Linux 在线扩容完全指南:从"分层模型"出发,一篇讲透 LVM 与普通分区
- 2026-07-02 16:35:40
一、先建立一个心智模型:Linux 存储是"分层"的
绝大多数人扩容失败、或者扩完发现"没生效",根本原因只有一个:没搞清楚存储是分层的,把某一层的操作误以为是全部。
所以我们不急着敲命令。先把这张图刻进脑子里。
1.1 两条链路
LVM 链路(服务器常见,层数多):
物理磁盘 (Disk) └─ 分区 (Partition) └─ 物理卷 (PV = Physical Volume) └─ 卷组 (VG = Volume Group) └─ 逻辑卷 (LV = Logical Volume) └─ 文件系统 (Filesystem) ← 你和数据真正打交道的层LVM六层分层架构示意图

普通分区链路(云镜像、Debian、桌面版常见,层数少):
物理磁盘 (Disk) └─ 分区 (Partition) └─ 文件系统 (Filesystem) ← 直接就到文件系统了对照一下这几层各自的角色:
Red Hat 官方文档对 LVM 的核心描述是:可以聚合多个设备和分区成一个逻辑卷,文件系统能像使用一块大盘一样跨多个物理设备扩展,并且"无需重新格式化、无需重新分区"就能调整大小。Ubuntu 官方文档也强调:只要文件系统支持,LVM 可以在分区处于挂载状态时直接扩容,而且扩容时可以用卷组里任意位置的空闲空间,哪怕它在另一块磁盘上。
1.2 扩容的本质(核心思想)
扩容 = 从"发生变化的那一层"开始,把"我变大了"这个信息一层一层往上传递,直到最顶层的文件系统。
举例:你在虚拟化平台上把虚拟磁盘从 100G 改成 200G。这时候只有最底层的"磁盘"变大了,上面的分区、PV、VG、LV、文件系统全都还是旧的大小。你要做的,就是从磁盘这一层开始,逐层执行对应命令,把这个 100G 的新增量"推"上去。
每一层都有它专属的命令,差一层都不行:
growpartfdisk / gdisk / parted | |
pvresizepvcreate(新建) | |
vgextend | |
lvextendlvresize | |
resize2fsxfs_growfs(xfs) / btrfs filesystem resize(btrfs) |
所有扩容场景的差异,仅仅在于"变化从哪一层开始"。 想清楚起点,剩下的就是顺着链路往上走。这就是本文所有场景的统一方法论。
1.3 "在线"是怎么做到的
"在线"指的是不停机、不卸载文件系统、业务不中断。它能成立,靠的是两点:
内核支持在线重读分区表。 改完分区表后,用 partprobe通知内核刷新,不用重启。现代文件系统支持在挂载状态下扩容。 ext4 和 xfs 都能在 /正在使用时直接扩。
这里纠正一个常见误解:不是只有 LVM 才能在线扩容。 普通分区同样可以在线扩(云服务器天天这么干)。LVM 的真正优势不是"能不能在线",而是灵活——可以跨多块盘、空间能在不同 LV 之间挪、能做快照。普通分区受限于"分区必须物理连续、通常只能往后扩"。
二、起手式:lsblk —— 动手之前,先看清自己站在哪里
任何扩容操作的第一条命令,永远是 lsblk。 这不是仪式感,是有明确目的的。
2.1 为什么第一步必须是 lsblk
lsblk 用一棵树把"磁盘 → 分区 → LVM"的完整结构画出来。你要从它的输出里得到三个关键判断,这三个判断直接决定你接下来怎么走:
我这台机器到底有没有用 LVM? —— 决定走第三章还是第六章。 变化(空闲空间)出现在哪一层? —— 决定你的"起点"在哪里。 磁盘、分区、LV 的大小对不对得上? —— 大小不一致的地方,就是还没扩到位的地方。
2.2 一份典型输出,逐列精讲
$ lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTSsda 8:0 0 100G 0 disk├─sda1 8:1 0 1M 0 part├─sda2 8:2 0 2G 0 part /boot└─sda3 8:3 0 98G 0 part └─ubuntu--vg-ubuntu--lv 252:0 0 49G 0 lvm /做成示意图看起来更加明显
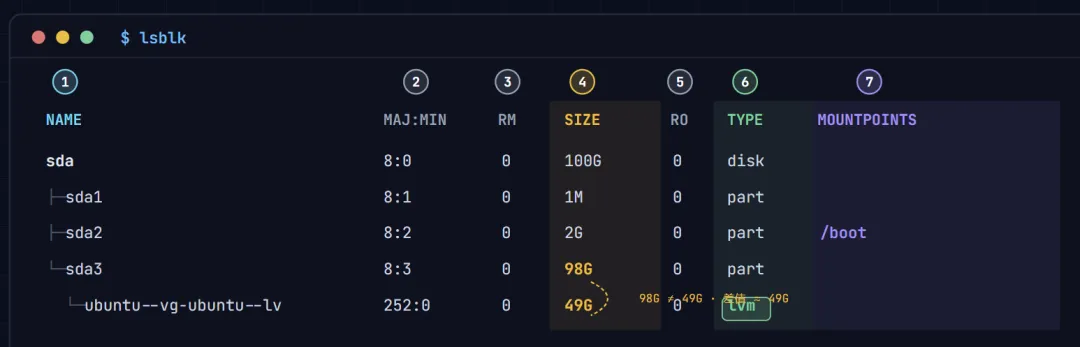
先看每一列是什么意思:
NAME —— 设备名。前面的 ├─└─表示层级隶属关系。sda是整块磁盘,sda1/2/3是它上面的分区,ubuntu--vg-ubuntu--lv是建在sda3之上的逻辑卷(名字里的--是 LVM 对-的转义,实际是ubuntu-vg卷组里的ubuntu-lv)。MAJ:MIN —— 内核给设备的主次设备号,日常扩容用不到,可忽略。 RM —— 是否可移动设备(U盘类)。 0表示固定磁盘。SIZE —— 【关键列】 每一层各自的大小。看扩容,主要就盯这一列。 RO —— 是否只读。 0表示可读写,正常。TYPE —— 【关键列】 设备类型。 disk=整块磁盘,part=分区,lvm=逻辑卷。只要这里出现了lvm,就说明这台机器用了 LVM。MOUNTPOINTS —— 【关键列】 挂载点。 /是根目录,/boot是引导分区,空白表示没挂载。
再看这份输出能读出什么(这才是重点):
sda这块盘是 100G,但它下面的分区sda1(1M) + sda2(2G) + sda3(98G)加起来约 101G ≈ 占满了。说明磁盘层面没有未分区的空闲空间。TYPE 列出现了 lvm→ 这台机器用了 LVM,要走第三章。注意看大小链条:分区 sda3是 98G,但建在它上面的逻辑卷ubuntu-lv只有 49G。两者差了约 49G。这个差值意味着什么? sda3整个交给了 LVM 当 PV,PV 有 98G,但 LV 只用了 49G —— 说明卷组 VG 里还躺着约 49G 没被使用的空闲空间。
结论:这台机器属于后文的「场景 A」——VG 里有现成空闲空间,是最简单的情况,两步就能扩完,连分区都不用碰。
这就是
lsblk起手式的价值:还没动手,你已经知道了自己是哪种场景、起点在哪、要走几步。
2.3 配套命令:lsblk -f 看文件系统类型
lsblk 默认不显示文件系统类型,但文件系统类型决定了最后一步用哪个命令(ext 用 resize2fs,xfs 用 xfs_growfs),所以紧接着要看一眼:
$ lsblk -fNAME FSTYPE FSVER LABEL MOUNTPOINTSsda├─sda1├─sda2 ext4 1.0 /boot└─sda3 LVM2_member LVM2 └─ubuntu--vg-ubuntu--lv ext4 1.0 /关键看 FSTYPE 列:
ubuntu-lv的 FSTYPE 是ext4→ 最后一步要用resize2fs。如果这里是xfs(CentOS/RHEL 7 以后默认),就要用xfs_growfs。sda3的 FSTYPE 是LVM2_member→ 这是个明确信号:这个分区已经被 LVM 接管当 PV 了,它身上没有普通文件系统。
等价命令
df -hT也能看文件系统类型,区别是df只列出已挂载的。两个都记住,lsblk -f看全貌,df -hT看在用的。
至此,起手式完成。下面正式进入扩容。
三、LVM 扩容(从简到难,三个场景)
3.0 场景速判表
用 lsblk 看完后,对照下表确认你是哪种场景:
| 场景 A | |||
| 场景 B | |||
| 场景 C |
怎么快速分辨 A / B / C:
vgs看到VFree不为 0 → 场景 A。磁盘 SIZE 比所有分区之和大,且这块盘是新加的或一直空着 → 场景 B。 磁盘 SIZE 比分区之和大,但这块盘原本是占满的(你刚在虚拟化平台/云控制台把它改大了)→ 场景 C。
下面三个场景,验证步骤会贯穿讲解——因为对 LVM 来说,"每扩一层就验证一层"比命令本身更重要。
3.1 场景 A:VG 里有现成空闲空间(最简单,两步搞定)
这是 Ubuntu 默认安装最常见的"坑":安装器把磁盘整个给了 VG,却只给逻辑卷分配了一半空间。Red Hat 系统也可能因为手动分区留出余量而出现这种情况。
起点在 LV 层,下面的磁盘、分区、PV、VG 全都不用动。
第 1 步:先验证——确认 VG 真的有空闲空间
$ sudo vgs VG #PV #LV #SN Attr VSize VFree ubuntu-vg 1 1 0 wz--n- <98.00g <49.00g示意图
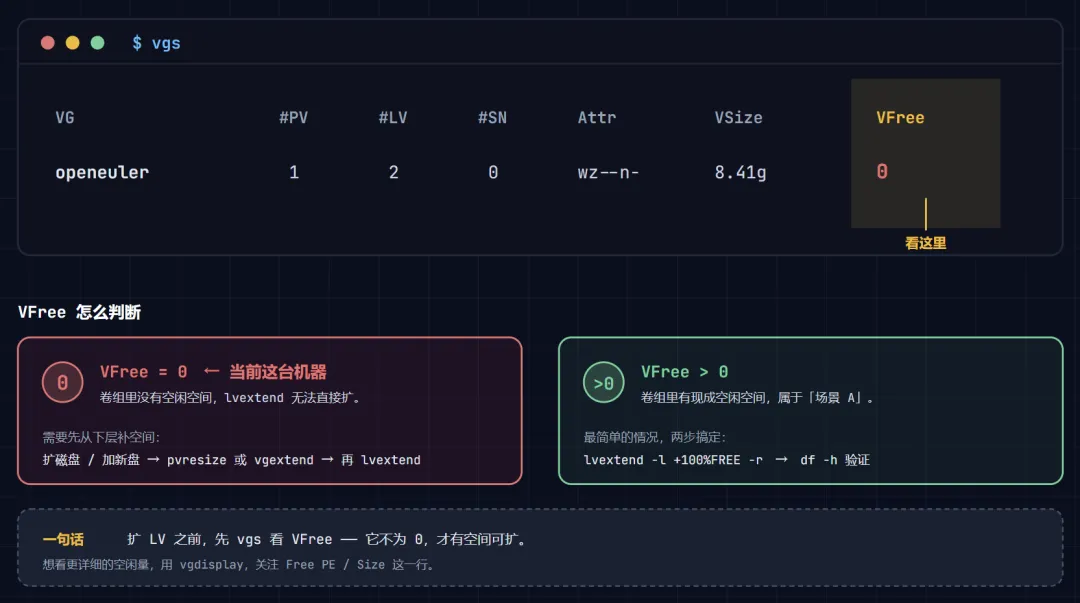
关键看 VFree 这一列:这里显示 <49.00g,意思是卷组里有将近 49G 没被任何 LV 占用。< 表示"略小于"。只要 VFree 不是 0,场景 A 成立,可以直接扩。
想看更详细的,用 vgdisplay:
$ sudo vgdisplay --- Volume group --- VG Name ubuntu-vg VG Size <98.00 GiB PE Size 4.00 MiB Total PE 25087 Alloc PE / Size 12543 / <49.00 GiB Free PE / Size 12544 / 49.00 GiB ← 关键行**关键看 Free PE / Size**:12544 / 49.00 GiB 表示有 12544 个空闲的 PE(Physical Extent,LVM 分配空间的最小单位,这里每个 4MiB),合计 49G 可用。Free PE 不为 0,确认有空间。
第 2 步:扩展 LV,并同步扩展文件系统
lvs 查出卷组名和逻辑卷名
LVM 提供了一个非常方便的参数 -r(--resizefs):扩 LV 的同时自动把上面的文件系统也一起扩了,一条命令完成两层。
# 把卷组里所有空闲空间都给 ubuntu-lv,并同步扩展文件系统$ sudo lvextend -l +100%FREE -r /dev/ubuntu-vg/ubuntu-lv参数说明(这几个写法要会区分):
-l +100%FREE—— 用掉 VG 里全部剩余空间。-l后面跟的是"按 PE/百分比"计。-L +20G—— 换成这个写法表示增加 20G(注意+)。-L后面跟的是"具体容量"。-L 60G—— 不带+,表示把 LV 设为 60G 这个绝对值。-r—— 关键!同步扩展文件系统。它内部会自动识别是 ext 还是 xfs 并调用对应工具。
执行后的输出:
Size of logical volume ubuntu-vg/ubuntu-lv changed from <49.00 GiB (12543 extents) to <98.00 GiB (25086 extents). Logical volume ubuntu-vg/ubuntu-lv successfully resized.resize2fs 1.46.5 (30-Dec-2021)Filesystem at /dev/mapper/ubuntu--vg-ubuntu--lv is mounted on /; on-line resizing requiredThe filesystem on /dev/mapper/ubuntu--vg-ubuntu--lv is now 25688064 (4k) blocks long.输出里要确认两件事:
changed from <49.00 GiB ... to <98.00 GiB—— LV 层扩成功了。on-line resizing required+is now 25688064 (4k) blocks long—— 文件系统层也在线扩成功了。这里能看到它自动调用了resize2fs(因为是 ext4)。
第 3 步:最终验证——df -h 才是真相
$ df -h /Filesystem Size Used Avail Use% Mounted on/dev/mapper/ubuntu--vg-ubuntu--lv 96G 20G 72G 22% /这一步绝对不能省。 这是新手最容易栽的地方,记住这句话:
lvs显示 LV 变大了,不等于df里变大了。LV 是"容器",文件系统是"容器里装东西的结构"。如果你没加-r、又忘了手动扩文件系统,会出现lvs显示 98G、但df还是 49G 的诡异情况——你以为扩了,其实没扩。**df -h看到Size变大,才算真正成功。**
场景 A 完成。两步:lvextend -r + df 验证。
3.2 场景 B:磁盘有未分区空间,或加了一块新硬盘
这两种情况合并讲,因为方法几乎一样——**起点都在"分区层"**,需要先造出一个新分区/新 PV,再往上推。
适用情形:
物理机/虚拟机里新插了一块硬盘( lsblk里出现一个全新的sdb,没有任何分区)。或者当前磁盘有一大段从没分过区的空闲空间。
完整链路:分区 → pvcreate → vgextend → lvextend → 文件系统。
第 1 步:lsblk 确认新空间
$ lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTSsda 8:0 0 100G 0 disk├─sda1 ...└─sda3 8:3 0 98G 0 part └─ubuntu--vg-ubuntu--lv 252:0 0 98G 0 lvm /sdb 8:16 0 50G 0 disk ← 新加的盘,干干净净关键:sdb 是 disk 类型、50G、下面没有任何子项 → 这是一块全新的、未分区的盘。
第 2 步:在新盘上建分区(用 fdisk 或 gdisk,详见第四章)
严格说,整块盘可以不分区直接
pvcreate /dev/sdb,LVM 也认。但实践中更推荐先分一个区再做 PV,原因:分区表能明确标记"这块空间被 LVM 占用",避免别的工具误判成空盘;管理上也更清晰。本文按"先分区"来讲。
用 fdisk 给 /dev/sdb 建一个占满全盘的分区,并把分区类型设为 LVM(具体交互过程见第四章)。建完后:
$ lsblk /dev/sdbNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTSsdb 8:16 0 50G 0 disk└─sdb1 8:17 0 50G 0 part ← 新分区出现了第 3 步:把新分区初始化为 PV(pvcreate)
$ sudo pvcreate /dev/sdb1 Physical volume "/dev/sdb1" successfully created.这一步是"把这个分区登记进 LVM 体系"。验证:
$ sudo pvs PV VG Fmt Attr PSize PFree /dev/sda3 ubuntu-vg lvm2 a-- <98.00g 0 /dev/sdb1 lvm2 --- 50.00g 50.00g ← 新 PV,但 VG 列是空的关键看 VG 列:/dev/sdb1 这一行的 VG 列是空的——说明它已经是 PV 了,但还没加入任何卷组。这就是下一步要做的。
第 4 步:把新 PV 加入卷组(vgextend)
$ sudo vgextend ubuntu-vg /dev/sdb1 Volume group "ubuntu-vg" successfully extended.验证:
$ sudo vgs VG #PV #LV #SN Attr VSize VFree ubuntu-vg 2 1 0 wz--n- 147.99g 50.00g关键看两个数:#PV 从 1 变成了 2(卷组现在由两块 PV 组成),VFree 出现了 50.00g 的空闲空间。卷组成功变大。
第 5 步:扩 LV + 扩文件系统(同场景 A 第 2 步)
$ sudo lvextend -l +100%FREE -r /dev/ubuntu-vg/ubuntu-lv第 6 步:df -h 最终验证
$ df -h /Filesystem Size Used Avail Use% Mounted on/dev/mapper/ubuntu--vg-ubuntu--lv 146G 20G 120G 15% /这个场景生动体现了 LVM 的威力:逻辑卷
ubuntu-lv现在横跨sda3和sdb1两块物理磁盘,但对系统和用户来说,它就是一个连续的 146G 空间。这是普通分区永远做不到的。
3.3 场景 C:底层磁盘本身被扩大了(最常见的生产场景)
这是云服务器、虚拟机最高频的场景:你在 VMware/Proxmox/vSphere 把虚拟磁盘从 100G 改成 200G,或者在云控制台把云盘扩容。结果是——磁盘变大了,但它上面那个旧分区还是旧大小。
这个场景比 B 多了一个**极其关键、又最容易被遗漏的命令:pvresize**。
完整链路:growpart 扩分区 → pvresize → lvextend → 文件系统。
第 1 步:lsblk 看出"盘和分区对不上"
在虚拟化平台把盘改大后,进系统执行:
$ lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTSsda 8:0 0 200G 0 disk ← 磁盘已经 200G├─sda1 8:1 0 1M 0 part├─sda2 8:2 0 2G 0 part /boot└─sda3 8:3 0 98G 0 part ← 但分区还是 98G! └─ubuntu--vg-ubuntu--lv 252:0 0 98G 0 lvm /关键对比:sda 是 200G,但 sda1+sda2+sda3 ≈ 100G。中间凭空多出来约 100G——这就是新增空间,它现在卡在"磁盘层",还没传到分区层。这正是场景 C 的典型特征。
第 2 步:扩展分区(growpart,强烈推荐)
要把 sda3 这个分区的边界往后推到磁盘末尾。最省心、最安全的工具是 growpart。
$ sudo growpart /dev/sda 3CHANGED: partition=3 start=4198400 old: size=205520896 end=209719296 new: size=415236063 end=419434463注意两点:
设备名 /dev/sda和分区号3之间有一个空格,是两个独立参数(这是 AWS 文档反复强调的,写错就报错)。输出里 old: size=...→new: size=...数字明显变大 → 分区扩展成功。如果它返回NOCHANGE,说明分区已经是满的、或者你看错了空间位置。
growpart属于cloud-guest-utils(Ubuntu/Debian)或cloud-utils-growpart(RHEL/CentOS/Amazon Linux)包。如果系统没有,先装:
Ubuntu/Debian: sudo apt install cloud-guest-utilsRHEL/CentOS/Amazon Linux: sudo yum install cloud-utils-growpart
growpart的一大好处是它会自动通知内核重读分区表,不用你手动partprobe。如果你坚持用fdisk/parted手动改分区,扩完后必须自己执行partprobe(见第四章)。
验证分区已扩:
$ lsblk /dev/sda3NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTSsda3 8:3 0 198G 0 part└─ubuntu--vg-ubuntu--lv 252:0 0 98G 0 lvm /sda3 现在是 198G 了。但注意——它上面的 ubuntu-lv 还是 98G。继续往上推。
第 3 步:让 PV 识别新边界(pvresize)—— 场景 C 的灵魂步骤
sda3 这个分区变大了,但建在它上面的 PV 还以为自己只有 98G。必须用 pvresize 让 PV 重新探测分区的真实大小。
$ sudo pvresize /dev/sda3 Physical volume "/dev/sda3" changed 1 physical volume(s) resized or updated / 0 physical volume(s) not resized这一步是场景 B 没有的。 场景 B 是"加了一块新 PV",用 vgextend;场景 C 是"老 PV 自己变大了",用 pvresize。两者不能混。漏掉 pvresize 是这个场景最常见的失败原因——分区明明扩了,vgs 却看不到空闲空间。
验证:
$ sudo pvs PV VG Fmt Attr PSize PFree /dev/sda3 ubuntu-vg lvm2 a-- <198.00g 100.00g**关键看 PSize 和 PFree**:PSize 从原来的 98G 变成了 198G(PV 认识到分区变大了),PFree 出现了 100G 空闲。
再看卷组:
$ sudo vgs VG #PV #LV #SN Attr VSize VFree ubuntu-vg 1 1 0 wz--n- <198.00g 100.00gVFree 也有 100G 了。空间已经成功传到 VG 层。
第 4 步:扩 LV + 扩文件系统
$ sudo lvextend -l +100%FREE -r /dev/ubuntu-vg/ubuntu-lv第 5 步:df -h 最终验证
$ df -h /Filesystem Size Used Avail Use% Mounted on/dev/mapper/ubuntu--vg-ubuntu--lv 195G 20G 168G 11% /完成。
3.4 LVM 验证命令大全(务必形成肌肉记忆)
你前面提到验证特别重要,问 lvscan 好不好用——lvscan 能用,但它信息太少(只列出 LV 路径和大小一行)。生产中应该按从下到上、每层一个命令的顺序验证。下面这套是建议固定记住的:
lsblk | lsblk -f | ||
pvs | pvdisplay | PSizePFree(空闲) | |
vgs | vgdisplay | VFreeFree PE(决定还能不能扩) | |
lvs | lvdisplay | LSize | |
| 文件系统 | df -h | df -hT | Size(用户真正能用的空间) |
记住三句话,胜过记一堆命令:
扩之前,先 vgs看VFree—— 没有空闲空间,lvextend必然失败。每扩一层,立刻验证那一层 —— pvresize后查pvs,vgextend后查vgs,lvextend后查lvs。哪一层数字没变,问题就卡在那一层,立刻能定位。最后一定以 df -h收尾 —— 它是唯一能证明"用户真的有空间可用"的命令。lvs变大但df没变,就是只扩了容器没扩内容,等于白做。
四、磁盘分区工具详解:fdisk / gdisk / parted
场景 B 和 C 都绕不开"建分区 / 改分区"。这一章把三个主流工具讲清楚。
4.1 先搞清楚 MBR 和 GPT
分区之前,磁盘上要先有一张分区表。分区表有两种格式,直接决定你该用哪个工具:
| 2TB 上限 | ||
| 新盘、大盘、数据盘一律用 GPT |
怎么看自己的盘是哪种? 用 fdisk -l 看 Disklabel type 那一行,或 parted /dev/sda print 看 Partition Table 那一行:
$ sudo fdisk -l /dev/sdaDisk /dev/sda: 200 GiB ...Disklabel type: gpt ← 这里写 gpt 或 dos(=MBR)工具与分区表的对应关系:
fdisk—— 老牌工具。早期只支持 MBR;新版本(util-linux 2.23 以后,现代发行版都满足)已经同时支持 MBR 和 GPT。交互式菜单。gdisk—— GPT 专用(名字就是 GPT fdisk)。操作界面和 fdisk 几乎一样,专治 GPT 盘。parted—— 全能型,MBR/GPT 都支持,还能脚本化(非交互),有独有的resizepart可以直接调分区大小。
一句话选型:现代系统、GPT 盘,fdisk 新版或 parted 都行;纯 GPT 操作想要更专业的提示用 gdisk;想脚本化、想直接 resize 用 parted。
⚠️ 改分区前的铁律:分区操作有风险,删错、改错分区会丢数据。在线扩容生产环境前,务必先确认目标设备名(再三核对
lsblk输出),重要数据先备份。
4.2 fdisk 实操
用法一:在新盘上建一个分区(场景 B)
$ sudo fdisk /dev/sdb进入交互界面后,常用命令字母:
m | |
p | |
n | |
d | |
t | |
w | |
q |
新建分区的完整交互(敲 n):
Command (m forhelp): nPartition type p primary (0 primary, 0 extended, 4 free) e extendedSelect (default p): p ← 选主分区,直接回车Partition number (1-4, default 1): 1 ← 分区号,回车用默认First sector (2048-104857599, default 2048): ← 起始扇区,回车用默认(重要)Last sector, +/-sectors or +/-size{K,M,G,T,P}: ← 结束位置,回车=占满全盘Created a new partition 1 of type'Linux' and of size 50 GiB.把分区类型改成 LVM(敲 t):
Command (m forhelp): tSelected partition 1Hex code or alias (type L to list all): 8e ← MBR 的 LVM 类型码是 8eChanged type of partition 'Linux' to 'Linux LVM'.类型码说明:MBR 下
8e= Linux LVM,83= Linux 普通文件系统。GPT 下对应是8e00和8300。 严格说,分区类型码只是个"标签/约定",即使不改8e,pvcreate也能成功。但强烈建议改——它让lsblk -f、其他管理员一眼就知道这分区归 LVM 用,避免误操作。
最后写入:
Command (m forhelp): wThe partition table has been altered.Syncing disks.敲完 w 才算数。 在 w 之前你做的一切都还在内存里,敲 q 就全部撤销——这其实是个安全网,操作过程中发现敲错了,q 退出重来即可。
用法二:扩大一个已有分区(场景 C,fdisk 的"删了重建"大法)
这是 fdisk 一个反直觉但必须知道的点:现代 fdisk 没有"resize 分区"功能。要扩大一个已有分区,办法是——删掉它、再用同样的起始扇区重新建一个更大的。
听起来吓人,但只要起始扇区不变,分区上的数据不会动(分区表只是记录"从哪到哪"的元数据,数据本身在原地)。
$ sudo fdisk /dev/sdaCommand (m forhelp): p ← 先打印,把 sda3 的 Start 扇区号抄下来!!.../dev/sda3 4198400 209719296 ... ← 记住 Start = 4198400Command (m forhelp): d ← 删除Partition number (1-3, default 3): 3Partition 3 has been deleted.Command (m forhelp): n ← 重建Partition number (3,4, default 3): 3First sector (..., default ...): 4198400 ← 必须填回刚才记下的那个数!Last sector ...: ← 回车,占满到磁盘新的末尾此时会跳出一个最关键的提示:
Partition #3 contains a ext4 signature.Do you want to remove the signature? [Y]es/[N]o: N ← 必须选 N !!!这里必须输入 N(No)。 选 Y 会清掉文件系统签名,数据就毁了。选 N 保留签名,数据完好。
正因为"删了重建"这套操作步步是坑(起始扇区抄错、签名误删),**生产环境扩已有分区,强烈优先用第 4.5 节的
growpart**,它把这些坑全替你处理好了。fdisk删建法作为原理理解、或没装 growpart 时的备选。
写入退出后,因为 sda3 正在使用中,内核需要被通知刷新分区表(见 4.6 节 partprobe)。
4.3 gdisk 实操
gdisk 是 GPT 专用版的 fdisk,命令字母几乎一样。它有个贴心之处:一进去就报告分区表的健康状况。
$ sudo gdisk /dev/sdbGPT fdisk (gdisk) version 1.0.8Partition table scan: MBR: protective GPT: present ← 确认这是张正常的 GPT 表Found valid GPT with protective MBR; using GPT.Command (? forhelp): n ← 新建分区Partition number (1-128, default 1): 1First sector (...): [回车]Last sector (...): [回车,占满]Current type is 8300 (Linux filesystem)Hex code or GUID (L to show codes, Enter = 8300): 8e00 ← GPT 下 LVM 是 8e00Changed type of partition to 'Linux LVM'Command (? forhelp): w ← 写入About to write GPT data. THIS WILL OVERWRITE EXISTING PARTITIONS!!Do you want to proceed? (Y/N): Ygdisk 的命令字母对照:p 打印、n 新建、d 删除、t 改类型、w 写入、q 放弃退出、? 帮助、v 校验分区表。和 fdisk 基本通用。
4.4 parted 实操
parted 的最大优势:有 resizepart,不用"删了重建"就能直接把分区改大。
$ sudo parted /dev/sda(parted) print ← 查看分区表,确认分区号Model: ...Disk /dev/sda: 215GBPartition Table: gptNumber Start End Size File system Name 3 2150MB 105GB 103GB(parted) resizepart 3 100% ← 把 3 号分区直接扩到磁盘 100%(parted) print ← 再打印确认 End/Size 变了(parted) quitparted 的常用子命令:print 查看、mklabel gpt/mklabel msdos 建分区表、mkpart 建分区、rm 删分区、resizepart 调整分区大小、quit 退出。
⚠️ 注意:
parted的某些操作是即时写入、没有"先在内存里攒着"的机制,敲下去就生效,不像 fdisk 有w这道关。所以用parted操作要更谨慎,每一步先
4.5 growpart:云时代的省心首选
前面反复推荐它,这里集中说。growpart 专门干一件事:把指定分区的边界扩展到能用的最大空间。它的优势是把 fdisk 删建法的所有坑都内部处理了——不用记起始扇区、不会误删签名、还自动刷新分区表。
$ sudo growpart /dev/sda 3CHANGED: partition=3 start=4198400 old: size=205520896 end=209719296 new: size=415236063 end=419434463返回值含义:
CHANGED—— 分区成功扩大。NOCHANGE: partition 3 is size=... it cannot be grown—— 分区已经是满的,没空间可扩了。报"unable to..."类错误 —— 多半是设备名或分区号写错了,重新核对 lsblk。
AWS 官方文档特别提醒:
growpart /dev/sda 3里设备名和分区号之间必须有空格,它们是两个参数。写成growpart /dev/sda3会失败。
4.6 partprobe:让内核重新认识分区表
一个容易被忽略、但对"在线"成败至关重要的点:
你用
fdisk/parted改了一块正在被使用的磁盘的分区表后,内核不会立刻知道。它脑子里还是旧的分区布局。这时候你直接pvresize会发现"分区大小没变"。
解决办法是通知内核重读分区表,三选一:
$ sudo partprobe /dev/sda # 最常用$ sudo partx -u /dev/sda # 等价,更新分区表$ sudo blockdev --rereadpt /dev/sda用 growpart的话,这一步它自动做了,你不用管。用 fdisk/parted手动改分区,这一步绝对不能漏。漏了的典型症状就是"分区表改了,但后续命令死活看不到新空间,重启后才好"——而需要重启,"在线"就破功了。
4.7 云平台扩容后常见的警告提示,逐条解释
在云控制台 / 虚拟化平台把磁盘改大之后,进系统用 parted 或 fdisk 一看,常常会跳出一串警告。很多人第一反应是"出错了",其实绝大多数都不是错误,而是分区工具在如实告诉你:"我发现盘和分区表对不上了。" 这一节把最常见的几条集中解释。
根因只有一个:你把磁盘容量改大了,但磁盘上那张分区表(尤其是 GPT)里记录的还是旧的容量。盘大了、表没跟上,于是工具一打开就察觉到这个不一致,并提示你。这正是「场景 C」的典型现象,遇到它说明你判断对了——盘确实变大了。
提示一:parted 的 Fix / Ignore 询问
$ sudo parted /dev/vda print freeWarning: Not all of the space available to /dev/vda appears to be used,you can fix the GPT to use all of the space (an extra 62914560 blocks)or continue with the current setting?Fix/Ignore?含义:parted 发现"磁盘真实大小"比"GPT 表里记录的大小"大,多出来的部分就是 an extra ... blocks(这里 62914560 × 512 字节 ≈ 30 GiB,正是你新增的空间)。Fix:把 GPT 分区表更新成磁盘的真实大小,并把存在盘尾的那份 GPT 备份表挪到新的盘尾。只动分区表元数据,不碰任何分区里的数据,安全。** Ignore**:这次不修,按旧记录继续。该选哪个:扩容场景**必须选 Fix**。不修的话,GPT 表仍以为盘只有旧大小,后续growpart想把分区往后扩时会被这张过时的表挡住,认为后面没有空间。
提示二:fdisk 的 GPT PMBR size mismatch
$ sudo fdisk /dev/vdaGPT PMBR size mismatch (20971519 != 83886079) will be corrected by write.含义:和提示一是同一件事——盘和 GPT 表大小不一致。 20971519是表里的旧大小,83886079是磁盘的真实大小。关键看后半句 will be corrected by write:fdisk 不像 parted 那样停下来问你,而是直接告诉你"等你执行w(write)写入时,我会顺手帮你修正"。这是 fdisk 和 parted 的风格差异,不是错误。
提示三:fdisk 的 backup GPT table is not on the end
The backup GPT table is not on the end of the device.This problem will be corrected by write.含义:GPT 在盘首和盘尾各存一份分区表。盘变大后,原来在"旧末尾"的那份备份表就不在末尾了。 **同样看 will be corrected by write**:fdisk 会在写入时把备份表移回新的盘尾。无需手动干预。
提示四:fdisk 的 This disk is currently in use
This disk is currently in use - repartitioning is probably a bad idea.It's recommended to umount all file systems, and swapoff all swappartitions on this disk.含义:这一条才是真正提醒你留意的,但它也不是"出错了"。意思是 /dev/vda是正在使用中的系统盘(根分区在上面),fdisk 出于谨慎提醒"动正在用的盘有风险"。怎么理解:fdisk 无法判断你想做哪种操作,所以一律提醒。要分清两种情况—— 如果你要删分区、重构分区表:那确实危险,这条提醒很对,应先卸载。 如果你只是把最后一个分区往后扩大(场景 C 要做的事):在线扩是成熟可行的,配合之后的 partprobe通知内核即可完成,不必卸载根分区。
小结:一张速查表
Fix/Ignore? | Fix | |
GPT PMBR size mismatch ... will be corrected by write | w 写入时自动修 | |
backup GPT table is not on the end | w 写入时自动修 | |
This disk is currently in use |
最省心的建议:既然这些 GPT 提示在
parted/fdisk上反复出现,**场景 C 扩分区干脆别手动操作,直接用growpart**:
growpart会把上面这些事——修正 GPT、移动备份表、扩分区、通知内核——全部一次性、自动、安全地处理掉,你不会面对任何Fix/Ignore或 in-use 提示。这也是 AWS 官方文档对在线扩分区的推荐做法。fdisk删建法在 4.2 节讲,是为了让你理解原理;真正动手,growpart才是首选。
五、文件系统扩容:ext / xfs / btrfs
这是分层链路的最顶层、也是最后一步。必须先确认文件系统类型,再选命令——用错命令会直接报错。
先确认类型:df -hT 或 lsblk -f,看 FSTYPE / Type 列。
resize2fs | 设备路径/dev/sda1) | |||
xfs_growfs | 挂载点/) | 不能,xfs 只能扩不能缩 | ||
btrfs filesystem resize |
5.1 ext 系列:resize2fs
$ sudo resize2fs /dev/mapper/ubuntu--vg-ubuntu--lv参数给设备路径,不是挂载点。 不带大小参数 = 自动扩满整个设备。也可指定 resize2fs /dev/xxx 50G扩到指定大小。输出里看到 on-line resizing required和The filesystem ... is now XXXX blocks long就是成功。常见报错 Bad magic number in super-block—— 说明这个设备根本不是 ext 文件系统,类型看错了,回头df -hT重新确认。
5.2 xfs:xfs_growfs
$ sudo xfs_growfs / # 参数是挂载点# 或者写设备也行,加 -d 扩到最大:$ sudo xfs_growfs -d /参数给挂载点( /、/data),不是设备路径——这点和resize2fs正好相反,是最容易搞混的地方。xfs 必须在挂载状态下扩,而且只能扩、永远不能缩。CentOS/RHEL 7 以后根分区默认就是 xfs,这条务必记牢。 常见报错 xxx is not a mounted XFS filesystem—— 挂载点写错了,或这个文件系统不是 xfs。data size unchanged, skipping—— 文件系统已经是满的了,没东西可扩(通常意味着前面某一层没扩到位)。
5.3 btrfs
$ sudo btrfs filesystem resize max / # max = 扩到最大$ sudo btrfs filesystem resize +20G / # 或增加 20Gbtrfs 用挂载点,支持在线扩、也支持在线缩,用 max 关键字一步扩满。日常服务器用得比 ext4/xfs 少,了解即可。
省事提醒:第三章里
lvextend加-r参数,会自动识别文件系统类型并调用上面对应的工具,等于把本章这一步合并掉了。本章单独拎出来讲,是为了让你理解"它到底替你做了什么",以及当你需要手动操作(比如非 LVM 场景)时知道怎么选。
六、普通分区扩容(非 LVM)
如果 lsblk 的 TYPE 列完全没有 lvm,那就是普通分区结构。云服务器官方镜像(AWS AMI、阿里云、腾讯云)的根盘绝大多数都是这种。
链路短:磁盘 → 分区 → 文件系统,没有 PV/VG/LV 那三层。
6.1 典型场景:云服务器根盘扩容
你在云控制台把云盘从 50G 扩到 100G。进系统后:
第 1 步:lsblk 确认
$ lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTSnvme0n1 259:0 0 100G 0 disk ← 盘已经 100G└─nvme0n1p1 259:1 0 50G 0 part / ← 但分区还是 50G特征:磁盘 100G,分区 50G,差 50G;TYPE 列没有 lvm。
云上设备名注意:新一代实例多是 NVMe 接口,盘叫
nvme0n1,它的第 1 个分区叫nvme0n1p1(中间有个p)。老式的叫xvda/xvda1(没有p)。growpart的分区号就是设备名最后那个数字。
第 2 步:扩展分区(growpart)
$ sudo growpart /dev/nvme0n1 1CHANGED: partition=1 start=4096 old: size=104853471 end=104857567 new: size=209711070 end=209715166(设备名 /dev/nvme0n1 和分区号 1 之间有空格。)
验证:
$ lsblknvme0n1 259:0 0 100G 0 disk└─nvme0n1p1 259:1 0 100G 0 part / ← 分区也 100G 了第 3 步:确认文件系统类型
$ df -hT /Filesystem Type Size Used Avail Use% Mounted on/dev/nvme0n1p1 ext4 49G 8G 39G 17% / ← Type 列:ext4第 4 步:扩展文件系统(按类型选命令)
ext4(Ubuntu、Amazon Linux 2、RHEL 常见):
$ sudo resize2fs /dev/nvme0n1p1xfs(Amazon Linux 2023、部分 RHEL 常见):
$ sudo xfs_growfs -d /第 5 步:df -h 最终验证
$ df -h /Filesystem Size Used Avail Use% Mounted on/dev/nvme0n1p1 98G 8G 86G 9% /完成。可以看到普通分区扩容就两步实质操作:growpart 扩分区 + resize2fs/xfs_growfs 扩文件系统。
6.2 普通分区 vs LVM,差异小结
| 不能 | 能 | |
vgextend 把新盘并进来即可 | ||
| 能 | ||
所以那句常见的"不用 LVM 就没法在线扩容"是错的。普通分区照样在线扩。LVM 的价值在灵活:加盘、跨盘、快照、空间在多个 LV 间调配——不在"能不能在线"。
七、速查表 & 避坑清单
7.1 一图流速查(按"变化从哪层来"选路径)
用 lsblk 起手,先回答:TYPE 列有没有 lvm?│├─ 没有 lvm(普通分区)│ growpart 扩分区 → resize2fs / xfs_growfs 扩文件系统 → df -h 验证│└─ 有 lvm(LVM 结构)→ 再看 vgs 的 VFree │ ├─ VFree 不为 0(场景 A) │ lvextend -l +100%FREE -r → df -h 验证 │ ├─ 加了新盘 / 有未分区空间(场景 B) │ 建分区 → pvcreate → vgextend → lvextend -r → df -h 验证 │ └─ 老磁盘自己被改大了(场景 C) growpart 扩分区 → pvresize → lvextend -r → df -h 验证7.2 命令速查表
lsblklsblk -f | |
df -hT | |
growpart /dev/sdX N | |
fdiskgdisk / parted | |
partprobe /dev/sdX | |
pvcreate /dev/sdXN | |
pvresize /dev/sdXN | |
vgextend VG名 /dev/sdXN | |
lvextend -l +100%FREE -r /dev/VG名/LV名 | |
resize2fs /dev/设备 | |
xfs_growfs 挂载点 | |
pvsvgs / lvs | |
df -h |
7.3 避坑清单(每条都是真实翻车点)
**永远先 lsblk**,再三核对设备名。在/dev/sda上做的操作,敲成/dev/sdb就是灾难。lvextend之后必须扩文件系统(用-r自动做,或手动resize2fs/xfs_growfs)。只lvextend不扩文件系统 =lvs变大但df没变 = 白做。每扩一层,立刻验证那一层。哪层数字没动,问题就在那层。 **场景 C 别忘 pvresize**。分区扩了但vgs没空闲空间,十有八九是漏了它。**手动改分区后必须 partprobe**。用growpart则不用,它自动做了。** fdisk删建分区时,起始扇区必须填回原值;"是否移除签名"必须选N**。怕出错就改用growpart。xfs 只能扩不能缩。需要缩容的场景,规划阶段就别选 xfs。 扩文件系统前先确认类型。ext 用 resize2fs给设备路径,xfs 用xfs_growfs给挂载点,搞反了直接报错。缩容(reduce)远比扩容危险,必须卸载、必须备份,本文只讲扩容。生产环境能不缩就不缩。 任何分区操作前,重要数据先备份。在线扩容虽然成熟,但磁盘操作没有"绝对安全"。
7.4 的 LVM命令速查表
LVM 命令是高度规律的,三件套全是这个模式:
pv | pv | pv | |
vg | vg | vg | |
lv | lv | lv |
记住这张表,你不仅记住了 lvextend,还顺手记住了整套 LVM 命令。**"层名 + 动作"是 LVM 的命名公约**。
lvextend用法实用的两种写法只有这两个,记住即可:
-l +100%FREE # 把 VG 里剩下的全给我-L +20G # 给我多加 20G结语
回到开头那个核心模型——存储是分层的,扩容就是从变化的那一层开始,逐层把"变大了"往上推到文件系统。
本文看着内容多,其实就一套方法:
lsblk起手,判断有没有 LVM、变化从哪层来。顺着分层链路,从起点那一层开始,逐层执行对应命令。 每过一层就验证一层,最后用 df -h收尾确认。
把这套"分层 + 逐层验证"的思路吃透,你就不再需要背命令——遇到任何新环境,lsblk 一看,自己就能推导出该走哪几步。这才是这篇教程真正想留给你的东西。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 从 Windows 到 Linux 的那道坎
- 推断示例:记忆控制器核心逻辑(Python 3.8+, torch>=1.12)
- 99个Python语法知识点
- Python字典操作的时间空间复杂度与底层原理深度解析
- 【Python入门】Python中字符串相关拓展
- Linux 最新资讯 20260523——RHEL 10.2 发布,新增AI命令行辅助; systemd 261-rc1 发布,含 OS Installer、IMDS 子系统及新 storagectl
- 这个霸总会Python(3/14)- “金融黑洞 "
- Linux 防火墙 firewalld 实战配置
- 10 个 Linux 运维神器脚本
- 如何用Python实现报表自动化?一篇教会你(附案例)
