概述
调用sklearn.linear_model中的LogisticRegression库,尝试通过对率回归对离散数据进行划分,对每个属性进行预测,选取正确率最大的属性作为根节点,并对该节点的每个属性取值进行划分选择,依此类推,最终绘制一棵决策树。
程序功能
对于给定西瓜数据集3.0,将字符串类型的属性取值转换为数值类型以便模型进行训练,并将连续属性离散化以便选取划分点,通过正确率来选取根节点,最终得到决策树数组。通过dealanddraw(n0, pngname)函数将数组转化为字典类型,绘制决策树,将决策树以图片形式保存在程序的同一目录下。
完整代码链接
python实现对率回归决策树 https://download.csdn.net/download/qq_36949278/85235060
https://download.csdn.net/download/qq_36949278/85235060
程序数据及代码
# -*- coding: utf-8 -*-"""Created on Sun Apr 21 11:57:22 2019@author: lazyn"""import osfrom sklearn.linear_model import LogisticRegressionimport numpy as npimport pandas as pdimport warningsfrom createPlot import createPlotimport matplotlib.pyplot as plt warnings.filterwarnings("ignore")#定义连续值处理函数def con_deal(temp_df, a): for j in range(0, len(temp_df)): temp_df.iat[j] = 0 if(temp_df.iat[j] < a) else 1 return temp_df#定义计算连续值正确率的函数def con_acc(data, Y): a = np.sort(np.array(data)) a = (a[0: len(a) - 1] + a[1: len(a)])/2 max_acc, ind = 0, 0 for i in range(0, len(a)): temp_df = con_deal(data.copy(), a[i]) X0 = np.array(temp_df).reshape(-1, 1) logreg = LogisticRegression() logreg.fit(X0, Y) acc = logreg.score(X0, Y) if max_acc < acc: max_acc = acc ind = i temp_df0 = X0 print(round(max_acc, 3), end = ', 判断结果为:\n') print(logreg.predict(temp_df0)) return [max_acc, a[ind]]#获取根节点函数def getroot(X1, Y1, m): max_acc = 0 for i in m: if i != '密度' and i != '含糖率': print(i + '节点, 正确率为', end = ':') X0 = np.array(X1[i]).reshape(-1, 1) logreg = LogisticRegression() logreg.fit(X0, Y1) acc = logreg.score(X0, Y1) print(round(acc, 3), end = ', 判断结果为:\n') print(logreg.predict(X0)) if max_acc < acc: max_acc = acc root = i else: print(i + '节点, 正确率为', end = ':') acc = con_acc(X1[i], Y1)[0] if max_acc < acc: max_acc = acc root = i return root#获取决策树数组函数def gettree(X, Xo, Y, m): n1, n2 = [], [] root = getroot(X, Y['好瓜'], m) print('故选择' + root + '为根节点') n1.append(root) m.remove(root) if root == '密度' or root == '含糖率': div = con_acc(X[root], Y['好瓜'])[1] X[root], Xo[root], Y[root] = con_deal(X[root], div), con_deal(Xo[root], div), con_deal(X[root], div)# print(X, Xo) Attr, Attro = X[root].unique(), Xo[root].unique()# print(Attr, Attro) for j, jo in zip(Attr, Attro): n3 = [] if root == '密度' or root == '含糖率': if j >= div: key = '≥' + str(div) else: key = '<' + str(div) else: key = jo print(root + '为' + key + '时:') n3.append(key) X1 = X[X[root] == j] Xo1 = Xo[Xo[root] == jo] Y0 = Y[Y[root] == j] Y1 = Y0['好瓜'] if Y1.unique().size > 1: Xn, Xon, Yn = X1, Xo1, Y0 n3.append(gettree(Xn, Xon, Yn, m)) else: flag = '好瓜' if Y1.unique() == '是' else '坏瓜' print(flag) n3.append(flag) n2.append(n3) n1 += n2 return n1 #数组处理及绘制函数def dealanddraw(n0, pngname): alstr = str(n0) alstr = alstr.replace(',', ':'); alstr = alstr.replace(']: [', ',') alstr = alstr.replace(']:', '],') alstr = alstr.replace('[', '{'); alstr = alstr.replace(']', '}') inTree = eval(alstr)# print(inTree) plt.figure(figsize = (10, 7)) createPlot(inTree)# dpi, 控制每英寸长度上的分辨率;bbox_inches, 能删除figure周围的空白部分 plt.savefig(pngname, dpi = 400, bbox_inches = 'tight')f = open('watermelon3.txt')watermelon3_df = pd.read_table(f)Xo = watermelon3_df[['色泽', '根蒂', '敲声', '纹理', '脐部', '触感', '密度', '含糖率']]m = list(watermelon3_df.columns)h = 0.001for i in m: if i != '密度' and i != '含糖率' and i != '好瓜': size_mapping = {} m0 = watermelon3_df[i].unique() j = 1 for i0 in m0: size_mapping[i0] = j j += 1# print(size_mapping) watermelon3_df[i] = watermelon3_df[i].map(size_mapping)X = watermelon3_df[['色泽', '根蒂', '敲声', '纹理', '脐部', '触感', '密度', '含糖率']]Y = watermelon3_dfm = list(X.columns)n0 = gettree(X, Xo, Y, m)pngname = os.path.basename(os.path.realpath(__file__)).replace('py', 'png')dealanddraw(n0, pngname)
参考自决策树的绘制_TaoTaoFu的博客-CSDN博客_绘制决策树,并做部分修改后代码如下:
import matplotlib.pyplot as plt#用来正常显示中文plt.rcParams['font.sans-serif'] = ['SimHei']#用来正常显示负号plt.rcParams['axes.unicode_minus'] = False#设置画节点用的盒子的样式decisionNode = dict(boxstyle = "sawtooth", color = '#3366FF')leafNode = dict(boxstyle = "round4", color = '#FF6633')#设置画箭头的样式arrow_args = dict(arrowstyle="<-", color='g')def getNumLeafs(myTree): #初始化树的叶子节点个数 numLeafs = 0 #myTree.keys()获取树的非叶子节点'no surfacing'和'flippers' #list(myTree.keys())[0]获取第一个键名'no surfacing' firstStr = list(myTree.keys())[0] #通过键名获取与之对应的值,即{0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}} secondDict = myTree[firstStr] #遍历树,secondDict.keys()获取所有的键 for key in secondDict.keys(): #判断键是否为字典,键名1和其值就组成了一个字典,如果是字典则通过递归继续遍历,寻找叶子节点 if type(secondDict[key]).__name__=='dict': numLeafs += getNumLeafs(secondDict[key]) #如果不是字典,则叶子结点的数目就加1 else: numLeafs += 1 #返回叶子节点的数目 return numLeafsdef getTreeDepth(myTree): #初始化树的深度 maxDepth = 0 #获取树的第一个键名 firstStr = list(myTree.keys())[0] #获取键名所对应的值 secondDict = myTree[firstStr] #遍历树 for key in secondDict.keys(): #如果获取的键是字典,树的深度加1 if type(secondDict[key]).__name__ == 'dict': thisDepth = 1 + getTreeDepth(secondDict[key]) else: thisDepth = 1 #去深度的最大值 if thisDepth > maxDepth : maxDepth = thisDepth #返回树的深度 return maxDepth#绘图相关参数的设置def plotNode(nodeTxt,centerPt,parentPt,nodeType): ''' annotate函数是为绘制图上指定的数据点xy添加一个nodeTxt注释 nodeTxt是给数据点xy添加一个注释,xy为数据点的开始绘制的坐标,位于节点的中间位置 xycoords设置指定点xy的坐标类型,xytext为注释的中间点坐标,textcoords设置注释点坐标样式 bbox设置装注释盒子的样式,arrowprops设置箭头的样式 ''' ''' figure points:表示坐标原点在图的左下角的数据点 figure pixels:表示坐标原点在图的左下角的像素点 figure fraction:此时取值是小数,范围是([0,1],[0,1]),在图的左下角时xy是(0,0),最右上角是(1,1) 其他位置是按相对图的宽高的比例取最小值 axes points : 表示坐标原点在图中坐标的左下角的数据点 axes pixels : 表示坐标原点在图中坐标的左下角的像素点 axes fraction : 与figure fraction类似,只不过相对于图的位置改成是相对于坐标轴的位置 ''' createPlot.ax1.annotate(nodeTxt, xy = parentPt, xycoords = 'axes fraction', xytext = centerPt, textcoords = 'axes fraction', va = "center", ha = "center", bbox = nodeType, arrowprops = arrow_args)#绘制线中间的文字(0和1)的绘制def plotMidText(cntrPt, parentPt, txtString): xMid = (parentPt[0] - cntrPt[0])/2.0 + cntrPt[0] #计算文字的x坐标 yMid = (parentPt[1] - cntrPt[1])/2.0 + cntrPt[1] #计算文字的y坐标 createPlot.ax1.text(xMid, yMid, txtString, va = "center", ha = "center", rotation = 20)#绘制树def plotTree(myTree, parentPt, nodeTxt): #获取树的叶子节点 numLeafs = getNumLeafs(myTree) #获取树的深度 depth = getTreeDepth(myTree) #firstStr = myTree.keys()[0] #获取第一个键名 firstStr = list(myTree.keys())[0] #计算子节点的坐标 cntrPt = (plotTree.xoff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yoff) #绘制线上的文字 plotMidText(cntrPt, parentPt, nodeTxt) #绘制节点 plotNode(firstStr, cntrPt, parentPt, decisionNode) #获取第一个键值 secondDict = myTree[firstStr] #计算节点y方向上的偏移量,根据树的深度 plotTree.yoff = plotTree.yoff - 1.0/plotTree.totalD for key in secondDict.keys(): if type(secondDict[key]).__name__ == 'dict': #递归绘制树 plotTree(secondDict[key], cntrPt, str(key)) else: #更新x的偏移量,每个叶子结点x轴方向上的距离为 1/plotTree.totalW plotTree.xoff = plotTree.xoff + 1.0 / plotTree.totalW #绘制非叶子节点 plotNode(secondDict[key], (plotTree.xoff, plotTree.yoff), cntrPt, leafNode) #绘制箭头上的标志 plotMidText((plotTree.xoff, plotTree.yoff), cntrPt, str(key)) plotTree.yoff = plotTree.yoff + 1.0 / plotTree.totalD#绘制决策树def createPlot(inTree): #清除figure plt.clf() axprops = dict(xticks = [], yticks = []) #创建一个1行1列1个figure,并把网格里面的第一个figure的Axes实例返回给ax1作为函数createPlot() #的属性,这个属性ax1相当于一个全局变量,可以给plotNode函数使用 createPlot.ax1 = plt.subplot(frameon = False, **axprops) #获取树的叶子节点 plotTree.totalW = float(getNumLeafs(inTree)) #获取树的深度 plotTree.totalD = float(getTreeDepth(inTree)) #节点的x轴的偏移量为-1/plotTree.totlaW/2,1为x轴的长度,除以2保证每一个节点的x轴之间的距离为1/plotTree.totlaW*2 plotTree.xoff = -0.5/plotTree.totalW plotTree.yoff = 1.0 plotTree(inTree, (0.5, 1.0), '') plt.show()#inTree = {'色泽': {'青绿': {'敲声': {'浊响': '好瓜', '清脆': '坏瓜', '沉闷': '坏瓜'}},\# '乌黑': {'根蒂': {'蜷缩': '好瓜', '稍蜷': {'纹理': {'稍糊': '好瓜', '清晰': '坏瓜'}}}},\# '浅白': '坏瓜'}}#createPlot(inTree)
色泽 根蒂 敲声 纹理 脐部 触感 密度 含糖率 好瓜青绿 蜷缩 浊响 清晰 凹陷 硬滑 0.697 0.46 是乌黑 蜷缩 沉闷 清晰 凹陷 硬滑 0.774 0.376 是乌黑 蜷缩 浊响 清晰 凹陷 硬滑 0.634 0.264 是青绿 蜷缩 沉闷 清晰 凹陷 硬滑 0.608 0.318 是浅白 蜷缩 浊响 清晰 凹陷 硬滑 0.556 0.215 是青绿 稍蜷 浊响 清晰 稍凹 软粘 0.403 0.237 是乌黑 稍蜷 浊响 稍糊 稍凹 软粘 0.481 0.149 是乌黑 稍蜷 浊响 清晰 稍凹 硬滑 0.437 0.211 是乌黑 稍蜷 沉闷 稍糊 稍凹 硬滑 0.666 0.091 否青绿 硬挺 清脆 清晰 平坦 软粘 0.243 0.267 否浅白 硬挺 清脆 模糊 平坦 硬滑 0.245 0.057 否浅白 蜷缩 浊响 模糊 平坦 软粘 0.343 0.099 否青绿 稍蜷 浊响 稍糊 凹陷 硬滑 0.639 0.161 否浅白 稍蜷 沉闷 稍糊 凹陷 硬滑 0.657 0.198 否乌黑 稍蜷 浊响 清晰 稍凹 软粘 0.36 0.37 否浅白 蜷缩 浊响 模糊 平坦 硬滑 0.593 0.042 否青绿 蜷缩 沉闷 稍糊 稍凹 硬滑 0.719 0.103 否
结果
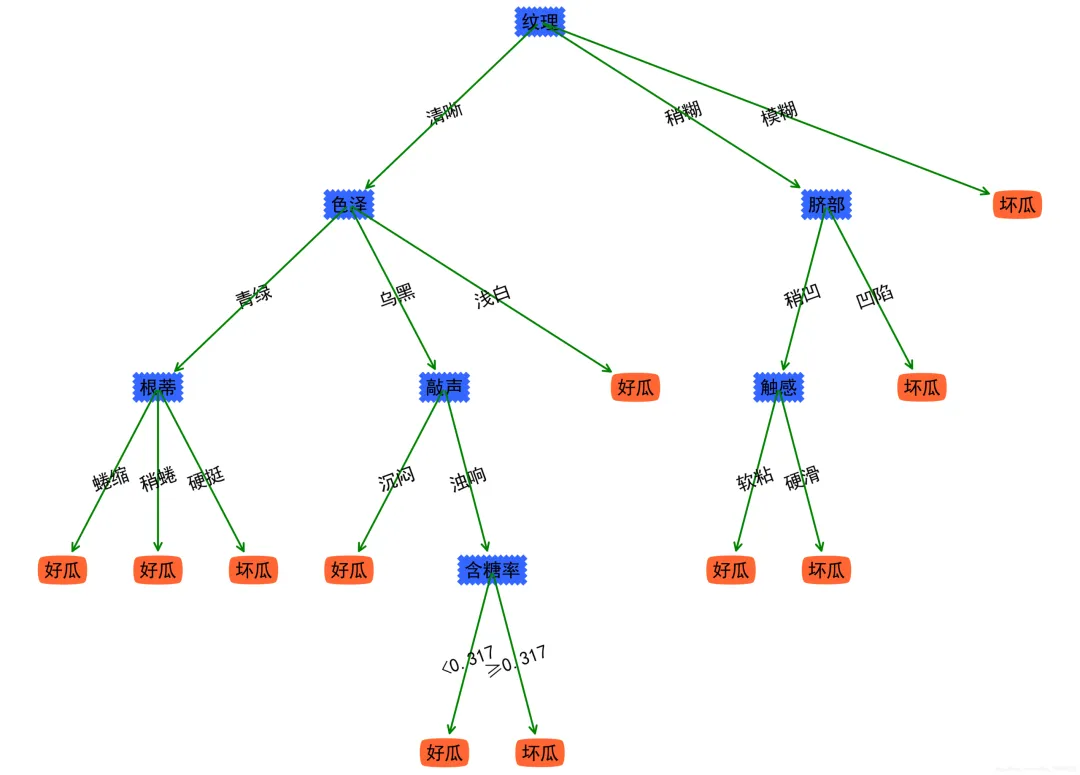 对率回归决策树
对率回归决策树不足
对于正确率相同的节点,选取优先遍历的属性作为根节点,与基于信息增益进行划分选择的方法相比,通过下图,可知两种方法绘制的决策树正确率均为100%,但对率回归方法容易忽略在同一正确率下划分较佳的节点,从而使决策树层数增多,变得更加复杂。
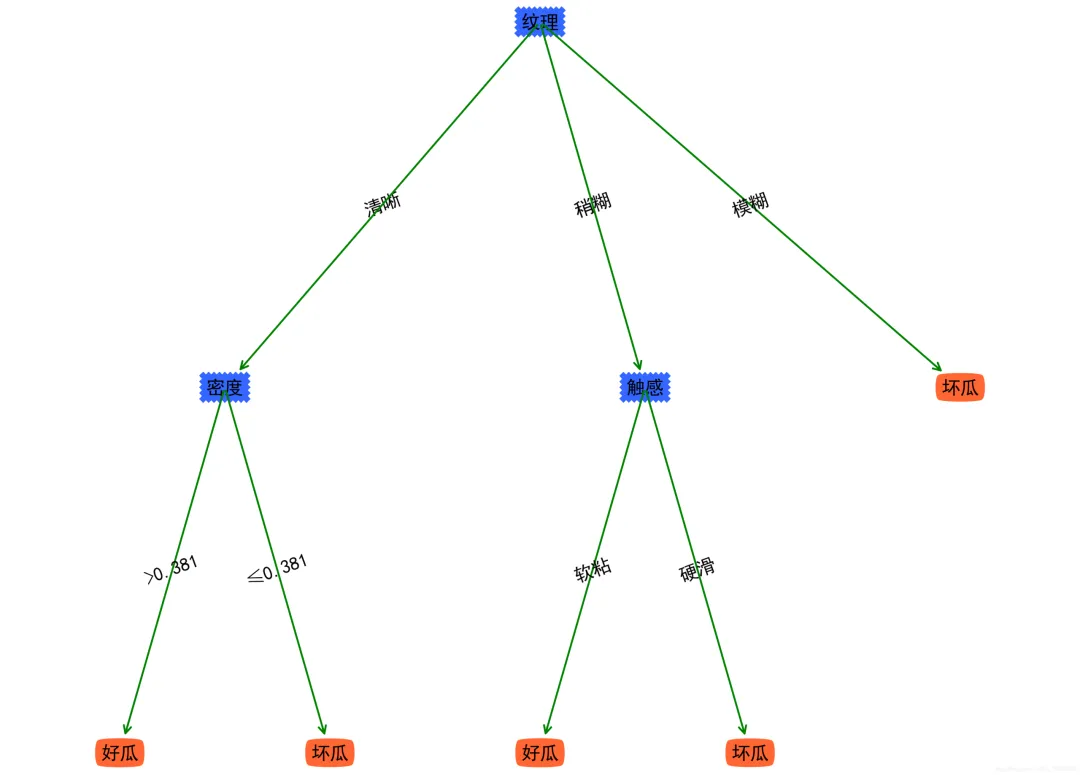 信息增益决策树
信息增益决策树数据集来源
《机器学习》周志华

