第一章 DMA-BUF 出现的背景
1.1 Linux 多媒体子系统的数据拷贝问题
早期 Linux 驱动架构中,不同硬件模块之间的数据交换往往依赖用户空间进行中转。例如 Camera 采集图像后,先通过 V4L2 驱动拷贝到用户空间,然后 GPU 再从用户空间重新拷贝到显存完成渲染,最后显示控制器再从 GPU 获取数据输出到屏幕。整个过程中数据会发生多次 CPU copy,不仅消耗内存带宽,还会导致严重 cache flush 与上下文切换开销。
对于高清视频场景,这种问题尤其明显。以 4K YUV420 视频为例,单帧数据量已经达到数 MB,如果 Camera、GPU、VPU、Display 之间频繁 copy buffer,系统内存带宽会迅速耗尽。很多 ARM SoC 的 DDR 带宽本身就有限,因此视频 pipeline 往往会因为 buffer copy 导致丢帧、延迟抖动甚至系统卡顿。
Linux 内核早期缺乏统一的跨设备 buffer sharing 机制。不同厂商通常会自行实现私有 buffer framework,例如 Android ION、OMAP TILER、NVIDIA NvMap 等。但这些方案缺乏统一接口,不同 driver 无法协同工作,导致 Linux 多媒体生态长期碎片化。
1.2 DMA-BUF 的设计目标
DMA-BUF 的核心目标,是在不同设备之间实现“零拷贝共享内存”。它允许一个设备分配 DMA buffer,然后将该 buffer 导出给其他设备使用。整个过程中不需要用户空间 copy 数据,也不需要重新分配物理内存。
DMA-BUF framework 本质上是一套 Linux 内核中的 buffer ownership 与 sharing 机制。它定义了 exporter、importer、attachment、reservation object、fence 等统一模型,从而让 GPU、V4L2、DRM、Codec、ISP、Display 等 subsystem 可以共享同一块 DMA memory,例如典型视频链路:
Camera ISP ↓DMA-BUF Export ↓GPU Import ↓Display Import
整个过程中,buffer 始终只有一份物理内存。不同硬件模块共享同一块 buffer,从而避免多次 copy。这也是现代 Linux 多媒体系统实现高性能 pipeline 的基础。
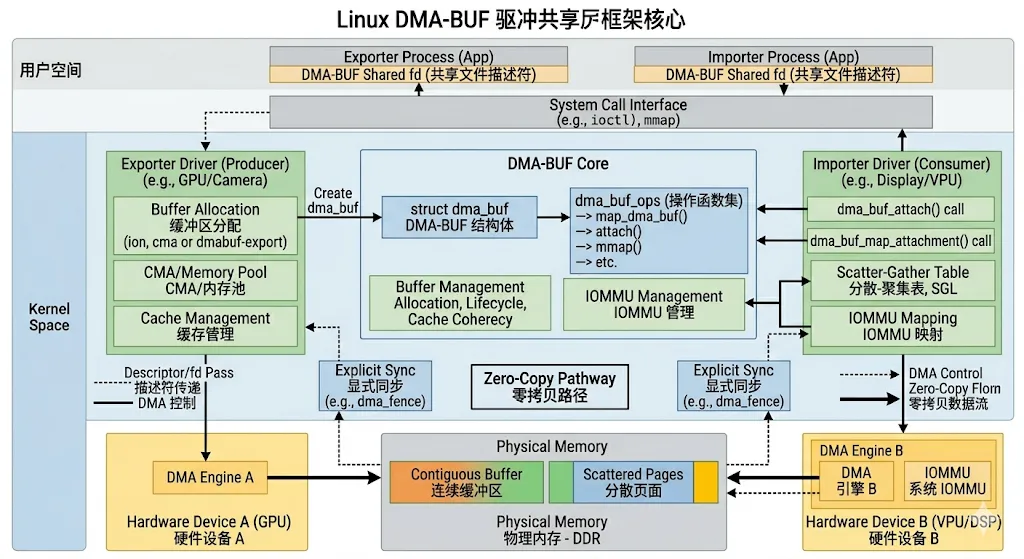
第二章 DMA-BUF 核心架构
2.1 Exporter 与 Importer 模型
DMA-BUF framework 的核心是 exporter/importer 架构。Exporter 负责分配与导出 buffer;Importer 负责接收并使用 buffer。通常 Camera、DRM GEM、ION、CMA allocator 等属于 exporter,而 GPU、Display、Codec 等则可能作为 importer,Linux 内核通过 struct dma_buf 抽象共享 buffer:
struct dma_buf { size_t size; struct file *file; const struct dma_buf_ops *ops; struct list_head attachments; struct reservation_object *resv;};
其中 file 用于向用户空间导出 fd;attachments 用于记录所有 importer;ops 则定义 exporter 提供的操作接口。DMA-BUF 本质上是基于 file descriptor 的共享机制,因此用户空间可以像传递普通 fd 一样在不同进程间传递 DMA buffer
Camera Driver ↓dma_buf_export() ↓fd = dma_buf_fd() ↓Userspace IPC ↓GPU Driver ↓dma_buf_get(fd)
这种设计极大增强了 Linux 多媒体 pipeline 的灵活性。
2.2 DMA-BUF 生命周期
DMA-BUF 生命周期主要包括:创建、导出、附加、映射、同步、释放几个阶段。Exporter 首先分配 DMA memory,然后创建 dma_buf;用户空间通过 fd 获取 buffer handle;Importer 通过 dma_buf_get() 获取引用;随后 importer attach 到 buffer,并完成 DMA mapping,典型流程:
Allocate DMA Memory ↓dma_buf_export() ↓dma_buf_fd() ↓Userspace Pass FD ↓dma_buf_get() ↓dma_buf_attach() ↓dma_buf_map_attachment() ↓DMA Access ↓dma_buf_unmap_attachment() ↓dma_buf_detach() ↓dma_buf_put()
Linux 使用引用计数管理 dma_buf 生命周期。只要仍有 importer 使用 buffer,对应物理内存就不会释放。这种设计保证了 buffer sharing 的安全性。
第三章 DMA-BUF 内存映射机制
3.1 Scatter-Gather Table
DMA-BUF 最大特点之一,是它并不要求 buffer 必须物理连续。Linux 内核通常通过 sg_table 描述 DMA buffer 的物理页面布局。
struct sg_table { struct scatterlist *sgl; unsigned int nents; unsigned int orig_nents;};
scatterlist 本质上是物理页链表。对于 CMA allocator,buffer 可能是连续物理内存;但对于 system heap 或 page allocator,buffer 往往由离散页面组成。DMA-BUF framework 统一通过 sg_table 向 importer 描述 buffer。
Importer 在 dma_buf_map_attachment() 阶段,会获取 sg_table,并调用 dma_map_sg() 完成 IOMMU 或 DMA address mapping。最终设备实际访问的是 DMA address,而不是 CPU virtual address。
3.2 IOMMU 与 DMA-BUF
现代 ARM SoC 大量使用 IOMMU。DMA-BUF 与 IOMMU 的结合,使不同设备能够使用统一虚拟 DMA 地址访问共享 buffer,例如 GPU 与 VPU 可能拥有不同 IOMMU domain:
CPU VA ↓Physical Memory ↓IOMMU Mapping ↓GPU IO VA ↓VPU IO VA
虽然底层物理内存相同,但不同设备看到的 DMA address 可能完全不同。因此 DMA-BUF attachment 阶段非常关键。每个 importer 都需要独立建立 DMA mapping,Linux 内核通过 dma_buf_attachment 保存 importer 的 mapping 信息:
struct dma_buf_attachment { struct device *dev; struct sg_table *sgt;};
attachment 本质上就是 exporter 与 importer 之间的桥梁。
第四章 DMA-BUF 同步机制
4.1 Cache Coherency 问题
DMA-BUF 共享 buffer 最大的复杂性之一,是 cache coherency。CPU 与 DMA device 往往拥有独立 cache hierarchy。如果缺乏同步机制,就可能出现数据不一致。
例如 CPU 修改 buffer 后,数据仍停留在 CPU cache 中,而 GPU DMA engine 直接读取 DDR,此时 GPU 看到的可能是旧数据。同样 GPU 写入 buffer 后,CPU cache 也可能仍然保留旧 cacheline。
Linux DMA API 提供了 dma_sync_single_for_cpu() 与 dma_sync_single_for_device() 等接口,但 DMA-BUF 场景更加复杂,因为多个设备可能同时访问同一 buffer。因此 DMA-BUF framework 内部必须维护统一同步模型。
4.2 Fence 与 Reservation Object
Linux DMA-BUF 使用 reservation object 与 fence 实现 buffer synchronization。Fence 本质上是一个异步完成对象,用于表示 DMA operation 是否结束。
例如 GPU rendering 尚未完成时,Display controller 不能立即扫描 framebuffer,否则可能发生 tearing 或读取脏数据。因此 Display 必须等待 GPU fence signal,Linux fence 机制如下:
struct dma_fence { spinlock_t *lock; const struct dma_fence_ops *ops; ktime_t timestamp; unsigned seqno;};
reservation object 则用于管理 buffer 上的 fence:
struct reservation_object { struct dma_fence __rcu *fence;};
当 importer 使用 buffer 前,会等待相关 fence signal。这样 Linux 就能实现 GPU、VPU、Display 之间的 pipeline synchronization。
第五章 DMA-BUF 与 DRM 子系统
5.1 GEM 与 DMA-BUF 的关系
Linux DRM subsystem 是 DMA-BUF 最重要的使用者之一。DRM 中的 GEM(Graphics Execution Manager)负责 GPU buffer 管理,而 DMA-BUF 则负责跨设备共享,GPU 通常首先创建 GEM object:
struct drm_gem_object { size_t size; struct dma_buf *dma_buf;};
随后通过 drm_gem_prime_export() 导出为 DMA-BUF。这样 V4L2、Display、Codec 等 subsystem 就能共享 GPU buffer,例如 Android SurfaceFlinger 的典型 pipeline:
Camera ↓DMA-BUF ↓GPU Composition ↓DRM KMS ↓Display Controller
整个图形栈几乎完全依赖 DMA-BUF 实现 zero-copy。
5.2 PRIME Buffer Sharing
DRM PRIME 是 DRM subsystem 基于 DMA-BUF 实现的 buffer sharing framework。它允许不同 GPU driver 甚至不同 subsystem 共享 framebuffer,例如:
fd = drmPrimeHandleToFD(fd_dev, gem_handle, DRM_CLOEXEC, &prime_fd);
随后其他subsystem 即可import:gem_handle = drmPrimeFDToHandle(fd_dev, prime_fd);
PRIME 本质上只是 DRM 对 DMA-BUF 的封装。它真正解决的问题,是不同 DRM device 之间的 buffer interoperability。
现代 Linux 图形系统,包括 Wayland、Android、ChromeOS,大量依赖 PRIME + DMA-BUF 完成图像共享。
第六章 DMA-BUF 与 V4L2
6.1 V4L2 Buffer Sharing
V4L2 是 Linux 视频采集核心框架,而 DMA-BUF 则是现代 V4L2 pipeline 的关键组成部分。Camera ISP 输出的视频帧,通常直接导出为 DMA-BUF,然后交给 GPU 或 VPU 继续处理,V4L2 中常见 memory type 包括:
V4L2_MEMORY_MMAPV4L2_MEMORY_USERPTRV4L2_MEMORY_DMABUF
其中 DMABUF mode 专门用于 buffer sharing。应用层可以通过 VIDIOC_QBUF 提交 DMA-BUF fd:
buf.memory = V4L2_MEMORY_DMABUF;buf.m.fd = dmafd;
此时 V4L2 driver 不再自行分配 buffer,而是直接使用外部 DMA-BUF。
6.2 Camera Zero-Copy Pipeline
现代 Camera pipeline 几乎全部基于 DMA-BUF。例如 Android Camera HAL 中,ISP 输出 buffer 后,不会 copy 到用户空间,而是直接共享给 GPU 或 Codec,典型流程如下:
Sensor ↓ISP ↓DMA-BUF Export ↓GPU Import ↓OpenGL Texture ↓Display
整个 pipeline 中数据始终停留在 DMA buffer 中,CPU 仅负责控制逻辑。这也是现代手机能够实现 4K/8K 视频实时处理的重要原因。
如果没有 DMA-BUF,CPU memory copy 将成为整个 pipeline 最大瓶颈。
第七章 DMA-BUF Heap 机制
7.1 Android ION 的历史问题
Android 早期大量依赖 ION allocator 管理 multimedia buffer。ION 提供 system heap、carveout heap、CMA heap 等多种 allocator,但其架构长期存在问题,首先 ION 属于 Android 私有 framework,与 upstream Linux 不兼容;其次 heap abstraction 过于复杂,不同 vendor 大量扩展私有 heap,导致 fragmentation 严重。此外 ION 与 DMA-BUF 耦合方式也不够标准。
所以 Linux 社区最终推动 DMA-BUF Heaps 替代 ION。Android 新版本已经逐步移除 ION。
7.2 DMA-BUF Heap 架构
DMA-BUF Heaps 本质上是标准化 DMA allocator framework。不同 heap 提供统一 fd-based allocation interface。
/dev/dma_heap/system/dev/dma_heap/system-uncached/dev/dma_heap/cma
用户空间可以直接申请 DMA-BUF:
fd = open("/dev/dma_heap/system", O_RDWR);ioctl(fd, DMA_HEAP_IOCTL_ALLOC, &alloc_data);
随后返回 DMA-BUF fd。整个 allocator framework 完全基于 upstream Linux 标准接口,DMA-BUF Heaps 已经成为 Android 与 Linux multimedia stack 的主流 allocator 架构。
第八章 DMA-BUF 内核实现分析
8.1 dma_buf_ops 回调机制
DMA-BUF framework 的核心操作由 dma_buf_ops 定义。Exporter 必须实现这些 callback。
struct dma_buf_ops { int (*attach)(struct dma_buf *, struct dma_buf_attachment *); void (*detach)(struct dma_buf *, struct dma_buf_attachment *); struct sg_table *(*map_dma_buf)( struct dma_buf_attachment *, enum dma_data_direction dir); void (*unmap_dma_buf)( struct dma_buf_attachment *, struct sg_table *, enum dma_data_direction dir);};
Importer attach 时,DMA-BUF framework 会调用 attach callback;设备真正开始 DMA 时,则调用 map_dma_buf() 获取 sg_table,这种 callback-based architecture,使 DMA-BUF 可以兼容各种 allocator 与硬件架构。
8.2 DMA-BUF File Descriptor
DMA-BUF 一个非常巧妙的设计,是将共享 buffer 抽象为匿名 file descriptor。Linux 内核通过 anon_inode_create() 创建匿名 inode,并将 dma_buf 绑定到 struct file,因此用户空间可以直接使用:
dup()sendmsg()poll()close()
等标准 UNIX fd 语义操作 DMA-BUF。这种设计极大简化了跨进程共享模型,例如 Wayland compositor 与 GPU process 之间,就可以通过 UNIX domain socket 直接传递 DMA-BUF fd,而无需额外 IPC protocol,Linux 通过 file descriptor 将 DMA-BUF 自然融入 UNIX object model,这是整个 framework 非常经典的设计之一。
第九章 DMA-BUF 调试与性能分析
9.1 DMA-BUF DebugFS
Linux DMA-BUF framework 提供了丰富调试接口。最常用的是:/sys/kernel/debug/dma_buf/bufinfo,大家可以查看当前系统所有 DMA-BUF:size exporter attachments,这里有exporter 名称、引用计数、映射状态等信息。这对于定位 buffer leak 非常重要。
很多 Android 系统长期运行后内存异常,本质上就是 DMA-BUF 未释放。由于 DMA-BUF 通常属于大块连续内存,因此泄漏后系统很容易出现 CMA exhaustion。
9.2 DMA-BUF 性能瓶颈
虽然 DMA-BUF 解决了 zero-copy 问题,但并不意味着没有性能成本。最大的开销通常来自:
IOMMU MappingCache MaintenanceFence SynchronizationTLB Flush
尤其在高帧率场景下,频繁 map/unmap DMA buffer 可能导致严重 IOMMU TLB flush 开销。因此很多 GPU driver 会缓存 mapping,避免重复建立 IOVA。
还有 cache maintenance 也可能成为瓶颈。对于 non-coherent DMA architecture,大量 dma_sync 操作会严重影响性能。因此现代 ARM SoC 越来越倾向于使用 fully coherent interconnect,DMA-BUF 的本质目标是减少 CPU copy,但整个 pipeline 仍然需要 carefully optimized。
第十章 DMA-BUF 在现代系统中的作用
10.1 Wayland 与 DMA-BUF
Wayland compositor 大量依赖 DMA-BUF 实现图形 buffer sharing。客户端应用渲染 framebuffer 后,直接将 DMA-BUF fd 提交给 compositor,而不需要额外 copy。
App Render ↓DMA-BUF Export ↓Wayland Compositor ↓DRM KMS ↓Display
整个桌面图形栈都建立在 DMA-BUF 之上。这也是 Linux 图形系统能够实现低延迟渲染的重要原因,Mesa、Weston、Chrome、Android SurfaceFlinger 等现代图形系统,实际上都已经深度绑定 DMA-BUF。
10.2 DMA-BUF 的未来发展方向
随着 heterogeneous computing 普及,DMA-BUF 的重要性越来越高。现代 SoC 中,CPU、GPU、NPU、DSP、ISP、Codec 都需要共享大量数据,未来 DMA-BUF framework 发展方向主要包括:
更高效的 fence synchronization更低开销的 IOMMU mapping跨 VM buffer sharing安全隔离机制统一 heterogeneous memory model
尤其在 AI 与边缘计算场景下,大量 tensor buffer 需要在 GPU/NPU/CPU 之间流转。DMA-BUF 很可能进一步扩展,成为 Linux heterogeneous memory sharing 的核心基础设施。
从 Linux 内核整体架构来看,DMA-BUF 实际上代表了一种“统一共享内存抽象”。它不仅仅是 multimedia framework,更是 Linux 在 heterogeneous device memory management 方向的重要演进成果。
建了一个嵌入式Linux技术群,专门聊难题分析和求职面试,欢迎大家一起加入,共同解决工作中的疑难杂症问题