由于借助 AI 工具学习编程已经变得非常容易了,因此之后的课程就不再默认进行视频讲解了,如果特别需要视频讲解也可以联系李老师预约讲解~讲义材料学习过程中遇到的问题也可以及时与李老师联系。
购买 RStata 名师讲堂会员即可参加该课程啦(之前的和未来的都可以参加)!
价格:2800/年 或者 4800/长期
购买会员可以从这里下单:https://rstata.duanshu.com/#/card/list/
名师讲堂会员权益:
- 参加平台上的其他 R 语言和 Stata 的课程;
- 以会员折扣价购买我们分享的数据资料(10 元/份);
* 如果发票可添加小编微信 r_stata2 (RStata 李老师)开具。如需数据资料,购买后可添加小编微信免费领取数据折扣卡。
更多关于 RStata 会员的更多信息可添加微信号 r_stata2 咨询:

课程主页(点击文末的阅读原文即可跳转):https://rstata.duanshu.com/#/brief/course/ba3a14585f3f4ee4af29333510b956eb
本次课程在原始 CD 指数(Funk & Owen-Smith, 2017)的基础上,介绍徐照宜等(2023)在《金融研究》上发表的改进算法:ACD 指数和 mACD 指数。改进的核心是解决"从未被引用专利"的歧义问题,以及调整分母以更好地反映专利的突破性。
本课程提供 Python 版本 的完整实现,通过 reticulate 包在 R Markdown 中调用 Python,与 R 语言版本计算结果完全一致。
附件中提供了相关论文 PDF 和计算代码。
一、背景:原始 CD 指数及其问题
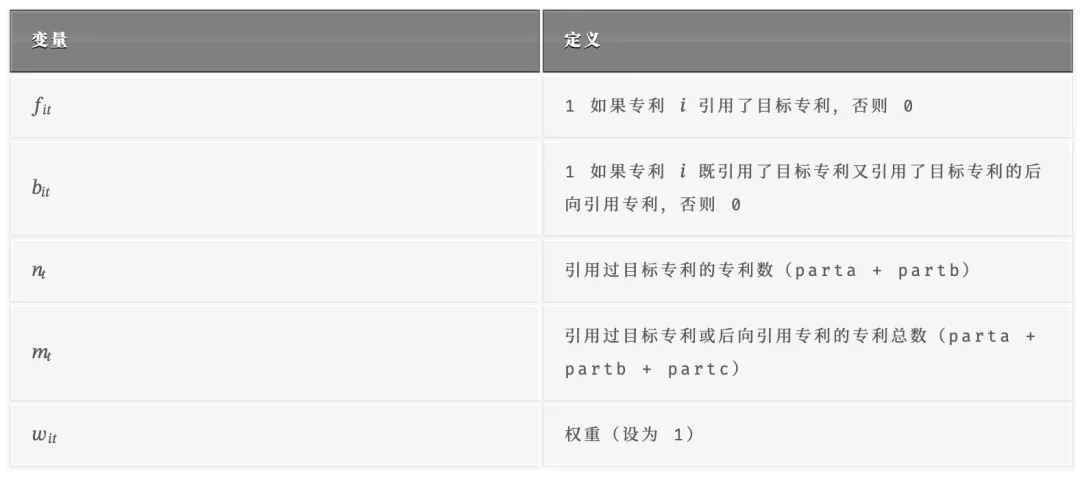
1.1 CD 指数公式
CD 指数由 Funk & Owen-Smith (2017) 提出,用于衡量专利的创新突破程度:
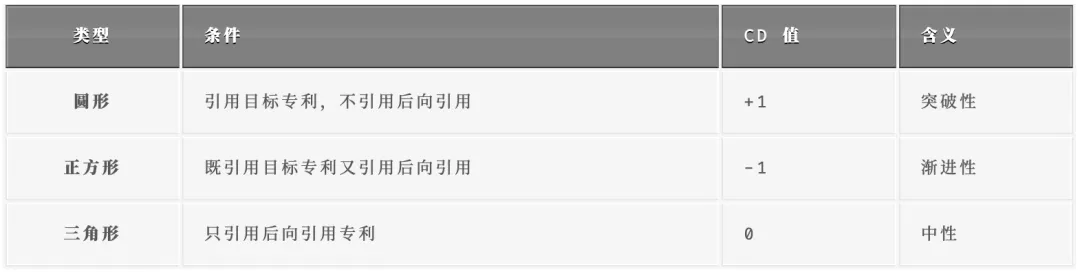
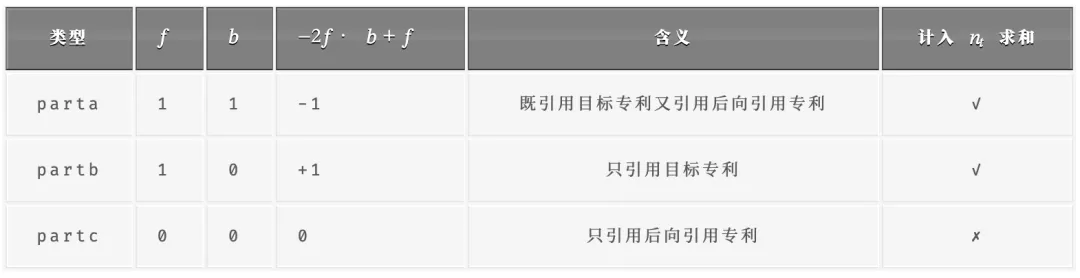
1.2 三种引用情况的 CD 值
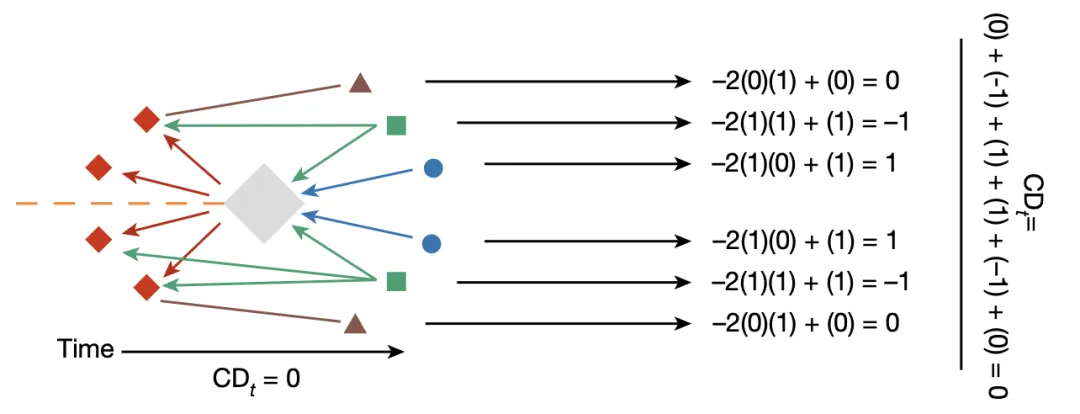
论文中的示意图如下:
三、使用 reticulate 创建与管理 Python 虚拟环境
在 R 中通过 reticulate 包来调用 Python,最好的实践是为项目创建一个专属的 Python 虚拟环境,将所需依赖隔离到独立空间,避免与系统 Python(如 Anaconda)发生版本冲突。
重要说明(避免"已初始化"报错):reticulate 在 R 会话中只能绑定一次 Python——一旦某个 {python} 代码块运行,Python 解释器就被锁定,之后再调用 use_virtualenv() 会报错:
ERROR: The requested version of Python cannot be used, as another version has already been initialized.因此,虚拟环境的激活必须在所有 {python} 代码块之前完成。本文档的解决方案是在 setup chunk 中通过 Sys.setenv(RETICULATE_PYTHON = ...) 提前锁定 Python 路径,这是 reticulate 选取 Python 的最高优先级入口。
3.1 安装 reticulate(仅首次)
# 设置 CRAN 镜像(knit 时 R 处于非交互模式,不会自动选择镜像)options(repos = c(CRAN = "https://mirrors.tuna.tsinghua.edu.cn/CRAN/"))# 仅在尚未安装时才安装,避免每次 knit 都重装if (!requireNamespace("reticulate", quietly = TRUE)) { install.packages("reticulate") message("reticulate 安装完成!") message("reticulate 已安装,版本:", packageVersion("reticulate"))3.2 虚拟环境初始化原理(已在 setup chunk 中完成)
本文档的 setup chunk(隐藏运行)包含如下逻辑:
.venv_python <- virtualenv_python(.venv_name)if(!file.exists(.venv_python)){ virtualenv_create(.venv_name) .venv_python <- virtualenv_python(.venv_name)# 通过环境变量抢先锁定 Python(优先级最高,早于任何 {python} chunk)Sys.setenv(RETICULATE_PYTHON = .venv_python)use_virtualenv(.venv_name, required =TRUE)3.3 在虚拟环境中安装 Python 包(仅首次)
py_pkgs <- c("numpy", "pandas")installed <- py_list_packages(".venv")$packageneed_install <- setdiff(py_pkgs, installed)if (length(need_install) > 0) { virtualenv_install(".venv", packages = need_install) message("已安装缺失的包:", paste(need_install, collapse = ", ")) message("所有 Python 包已就绪,无需安装")3.4 验证激活状态
# 验证当前绑定的 Python 路径(应指向 .venv 目录)3.5 虚拟环境管理常用命令
# virtualenv_remove(".venv")# virtualenv_install(".venv", packages = "pandas", ignore_installed = TRUE)四、数据来源与处理过程
4.1 原始数据
本课程使用的数据来源于中国专利数据库,包含 1985-2024年 上市公司申请的专利及其引用关系数据。
4.2 数据文件说明
本 Python 版本使用从 R 版本 RDS 文件转换的 CSV 格式数据:
处理方法可以参考 R 语言版本的课程。另外这三个文件已经可以用来计算全部上市公司 ACD 和 mACD 指数了,无需额外再处理了。
| | | |
|---|
patent_citations2.csv | | newipzlid, newipzlid2, date, date2 | |
nobackrefs.csv | | | |
patents_with_citations.csv | | | |
变量说明:
newipzlid:引用专利的ID(申请日的专利)newipzlid2:被引用专利的ID(被引用的专利)
4.3 数据读取
读取本课程提供的处理后数据:
patent_citations2 = pd.read_csv(DATA_DIR / "patent_citations2.csv")print(f"专利引用数据行数: {len(patent_citations2):,}")patent_citations2['date'] = pd.to_datetime(patent_citations2['date'])patent_citations2['date2'] = pd.to_datetime(patent_citations2['date2'])sspat = pd.read_csv(DATA_DIR / "2010年上市公司与专利数据匹配结果.csv")print(f"上市公司专利数: {len(sspat):,}")nobackrefs = pd.read_csv(DATA_DIR / "nobackrefs.csv")print(f"无后向引用专利数: {len(nobackrefs):,}")print(patent_citations2.head())专利引用数据的变量说明:
newipzlid2:被引用专利的ID(被引用方)
五、计算示例
5.1 单个专利的计算逻辑
以某个专利为例,详细展示 ACD 和 mACD 的计算过程:
target_patent = patent_citations2[patent_citations2['newipzlid2'] == patent_id]步骤 1:获取后向引用专利
步骤 4:计算三种情况的专利集合
parta = len(part1_set & part2_set) # 既引用目标又引用后向引用partb = len(part1_set - part2_set) # 只引用目标专利partc = len(part2_set - part1_set) # 只引用后向引用专利print(f"parta (既引用目标又引用后向引用): {parta}")print(f"partb (只引用目标专利): {partb}")print(f"partc (只引用后向引用专利): {partc}")步骤 5:计算 n_t 和 m_t
- n_t = parta + partb(引用目标专利的专利数)
- m_t = parta + partb + partc(引用目标专利或后向引用专利的专利总数)
m_t = parta + partb + partc步骤 6:计算 ACD 和 mACD
5.2 封装计算函数
将上述逻辑封装成函数,方便批量计算:
test_result = calc_patent_acd_macd(20190809613, patent_citations2)六、批量计算与多线程优化
6.1 筛选需要计算的专利
并非所有专利都需要计算。如果某个专利没有后向引用,则所有引用它的专利都落在 partb,ACD = 2:
nobackrefs_ids = set(nobackrefs['newipzlid2'].tolist())all_cited_patents = set(patent_citations2['newipzlid2'].unique())patents_with_backrefs = all_cited_patents - nobackrefs_idsprint(f"无后向引用专利数: {len(nobackrefs_ids):,}")print(f"有后向引用专利数: {len(patents_with_backrefs):,}")6.2 批量计算
读取上市公司专利数据,只计算需要计算的专利:
sspat_ids = set(sspat['newipzlid'].unique())need_calc_ids = list(sspat_ids & patents_with_backrefs)print(f"需要计算的有后向引用的上市公司专利数: {len(need_calc_ids):,}")test_ids = need_calc_ids[:10] result = calc_patent_acd_macd(pid, patent_citations2)results_df = pd.DataFrame(results)print(results_df.to_string(index=False))6.3 多线程计算
由于计算量较大,使用多线程加速(需在独立脚本中执行):
注意:在 Rmd 文档中,由于 reticulate 的限制,多线程代码需要在独立的 Python 脚本中执行。以下是多线程脚本的关键代码示例。
七、结果汇总
7.1 合并计算结果
将计算结果与上市公司专利数据合并:
patent_with_backrefs = sspat.merge(print(f"有后向引用的上市公司专利数: {len(patent_with_backrefs):,}")7.2 结果展示
print(results_df.to_string(index=False))7.3 统计汇总
print("\n=== ACD 统计 ===")print(results_df['ACD'].describe())print("\n=== mACD 统计 ===")print(results_df['mACD'].describe())7.4 公司层面汇总
将专利层面的 ACD/mACD 汇总到公司-年份层面:
八、附件说明
本课程提供了以下附件:
8.1 数据文件
| | |
|---|
patent_citations2.csv | | 推荐使用 |
nobackrefs.csv | | |
patents_with_citations.csv | | |
8.2 代码文件
| |
|---|
acd_macd.py | |
计算ACD_mACD.py | |
计算ACD_mACD_多线程.py | |
合并汇总ACD_mACD.py | |
8.3 参考文件
| |
|---|
金融科技、数字化转型与企业突破性创新——基于全球专利引用复杂网络的分析_徐照宜.pdf | |
pic1.png | |
8.4 直接运行 Python 脚本
如果不想在 Rmd 中运行,也可以直接使用终端执行 Python 脚本:
cd"使用 Python 语言测算专利的创新突破度:ACD指数和mACD指数"九、参考文献
Funk, R. J., & Owen-Smith, J. (2017). A dynamic network measure of technological change. Management Science, 63(12), 4174-4187.
徐照宜, 巩冰, 陈彦名, 成程. 金融科技、数字化转型与企业突破性创新——基于全球专利引用复杂网络的分析[J]. 金融研究, 2023(10): 47-65.
如何参加课程?
购买 RStata 名师讲堂会员即可参加该课程啦(之前的和未来的都可以参加)!
价格:2800/年 或者 4800/长期
购买会员可以从这里下单:https://rstata.duanshu.com/#/card/list/
名师讲堂会员权益:
- 参加平台上的其他 R 语言和 Stata 的课程;
- 以会员折扣价购买我们分享的数据资料(10 元/份);
* 如果发票可添加小编微信 r_stata2 (RStata 李老师)开具。如需数据资料,购买后可添加小编微信免费领取数据折扣卡。
更多关于 RStata 会员的更多信息可添加微信号 r_stata2 咨询:

课程主页(点击文末的阅读原文即可跳转):https://rstata.duanshu.com/#/brief/course/ba3a14585f3f4ee4af29333510b956eb









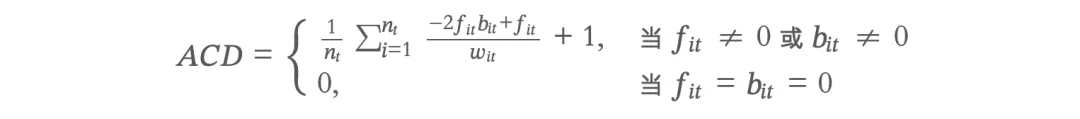
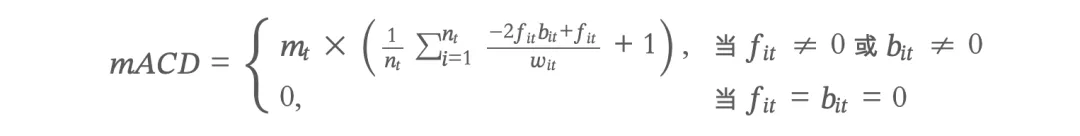
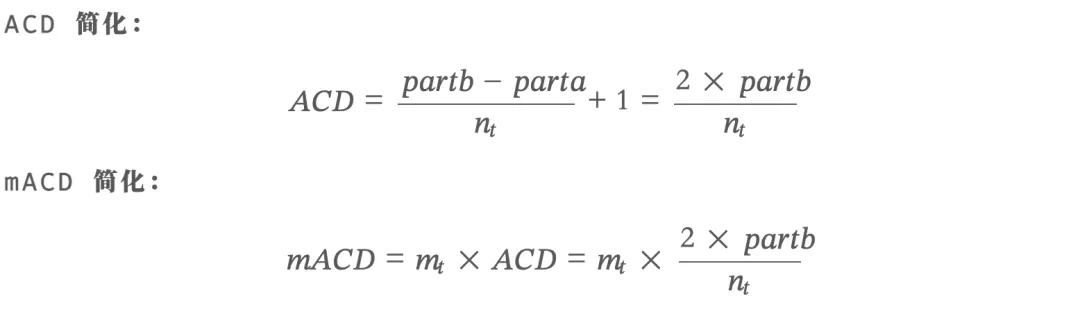

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
