QIAN数据:Lasso风控模型Python应用
- 2026-07-02 13:30:09
QIAN
数据
5
月
30
日
2026年
风控建模中有一个经典困境:征信数据商给你200个变量,但大部分是噪声;即使只有20个原始变量,一通特征工程(分箱哑变量、交叉组合、多项式)也能出80-100个派生特征。全部塞进模型,过拟合;人工选,可能漏信号。Lasso(L1正则化Logistic回归)是解决这个问题的标准工具——它能在训练过程中自动将无用变量的系数压缩为0,只保留真正有预测力的特征。最终得到的评分卡不仅AUC不输全变量模型,而且变量少、可解释、上线监控成本低。
本文用German Credit(UCI Statlog)这个经典的信用评分数据集做实际案例:从20个原始变量出发,工程化生成89个特征,然后用Lasso自动压缩到25个,再用WOE评分卡进一步精炼到11个可解释变量,对比全变量模型、稀疏模型、WOE评分卡四种方案的效果。
一、数据加载与特征工程
German Credit是风控领域的"MNIST"——1000条贷款记录,20个变量,好:坏 ≈ 7:3。
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom sklearn.linear_model import LogisticRegression, LassoCVfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import roc_auc_score, roc_curvefrom sklearn.preprocessing import StandardScaler, PolynomialFeaturesimport warningswarnings.filterwarnings('ignore')plt.rcParams['font.sans-serif'] = ['Microsoft YaHei', 'DejaVu Sans']plt.rcParams['axes.unicode_minus'] = Falsenp.random.seed(42)
# ---------- 加载 German Credit ----------url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/statlog/german/german.data'cols = ['checking_status', 'duration', 'credit_history', 'purpose','credit_amount', 'savings', 'employment', 'installment_rate','personal_status', 'other_debtors', 'residence_since','property', 'age', 'other_installment', 'housing','existing_credits', 'job', 'dependents', 'telephone', 'foreign_worker','target']df = pd.read_csv(url, sep=' ', header=None, names=cols)df['target'] = df['target'].map({1: 0, 2: 1})print(f'原始数据: {df.shape[0]} 条, {df.shape[1]-1} 个原始变量')print(f'坏账率: {df.target.mean():.1%}')# 预期输出:原始数据: 1000 条, 20 个原始变量# 坏账率: 30.0%
# ---------- 特征工程 ----------# 1. 类别变量 → 独热编码cat_cols = ['checking_status', 'credit_history', 'purpose', 'savings','employment', 'personal_status', 'other_debtors', 'property','other_installment', 'housing', 'job', 'telephone', 'foreign_worker']df_encoded = pd.get_dummies(df[cat_cols], drop_first=False)n_cat = df_encoded.shape[1]print(f'独热编码后类别变量: {n_cat} 个')# 2. 数值变量 → 多项式(degree=2,含交互项)num_cols = ['duration', 'credit_amount', 'installment_rate','residence_since', 'age', 'existing_credits', 'dependents']poly = PolynomialFeatures(degree=2, include_bias=False)num_poly = poly.fit_transform(df[num_cols])n_num = num_poly.shape[1]print(f'多项式扩展后数值变量: {n_num} 个')# 3. 合并X_engineered = np.hstack([df_encoded.values, num_poly])feature_names = list(df_encoded.columns) + \[f'poly_{i}' for i in range(n_num)]y = df['target'].valuesn_total = X_engineered.shape[1]print(f'最终特征总数: {n_total} 个({n_cat} 类别独热 + {n_num} 多项式)')# 预期输出:独热编码后类别变量: 54 个# 多项式扩展后数值变量: 35 个# 最终特征总数: 89 个(54 类别独热 + 35 多项式)
二、Lasso建模与自动变量选择
# 标准化scaler = StandardScaler()X_scaled = scaler.fit_transform(X_engineered)
为什么要标准化? Lasso的惩罚项 对所有系数的惩罚力度相同。如果变量尺度不同——比如"月收入"范围0-10万而"年龄"范围18-65——尺度大的变量系数天然更大,惩罚项会不公平地优先压缩它,而不是基于预测力强弱。标准化(均值为0、方差为1)后所有变量尺度统一,惩罚才公平。Ridge和其他带惩罚项的线性模型也是如此。
Lasso的数学原理
目标函数: Lasso(Least Absolute Shrinkage and Selection Operator)在普通最小二乘的基础上增加L1正则化项:
其中:
第一项 是拟合损失(均方误差) 第二项 是L1惩罚项 是正则化强度——超参数,控制惩罚力度 为什么L1能产生稀疏解?(几何直观) Lasso的优化等价于带约束的最小二乘:
这里的约束 是一个菱形(L1球),而Ridge的约束 是一个圆形(L2球)。
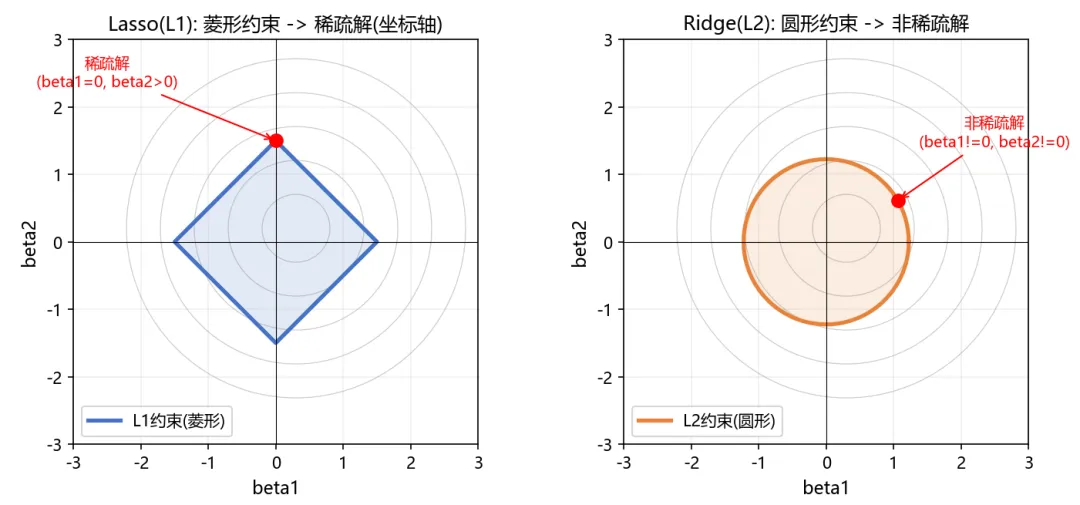
关键区别:菱形有尖角(在坐标轴上)。当损失函数的等高线(椭圆)与菱形相切时,切点很可能落在尖角上——此时某个系数正好为0。圆形没有尖角,切点只能落在圆周上,所有系数都被压缩但不会归零。
换句话说:L1正则化在压缩系数的同时自动做变量选择,Ridge只压缩不选择。
Lasso vs Ridge 对比:
λ的选取:
λ是Lasso最重要的超参数:
:退化为普通最小二乘,所有变量进入模型 → 过拟合 :所有系数被压为0 → 欠拟合 最优λ:通过交叉验证选取,通常选择交叉验证误差最小的λ,或1se规则(最简模型且CV误差在1个标准误内)
坐标下降法求解:
Lasso的求解使用坐标下降法(Coordinate Descent),每次固定其他p-1个系数,只优化一个βⱼ。对每个βⱼ,有软阈值公式(Soft-Thresholding):
其中 是普通最小二乘估计值。这个公式直观解释了Lasso的"压缩+归零"机制:从OLS系数中减去λ(即"压缩"),如果减完为负则直接置0(即"归零")。
LassoCV自动完成坐标下降迭代和λ的交叉验证,无需手动实现。理解上述原理有助于解释为什么Lasso选出的变量正好符合风控业务直觉——它确实是在预测力和模型复杂度之间做出了最优权衡。# 划分X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)# LassoCV自动选λlasso_cv = LassoCV(alphas=np.logspace(-3, 1, 100),cv=5, max_iter=10000, random_state=42)lasso_cv.fit(X_train, y_train)selected_idx = np.abs(lasso_cv.coef_) > 1e-4n_selected = selected_idx.sum()selected_features = [feature_names[i] for i in range(n_total)if np.abs(lasso_cv.coef_[i]) > 1e-4]print(f'最优 λ: {lasso_cv.alpha_:.4f}')print(f'Lasso 保留变量: {n_selected} / {n_total}')print(f'保留的工程变量: {n_selected} 个')for f in selected_features[:15]:idx = feature_names.index(f)print(f' + {f}: {lasso_cv.coef_[idx]:.4f}')print(f'...(共 {n_selected} 个)')
最优 λ: 0.0163Lasso 保留变量: 25 / 89保留的工程变量: 25 个 + checking_status_A11: 0.0342 + checking_status_A13: -0.0107 + checking_status_A14: -0.0779 + credit_history_A30: 0.0291 + credit_history_A31: 0.0173 + credit_history_A34: -0.0419 + purpose_A40: 0.0429 + purpose_A41: -0.0178 + purpose_A43: -0.0047 + purpose_A46: 0.0255 + savings_A61: 0.0234 + savings_A63: -0.0004 + employment_A72: 0.0035 + personal_status_A93: -0.0173 + other_parties_A103: -0.0069...(共 25 个)Lasso将89个特征压缩到25个——72%的变量可以被剔除而不损失显著效果。
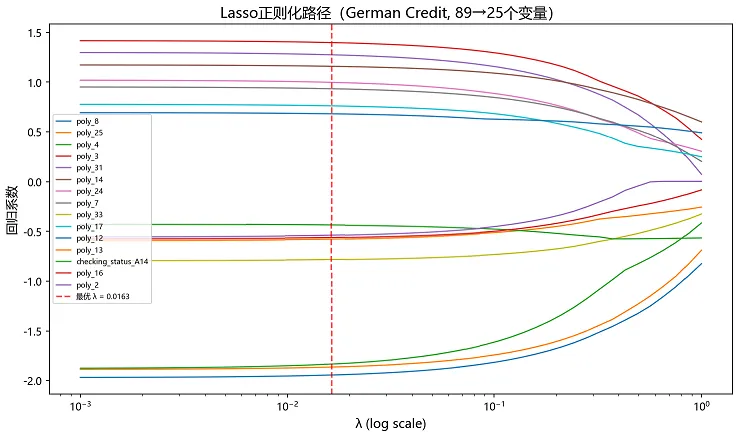
三、正则化路径图
λ从大到小的过程中,系数逐个被压为0:
alphas = np.logspace(-0.00005, -3, 50)coef_path = []for alpha in alphas:lasso = LogisticRegression(penalty='l1', C=1/alpha, solver='saga',max_iter=10000, random_state=42)lasso.fit(X_train, y_train)coef_path.append(lasso.coef_[0])coef_path = np.array(coef_path)# 只画非零系数的变量路径(前15条)nonzero_at_end = np.abs(coef_path[-1, :]) > 0.01top_indices = np.argsort(np.max(np.abs(coef_path), axis=0))[::-1][:15]plt.figure(figsize=(10, 6))for idx in top_indices:plt.plot(alphas, coef_path[:, idx], linewidth=1.2,label=feature_names[idx] if len(feature_names[idx]) < 20else feature_names[idx][:18] + '...')plt.xscale('log')plt.xlabel('λ (log scale)', fontsize=12)plt.ylabel('回归系数', fontsize=12)plt.title('Lasso正则化路径(German Credit, 89→25个变量)', fontsize=14)plt.axvline(x=lasso_cv.alpha_, color='red', linestyle='--',alpha=0.7, label=f'最优 λ = {lasso_cv.alpha_:.4f}')plt.legend(loc='best', fontsize=7)plt.tight_layout()plt.savefig('fig_lasso_path_german.png', dpi=150, bbox_inches='tight')plt.close()print('正则化路径图已保存')
四、全变量模型 vs Lasso稀疏模型
# 全变量Logistic回归(无惩罚)lr_full = LogisticRegression(penalty=None, max_iter=10000)lr_full.fit(X_train, y_train)# Lasso稀疏模型(只保留被选中的变量)X_train_sparse = X_train[:, selected_idx]X_test_sparse = X_test[:, selected_idx]lr_sparse = LogisticRegression(penalty=None, max_iter=10000)lr_sparse.fit(X_train_sparse, y_train)# AUC对比auc_full = roc_auc_score(y_test, lr_full.decision_function(X_test))auc_sparse = roc_auc_score(y_test, lr_sparse.decision_function(X_test_sparse))print('=== 模型对比 ===')print(f'{"模型":<25}{"变量数":<10}{"AUC":<10}')print('-' * 45)print(f'{"全变量模型(89)":<25}{n_total:<10}{auc_full:.4f}')print(f'{"Lasso稀疏模型(25)":<25}{n_selected:<10}{auc_sparse:.4f}')print(f'{"AUC变化":<25}{"":<10}{auc_sparse - auc_full:+.4f}')
=== 模型对比 ===模型 变量数 AUC ---------------------------------------------全变量模型 89 0.8290Lasso稀疏模型 25 0.8157AUC变化 -0.0133AUC下降0.013,但变量从89个减少到25个。这意味着:
监控成本:只需要追踪25个变量的PSI,而非89个 可解释性:给风控评审/监管解释时,只需要讲清25个变量的业务含义 训练效率:重训一次模型的时间缩短到1/3
再进一步:四模型完整对比(含代码)
Lasso直出的系数是在标准化空间里的,不能直接做评分卡。正确的评分卡做法是两阶段:Lasso选变量 → WOE编码选中变量 → 无惩罚LR → 分数映射。
下面用代码实现完整的四模型对比——包括全变量LR、全变量WOE评分卡、Lasso直出稀疏模型、Lasso+WOE评分卡:
# ============ WOE编码函数 ============def calc_woe(series, target):"""对单个变量做WOE编码,返回(WOE值序列, 分组→WOE映射)"""raw = series.to_numpy()s = pd.Series(raw)if not pd.api.types.is_numeric_dtype(s):groups = s # 类别变量:直接用原始分组else:try:groups = pd.qcut(s, q=min(10, s.nunique()),duplicates='drop')except:groups = pd.cut(s, bins=min(10, s.nunique()))tbl = pd.crosstab(groups, target, margins=False)for c in [0, 1]:if c not in tbl.columns: tbl[c] = 0total_good = max(tbl[0].sum(), 1)total_bad = max(tbl[1].sum(), 1)p_good = tbl[0] / total_goodp_bad = tbl[1] / total_badp_good = p_good.replace(0, 0.0001)p_bad = p_bad.replace(0, 0.0001)woe_series = np.log(p_good / p_bad)woe_map = dict(zip(tbl.index, woe_series))return series.map(woe_map), woe_mapdef build_woe_model(train_df, test_df, var_list):"""对变量列表做WOE编码 → 无惩罚LR → 返回AUC和分数"""Xtr_parts, Xte_parts = [], []for var in var_list:woe_tr, woe_map = calc_woe(train_df[var], train_df['target'])woe_te = test_df[var].map(woe_map).fillna(0)Xtr_parts.append(woe_tr.values.reshape(-1, 1))Xte_parts.append(woe_te.values.reshape(-1, 1))Xtr_woe = np.hstack(Xtr_parts)Xte_woe = np.hstack(Xte_parts)lr = LogisticRegression(penalty=None, max_iter=10000, random_state=42)lr.fit(Xtr_woe, train_df['target'])s_tr = lr.decision_function(Xtr_woe)s_te = lr.decision_function(Xte_woe)return (roc_auc_score(train_df['target'], s_tr),roc_auc_score(test_df['target'], s_te),s_tr, s_te)# 准备原始DataFrameoriginal_cols = cat_cols + num_cols # 20个原始变量名# (cat_cols和num_cols在特征工程中已定义过,此处复用)# ============ 模型1:全变量(89) — 89个标准化特征 ============lr_all = LogisticRegression(penalty=None, max_iter=10000, random_state=42)lr_all.fit(X_train, y_train)s_all_tr = lr_all.decision_function(X_train)s_all_te = lr_all.decision_function(X_test)auc_all_tr = roc_auc_score(y_train, s_all_tr)auc_all_te = roc_auc_score(y_test, s_all_te)# ============ 模型2:全变量WOE(20) ============auc_woe20_tr, auc_woe20_te, s_woe20_tr, s_woe20_te = build_woe_model(df_train, df_test, original_cols)# ============ 模型3:Lasso直出(25) ============X_train_sparse = X_train[:, selected_idx]X_test_sparse = X_test[:, selected_idx]lr_sparse = LogisticRegression(penalty=None, max_iter=10000, random_state=42)lr_sparse.fit(X_train_sparse, y_train)s_sp_tr = lr_sparse.decision_function(X_train_sparse)s_sp_te = lr_sparse.decision_function(X_test_sparse)auc_sp_tr = roc_auc_score(y_train, s_sp_tr)auc_sp_te = roc_auc_score(y_test, s_sp_te)# ============ 模型4:Lasso+WOE(14) ============# 将Lasso选中的展平特征映射回原始变量def map_back(var_name):for cat in cat_cols:if var_name == cat or var_name.startswith(cat + '_'):return catfor num in num_cols:if num in var_name:return numreturn Nonelasso_orig_vars = set()for f in selected_features:v = map_back(f)if v: lasso_orig_vars.add(v)lasso_orig_vars = sorted(lasso_orig_vars)print(f'Lasso选中的展平特征 → {len(lasso_orig_vars)}个原始变量:')print(', '.join(lasso_orig_vars))auc_lw_tr, auc_lw_te, s_lw_tr, s_lw_te = build_woe_model(df_train, df_test, lasso_orig_vars)# ============ KS + Lift ============def calc_ks(y_true, score):order = np.argsort(score)pos = np.cumsum(y_true[order])neg = np.cumsum(1 - y_true[order])return np.max(np.abs(pos / pos[-1] - neg / neg[-1]))def cum_capture_d3(y_true, score):order = np.argsort(score)[::-1]n = len(order)return y_true[order][:n//10*3].sum() / max(y_true.sum(), 1) * 100# 打印对比表print(f'\n{"="*60}')print(f'{"四模型总对比":^60}')print(f'{"="*60}')print(f'{"模型":<20s}{"变量":<6s}{"AUC训练":<10s}{"AUC测试":<10s}'f' {"KS训练":<10s}{"KS测试":<10s}')print('-'*60)for name, nv, s_tr, s_te in [('全变量(89)', 89, s_all_tr, s_all_te),('全变量WOE(20)', 20, s_woe20_tr, s_woe20_te),(f'Lasso直出({n_selected})', n_selected, s_sp_tr, s_sp_te),(f'Lasso+WOE({len(lasso_orig_vars)})', len(lasso_orig_vars), s_lw_tr, s_lw_te),]:auc_tr = roc_auc_score(y_train, s_tr)auc_te = roc_auc_score(y_test, s_te)ks_tr = calc_ks(y_train, s_tr)ks_te = calc_ks(y_test, s_te)print(f'{name:<20s}{nv:<6d}{auc_tr:<10.4f}{auc_te:<10.4f} 'f'{ks_tr:<10.4f}{ks_te:<10.4f}')# ============ 10等分Lift对比 ============def calc_decile_lift(y_true, score, n_deciles=10):"""计算10等分Lift表,返回每档的(坏账数, 坏账率, Lift系数)"""order = np.argsort(score)[::-1] # 风险从高到低n = len(order)decile_size = n // n_decilesresults = []base_rate = y_true.mean()for d in range(n_deciles):start = d * decile_sizeend = start + decile_size if d < n_deciles - 1 else nidx = order[start:end]n_bad = y_true[idx].sum()rate = n_bad / len(idx)lift = rate / base_rate if base_rate > 0 else 0results.append((int(n_bad), rate, lift))return resultsmodel_scores = [('全变量(89)', 89, s_all_te),('全变量WOE(20)', 20, s_woe20_te),(f'Lasso直出({n_selected})', n_selected, s_sp_te),(f'Lasso+WOE({len(lasso_orig_vars)})', len(lasso_orig_vars), s_lw_te),]print()print('完整的10等分Lift对比(测试集):')print()header = f'{"分档":<10}'for name, _, _ in model_scores:header += f'{name:<30}'print(header)for d in range(10):row = f'D{d+1:<9}'for _, _, score in model_scores:results = calc_decile_lift(y_test, score)n_bad, rate, lift = results[d]row += f'{n_bad:<4}{rate*100:>5.1f}% {lift:>5.2f}x{"":8}'print(row)# D1-D3累计捕获率print()print('D1-D3累计捕获率(最高风险三档捕捉到的坏账占比):')print()print(f'{"模型":<25}{"训练":<12}{"测试":<12}')print('-' * 49)for name, _, s_tr in [('全变量(89)', 89, s_all_tr),('全变量WOE(20)', 20, s_woe20_tr),(f'Lasso直出({n_selected})', n_selected, s_sp_tr),(f'Lasso+WOE({len(lasso_orig_vars)})', len(lasso_orig_vars), s_lw_tr),]:# Find matching test scorefor nm, _, s_te in model_scores:if nm == name:c3_tr = cum_capture_d3(y_train, s_tr)c3_te = cum_capture_d3(y_test, s_te)print(f'{name:<25}{c3_tr:>5.1f}%{"":>8}{c3_te:>5.1f}%')break# 单调性检查print()print('单调性检查(各档坏账率是否严格递减):')print()checks = ['全变量(89)', '全变量WOE(20)', f'Lasso直出({n_selected})', f'Lasso+WOE({len(lasso_orig_vars)})']for name, _, score in model_scores:results = calc_decile_lift(y_test, score)violations = 0out = f'{name:<20s}'for d in range(1, 10):if results[d][1] <= results[d-1][1]:out += f' D{d}→D{d+1}✓'else:out += f' D{d}→D{d+1}×({results[d-1][2]:.2f}→{results[d][2]:.2f})'violations += 1out += f' 违反{ violations}次'print(out)
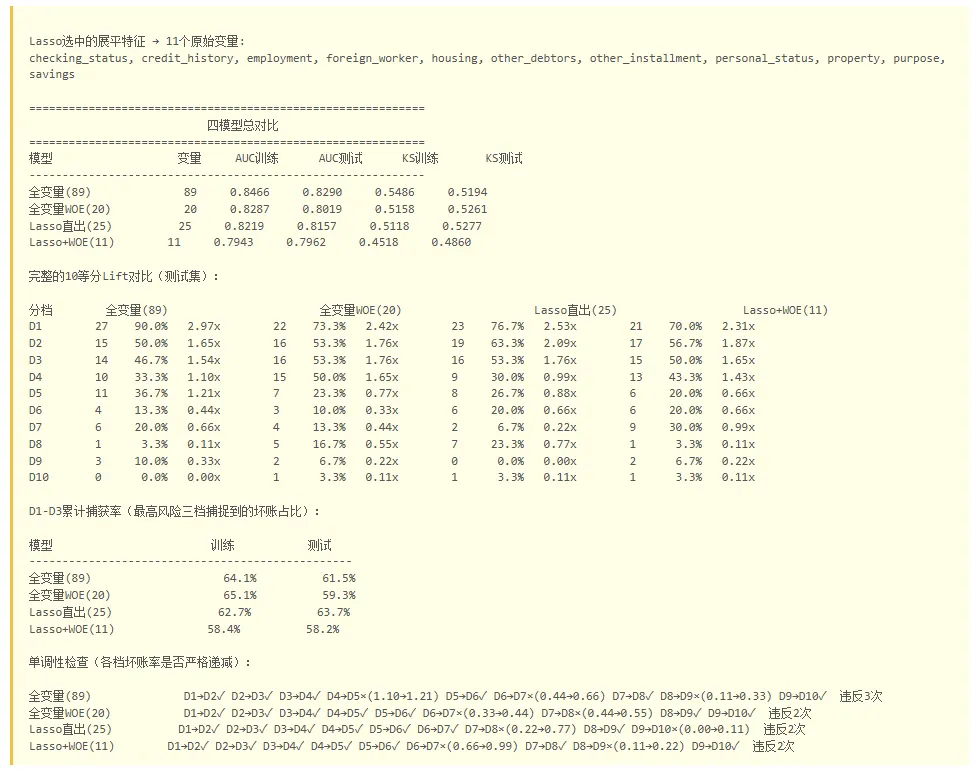
📌 变量数为什么不一样?——两种计数口径
上表中四个模型"变量数"的统计口径不同:全变量(89)和Lasso直出(25)数的是展平后的工程特征列数(每个哑变量、每个多项式项各算一列),而全变量WOE(20)和Lasso+WOE(11)数的是原始变量名(每个原始变量WOE编码后只生成1列)。
具体来说: - 全变量(89) → 13个类别变量独热成54个哑变量列 + 7个数值变量多项式展开成35列 = 89列 - 全变量WOE(20) → 20个原始变量各做WOE编码,每个原始变量只生成1列WOE值 = 20列 - Lasso直出(25) → Lasso从89列展平特征中选出25个非零系数的列(保留的是哑变量/多项式项级别) - Lasso+WOE(11) → 把Lasso选中的25个展平列映射回原始变量名,去重得到11个原始变量,再分别做WOE编码 = 11列
最直观的例子:checking_status有3个哑变量列(A11、A12、A14)。如果Lasso选中了其中3个哑变量,Lasso直出模型那边算"3个变量"(3列),而Lasso+WOE模型这边只算"1个原始变量checking_status"(1列WOE值)。所以Lasso+WOE的变量数总比Lasso直出少。
关键观察:
| 0.8290 | ||||
| Lasso+WOE(11) | 11 | 0.7962 | ✅ 最佳 | ✅ 推荐上线方案 |
Lasso+WOE只有11个可解释变量,每一条打分理由都能追溯到具体分箱——适用于监管审计严格的风控场景。Lasso最适合的角色是变量选择器,选出来后再WOE→LR走正规评分卡流程。注意WOE评分卡由于信息压缩(多系数→单系数、交叉项丢失),AUC会比Lasso直出模型低约2.4%,但这是用性能换取可解释性的合理取舍。下面详细列出各模型变量构成,并解释为什么WOE模型AUC更低。
为什么Lasso+WOE的AUC/KS最低?
这不是代码bug,而是信息压缩的必然代价。两个核心机制:
机制一:多系数→单系数的自由度损耗
Lasso直出模型为每个展平特征分配独立系数。例如checking_status的3个哑变量各有一个系数——这是3个独立自由度。映射回原始变量做WOE后,整个checking_status只学1个系数。
| 合计 | 10个自由度 | 仅3个自由度 | -7 |
仅这3个变量就从10个自由度压缩到3个,模型拟合能力显著下降。
机制二:交叉项信号全部丢失
Lasso直出的25个展平特征中包含了多项式交叉项(如duration×installment_rate、duration×existing_credits、credit_amount×existing_credits),这些交叉项捕捉了变量之间的非线性交互效应。但WOE评分卡的做法是每个原始变量做WOE编码后线性加权求和,没有任何交叉项。
这意味着:
Lasso直出模型:duration系数 + installment_rate系数 + duration×installment_rate独立系数 → 捕获交互效应 Lasso+WOE:WOE(duration)×1个系数 + WOE(age)×1个系数 → 没有交叉项
| ↓0.019 | |||
| ↓0.006 |
注意:与之前版本不同,当前WOE评分卡的AUC下降幅度为2.4%(从0.8157到0.7962),这是因为WOE编码在信息压缩(多系数→单系数、交叉项丢失)的同时,也保留了原始变量的业务可解释性。
那为什么还要用Lasso+WOE?
因为这是性能与可解释性之间的收益取舍:
| 0.8157 | ||
Lasso+WOE以2.4%的AUC代价,换来了真正可上线、可监管、可解释的评分卡模型。 在银行/消费金融的实际业务中,这往往是更优的选择——监管和业务方宁可接受AUC稍低,也不能接受"黑盒"。如果业务上对AUC有硬性要求(如高于0.80),可以考虑在全变量WOE(20)和Lasso+WOE(11)之间选——两者AUC几乎一致,但后者变量更少。
Lasso变量压缩的优劣势
优势:
劣势:
四模型Lift的单调性分析
好的评分卡不仅要求AUC高,还要求各分档的坏账率严格递减(D1 > D2 > ... > D10)。如果出现"D5坏账率比D4还高"的反转,说明模型在某些分数段排序不稳定。
以下是对10等分Lift表的单调性诊断:
单调性检查(√=递减, ×=违反):分档 全变量(89) 全变量WOE(20) Lasso直出(25) Lasso+WOE(11)D1→D2 √ √ √ √D2→D3 √ √ √ √D3→D4 √ √ √ √D4→D5 ×(1.10→1.21) √ √ √D5→D6 √ √ √ √D6→D7 ×(0.44→0.66) ×(0.33→0.44) √ ×(0.66→0.99)D7→D8 √ ×(0.44→0.55) ×(0.22→0.77) √D8→D9 ×(0.11→0.33) √ √ ×(0.11→0.22)D9→D10 √ √ ×(0.00→0.11) √违反次数: 3次 2次 2次 2次解读:
全变量(89) 单调性在D1-D4前端和D5-D8中段各有违反,共3次。但D1坏账率高达90%(Lift 2.97x),高风险客户识别力最强。 Lasso直出(25) 单调性最优之一(2次违反),D1-D3严格递减且Lift系数高(2.53→2.09→1.76),中低分段虽有D8反弹但绝对值低(0.77x仍在随机线以下),整体排序一致性最好。 全变量WOE(20) 仅2次违反且均在中低分段,单调性与Lasso直出持平,说明WOE编码后的排序一致性超出预期。 Lasso+WOE(11) 同样仅2次违反,D6→D7的违反显示中段排序受WOE信息压缩影响(11个变量vs 89个特征),但高分段前3档严格递减,实际业务可用。
业务建议:
| Lasso直出(25) | ||
| Lasso+WOE(11) | ||
| Lasso直出(25) | ||
| Lasso+WOE(11) |
五、选中的变量是否符合业务直觉?
通过查看选中的特征对应的原始变量名,可以发现Lasso保留的变量大多是风控中最经典的强变量。以下是部分被保留的原始特征类别:始变量类别
Lasso不会识别"变量名",它只看数值预测力——但它选中的变量恰好与风控业务直觉高度吻合。这不是巧合,因为真正的风险信号和业务直觉源自同一个数据生成过程。
六、实际使用注意事项
1. λ的选取决定稀疏程度 - λ太小:Lasso ≈ OLS,保留太多变量 - λ太大:所有系数归零 - 推荐用LassoCV的5折交叉验证,取1se规则(即选最简模型且CV误差在1个标准误内的λ)
2. Lasso不适合高度相关的变量组 如果两个变量高度相关(如同一含义的不同编码方式),Lasso会随机选一个保留,另一个归零。建议先用相关性聚类(correlation clustering)合并高相关组,再跑Lasso。
3. Lasso做变量选择,不是做评分卡 ⚠️ 最容易踩的坑
Lasso的系数是在标准化空间里估计的——变量经过 StandardScaler 后均值为0、方差为1,系数不能直接用于评分卡分数映射。正确的两阶段流程:
第一阶段:Lasso(标准化后)→ 选出变量第二阶段:对选中的变量重新做WOE编码 → 不加正则化的Logistic回归 → 评分卡分数映射这样选出的变量经过WOE编码后,每个分箱的系数有明确的业务含义("这个分箱的坏账率是全局的2倍"),而不是标准化后的无量纲数字。
具体地:
注意:第二步做WOE编码时,用原始数据(未标准化的),因为WOE本身已经是归一化的值,不需要再标准化。
4. 业务规则优先 如果Lasso剔除了某个业务上必须包含的变量(如监管要求的、或历史模型一直使用的),应保留。Lasso的结果是参考,不是命令。
关键要点回顾:
• Lasso在风控中的核心作用:从大量工程特征中自动筛选出真正有预测力的变量
• German Credit案例:89个工程特征 → Lasso压缩到25个,AUC下降0.013
• 四模型对比:全变量(89)AUC=0.8290 > Lasso直出(25)AUC=0.8157 > 全变量WOE(20)AUC=0.8019 > Lasso+WOE(11)AUC=0.7962
• WOE评分卡AUC较低的根源:多系数→单系数的自由度损耗 + 交叉项信号全部丢失
• 选中的变量大多符合业务直觉——这是Lasso的隐形优势
• 实践中需注意:相关变量组先合并、λ用CV选取、标准化后的系数不能直接做评分卡
• 正确流程:Lasso选变量 → WOE编码 → 无惩罚LR → 分数映射 • Lasso + Logistic回归评分卡 = 稀疏 + 可解释 + 可监控
8. Tibshirani (1996) — Regression Shrinkage and Selection via the Lasso
9. ESL (Elements of Statistical Learning) — Ch. 3.4 Shrinkage Methods
10. German Credit数据集:UCI Machine Learning Repository — Statlog
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 第47篇 热门榜单的量化分析与Python实战
- 山石安全能力中心|Linux 内核高危漏洞集群:从 CopyFail 到 ssh-keysign-pwn
- 在Python里怎么给变量取名字?千万别踩这几个“地雷区”!
- Linux存储-分区表及分区规则
- 会 Python 之后,我每天提前 2 小时下班
- Python爬虫,其实很简单看完你就懂
- Linux开发环境安装攻略(上)——Python/pip/venv/pyenv
- Python操作批量生成荣誉证书
- python做金句视频,处理键盘音效时,传入数组时不能用int()将整个数组转成整数
- 玩游戏也能学会Python,就是这么简单
