1)
print(f"缓存查询结果: {user1_cached}\n")
# 更新用户信息
cache_system.update_user(1, {"name": "张三四", "email": "zhangsansi@example.com"})
# 再次查询,重新加载缓存
user1_updated = cache_system.get_user(1)
print(f"更新后查询: {user1_updated}\n")
# 演示搜索缓存
search_result = cache_system.search_products("手机")
print(f"搜索结果: {len(search_result['products'])} 条记录")
if __name__ == "__main__":
demo_cache_patterns()
classWriteThroughCache:
"""Write-Through模式实现"""
def__init__(self, redis_client, db_adapter):
self.redis = redis_client
self.db = db_adapter
defupdate_product(self, product_id: int, product_data: dict):
"""
更新商品信息(Write-Through模式)
Args:
product_id: 商品ID
product_data: 商品数据
"""
# 原子性操作:同时更新缓存和数据库
cache_key = f"product:{product_id}"
# 在事务中执行
pipeline = self.redis.pipeline()
# 1. 更新缓存
pipeline.setex(cache_key, 3600, json.dumps(product_data))
# 2. 更新数据库(这里简化处理)
pipeline.execute()
# 3. 同步更新数据库
self.db.update_product(product_id, product_data)
print(f"Write-Through模式: 商品{product_id}更新完成(缓存+数据库)")
| | |
| 缓存穿透 | | 1. 缓存空值
2. 使用布隆过滤器
3. 接口层校验 |
| 缓存击穿 | | 1. 热点key永不过期
2. 使用互斥锁重建缓存
3. 逻辑过期 |
| 缓存雪崩 | | 1. 过期时间加随机值
2. 缓存集群高可用
3. 降级熔断机制 |
| 缓存一致性 | | 1. Cache-Aside模式
2. 订阅数据库变更日志
3. 延迟双删 |
在分布式系统中,故障不是例外而是常态。咱们需要有完善的容错机制来保证系统的可靠性。
classCrashRecovery:
"""崩溃恢复机制"""
def__init__(self):
self.heartbeat_interval = 1.0# 心跳间隔
self.timeout_threshold = 3.0# 超时阈值
self.last_heartbeat = {}
defstart_heartbeat(self, node_id: str):
"""启动心跳检测"""
self.last_heartbeat[node_id] = time.time()
# 模拟心跳线程
defheartbeat_loop():
whileTrue:
time.sleep(self.heartbeat_interval)
self.last_heartbeat[node_id] = time.time()
threading.Thread(target=heartbeat_loop, daemon=True).start()
defcheck_node_health(self, node_id: str) -> bool:
"""检查节点健康状态"""
if node_id notinself.last_heartbeat:
returnFalse
elapsed = time.time() - self.last_heartbeat[node_id]
return elapsed < self.timeout_threshold
deffailover(self, primary_node: str, backup_nodes: list):
"""故障转移"""
ifnotself.check_node_health(primary_node):
print(f"节点 {primary_node} 故障,开始故障转移")
# 选择新的主节点
for backup in backup_nodes:
ifself.check_node_health(backup):
print(f"切换到备份节点 {backup}")
return backup
return primary_node
classPartitionTolerance:
"""分区容错处理"""
def__init__(self, nodes: list):
self.nodes = nodes
defhandle_partition(self, current_node: str, quorum_size: int):
"""
处理网络分区
Args:
current_node: 当前节点ID
quorum_size: 多数派大小
Returns:
bool: 当前分区是否允许提供服务
"""
# 模拟检测可达节点
reachable_nodes = self._detect_reachable_nodes(current_node)
print(f"节点 {current_node} 检测到 {len(reachable_nodes)}/{len(self.nodes)} 个可达节点")
# 检查是否达到多数派
iflen(reachable_nodes) >= quorum_size:
print("✓ 达到多数派,允许提供服务")
returnTrue
else:
print("✗ 未达到多数派,停止提供服务以避免数据不一致")
returnFalse
def_detect_reachable_nodes(self, current_node: str) -> list:
"""检测可达节点"""
# 模拟网络检测
reachable = [current_node]
for node inself.nodes:
if node != current_node:
# 模拟网络状况:70%概率可达
if random.random() < 0.7:
reachable.append(node)
return reachable
import time
from enum import Enum
from dataclasses import dataclass
from typing importCallable, Any, Optional
classCircuitState(Enum):
"""熔断器状态"""
CLOSED = "closed"# 正常状态
OPEN = "open"# 熔断状态
HALF_OPEN = "half_open"# 半开状态
@dataclass
classCircuitBreakerConfig:
"""熔断器配置"""
failure_threshold: int = 5# 失败阈值
reset_timeout: float = 30.0# 重置超时时间
half_open_max_calls: int = 3# 半开状态最大调用次数
classCircuitBreaker:
"""熔断器实现"""
def__init__(self, name: str, config: Optional[CircuitBreakerConfig] = None):
self.name = name
self.config = config or CircuitBreakerConfig()
# 状态
self.state = CircuitState.CLOSED
self.failure_count = 0
self.last_failure_time = None
self.half_open_success_count = 0
defcall(self, func: Callable, *args, **kwargs) -> Any:
"""
调用受保护的方法
Args:
func: 要调用的函数
*args, **kwargs: 函数参数
Returns:
函数执行结果
Raises:
CircuitBreakerOpenError: 熔断器开启时抛出
"""
# 检查熔断器状态
ifself.state == CircuitState.OPEN:
ifself._is_reset_timeout_elapsed():
self._transition_to_half_open()
else:
raise CircuitBreakerOpenError(f"熔断器 {self.name} 已开启")
elifself.state == CircuitState.HALF_OPEN:
ifself.half_open_success_count >= self.config.half_open_max_calls:
self._transition_to_closed()
# 尝试调用
try:
result = func(*args, **kwargs)
self._on_success()
return result
except Exception as e:
self._on_failure()
raise e
def_on_success(self):
"""调用成功处理"""
ifself.state == CircuitState.HALF_OPEN:
self.half_open_success_count += 1
# 重置失败计数
self.failure_count = 0
def_on_failure(self):
"""调用失败处理"""
self.failure_count += 1
self.last_failure_time = time.time()
ifself.state == CircuitState.HALF_OPEN:
# 半开状态下失败,立即转为开启
self._transition_to_open()
elifself.state == CircuitState.CLOSED:
ifself.failure_count >= self.config.failure_threshold:
self._transition_to_open()
def_transition_to_open(self):
"""切换到开启状态"""
print(f"熔断器 {self.name}: CLOSED -> OPEN")
self.state = CircuitState.OPEN
self.last_failure_time = time.time()
def_transition_to_half_open(self):
"""切换到半开状态"""
print(f"熔断器 {self.name}: OPEN -> HALF_OPEN")
self.state = CircuitState.HALF_OPEN
self.half_open_success_count = 0
def_transition_to_closed(self):
"""切换到关闭状态"""
print(f"熔断器 {self.name}: HALF_OPEN -> CLOSED")
self.state = CircuitState.CLOSED
self.failure_count = 0
def_is_reset_timeout_elapsed(self) -> bool:
"""检查重置超时是否已过"""
ifnotself.last_failure_time:
returnFalse
elapsed = time.time() - self.last_failure_time
return elapsed >= self.config.reset_timeout
classCircuitBreakerOpenError(Exception):
"""熔断器开启异常"""
pass
defdemo_circuit_breaker():
"""熔断器演示"""
defunstable_service(success_rate: float = 0.3) -> str:
"""模拟不稳定的服务"""
if random.random() < success_rate:
return"服务调用成功"
else:
raise Exception("服务调用失败")
# 创建熔断器
cb = CircuitBreaker("unstable_service", CircuitBreakerConfig(
failure_threshold=3,
reset_timeout=5.0,
half_open_max_calls=2
))
# 模拟调用
print("=== 熔断器演示开始 ===\n")
for i inrange(20):
try:
result = cb.call(unstable_service, 0.3)
print(f"调用 {i+1}: {result}")
except CircuitBreakerOpenError as e:
print(f"调用 {i+1}: {e}")
except Exception as e:
print(f"调用 {i+1}: {e}")
time.sleep(0.5)
print("\n=== 熔断器演示结束 ===")
if __name__ == "__main__":
demo_circuit_breaker()
classRetryPolicy:
"""重试策略"""
def__init__(self, max_attempts: int = 3, base_delay: float = 0.1):
self.max_attempts = max_attempts
self.base_delay = base_delay
defexecute_with_retry(self, func: Callable, *args, **kwargs) -> Any:
"""
执行带有重试的函数
Args:
func: 要执行的函数
*args, **kwargs: 函数参数
Returns:
函数执行结果
"""
last_exception = None
for attempt inrange(1, self.max_attempts + 1):
try:
return func(*args, **kwargs)
except Exception as e:
last_exception = e
if attempt < self.max_attempts:
# 指数退避 + 随机抖动
delay = self.base_delay * (2 ** (attempt - 1))
jitter = random.uniform(0, delay * 0.1) # 10%的抖动
print(f"尝试 {attempt} 失败,{delay + jitter:.2f}秒后重试: {e}")
time.sleep(delay + jitter)
else:
print(f"尝试 {attempt} 失败,达到最大重试次数")
raise last_exception
3. 混沌工程(Chaos Engineering)
classChaosMonkey:
"""混沌猴子实现"""
def__init__(self, enabled: bool = False):
self.enabled = enabled
definject_failure(self, failure_type: str, probability: float = 0.1):
"""
注入故障
Args:
failure_type: 故障类型
probability: 注入概率
"""
ifnotself.enabled or random.random() > probability:
return
failure_handlers = {
"latency": self._inject_latency,
"exception": self._inject_exception,
"timeout": self._inject_timeout,
"memory": self._inject_memory_pressure,
}
handler = failure_handlers.get(failure_type)
if handler:
handler()
def_inject_latency(self):
"""注入延迟"""
delay = random.uniform(0.1, 2.0)
print(f"混沌猴子: 注入 {delay:.2f}秒延迟")
time.sleep(delay)
def_inject_exception(self):
"""注入异常"""
print("混沌猴子: 注入随机异常")
raise Exception("混沌猴子注入的异常")
def_inject_timeout(self):
"""注入超时"""
print("混沌猴子: 注入超时")
time.sleep(10) # 模拟长时间阻塞
def_inject_memory_pressure(self):
"""注入内存压力"""
print("混沌猴子: 注入内存压力")
# 模拟内存分配(实际中应更谨慎)
large_list = ["x" * 1024for _ inrange(1000)]
time.sleep(0.5)
del large_list
| | |
| CAP定理 | 分布式系统中,一致性、可用性、分区容错性三者不可兼得 | |
| Paxos | | |
| Raft | 更易理解和实现的一致性算法,分解为领导选举、日志复制、安全性 | |
| 分布式锁 | | |
| 缓存穿透 | | |
| 缓存击穿 | | |
| 熔断器 | | |