由于借助 AI 工具学习编程已经变得非常容易了,因此之后的课程就不再默认进行视频讲解了,如果特别需要视频讲解也可以联系李老师预约讲解~讲义材料学习过程中遇到的问题也可以及时与李老师联系。
购买 RStata 名师讲堂会员即可参加该课程啦(之前的和未来的都可以参加)!
价格:2800/年 或者 4800/长期
购买会员可以从这里下单:https://rstata.duanshu.com/#/card/list/
名师讲堂会员权益:
- 参加平台上的其他 R 语言和 Stata 的课程;
- 以会员折扣价购买我们分享的数据资料(10 元/份);
* 如果发票可添加小编微信 r_stata2 (RStata 李老师)开具。如需数据资料,购买后可添加小编微信免费领取数据折扣卡。
更多关于 RStata 会员的更多信息可添加微信号 r_stata2 咨询:

课程主页(点击文末的阅读原文即可跳转):https://rstata.duanshu.com/#/brief/course/e2c59b4087b14b2fbf6958c020fbb9a5
今天给大家介绍如何使用 Python 基于 LandScan 全球人口栅格数据,按照王峤(2024)论文中的方法测算各城市多中心指标。
一、指标来源与计算原理
1.1 数据来源
本方法使用的人口数据为美国能源部橡树岭国家实验室提供的 LandScan 全球人口密度栅格数据,空间分辨率约为 1 km × 1 km(坐标参考系转换后约 820 m)。
1.2 指标定义
多中心指数(Polycentric Index)源自论文:
王峤. 空间结构、城市规模与中国城市的创新绩效 [J]. 中国工业经济, 2024.
其核心定义为:
- 指数越大(趋近于 1):城市多中心特征越明显,次中心与主中心旗鼓相当。
1.3 计算流程
整个计算分为以下步骤:
- 坐标系转换:将 LandScan 栅格数据投影到等面积坐标系(Albers 投影),确保距离计算准确;
- 裁剪与掩膜:按城市行政边界裁剪栅格,获取该城市范围内的人口格点;
- 构建点邻接:使用距离阈值(1000 m)构建邻接关系(边邻接规则,仅选取上下左右相邻格点),生成空间权重矩阵;
- 局部 Moran's I 检验:使用 R
spdep::localmoran(conditional=TRUE) 的条件正态近似法(Sokal 1998)计算每个格点的局部莫兰指数和 p 值,识别统计显著的高-高聚类区域(HH 格点); - 聚类成中心:将 HH 格点按空间邻接分组,形成连续的"高密度区块";
- 筛选有效中心:要求每个区块格点数 ≥ 3、总人口 ≥ 100,000;
- 计算多中心指数:按主中心(最大人口区块)与次中心之比计算。
1.4 参数设定说明
"sig_level": 0.05, # 局部莫兰指数显著性阈值"min_cells": 3, # 中心最小格点数(过滤噪点)"min_pop": 100000, # 中心最小人口(单位:人)"dist_nb": 1000# 邻接距离阈值(米)for k, v in ANALYSIS_PARAMS.items():关于 dist_nb = 1000 的设定:LandScan 数据经 Albers 投影后分辨率约为 820 m。相邻格点(上下左右)的距离约为 820 m,对角线方向约为 820 × √2 ≈ 1159 m。因此将阈值设为 1000 m,可精确选取边邻接格点,不会错误地把对角线邻居算进来。
二、使用 reticulate 创建与管理 Python 虚拟环境
在 R 中通过 reticulate 包来调用 Python,最好的实践是为项目创建一个专属的 Python 虚拟环境,将所需依赖隔离到独立空间,避免与系统 Python(如 Anaconda)发生版本冲突。
重要说明(避免"已初始化"报错):reticulate 在 R 会话中只能绑定一次 Python——一旦某个 {python} 代码块运行,Python 解释器就被锁定,之后再调用 use_virtualenv() 会报错:
ERROR: The requested version of Python cannot be used, as another version has already been initialized.因此,虚拟环境的激活必须在所有 {python} 代码块之前完成。本文档的解决方案是在 setup chunk 中通过 Sys.setenv(RETICULATE_PYTHON = ...) 提前锁定 Python 路径,这是 reticulate 选取 Python 的最高优先级入口。
2.1 安装 reticulate(仅首次)
# 设置 CRAN 镜像(knit 时 R 处于非交互模式,不会自动选择镜像)options(repos = c(CRAN = "https://mirrors.tuna.tsinghua.edu.cn/CRAN/"))# 仅在尚未安装时才安装,避免每次 knit 都重装if (!requireNamespace("reticulate", quietly = TRUE)) { install.packages("reticulate") message("reticulate 安装完成!") message("reticulate 已安装,版本:", packageVersion("reticulate"))2.2 虚拟环境初始化原理(已在 setup chunk 中完成)
本文档的 setup chunk(隐藏运行)包含如下逻辑:
.venv_python <- virtualenv_python(.venv_name)if(!file.exists(.venv_python)){ virtualenv_create(.venv_name) .venv_python <- virtualenv_python(.venv_name)# 通过环境变量抢先锁定 Python(优先级最高,早于任何 {python} chunk)Sys.setenv(RETICULATE_PYTHON = .venv_python)use_virtualenv(.venv_name, required =TRUE)这样做的关键在于:knitr 在处理第一个 {python} chunk 时,reticulate 已经通过 RETICULATE_PYTHON 环境变量知道要使用 .venv,不会再去碰 Anaconda。
2.3 在虚拟环境中安装 Python 包(仅首次)
"numpy", "pandas", "geopandas", "rasterio","libpysal", "scipy", "matplotlib", "pyproj", "shapely"installed <- py_list_packages(".venv")$packageneed_install <- setdiff(py_pkgs, installed)if (length(need_install) > 0) { virtualenv_install(".venv", packages = need_install) message("已安装缺失的包:", paste(need_install, collapse = ", ")) message("所有 Python 包已就绪,无需安装")2.4 验证激活状态
# 验证当前绑定的 Python 路径(应指向 .venv 目录)2.5 查看已安装的包
pkgs <- py_list_packages(".venv")key_pkgs <- c("numpy", "pandas", "geopandas", "rasterio", "libpysal", "scipy")pkgs[pkgs$package %in% key_pkgs, c("package", "version")]2.6 虚拟环境管理常用命令
# virtualenv_remove(".venv")# virtualenv_install(".venv", packages = "geopandas", ignore_installed = TRUE)
三、环境配置与数据准备
3.1 加载 Python 包
from rasterio.mask import maskfrom shapely.geometry import Pointfrom scipy.spatial import KDTreefrom scipy.stats import normfrom libpysal.weights import DistanceBand, lag_spatialimport matplotlib.pyplot as pltimport matplotlib.font_manager as fmwarnings.filterwarnings("ignore")font_path = os.path.expanduser("~/Library/Fonts/LXGWWenKai-Regular.ttf")fm.fontManager.addfont(font_path)prop = fm.FontProperties(fname=font_path)plt.rcParams["font.family"] = prop.get_name()plt.rcParams["axes.unicode_minus"] = False3.2 全局路径与参数配置
"+proj=aea +lat_0=0 +lon_0=105 +lat_1=25 +lat_2=47"" +x_0=0 +y_0=0 +ellps=krass +units=m +no_defs""pop_tif": BASE_DIR / "pop-tif2","city_shp": BASE_DIR / "2021行政区划" / "市.shp",数据预处理提示:如果你的 LandScan tif 文件还是 WGS84 坐标系,需要先转换到 MY_CRS:
from rasterio.warp import calculate_default_transform, reproject, Resamplingos.makedirs("pop-tif2", exist_ok=True)for src_path insorted(glob.glob("pop-tif/*.tif")): dst_path = src_path.replace("pop-tif", "pop-tif2")with rasterio.open(src_path) as src: transform, width, height = calculate_default_transform( src.crs, MY_CRS, src.width, src.height, *src.boundswith rasterio.open(dst_path, "w", **kwargs) as dst:for band inrange(1, src.count + 1): source=rasterio.band(src, band), destination=rasterio.band(dst, band), src_transform=src.transform, resampling=Resampling.nearest,
四、单城市演示计算(北京市,2020 年)
4.1 读取城市边界与人口栅格
city_demo = gpd.read_file(PATH["city_shp"])city_demo["geometry"] = city_demo["geometry"].buffer(0)city_demo = city_demo[~city_demo.is_empty]city_demo = city_demo.to_crs(MY_CRS)city_demo = city_demo[city_demo["市"] == "北京市"]4.2 裁剪与栅格转点
4.3 构建空间权重矩阵
coords = np.array([(p.x, p.y) for p in pop_points.geometry])w = DistanceBand(coords, threshold=ANALYSIS_PARAMS["dist_nb"], binary=True, alpha=-1.0)print(f"平均邻居数: {w.mean_neighbors:.2f}")参数说明
binary=True:二元权重,邻居权重为 1,非邻居为 0;alpha=-1.0:距离衰减参数,-1 表示使用 1/距离作为权重(当 binary=False 时生效);transform = "r":行标准化权重,与 R 中 style = "W" 等价。
4.4 局部 Moran's I 检验
局部 Moran's I 是用来找 "高值围着高值、低值围着低值" 的空间集聚热点的工具。在这里,它的唯一作用就是:找出人口高密度、且周围也是高密度的区域 → 也就是城市中心(HH 集聚区)。
# 自实现条件正态近似法(完全复现 R spdep::localmoran(conditional=TRUE) 源码)deflocal_moran_conditional_p(y, w): 使用 R spdep::localmoran(conditional=TRUE) 的条件正态近似法计算 LISA p 值。 y = np.asarray(y, dtype=np.float64) m2 = np.sum(z ** 2) / n # mlvar=TRUE 时的方差 z_lag = lag_spatial(w, z)iflen(w.neighbors[i]) > 0: weights_i = np.array(w.weights[i]) Wi[i] = np.sum(weights_i) Wi2[i] = np.sum(weights_i ** 2)# 条件期望:E[Ii] = -(z_i^2 * Wi) / ((n-1) * m2) E_Ii = -(z ** 2 * Wi) / ((n - 1) * m2)# 条件方差(Sokal 1998,R 源码 conditional=TRUE 分支) var_Ii = (zi_over_m2 ** 2) * (n / (n - 2)) * (Wi2 - Wi ** 2 / (n - 1)) * (m2 - z ** 2 / (n - 1)) var_Ii = np.maximum(var_Ii, 0.0) z_score = np.where(var_Ii > 0, (Ii - E_Ii) / np.sqrt(var_Ii), 0.0) p_val = 2.0 * norm.sf(np.abs(z_score))p_val, Ii = local_moran_conditional_p(pop_points["pop"].values, w)# 结果包含:Ii(局部莫兰指数)、p_val(条件正态近似 p 值)result_df = pd.DataFrame({4.5 空间类型分类(LISA 象限)
pop_med = pop_points["pop"].median()pop_lag = lag_spatial(w, pop_points["pop"].values)sig = p_val < ANALYSIS_PARAMS["sig_level"]self_type = np.where(pop_points["pop"].values > pop_med, "H", "L")nb_type = np.where(pop_lag > pop_med, "H", "L") sig & (self_type == "H") & (nb_type == "H"), "HH", "其他"pop_points = pop_points.copy()pop_points["p_value"] = p_valpop_points["pop_med"] = pop_medpop_points["pop_lag"] = pop_lagpop_points["self_type"] = self_typepop_points["nb_type"] = nb_typepop_points["cluster_type"] = cluster_typepop_points["cluster_type"].value_counts()这里只关心 HH 类型(自身人口高 + 邻居人口高 + 统计显著),这类格点代表真正的人口密集聚集区,是城市中心的候选位置。
4.6 提取 HH 格点并聚类成中心
hh_points = pop_points[pop_points["cluster_type"] == "HH"].reset_index(drop=True)print(f"HH 格点数量: {len(hh_points)}")# 对 HH 格点聚类(使用 Union-Find 算法识别连通分量)iflen(hh_points) >= ANALYSIS_PARAMS["min_cells"]: coords_hh = np.array([(p.x, p.y) for p in hh_points.geometry]) parent[x] = parent[parent[x]] rx, ry = find(x), find(y) pairs = tree.query_pairs(r=ANALYSIS_PARAMS["dist_nb"]) clusters = [find(i) for i inrange(n)] unique_clusters = sorted(set(clusters)) cluster_map = {c: idx + 1for idx, c inenumerate(unique_clusters)} hh_points["cluster_id"] = [cluster_map[c] for c in clusters]print(f"聚类数量: {hh_points['cluster_id'].nunique()}")4.7 筛选有效中心并计算多中心指数
4.8 可视化
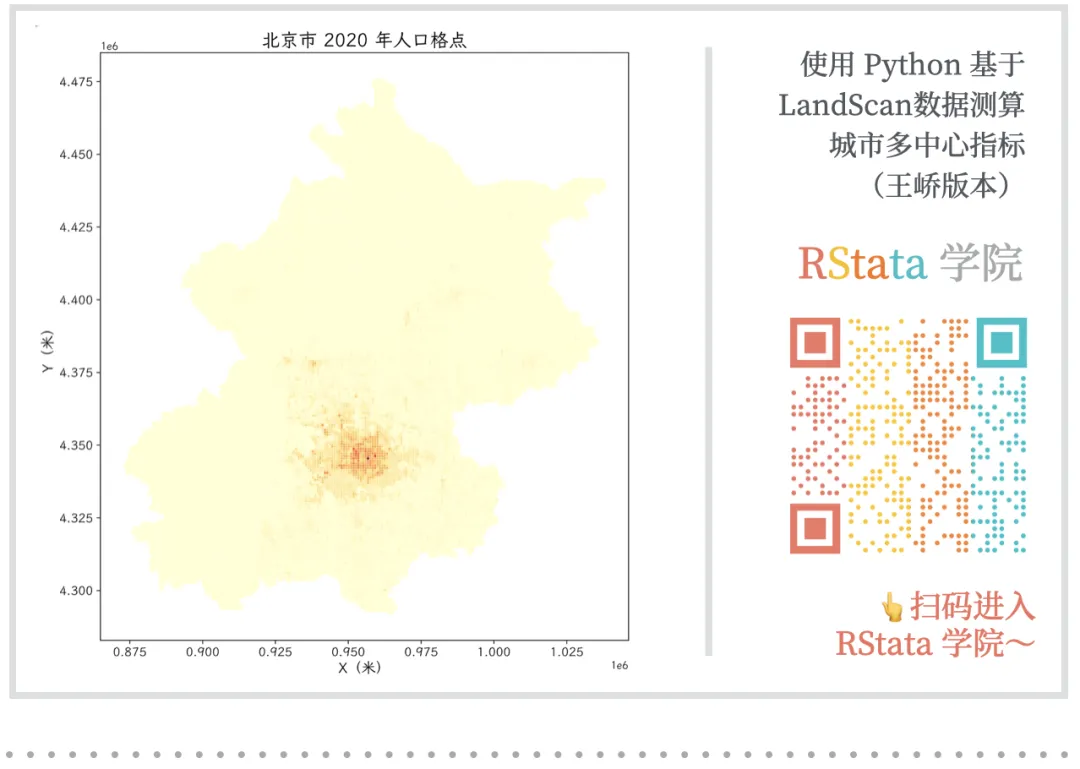
将上述分析结果绘制为双面板地图:左图展示城市人口格点分布,右图展示 LISA 识别出的 HH 集聚区与中心。
fig, axes = plt.subplots(1, 2, figsize=(20, 9))axes[0].set_title("北京市 2020 年人口格点", fontsize=18)axes[0].set_xlabel("X(米)", fontsize=14)axes[0].set_ylabel("Y(米)", fontsize=14)axes[0].tick_params(labelsize=12)iflen(hh_points) > 0and"cluster_id"in hh_points.columns: other_points = pop_points[pop_points["cluster_type"] != "HH"] other_points.plot(ax=axes[1], color="lightgray", markersize=1) axes[1].set_title("北京市 2020 年 HH 集聚区与中心识别", fontsize=18) axes[1].set_title("北京市 2020 年 LISA 分类", fontsize=18)axes[1].set_xlabel("X(米)", fontsize=14)axes[1].set_ylabel("Y(米)", fontsize=14)axes[1].tick_params(labelsize=12)插图
五、批量并行计算(全国所有城市 × 所有年份)
5.1 封装核心计算函数
5.2 索引年份文件与批量计算
# 串行遍历所有城市(并行计算请使用独立的 batch_calculate.py 脚本)os.makedirs("res", exist_ok=True)for _, row in city_all.iterrows(): output_file = f"res/{code}.csv"if os.path.exists(output_file):print(f" 跳过 {city_name}({code},已计算)")print(f"正在计算:{city_name}({code})") city_geom = city_all[city_all["市代码"] == code].iloc[[0]]for year, pop_file in pop_files.items(): res = calculate_polycentric(city_geom, pop_file)print(f" {year} 年返回 None") pd.DataFrame(results).to_csv(output_file, index=False)print(f" {city_name} 完成,保存 {len(results)} 条记录")print(f" {city_name} 全部年份均无有效结果")print("======== 全部计算完成!结果保存在 res/ 文件夹 ========")
六、改进算法:预计算空间权重矩阵
6.1 为什么可以改进?
在上面的批量计算中,对同一个城市,每个年份都重新计算了一次空间权重矩阵。但实际上,空间权重矩阵只取决于城市边界的形状——它与年份无关,只要城市行政边界不变(本项目使用 2021 年固定边界),同一城市所有年份的空间权重矩阵完全相同。
因此,可以先把所有城市的权重矩阵计算并保存好,然后在计算各年数据时直接读取,显著减少重复计算。
对于一个有 NNN 个城市、TTT 个年份的数据集:
当 T=25T = 25T=25(2000~2024 年)时,改进方法可将权重矩阵的计算量缩减为原来的 1/25。
6.2 预计算并保存所有城市的权重矩阵
os.makedirs("lwres", exist_ok=True)# (ProcessPoolExecutor 在 reticulate 环境下无法序列化 __main__ 中定义的函数,# 因此 Rmd 中使用串行循环;如需并行请使用独立的 batch_calculate.py 脚本)for _, row in city_all.iterrows(): lw_path = f"lwres/{code}.pkl"if os.path.exists(lw_path):print(f" 跳过 {city_name}({code},权重矩阵已存在)")# 直接使用已加载的 city_all,不重复读取 shp city_geom = city_all[city_all["市代码"] == code].iloc[[0]]# 使用任意一年(如 2020 年)的栅格确定格点位置 points = clip_raster_to_city(str(PATH["pop_tif"] / "2020.tif"),print(f" {city_name}({code})无有效格点,跳过") w = build_spatial_weights(points)withopen(lw_path, "wb") as f:print(f" {city_name}({code})权重矩阵已保存")print("======== 所有城市权重矩阵计算完成,保存在 lwres/ ========")6.3 使用预计算权重矩阵的改进版计算函数
# 改进版核心函数:接受外部传入的 lw,不在函数内部重新计算# 见 calculate_polycentric.py 中的 calculate_polycentric(city_geom, pop_file, lw=...)# 传入 lw 参数后,函数内部将跳过权重矩阵构建步骤6.4 使用改进算法批量计算全部数据
6.5 合并所有结果并保存
for f insorted(glob.glob("resa/*.csv")): dfs.append(pd.read_csv(f))print(f" 读取 {f} 出错: {e}")print("⚠️ 没有找到任何结果文件,请先运行上面的计算步骤") df1 = pd.concat(dfs, ignore_index=True) df1 = df1.sort_values(["city_code", "year"]).reset_index(drop=True)# version=118(Stata 15+)支持 UTF-8 编码,可正确写入中文字符"center_count": "有效中心数量","polycentric_index": "多中心指数","sample_polycentric_index_wangqiao.dta", variable_labels=variable_labels,print(f"最终数据已保存:{len(df1)} 条记录")最终结果数据集包含如下变量:
| |
|---|
year | |
city_name | |
city_code | |
center_count | |
main_pop | |
sub_pop | |
polycentric_index | 多中心指数 = 次中心人口 / (主中心人口 + 次中心人口) |
如何参加课程?
购买 RStata 名师讲堂会员即可参加该课程啦(之前的和未来的都可以参加)!
价格:2800/年 或者 4800/长期
购买会员可以从这里下单:https://rstata.duanshu.com/#/card/list/
名师讲堂会员权益:
- 参加平台上的其他 R 语言和 Stata 的课程;
- 以会员折扣价购买我们分享的数据资料(10 元/份);
* 如果发票可添加小编微信 r_stata2 (RStata 李老师)开具。如需数据资料,购买后可添加小编微信免费领取数据折扣卡。
更多关于 RStata 会员的更多信息可添加微信号 r_stata2 咨询:

课程主页(点击文末的阅读原文即可跳转):https://rstata.duanshu.com/#/brief/course/e2c59b4087b14b2fbf6958c020fbb9a5









 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
