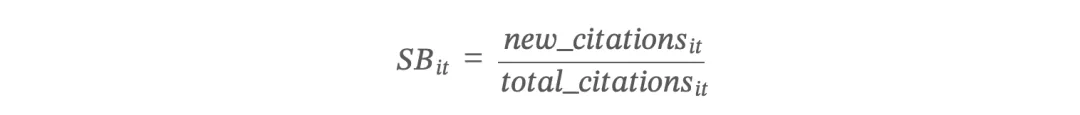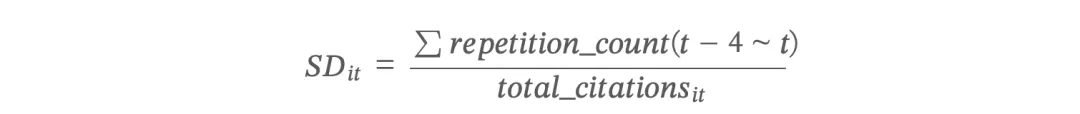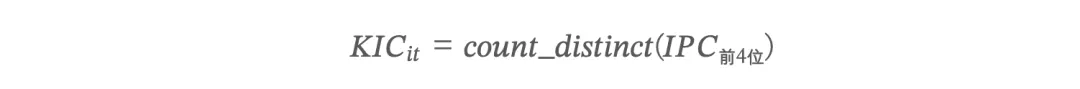今天给大家分享使用 Python 测算企业专利技术集中度(TS)、搜索广度(SB)、搜索深度(SD)及知识整合能力(KIC)的方法。该方法参考自王海花等(2026)《专精特新企业技术专业化与关键核心技术突破》。
附件中提供了该参考文献的 PDF 文件,感兴趣的小伙伴可以阅读原文。
指标来源与计算原理
这四个指标均基于发明专利计算(不含实用新型和外观设计),并采用 5 年滚动窗口 [t−4,t] 构建企业知识库。也就是说,对于观测年份 t,回溯 t−4 至 t 年共 5 年的专利数据进行计算。
技术集中度(TS — Technological Specialization)
技术集中度衡量的是企业技术活动的专业化 vs 多元化程度。核心思想是:如果企业的发明专利高度集中在少数 IPC 技术领域,说明技术专业化程度高;如果分散在众多不同领域,说明技术多元化。
计算分为两步:
搜索广度(SB — Search Breadth)
搜索广度衡量企业对新知识探索的程度。核心思想是:如果企业当年引用的专利中大部分是"新发现"的知识(之前没有引用过的),说明企业正在广泛搜索新知识领域。
其中:
SB 值越大(越接近 1),说明企业正在广泛搜索新知识领域。
搜索深度(SD — Search Depth)
搜索深度衡量企业在已有知识领域中的深化程度。核心思想是:如果企业对同一批专利反复引用,说明企业在特定知识领域持续深耕。
其中,分子是近 5 年窗口 [t−4,t] 内所有被引专利的重复引用次数之总和。
SD 值越大,说明企业对特定知识的挖掘越深入。SB 和 SD 是一对互补指标:SB 衡量"横向拓展"(广度),SD 衡量"纵向深化"(深度)。
知识整合能力(KIC — Knowledge Integration Capability)
知识整合能力反映企业融合多学科知识、进行交叉创新的能力。度量方式为:5 年窗口内,企业涉及的不同 IPC 前 4 位技术类别的去重计数。
KIC 值越大,说明企业跨越了更多不同的技术领域进行创新,跨领域知识整合能力越强。
四个指标对照
Python 环境配置
本课程使用 Python 的 pandas 和 numpy 包进行计算。为了方便不同操作系统的用户,推荐使用 R 语言的 reticulate 包来管理 Python 虚拟环境,macOS / Windows / Linux 操作完全一致。
在 R 控制台依次执行以下代码即可完成配置:
用默认的 Python 环境也完全 OK,这里仅仅是为了避免环境冲突。
# 1. 安装 reticulate 包(仅需一次)install.packages("reticulate")# 3. 新建虚拟环境(仅需一次,环境名可自定义)virtualenv_create("ts-sb-sd-kic")virtualenv_install("ts-sb-sd-kic", c("pandas", "numpy"))use_virtualenv("ts-sb-sd-kic")在 RMarkdown 中,可以在 setup 代码块中激活虚拟环境,后续的 Python 代码块将自动使用该环境:
use_virtualenv("ts-sb-sd-kic")数据准备
本课程使用的演示数据为 2010~2012 年上市公司与专利数据匹配结果(3 年共约 30 万行),其中包含:
- 上市公司与专利数据匹配结果:包含专利的 IPC 分类号、引证专利等字段
- 专利引用与被引用信息:用于 SB 和 SD 的计算
这两个数据可以从下面获取:
1985~2024 年上市公司与专利数据匹配结果(版本3, 含申请、授权信息):https://rstata.duanshu.com/#/brief/course/04100321f88b411f90429be934934bff
1985~2024 的专利引用与被引用信息及次数统计:https://rstata.duanshu.com/#/brief/course/de4968acb01047b3801c200e9cf7ed41
首先读取数据:
# dtype=str:与 R 的 cols(.default = "c") 一致,全部读为字符串# 不设 keep_default_na=False,让 "NA" 自动转为 NaN(与 R 的 read_csv 默认行为一致)"2010~2012年上市公司与专利数据匹配结果.csv",数据去重
专利数据中可能存在重复记录,需要在每家公司内部(企业层面)分别去重。这是因为存在多个公司共同申请同一专利的情况——例如公司 A 和公司 B 联合申请了一项专利,在匹配结果中会分别产生两条记录(同一专利号对应不同公司)。如果跨公司全局去重,会错误地删除其他公司共同申请的专利记录。
因此去重必须加入公司标识符(股票代码),分两轮执行:
- 第一轮:按
股票代码 + 年份 + 公开公告号_clean 去重
# Step 1: 清洗公开公告号(去掉末尾字母,如 CN101862134A → CN101862134)df["公开公告号_clean"] = df["公开公告号"].str.replace(r"[A-Z]$", "", regex=True)# Step 2: 第一轮去重 —— 按公司 + 年份 + 公开公告号_clean# 必须在每家公司内部去重,不能全局去重(存在多公司共同申请专利的情况)df = df.drop_duplicates(subset=["股票代码", "年份", "公开公告号_clean"], keep="first")# Step 3: 第二轮去重 —— 按公司 + 年份 + 申请号df = df.drop_duplicates(subset=["股票代码", "年份", "申请号"], keep="first")# Step 4: 筛选发明专利(TS/SB/SD/KIC 均只用发明专利)df_inv = df[df["专利类型"].notna() & df["专利类型"].str.contains("发明")].copy()df_inv["年份"] = df_inv["年份"].astype(int)# 展开 IPC 字段并提取前4位(如 G06F 3/00 → G06F)# IPC 字段为分号分隔的多个 IPC 分类号,一个专利可能属于多个 IPC 分类df_inv["IPC"] = df_inv["IPC"].replace("NA", pd.NA)df_inv_expanded = df_inv.assign( ipc_list=df_inv["IPC"].str.split(r";\s*")df_inv_expanded["ipc_list"] = df_inv_expanded["ipc_list"].str.strip()df_inv_expanded = df_inv_expanded[ df_inv_expanded["ipc_list"].notna() & (df_inv_expanded["ipc_list"] != "") & (df_inv_expanded["ipc_list"] != "NA")df_inv_expanded["ipc4"] = df_inv_expanded["ipc_list"].str[:4]df_inv_expanded = df_inv_expanded[ df_inv_expanded["ipc4"].notna() & (df_inv_expanded["ipc4"] != "")df_inv = df_inv_expanded.drop(columns=["ipc_list"]).reset_index(drop=True)技术集中度(TS)的计算
对于每家企业的每个观测年 t,使用 [t−4,t] 窗口内的发明专利计算:
defgroup_apply(df, group_col, func):"""对 df 按 group_col 分组后 apply func,返回包含 group_col 的 DataFrame"""for name, group in df.groupby(group_col, sort=False):if res isnotNoneandlen(res) > 0:return pd.concat(results, ignore_index=True)ts_panel = group_apply(df_inv, "股票代码", calc_ts)ts_panel = ts_panel[["股票代码", "年份", "TS", "n_patents_ts"]]上述代码中,calc_ts() 函数首先获取该企业所有的观测年份,然后对每个年份 t,筛选 [t−4,t] 窗口内的发明专利,按 IPC 前 4 位分组统计专利数,计算各组占比后得到变异系数。np.std(pro, ddof=1) 使用 ddof=1 参数与 R 的 sd() 函数保持一致(样本标准差,分母为 n−1)。
group_apply() 是一个辅助函数,用于对每家企业分别计算后正确恢复分组键列(股票代码)。这是因为 pandas 的 groupby().apply() 在新版本中使用 include_groups=False 后,分组列不在返回的 DataFrame 中,需要手动恢复。
搜索广度(SB)的计算
搜索广度的计算需要用到引证专利字段(即企业专利引用了哪些在先专利)。该字段通常是以分号分隔的字符串,需要先展开为逐条记录:
# 展开引证专利字段(一行可能含多个被引专利,用 "; " 分隔)# R 中 read_csv 将 "NA" 自动转为 NA,filter(!is.na(引证专利), 引证专利 != "NA", 引证专利 != "")# 等价于:引证专利 notna() 且 非空字符串且不等于 "NA"][["股票代码", "年份", "申请号", "引证专利"]].copy()# 与 R 的 str_split(引证专利, ";\\s*") + unnest 等价df_cite_raw["cited_list"] = df_cite_raw["引证专利"].str.split(r";\s*")df_cite = df_cite_raw.explode("cited_list")df_cite["cited_patent"] = df_cite["cited_list"].str.strip() df_cite["cited_patent"].notna() & (df_cite["cited_patent"] != "") & (df_cite["cited_patent"] != "NA")df_cite = df_cite[["股票代码", "年份", "申请号", "cited_patent"]].reset_index(drop=True)展开后,对每家企业构建 5 年滚动知识库,判断当年引用是否为"新知识":
sb_panel = group_apply(df_cite, "股票代码", calc_sb)sb_panel = sb_panel[["股票代码", "年份", "total_citations", "new_citations", "SB"]]注意知识库的窗口范围是 [t−4,t−1](不含当年),这是为了确保"新知识"的判定有意义——只有当年引用的专利不在过去 5 年的引用库中时,才被认为是新的知识探索。
搜索深度(SD)的计算
搜索深度考察的是企业在 5 年窗口内对被引专利的重复引用程度:
sd_panel = group_apply(df_cite, "股票代码", calc_sd)sd_panel = sd_panel[["股票代码", "年份", "SD"]]SD 的分母与 SB 相同(当年总引用数),分子是近 5 年内所有被引专利的重复引用次数之总和。例如,某被引专利在 5 年内被该企业引用了 3 次,那么它对分子的贡献就是 3。
知识整合能力(KIC)的计算
KIC 的计算最为简洁,直接统计 5 年窗口内企业涉及的不重复 IPC 前 4 位类别数:
kic_panel = group_apply(df_inv, "股票代码", calc_kic)kic_panel = kic_panel[["股票代码", "年份", "KIC"]]KIC 与 TS 的区别在于:TS 反映的是专利数量在各技术领域的分布均衡性(变异系数),而 KIC 反映的是企业跨越的绝对技术领域数量(去重计数)。
合并四个指标
将四个指标按企业-年度进行左连接合并:
# 以 TS 的企业-年度为基准(发明专利存在的企业年份) sb_panel[["股票代码", "年份", "SB", "total_citations", "new_citations"]],).sort_values(["股票代码", "年份"]).reset_index(drop=True)panel[["TS", "SB", "SD", "KIC"]].describe()panel.to_csv("firm_indicators_panel_python.csv", index=False)输出的面板数据包含以下变量:股票代码、年份、TS、n_patents_ts(窗口内发明专利数)、SB、total_citations(当年总引用次数)、new_citations(新知识引用次数)、SD、KIC。
如果需要全部数据,使用全部年份的上市公司专利数据及专利引用信息数据即可计算。
关联数据推荐
1985~2024 年上市公司与专利数据匹配结果(版本3, 含申请、授权信息):https://rstata.duanshu.com/#/brief/course/04100321f88b411f90429be934934bff
1985~2024 的专利引用与被引用信息及次数统计:https://rstata.duanshu.com/#/brief/course/de4968acb01047b3801c200e9cf7ed41