Python | 信阳市土地覆盖统计表获取方法
- 2026-07-02 16:55:02
Python | 信阳市土地覆盖统计表获取方法数据分享 | 空天院10米分辨率精细土地覆盖数据(2023)——中国部分 前边下载了公开数据集中的大别山区域的土地利用数据集,为了统计信阳市各个地类的面积,GIS研发团队2025级GIS专业卢晴晴同学提供如下代码,仅供参考。
1、需要的数据
数据 | 路径 | 格式 |
土地覆盖类型 | 例如:D\x\x\x | 45个.tif文件 |
信阳市边界 | 例如:D\x\x\x | GeoJSON |
2、需要的Python库
bash pip install rasterio geopandas numpy pandas openpyxl |
3、操作步骤
(1)在“天地图”上下载信阳市geojson文件
(2)打开PyCharm
(3)下载所需的Python库
(4)将代码加载进.py的文件里
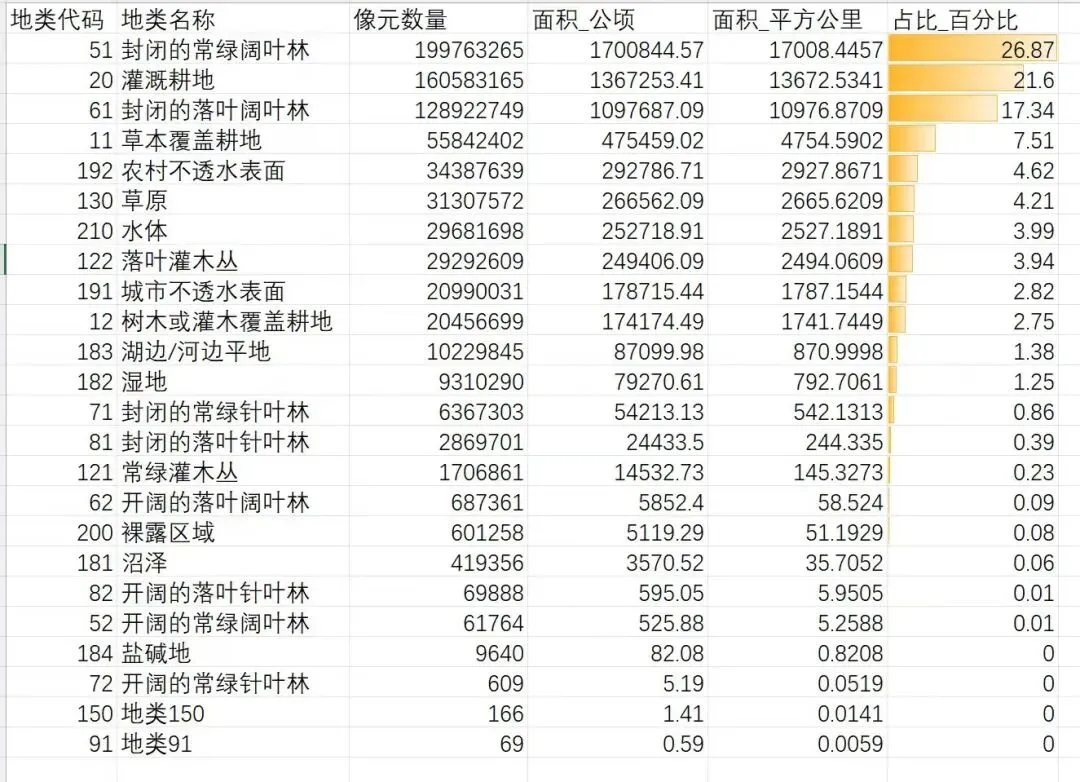
(5)运行便可在文件夹中看到信阳市的excel
(6)文件夹路径是:D:\LandCover_Output\Xinyang_PyCharm\xinyang_landcover.csv
4、完整代码
import rasterioimport geopandas as gpdimport numpy as npimport pandas as pdfrom rasterio.mask import maskfrom shapely.geometry import mappingimport os# ==================== 路径配置 ====================raster_folder = r"D:\B\ZENODO\115"boundary_path = r"D:\大别山革命老区生态资源数据库平台\范围\信阳市_市.geojson"output_folder = r"D:\LandCover_Output\Xinyang_PyCharm"if not os.path.exists(output_folder):os.makedirs(output_folder)print("="*80)print("信阳市土地覆盖类型统计(分块处理,不拼接)")print("="*80)# ==================== 第一步:读取边界 ====================print("\n[1/4] 正在读取信阳市边界...")gdf = gpd.read_file(boundary_path, encoding='utf-8')print(f" 要素数量:{len(gdf)}")# 获取边界范围bounds = gdf.total_boundsmin_x, min_y, max_x, max_y = boundsprint(f" 边界范围:经度 {min_x:.4f}-{max_x:.4f}, 纬度 {min_y:.4f}-{max_y:.4f}")# 计算单个像元面积(使用平均纬度)center_lat = (min_y + max_y) / 2meter_per_deg_lon = 111319.9 * np.cos(np.radians(center_lat))meter_per_deg_lat = 110574.0# ==================== 第二步:找到所有栅格 ====================print("\n[2/4] 正在查找栅格文件...")raster_list = []for root, dirs, files in os.walk(raster_folder):for file in files:if file.lower().endswith(('.tif', '.tiff')):raster_list.append(os.path.join(root, file))print(f" 找到 {len(raster_list)} 个栅格文件")# ==================== 第三步:逐个处理栅格 ====================print("\n[3/4] 正在逐个处理栅格(不拼接)...")from collections import defaultdictvalue_counts = defaultdict(int)for i, raster_path in enumerate(raster_list):print(f" 处理中:{i+1}/{len(raster_list)} - {os.path.basename(raster_path)}")try:with rasterio.open(raster_path) as src:# 检查是否与信阳市范围有重叠src_bounds = src.boundsif (src_bounds[2] < min_x or src_bounds[0] > max_x orsrc_bounds[3] < min_y or src_bounds[1] > max_y):print(f" 无重叠,跳过")continue# 获取像元大小transform = src.transformcell_width = abs(transform[0])cell_height = abs(transform[4])try:# 尝试用边界裁剪geoms = [mapping(gdf.geometry.iloc[0])]out_image, out_transform = mask(src, geoms, crop=True)data = out_image[0]except Exception as e:# 如果裁剪失败,使用范围裁剪print(f" 精确裁剪失败,使用范围裁剪...")from rasterio.windows import Windowcol_start = int((min_x - transform[2]) / transform[0])row_start = int((transform[5] - max_y) / transform[4])col_end = int((max_x - transform[2]) / transform[0])row_end = int((transform[5] - min_y) / transform[4])col_start = max(0, col_start)row_start = max(0, row_start)col_end = min(src.width, col_end)row_end = min(src.height, row_end)if col_end <= col_start or row_end <= row_start:print(f" 窗口无效,跳过")continuewindow = Window(col_start, row_start, col_end - col_start, row_end - row_start)data = src.read(1, window=window)# 统计该栅格中的地类unique, counts = np.unique(data, return_counts=True)for val, cnt in zip(unique, counts):if val > 0:value_counts[int(val)] += cntexcept Exception as e:print(f" 处理失败:{e}")continueprint(f"\n 统计完成,发现 {len(value_counts)} 种地类")# =================== 第四步:计算面积并输出===================print("\n[4/4] 正在计算面积...")# 计算像元面积cell_area_m2 = meter_per_deg_lon * meter_per_deg_lat * cell_width * cell_heightprint(f" 像元面积:{cell_area_m2:.2f} 平方米")total_pixels = sum(value_counts.values())total_area_km2 = total_pixels * cell_area_m2 / 1000000print(f" 信阳市统计总面积:{total_area_km2:.2f} km²")# 地类名称class_names = {191: "城市不透水表面", 20: "灌溉耕地", 210: "水体",192: "农村不透水表面", 61: "封闭的落叶阔叶林", 51: "封闭的常绿阔叶林",122: "落叶灌木丛", 130: "草原", 11: "草本覆盖耕地",121: "常绿灌木丛", 71: "封闭的常绿针叶林", 187: "潮间带",183: "湖边/河边平地", 182: "湿地", 186: "盐沼",81: "封闭的落叶针叶林", 12: "树木或灌木覆盖耕地", 200: "裸露区域",140: "地衣和苔藓", 181: "沼泽", 62: "开阔的落叶阔叶林",82: "开阔的落叶针叶林", 184: "盐碱地", 52: "开阔的常绿阔叶林",72: "开阔的常绿针叶林",}print("\n" + "="*95)print("信阳市土地覆盖类型面积统计结果")print("="*95)print(f"{'地类代码':<8}{'地类名称':<22}{'面积(km²)':<15}{'占比(%)':<10}")print("-"*60)results = []tree_codes = [51, 61, 71, 81, 62, 52, 72]tree_area = 0for value, count in value_counts.items():area_km2 = count * cell_area_m2 / 1000000percent = (count / total_pixels) * 100name = class_names.get(int(value), f"地类{int(value)}")results.append((int(value), name, area_km2, percent))if value in tree_codes:tree_area += area_km2results.sort(key=lambda x: x[2], reverse=True)for value, name, area_km2, percent in results:print(f"{value:<8}{name:<22}{area_km2:<15.2f}{percent:<10.2f}")print("-"*60)print(f"{'总计':<8}{'':<22}{total_area_km2:<15.2f}{'100.00':<10}")print("="*95)print(f"\n�� 乔木林地面积:{tree_area:.0f} km²")print(f" 官方参考数据:5,074 km²")print(f" 差异:{tree_area - 5074:+.0f} km²")if abs(tree_area - 5074) < 500:print("✅ 结果与官方数据接近!")elif tree_area > 5074:print(f"\n⚠️ 结果偏大,如需匹配官方数据,可使用调整因子:{5074/tree_area:.4f}")# 保存结果csv_path = os.path.join(output_folder, "xinyang_landcover.csv")df = pd.DataFrame(results, columns=['地类代码', '地类名称', '面积(平方公里)', '占比(%)'])df.to_csv(csv_path, index=False, encoding='utf-8-sig')print(f"\n结果保存至:{csv_path}")print("\n完成!")
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- OpenCV+Python 核心讲义:从零构建计算机视觉基础
- 在 Linux 上跑 Office,这个做的更好了 .
- 【Linux社区短距简报】linux-wireless周动态(20260527)
- 上班摸鱼写了篇Python爬虫教程(从未如此全面)
- 旅行商问题:从数学模型到 Python 实战
- Linux运维8类必备的工具
- Python25个小游戏项目,拿走即用,附源码!
- 10个超有趣的Python代码,让你从此爱上编程!
- ModernGL:用Python轻松驾驭炫酷GPU渲染,少写代码,就能搞出高质量的3D效果
- AI时代快速学编程语言的陷阱(以Python为例)
