有个周末朋友让我帮他搭一个实时数据看板,我下意识打开了 VS Code 准备写 Flask 路由,结果他丢过来一个链接:“试试这个,不需要懂 HTML。”我带着怀疑点开,十分钟后就把一个带图表、滑块、文件上传的页面跑起来了,全程没写一行 JavaScript。那个库就是 Streamlit。后来凡是要把数据分析结果变成网页的活,我基本都用它搞定。下面聊的全是干货和代码,希望你看完后也能把“写前端”从待办清单里划掉。
先跑起来再说。安装只需要一行:
新建一个 app.py,把下面这些贴进去:
import streamlit as stst.title("数据魔盒")st.write("这个页面全靠一个 Python 脚本撑着。")name = st.text_input("你叫什么名字?", value="探险家")st.write(f"嗨,{name},欢迎来到你的专属数据空间。")if st.button("点我试试"): st.success(f"{name},你刚刚触发了一个交互。")
在终端执行 streamlit run app.py,浏览器会自动打开 localhost:8501,你会看到一个标题、一个输入框、一段问候语和一个按钮。输入名字点按钮,提示信息立刻就变了。整个过程没有任何“请求-响应”的心智负担,你写的仿佛就是一个会持续刷新的脚本。
它到底做了什么?
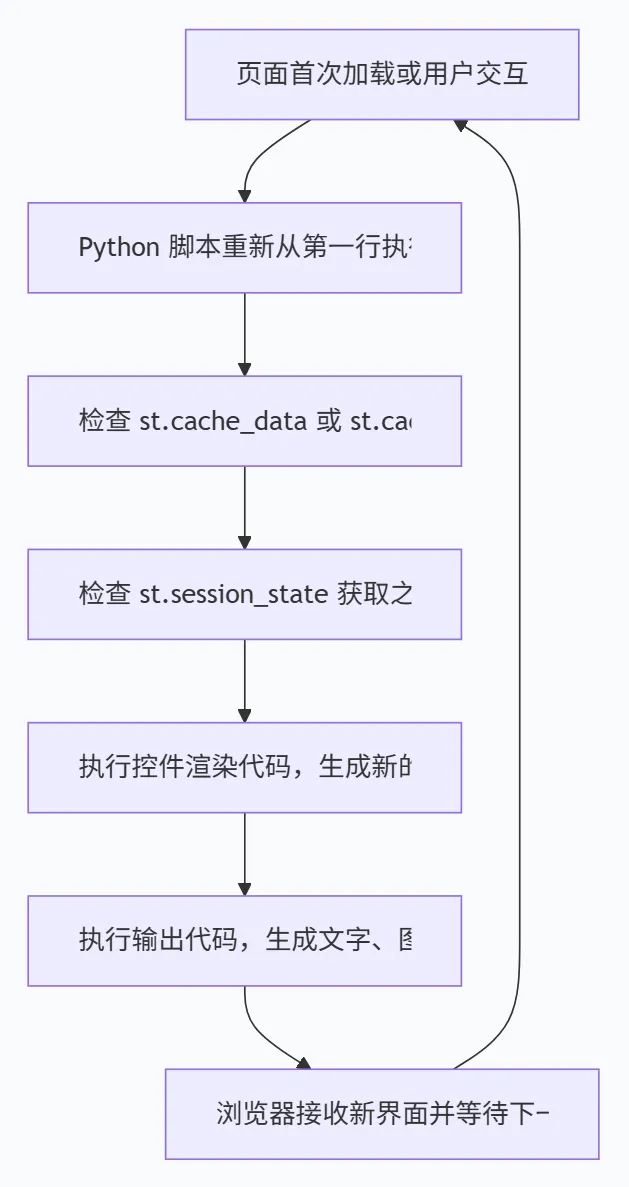
Streamlit 会把你的 Python 脚本从上到下完整执行一次,根据代码里的控件函数画出对应界面。你在页面上动了某个控件,整个脚本就重新执行一遍,新的输出覆盖旧界面。这种“全量重跑”的模式听起来很暴力,但实际上配合缓存和会话状态,既简单又够用。下面这张图概括了一次用户交互触发的完整循环:
这个流程最妙的地方在于,你不必手动维护 DOM 节点和事件绑定,只要专注于用 Python 处理数据就行。
把文本和数据扔到页面上
Streamlit 几乎所有输出都靠那几条命令,写熟了就像在用 print 调试一样自然。
st.markdown("## 今日行情快报")st.markdown("> 市场有风险,投资需谨慎。")st.caption("数据更新于 2026-05-27 14:30")st.code("def buy(): return 'all in'", language="python")st.latex(r"\int_0^\infty e^{-x^2} dx = \frac{\sqrt{\pi}}{2}")
显示 DataFrame 更是家常便饭,直接传过去就能得到一个带排序、搜索的交互表格,完全不需要手动拼 HTML。
import pandas as pdimport numpy as npdf = pd.DataFrame( np.random.randn(100, 3), columns=["收益率", "波动率", "成交量"])st.dataframe(df.style.highlight_max(axis=0))st.metric(label="今日收益", value="+2.38%", delta="0.52%")st.json({"name": "张三", "持仓": ["腾讯", "茅台", "宁德"]})
st.dataframe 会自动识别列类型,数字列还能加颜色条,比很多手写表格舒服多了。
让图表活起来
做数据分析的人手里肯定有 matplotlib 或 plotly 的代码,Streamlit 直接就能吞下这些 figure 对象,原样渲染。
import matplotlib.pyplot as pltimport plotly.express as px# Matplotlib 直方图fig, ax = plt.subplots()ax.hist(np.random.normal(0, 1, 1000), bins=40, color="#4c72b0", edgecolor="white")ax.set_title("收益分布")st.pyplot(fig)# Plotly 交互散点图iris = px.data.iris()fig2 = px.scatter( iris, x="sepal_width", y="sepal_length", color="species", size="petal_length", hover_data=["petal_width"], title="鸢尾花尺寸关系")st.plotly_chart(fig2, use_container_width=True)# Altair 柱状图import altair as altchart = alt.Chart(iris).mark_bar().encode( x=alt.X("species:N", title="品种"), y=alt.Y("count():Q", title="数量"), color="species").properties(width=300)st.altair_chart(chart, use_container_width=True)
三种库你爱用哪个用哪个,生成对象后丢给对应的 st.pyplot 或 st.plotly_chart 就行了。图表自带缩放、悬停提示,完全不需要额外配置。
互动控件:把参数变成会说话的变量
这是我觉得 Streamlit 最爽的地方。你想让用户调整一个阈值、选择一个数据集,只需创建一个控件,返回值就是普通 Python 变量,后面所有计算自动联动。
ticker = st.selectbox("选择股票", ["腾讯控股", "阿里巴巴", "美团"])start_date = st.date_input("起始日期")risk_level = st.slider("风险偏好", 0, 10, 5)show_detail = st.checkbox("显示详细统计")if show_detail: st.write(f"已选 {ticker},风险评分 {risk_level},起始日 {start_date}")uploaded_file = st.file_uploader("上传你的持仓 CSV", type="csv")if uploaded_file: portfolio = pd.read_csv(uploaded_file) st.write("持仓预览:", portfolio.head())
每次动滑块、切换选项,st.write 下方的输出就会立刻更新。你用不着写回调函数,也不用管 DOM 事件,变量自然就变了。
把页面当积木搭:布局、侧边栏、占位符
一个完整的仪表盘不可能只有从上到下的直线排列。用 columns、sidebar、expander 和 empty 可以组合出任何你想要的版式。
# 侧边放所有控制项with st.sidebar: st.header("控制台") display_mode = st.radio("展示模式", ["简洁", "详细", "专家"]) st.divider() st.caption("数据每 5 秒刷新一次")# 主区用三列展示关键指标col1, col2, col3 = st.columns(3)col1.metric("总资产", "¥1,245,600", "3.2%")col2.metric("年化收益", "18.7%", "-0.5%")col3.metric("最大回撤", "12.3%", "1.1%")# 可折叠的原始数据区with st.expander("点击查看原始明细"): st.dataframe(df)# 动态消息占位,可以随时替换或清空msg_placeholder = st.empty()if st.button("显示一条通知"): msg_placeholder.info("数据同步完成,2026-05-27 14:32:10") import time time.sleep(3) msg_placeholder.empty()
st.columns 返回的是三个上下文管理器,你往每个里面扔东西就行。侧边栏 st.sidebar 也一样,所有组件都能直接塞进去。
缓存:让重跑不再慢到崩溃
全量重跑最怕的是反复读大文件或训练模型。Streamlit 用两个简单的装饰器就能把结果缓存下来。
@st.cache_datadef load_market_data(symbol): # 模拟读取 500MB 的 CSV 文件 import time time.sleep(4) df = pd.DataFrame({ "date": pd.date_range("2025-01-01", periods=200), "price": np.cumsum(np.random.randn(200)) + 100 }) return dfdata = load_market_data("腾讯")st.line_chart(data.set_index("date")["price"])
第一次调用会等 4 秒,之后只要传入的 symbol 没变,函数体根本不会执行,直接从缓存取数据。缓存还能根据文件内容变化自动失效,很聪明。
如果缓存的是模型对象,就用 @st.cache_resource,它保证整个会话共享同一个实例:
from sklearn.linear_model import LinearRegression@st.cache_resourcedef get_trained_model(): model = LinearRegression() # 这里可以加载已训练的权重 return modelmodel = get_trained_model()
记住状态:让应用有“记忆”
由于每次交互脚本都重新跑,普通变量会归零。要做一个点击计数的功能,就得靠 st.session_state。
if "count" not in st.session_state: st.session_state.count = 0add = st.button("加一")if add: st.session_state.count += 1st.write(f"累计点击次数:{st.session_state.count}")def reset(): st.session_state.count = 0st.button("归零", on_click=reset)
st.session_state 像一个持久化的字典,在用户会话期间一直存在。你也可以用它来保存多步表单的中间结果,或者实现向导式的交互。
进度条和页面配置
处理耗时任务时,让用户盯着白屏很糟糕。用进度条或 spinner 给个反馈:
import timewith st.spinner("正在拉取实时行情..."): time.sleep(2) # 模拟网络请求st.success("行情已就绪")progress_bar = st.progress(0)for i in range(100): time.sleep(0.01) progress_bar.progress(i + 1)
页面标题、图标、布局宽度也可以通过 st.set_page_config 定死,一般写在脚本最前面:
st.set_page_config( page_title="我的量化终端", page_icon="📈", layout="wide", initial_sidebar_state="collapsed")
如果介意表情符号,可以把 page_icon 换成文字或空字符串,这里为了示范保留了一个股票图标,实际你可以用任何 emoji 或干脆去掉。
部署:把链接甩给别人
本地跑起来只是第一步,想让同事或客户看到,最简单的办法是推送到 GitHub,然后在 share.streamlit.io 上关联仓库,它会自动构建并给你一个公网链接。如果要自己用服务器,一个 Dockerfile 就搞定:
FROM python:3.11-slimWORKDIR /appCOPY requirements.txt .RUN pip install -r requirements.txtCOPY . .EXPOSE 8501CMD ["streamlit", "run", "app.py", "--server.port=8501", "--server.address=0.0.0.0"]
构建并运行:
docker build -t my-dashboard .docker run -p 8501:8501 my-dashboard
你也可以直接丢到 Heroku、阿里云函数计算或者任何能跑 Python 的云平台,只要启动命令是 streamlit run app.py 即可。
写到这里,你手里已经有了一套足以搭建大部分数据分析工具的积木:文本、图表、输入控件、布局、缓存、状态和部署。Streamlit 真正吸引我的不是它有多强大,而是它把我从“先写后端接口再套前端框架”的套路里彻底解放了出来。一个 py 文件,就是你全部的应用。下次遇到需要把数据展示出来的需求,不妨先别急着新建 React 项目,直接用 Streamlit 花半小时跑个原型,说不定连原型都直接能交付。
编辑:余文彬
审校:余雨馨