Python 调一个 AI 模型,背后其实调的是 C++
- 2026-07-02 08:19:16
有一次群里有同学发了一个截图,是他面试大厂时的官方记录:
面试官:"你说说,为什么我们训练好的 AI 模型,部署到生产环境时,最后推理都是用 C++ 做的?"
候选人:"……因为 Python 比较慢?"
面试官:"那你说说,Python 比 C++ 慢在哪里?"
候选人:"……"
看得我們群里都局俏了。但事实上,这个问题的确是面试里的高频卡点。很多人天天用 Python 写 model(inputs),感觉 AI 就是 Python 的天下,却从来没想过这一行代码背后发生了什么。
今天我就给你撕开这层窗户纸。
最近上线了一套【AI Coding实战课程】,把用AI做开发的整套方法都拆开讲清楚了,如果你也在用AI写代码,但感觉用不顺,想系统提升AI编程能力,可以看下方海报了解详情👇

二、一个实验:同一个模型,性能差几倍?
我先给你一个直观的对比。同一个简单的小模型(一个全连接层做矩阵乘法),分别用纯 Python 实现、PyTorch Python 接口、以及 C++ libtorch 实现,同款 CPU 下的执行时间对比:
libtorch 推理 |
纯 Python 循环实现慢了 40 倍,这不意外。但有意思的是:即使你写的是 torch.nn.Linear(...) 这种看起来纯粹的 Python 代码,执行速度也已经接近 C++ 了。
为什么?
因为 torch.nn.Linear 的前向计算,根本就不是在 Python 层完成的。Python 只是发了一条"命令",真正做矩阵运算的,是 C++ 写的 aten 底层引擎。
三、原理剂析:为什么非得用 C++ 做里子?
要理解这个现象,先得知道 Python 在运行时的两个天然缩颈。
第一个是 GIL(全局解释器锁)。Python 的内存管理不是线程安全的,所以 CPython 用了一把大锁:同一时刻只能有一个线程在执行 Python 字节码。你写了多线程代码,表面上跳来跳去,实际上还是串行的。
第二个是 解释执行。Python 是边解释边执行,每一行都要走一遍编码、词法分析、语义分析的流程。这就好比你每次做一道题都要先把题目背下来,而不是直接写答案。
而 C++ 在编译时就已经把代码翻译成机器码了,运行时直接上 CPU 命令。配合 -O2 或 -O3 编译优化,编译器还会做循环展开、向量化、内联展开等操作,把代码挑到极致。
所以 AI 框架们的选择很简单:Python 负责接地气,C++ 负责跑正事。
四、Python 是怎么"借"用 C++ 的?
这里有三种常见的"借力"方式,我们用一张表对比清晰:
ctypes | ||||
Cython | ||||
pybind11 |
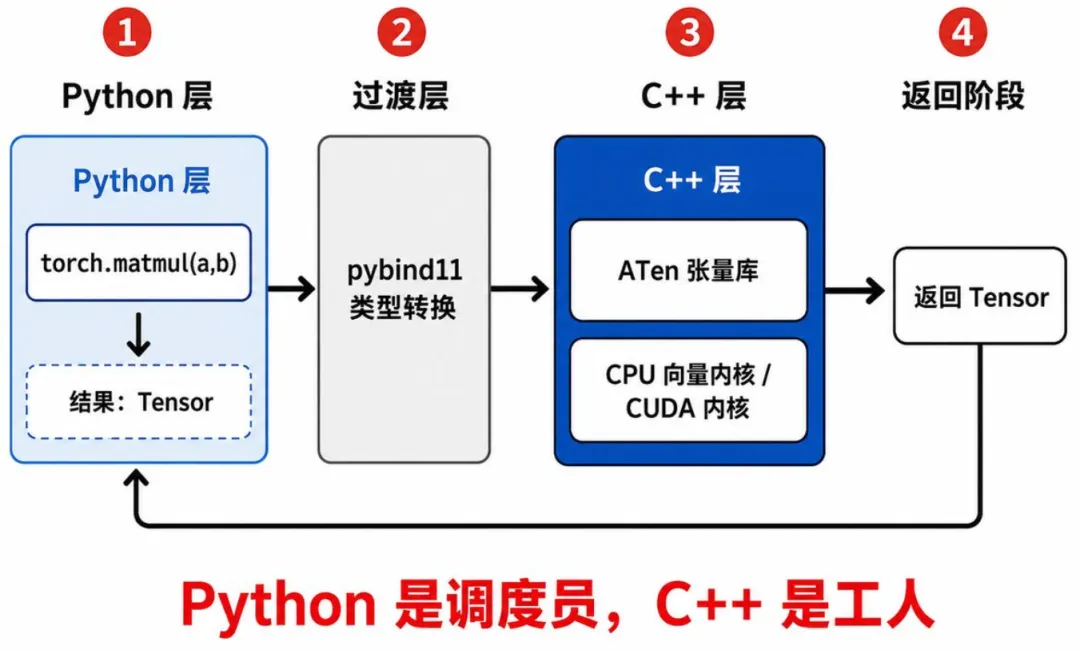
以 PyTorch 为例,你写的 torch.matmul(a, b) 大概走了这么一条路:
Python 层接收参数,做基础类型检查 通过 pybind11把Tensor传进 C++ 层C++ 层调度 ATen(张量操作库)执行计算如果有 CUDA,进一步调用 CUDA Kernel,否则走的是写好的 CPU 向量内核返回结果给 Python
看见了吗?Python 只是一个调度员,C++ 才是真正干活的工人。
而到了生产环境推理时,大家更傾向于直接用 ONNX Runtime 或 TensorRT 这种纯 C++ 后端跑模型,连 Python 那一层调度都省了。

五、面试及工程速查表
如果你是面试者,下面这张清单建议熔会于心:
面试必备要点
Python 的 GIL 是什么,为什么导致多线程不能真正并行 解释型语言和编译型语言的执行差异 为什么 AI 框架的计算密集部分要用 C++ 实现 pybind11的基本作用和原理(可以用一句话概括)
工程落地建议
开发阶段用 Python 快速验证模型,产业发模型是第一优先级 部署阶段考虑用 ONNX Runtime / TensorRT / libtorchC++ API 做推理服务化对延迟敏感的场景(如实时推理),尽量绕过 Python 层,直接走纯 C++ 推理链 编译 C++ 部分时加 -O2或-O3,配合-march=native让 CPU 满血运转

六、从会用到懂原理
我们今天讲的不是"别用 Python 了"。Python 仍然是 AI 生态中不可或缺的语言,它的易用性、丰富的库和极快的迭代速度,几乎没有对手。
但是,作为一个想要往深里走的工程师,你得明白自己在用什么。当你写下 model(inputs) 的时候,你在用 Python 的手指,动的却是 C++ 的肌肉。懂了这一点,你就不会在面试里被"追着打",也不会在产业部署时走弯路。
C++ 校招 / 社招跳槽逆袭!从0到1打造高含金量项目,导师1v1辅导,助你斩获大厂offer!
很多同学准备校招时最焦虑的问题就是:“简历没项目,怎么打动面试官?”
为了解决这个痛点,我们推出了C++项目实战训练营
在这里,你可以:
系统学习 C++ 进阶知识 自选项目,从 0 到 1 实战造轮子 导师一对一指导,代码逐行 Review 拿到能写进简历的项目成果,秋招直接加分!
我们不只是教你写代码,更带你走一遍完整的项目流程: 从需求分析、架构设计、编译调试,到版本管理、测试发布,全流程掌握!
项目配套资料齐全,遇到问题还有导师帮你答疑,不怕卡壳!
项目准备好了,你只差一次出发。
相信我,这些项目绝对能够让你进步巨大!下面是其中某三个项目的说明文档
训练营适用人群:
备战春招和秋招的应届生,科班非科班均可, 工作 3 年以内,想跳槽的社招同学 如果你有以下困扰,欢迎联系我们,我们愿意为你提供帮助和支持 不知道该复习哪些内容,如何开始复习。 对面试考察重点不清楚,复习效率低下。 缺乏有含金量的实战项目经验。 想要提升自己的实战能力,提升做项目及解决问题的能力 对算法题无从下手,缺乏解题思路和常见解题模板。 自控力不足,难以专注于系统复习。 希望获得大厂的内推机会。 独自备战校招社招感到孤单,想要找到学习伙伴。
不适合人群:
缺乏耐心和毅力,急于求成的人 对编程逻辑思维基础薄弱,且不愿努力提升的人 只想快速获得成果而不注重基础学习的人
推荐阅读:

