小七运维手札之Linux内存指标解析与实践
- 2026-07-02 02:45:27
偶然的项目,使用人多次询问Linux系统中内存使用率指标的疑问,包括如何设置可以呈现服务器或业务特点?Linux系统中各内存的价值?内存使用率指标的计算逻辑?当前商用、开源选择的算法是什么等等。
Linux到当前,除了传统的发行版之外,也有各种各样不同的发行版在更新,而对于Linux内存的计算确实也发生了一些变化,而这些变化的调整,会提升运维人员对于系统的运行情况的掌控、了解。
如图,最常见的查看内存数据:

简单描述,存疑可在网上释疑
Total(总内存)
•含义:系统物理内存总量
•计算:直接读取硬件信息
Used(已用内存)
•含义:当前被占用的内存总量
•常规计算:total - free - buff/cache
Free(空闲内存)
•含义:完全未被使用的内存
Shared(共享内存)
•含义:进程间共享的内存段
•主要用途:tmpfs内存文件系统、进程间通信
Buffers/Cache(缓冲区与缓存)
•Buffers:块设备元数据缓存(目录结构、权限信息、inode等)
•Cache:文件内容页缓存
•作用:加速文件读写操作
Available(可用内存)
•含义:系统估算的可分配给新进程的内存
•作用:判断内存健康度的核心指标
上面就是使用人日常看到内存指标,而多数人关注的就是use、free等几个,其实在Linux的整体内存体系中,cache、buffer、available、swap等,都有着自己明确的作用,在一些场景也是至关重要的指标。
Linux内存分的很细致,可以在/proc/meminfo中详细查阅。
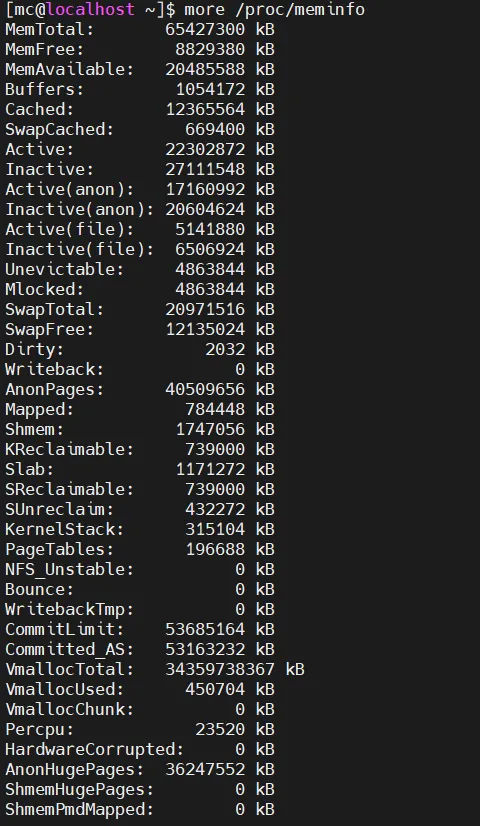
下面整理两点,一个是关于内存使用率的计算逻辑;一个是各个指标可能出现的异常场景。
1.内存使用率的计算逻辑
早年前的处理逻辑很简单就是total-free ,但现在还是用这种逻辑的已然很少,更多是使用文中提及的total - free - buff/cache,后者会更准确的体现出内存的使用情况,减少虚高,避免误告。大部分的商用运维也依然采用的这个算法,不过现在越来越多的运维在关注available值,如上文所说它才是真正可用内存;简单来说,available= free + 可回收buffer/cache - 不可回收内核开销,一眼看去,或许和传统算法很像,但还是有差别的,所以当前不少运维软件对于使用率的计算会选择 total –available的方式,比如Prometheus在这里就选择的node_memory_MemAvailable,更加贴切一些。
2.各个指标在场景中使用
每个指标都有意义,但有些指标出现异常走高或走低时,可以帮助使用人快捷的分析原因。
lSwap use 持续增加
交换分区使用持续增高,系统在操作层面会有明显的体现,这种情况下可能某些应用出现了内存泄露,也可能是物理内存不足。
lCache/buffer 持续走低
如果Cached特别大,说明系统缓存了很多文件;如果Buffers很大,可能是有大量的磁盘IO操作;结合常见的业务场景来说,大概率是海量小文件操作或数据库全扫描之类的操作。
lAvailable 持续走低
上文说过Available的意义,所以它持续走低,大概率是有异常的,不过这点就不能宽泛的去描述原因了,需要去结合各种情况来分析;
比如某场景中,available 经常性可用很低,而相关业务应用使用的内存不高,就得通过相关工具或命令去分析具体进程的内存使用消耗。
Ps命令搭配一些参数可以进一步分析
#ps -aux –sort=-%mem | head -10
#ps aux |grep xxx | awk '{sum+=\$6} END {print "Total memory: " sum/1024 " MB"}'
命令灵活或者提需求让AI给出即可。
END
Linux没有那么复杂,关键是多实操、多思考、多重复;重复多了就有了积累,积累多了就有了经验,经验多了,应对的空间就灵活了。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Linux中断子系统调试指南:debugfs与/proc/interrupts信息解读 【第15篇完·共15篇】
- 图解 Linux 内核 ORC 解栈(unwinding)原理
- 大语言模型与Python计算社会科学实证量化特训营!
- Formation Studio:让Python GUI开发变得简单易用
- python基础打印与多行打印练习
- Python数据分析练完这26页,搞定90%工作
- 当Python机器学习遇上AI智能体:2026年经管研究的"新标配",你配齐了吗?
- 学业辅导 | python王牌辅导班文科专场马上开启~速来报名!
- 三、Linux 文件管理+用户管理
- Python字典与列表的20个神仙操作
