大家好,我是蟹老板~
很多朋友学 Linux 内核的时候,最大的感悟就是:看得懂每一行代码,却看不懂整个系统。
为什么会这样呢?因为 Linux 内核本质上就是一个巨大的数据结构集合。
调度器在管理数据结构。
内存管理在维护数据结构。
文件系统在组织数据结构。
网络协议栈更是在疯狂操作数据结构。
说得再直白一点:Linux 内核其实就是一群数据结构,加上一堆操作这些数据结构的函数。
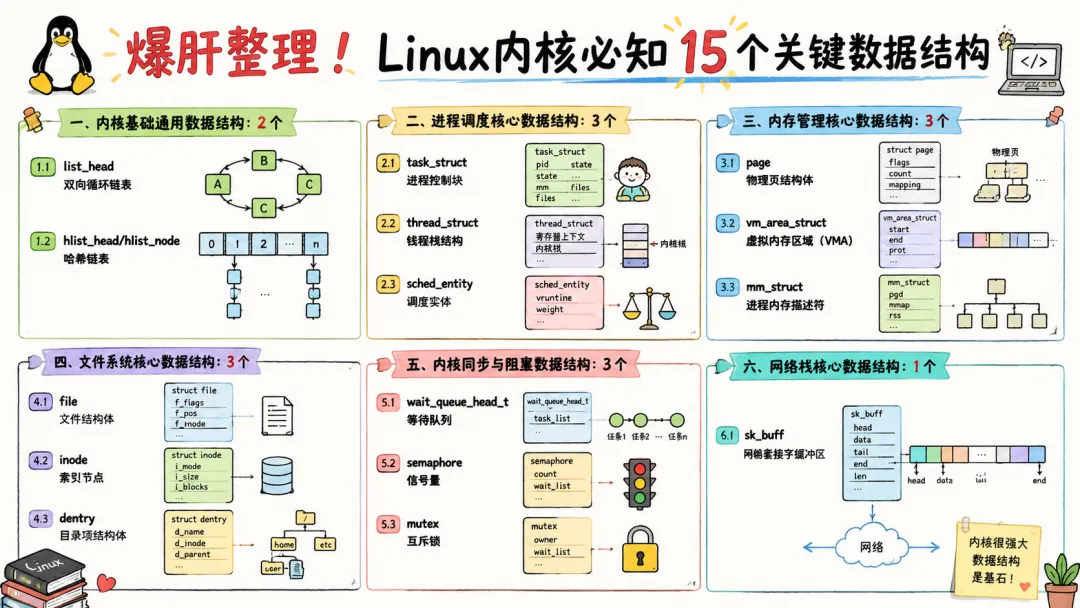
所以今天这一篇我准备把 Linux 内核里最核心、最常见、最容易在内核源码阅读和高级面试里出现的 15 个关键数据结构,硬核总结出来给你们捋一遍。
不是为了让大家背定义,而是让你真正知道:内核到底是怎么管理进程、内存、文件和网络的。
毕竟内核代码动不动几万行,抓不住数据结构的核心,改个bug都能改到自闭,头发真的保不住啊。
一、内核基础通用数据结构(2 个)
内核所有高级功能的数据流转,都基于通用基础数据结构实现!这两个链表结构是内核的"基石工具",贯穿内核所有模块,是所有内核开发者的入门必修课,没有任何例外。
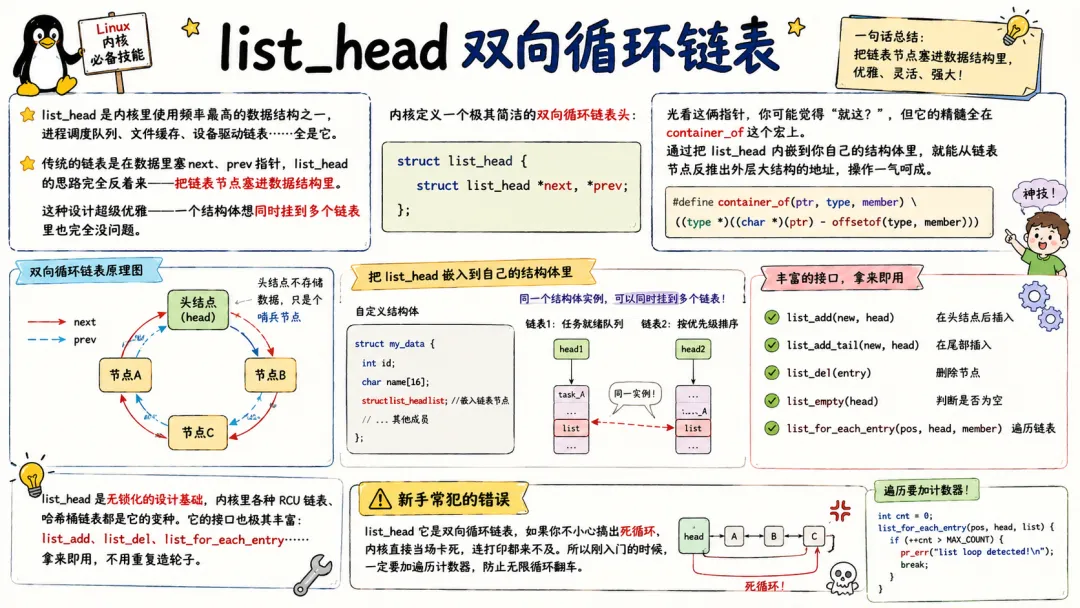
1.1 list_head 双向循环链表
list_head是内核里 使用频率最高的数据结构之一,进程调度队列、文件缓存、设备驱动链表……全是它。
传统的链表是在数据里塞 next、prev 指针,list_head 的思路完全反着来——把链表节点塞进数据结构里。这种设计超级优雅——一个结构体想同时挂到多个链表里也完全没问题。
内核定义一个极其简洁的双向循环链表头:
struct list_head {struct list_head *next, *prev;};
光看这俩指针,你可能觉得"就这?",但它的精髓全在 container_of 这个宏上。通过把 list_head 内嵌到你自己的结构体里,就能从链表节点反推出外层大结构的地址,操作一气呵成。
list_head 是 无锁化的设计基础,内核里各种 RCU 链表、哈希桶链表都是它的变种。它的接口也极其丰富:list_add、list_del、list_for_each_entry……拿来即用,不用重复造轮子。
给你们看个最经典的用法——遍历设备列表,找到对应设备:
struct my_device { int id;struct list_head node; // 内嵌链表节点};// 遍历链表struct my_device *dev;list_for_each_entry(dev, &device_list, node) { if (dev->id == target_id) { // 找到了,直接操作dev break; }}
你看,根本不需要手写遍历逻辑,一个宏直接搞定。刚接触的时候可能觉得 container_of 绕脑,但等你手写几次驱动,就会发现这玩意儿简直是"内核版的乐高积木"。
新手常犯的错误是 list_head 它是双向循环链表,如果你不小心搞出死循环,内核直接当场卡死,连打印都来不及。所以刚入门的时候,一定要加遍历计数器,防止无限循环翻车。
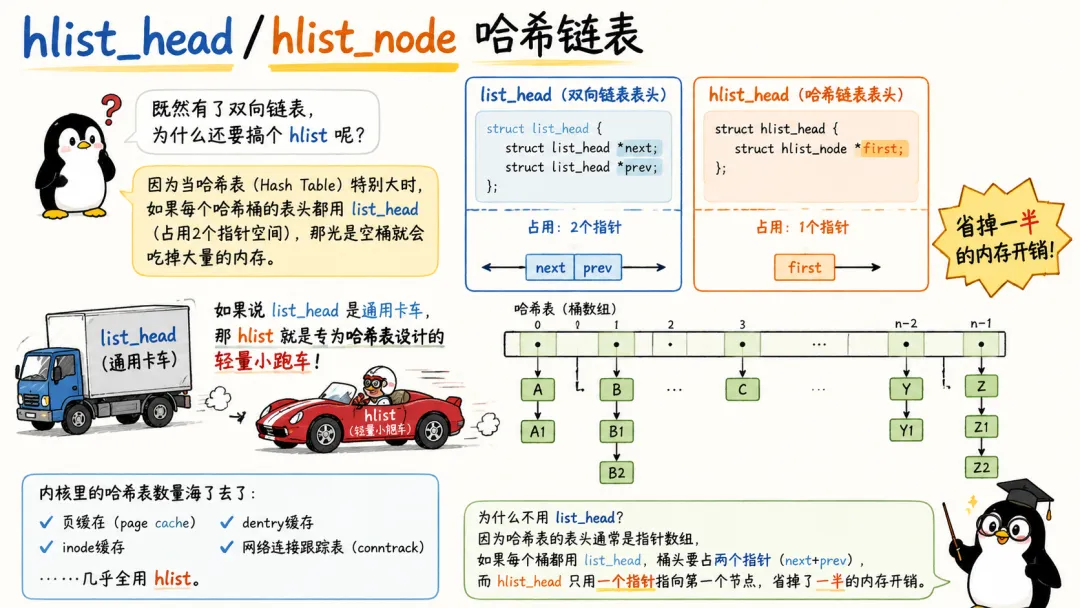
1.2 hlist_head / hlist_node 哈希链表
既然有了双向链表,为什么还要搞个 hlist?
因为当哈希表(Hash Table)特别大时,如果每个哈希桶的表头都用 list_head(占用2个指针空间),那光是空桶就会吃掉大量的内存。
如果说 list_head 是通用卡车,那 hlist 就是专为哈希表设计的轻量小跑车。
内核里的哈希表数量海了去了:页缓存(page cache)、inode 缓存、dentry 缓存、网络连接跟踪表……几乎全用 hlist。为什么不用 list_head?因为哈希表的表头通常是指针数组,如果每个桶都用 list_head,桶头要占两个指针(next + prev),而 hlist_head 只用一个指针指向第一个节点,省掉了一半的内存开销。
结构体长这样:
struct hlist_head {struct hlist_node *first;};struct hlist_node {struct hlist_node *next, **pprev;};
注意这个 pprev,它是一个二级指针,指向前一个节点的 next 指针的地址。这种设计让删除节点时不需要遍历找到前驱,直接通过 *pprev = next 就能把自己从链表中摘走,效率极高,也方便 RCU 读端无锁遍历。
日常开发中,hlist 大量用在需要快速查找的场景,比如根据 inode 号快速定位 inode 缓存。面试时如果被问到"内核里哈希表怎么实现",你能把 hlist_head、pprev 的设计初衷讲清楚,基本就能拿捏住面试官了。
一个典型的内核 hlist 初始化 + 查找代码片段:
struct hlist_head hash_table[HASH_SIZE];// 初始化每个桶的头for (i = 0; i < HASH_SIZE; i++) INIT_HLIST_HEAD(&hash_table[i]);// 查找元素struct my_hash_item *item;struct hlist_node *tmp;hlist_for_each_entry(item, tmp, &hash_table[key], hnode) { if (item->id == target_id) return item;}
hlist 的短板就是没办法直接反向遍历,且操作不当容易引发 pprev 悬空指针导致内核 panic。不过只要你老老实实用内核提供的 hlist_add、hlist_del,别自己瞎改指针,就没大事。
二、进程调度核心数据结构(3 个)
Linux 是分时多任务操作系统,所有进程的创建、管理、调度、切换,全靠这三个核心结构支撑,是进程子系统的骨架,面试进程调度必问,驱动多进程开发必懂。
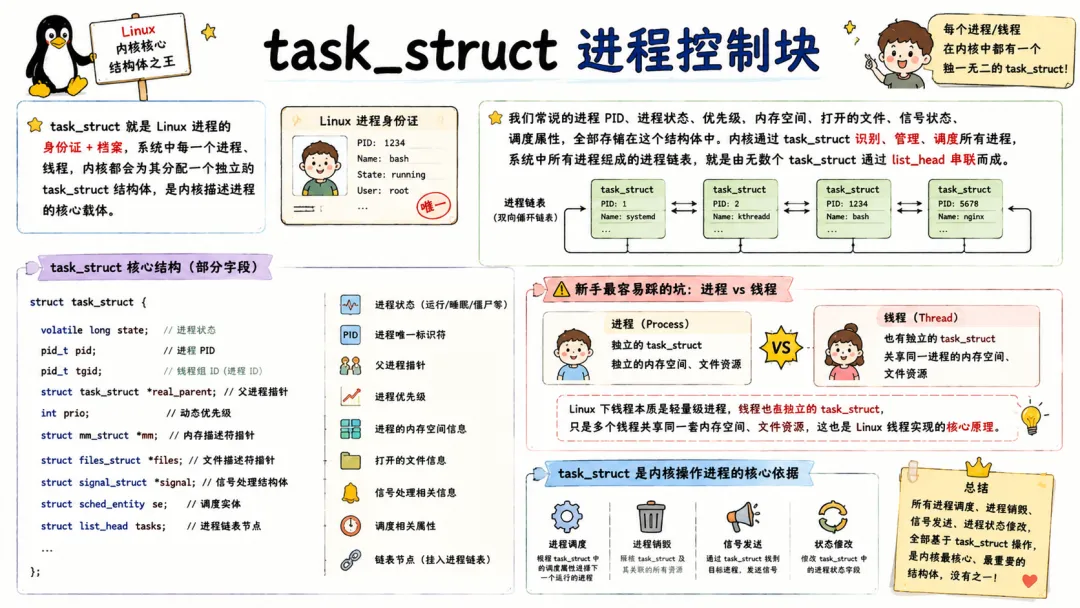
2.1 task_struct 进程控制块
task_struct 是 Linux 内核里最大、最复杂、最重要的数据结构,没有之一。
内核用"任务"的概念管理所有执行流——进程、线程、内核线程全部用 task_struct 表示。一个进程的 PID、状态、内存映射、文件描述符表、信号处理、调度信息……统统塞在这个大结构里。
它的体积非常庞大,在64位系统上通常有几千字节,包含数百个字段。我们不需要全记住,但要能抓住核心的几个区域:
- • 调度相关:
state(运行/就绪/阻塞)、prio、se(调度实体) - • 内存相关:
mm(进程地址空间)、active_mm - • 文件相关:
fs(文件系统信息)、files(打开文件表) - • 关系信息:
parent、children、sibling 链表,构成进程树
在项目开发里,你通过 current 宏就能直接拿到当前进程的 task_struct。内核模块开发中,读取进程 PID、判断进程状态、遍历子进程,全靠它。
task_struct 不仅字段多,还牵扯到内核栈的巧妙设计。内核为每个进程分配一个内核栈(通常 8KB 或 16KB),而 task_struct 被放在栈底(或通过 thread_info 关联),这样内核通过栈指针就能快速计算出 task_struct 地址,效率极高。
task_struct 是内核 OOM 和调度延迟的敏感根源——调度器、内存回收、cgroup 等子系统几乎全在读写它,一处改错,整个内核都可能崩。
面试常问:"内核是怎么区分进程和线程的?"答案就藏在 task_struct 的 clone_flags、tgid 和共享资源里。
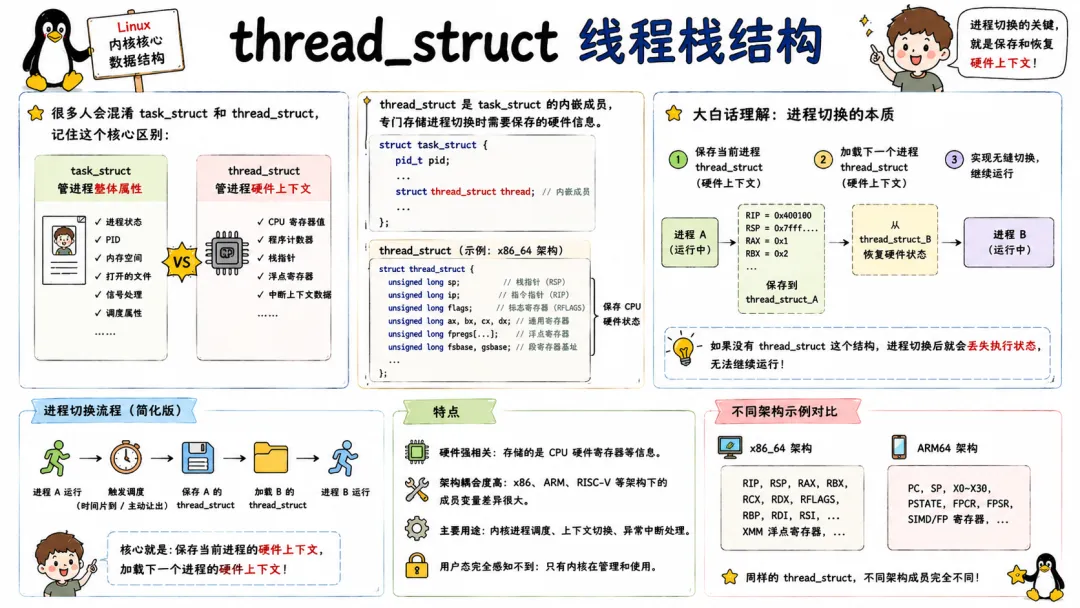
2.2 thread_struct 线程栈结构
thread_struct 虽然名气没 task_struct 大,但进程切换时的 CPU 上下文,全靠它保存和恢复。
它和硬件架构强相关,x86 下结构定义在 arch/x86/include/asm/processor.h 中,保存了内核态和用户态的寄存器快照、浮点寄存器(fpu)、调试寄存器等。每次进程切换时,内核先保存当前进程的 CPU 上下文到它的 thread_struct 中,再从新进程的 thread_struct 里恢复上下文,这就是所谓的"上下文切换"。
很多人对进程切换只停留在"保存寄存器"这个笼统概念上,但实际上,FPU 状态的延迟保存(eager fpu 和 lazy fpu)优化,就是围绕 thread_struct 展开的。进程如果没有用过浮点指令,切换时就不必保存 FPU 上下文,能省掉大量时间。
在内核调试中,如果遇到莫名其妙的段错误或浮点计算异常,经常就是 thread_struct 保存不完整或恢复错误导致的。了解它的字段,对分析 crash dump 非常有帮助。
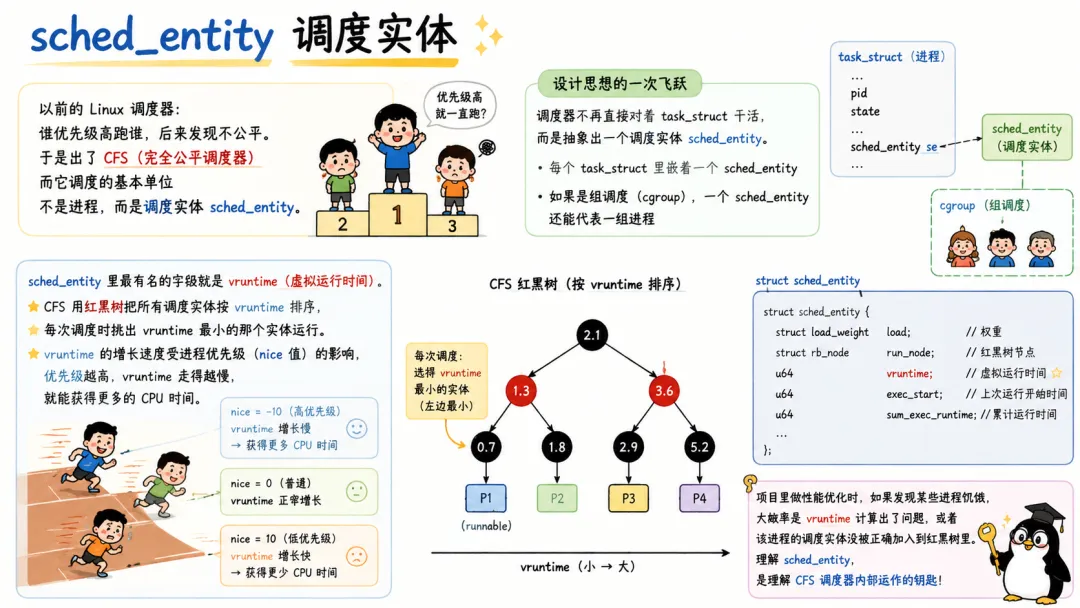
2.3 sched_entity 调度实体
以前的 Linux 调度器谁优先级高跑谁,后来发现不公平。于是出了 CFS(完全公平调度器),而它调度的基本单位不是进程,而是调度实体sched_entity。
这是设计思想的一次飞跃:调度器不再直接对着 task_struct 干活,而是抽象出一个调度实体,task_struct 里嵌着一个 sched_entity。如果是组调度(cgroup),一个调度实体还能代表一组进程。
sched_entity 里最有名的字段就是 vruntime(虚拟运行时间)。CFS 用红黑树把所有调度实体按 vruntime 排序,每次调度时挑出 vruntime 最小的那个实体运行。vruntime 的增长速度受进程优先级(nice 值)的影响,优先级越高,vruntime 走得越慢,就能获得更多的 CPU 时间。
struct sched_entity {struct load_weight load; // 负载权重struct rb_node run_node; // 挂在CFS红黑树上的节点 u64 vruntime; // 虚拟运行时间,CFS核心排序键 // ...};
项目里做性能优化时,如果发现某些进程饥饿,大概率是 vruntime 计算出了问题,或者该进程的调度实体没被正确加入到红黑树里。理解 sched_entity,是理解 CFS 调度器内部运作的钥匙。
三、内存管理核心数据结构(3 个)
Linux 的内存管理是出了名的复杂,但只要你抓住下面三个结构,主线逻辑就瞬间清晰了。
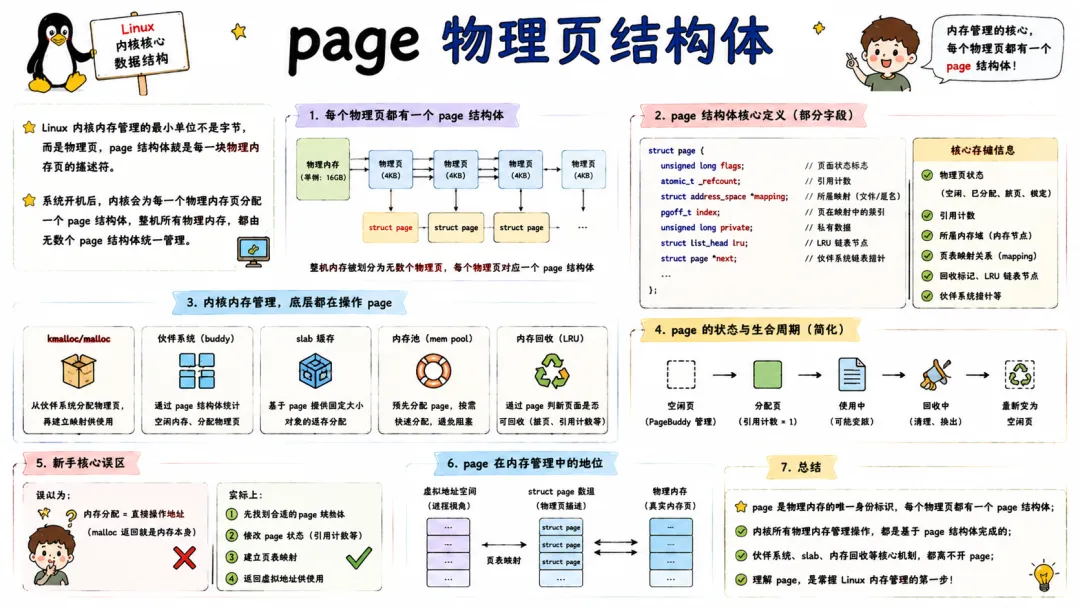
3.1 page 物理页结构体
Linux 以页为基本单位管理物理内存,每一个物理页框对应一个 page 结构体。
struct page 在内核里无处不在,它是 buddy 分配器、slab 分配器、页回收、页面迁移、文件缓存的基础。一个 page 既可能代表一段物理内存,也可能关联一个文件缓存页,甚至还能代表一个设备映射页,这种多义性(union 复用)让 page 结构体非常"精分"。
关键字段包括:flags(页状态标记,比如脏、锁定、回写)、_refcount(引用计数)、mapping(关联的地址空间,用于文件页)、index(在映射中的偏移)等。
开发驱动或者优化内存时,通过 page 可以查到页面是否被锁定、是否有活跃引用,从而分析内存泄漏或高昂的缺页异常。不过要小心,page 结构本身也消耗内存,在大内存服务器上,所有 page 结构体的总大小可达 GB 级,这是物理内存的一笔固定开销。
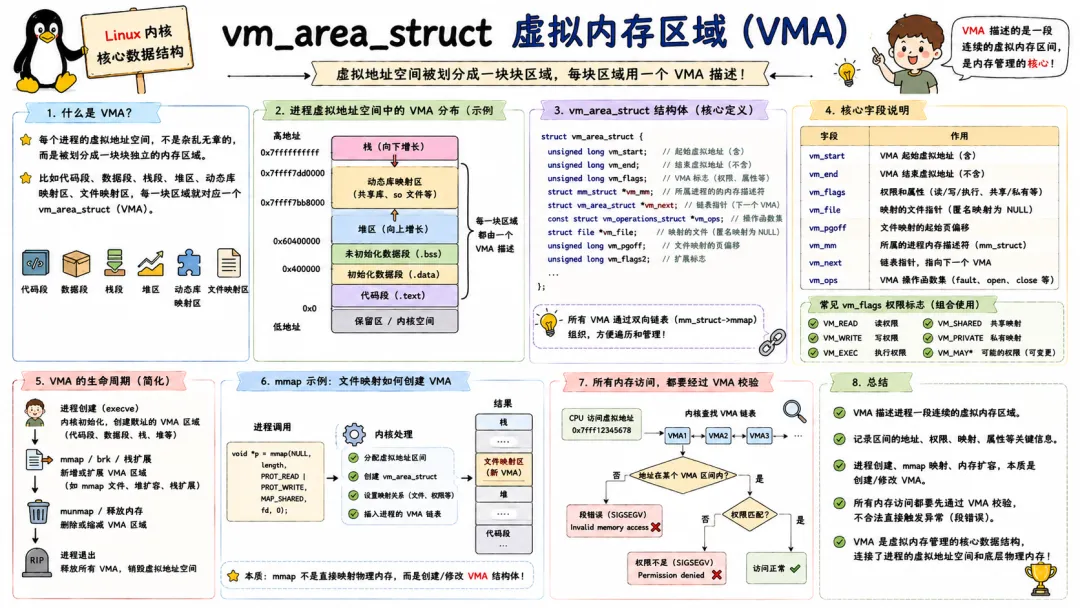
3.2 vm_area_struct 虚拟内存区域(VMA)
进程的地址空间并不是一整块内存,而是由一段段虚拟内存区域组成的,每一段就是一个 vm_area_struct,简称 VMA。
每个 VMA 描述了进程地址空间里一段连续虚拟地址的属性:起始/结束地址、访问权限(可读/可写/可执行)、映射类型(文件映射/匿名映射)。当进程 mmap 一个文件,或者 malloc 一块大内存时,内核就会创建或扩展对应的 VMA。
VMA 用链表和红黑树两种方式组织:mm_struct 里一个链表链接所有 VMA,同时用红黑树加速查找。当发生缺页异常时,内核必须在 VMA 树里快速定位到发生异常的地址所属的 VMA,才能决定如何处理这次缺页。
日常开发中,如果一个进程 SIGSEGV 段错误,你查看 /proc/pid/maps 看到的每一行,就是一个 VMA。有了 VMA,才实现了 demand paging、写时复制、内存锁等高级特性。
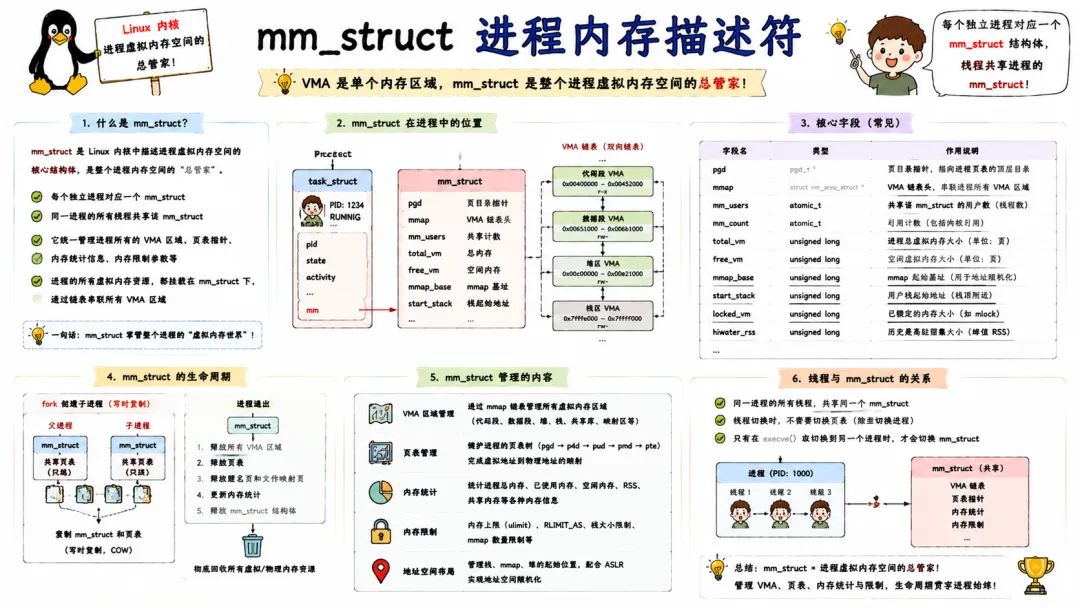
3.3 mm_struct 进程内存描述符
一个进程的整个虚拟地址空间,全封装在 mm_struct 里。task_struct 中的 mm 指针指向它。
mm_struct 里面装了进程的内存全局信息:VMA 链表头和红黑树根、页表指针(pgd)、mmap 锁、内存映射段基地址、堆栈区间、VSZ 和 RSS 统计、引用计数等。
在创建进程时,fork() 会利用写时复制(COW)复制父进程的 mm_struct;而线程则共享同一个 mm_struct,这正是线程共享地址空间的根本原因。
做内存压力分析和性能剖析时,经常需要看 mm_struct 中的 total_vm、locked_vm、pinned_vm,来判断进程用了多少虚拟内存、锁定了多少物理页。如果系统 OOM,mm_struct 的 oom_score_adj 也会直接影响哪个进程被优先杀掉。
四、文件系统核心数据结构(3 个)
Linux 里一切皆文件,下面这三个结构体,就是文件系统的"铁三角",直接决定了 VFS "一切皆文件"的抽象能力。管你是磁盘上的 txt,还是鼠标、网卡、甚至是一个进程,在内核里统统被抽象成文件。
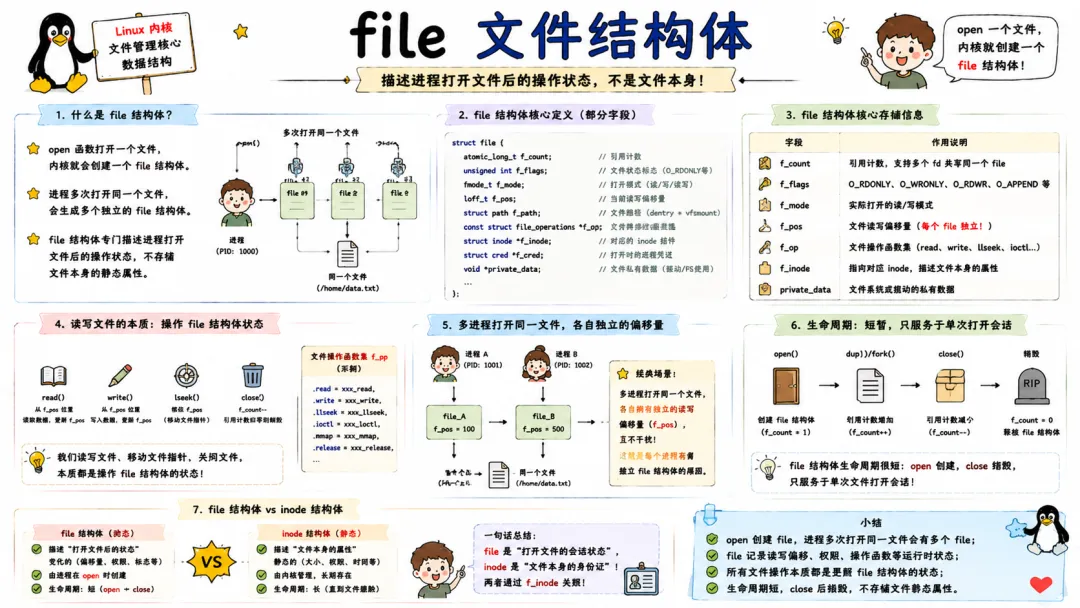
4.1 file 文件结构体
struct file 是文件打开后的"内核级句柄"。用户态拿到的 fd,内核里就对应着一个 file 结构。
file 里记录当前读写位置(f_pos)、打开标志(f_flags,如 O_RDONLY)、指向 file_operations 的指针(里面包含 read、write、mmap 等函数指针),以及指向对应 dentry 和 inode 的指针。
一个文件可以被多次打开,每次 open 都生成一个新的 file 结构体,但多个 file 可以共享同一个 dentry 和 inode。这也是父子进程打开同一个文件时,文件偏移量相互独立的原因,因为它们各自有一个 file 结构体。
在内核态开发中,你会经常使用 filp_open 打开文件,直接拿到 file 指针,然后通过 kernel_read / kernel_write 进行读写。但要牢记,file 结构体的引用计数必须正确管理,fget / fput 配对,否则会导致文件无法关闭甚至内核资源泄漏。
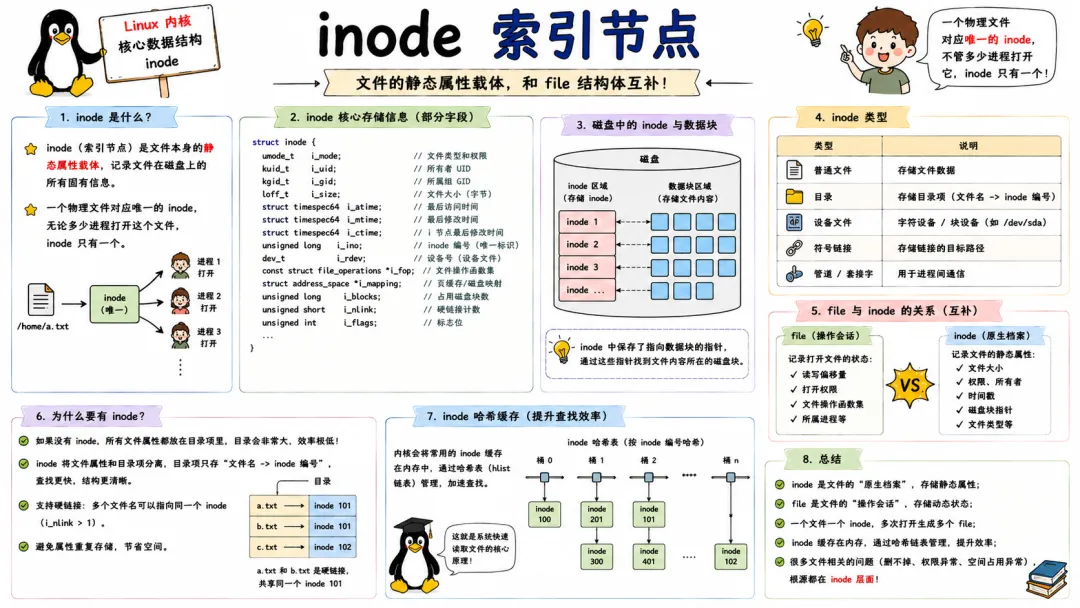
4.2 inode 索引节点
inode 是文件系统里的唯一标识,代表一个真实的文件或目录。它和 file 不同:一个 inode 对应磁盘上一个实实在在的对象,而 file 只是打开该对象产生的一个访问实例。
inode 里存了文件的几乎所有元数据:文件大小、访问时间、修改时间、权限、所有者、块映射信息等。内核在读写文件时,必须先把 inode 加载到内存中,然后通过 inode 中的地址空间(address_space)来缓存文件数据。
inode 的生命周期比 file 长得多。即使文件没有被任何进程打开,inode 只要在缓存中,就能加速下一次访问。当系统内存紧张时,内核会回收未使用的 inode 缓存。做文件系统优化时,调整 /proc/sys/vm/vfs_cache_pressure 可以控制 inode / dentry 缓存的回收倾向。
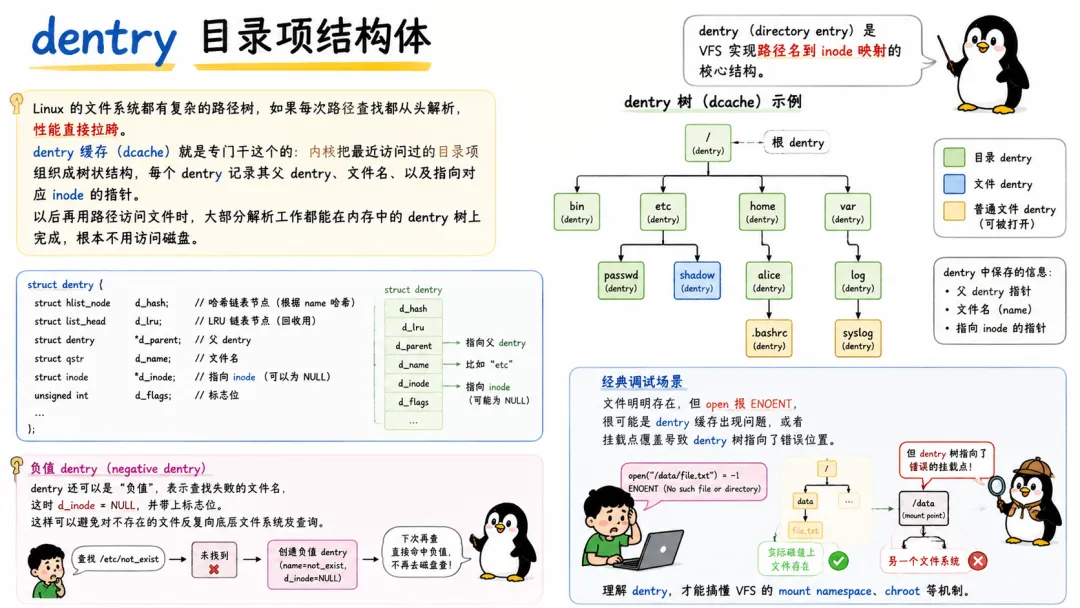
4.3 dentry 目录项结构体
dentry(directory entry)是 VFS 实现路径名到 inode 映射的核心结构。
Linux 的文件系统都有复杂的路径树,如果每次路径查找都从头解析,性能直接拉胯。dentry 缓存(dcache)就是专门干这个的:内核把最近访问过的目录项组织成树状结构,每个 dentry 记录其父 dentry、文件名、以及指向对应 inode 的指针。以后再用路径访问文件时,大部分解析工作都能在内存中的 dentry 树上完成,根本不用访问磁盘。
dentry 还可以是"负值"(negative dentry),表示查找失败的文件名,这样可以避免对不存在的文件反复向底层文件系统发查询。
一个经典的内核调试场景:文件明明存在,但 open 报 ENOENT,很可能就是 dentry 缓存出现问题,或者挂载点覆盖导致 dentry 树指向了错误位置。理解 dentry,才能搞懂 VFS 的 mount namespace、chroot 等机制。
五、内核同步与阻塞数据结构(3 个)
内核里有很多并行的任务,抢占、中断、多核争抢随时发生。为了防止数据被写烂,或者为了让进程在没数据时乖乖睡觉,就需要这些同步与阻塞结构。
下面这三个,覆盖了 90% 的同步和阻塞场景。
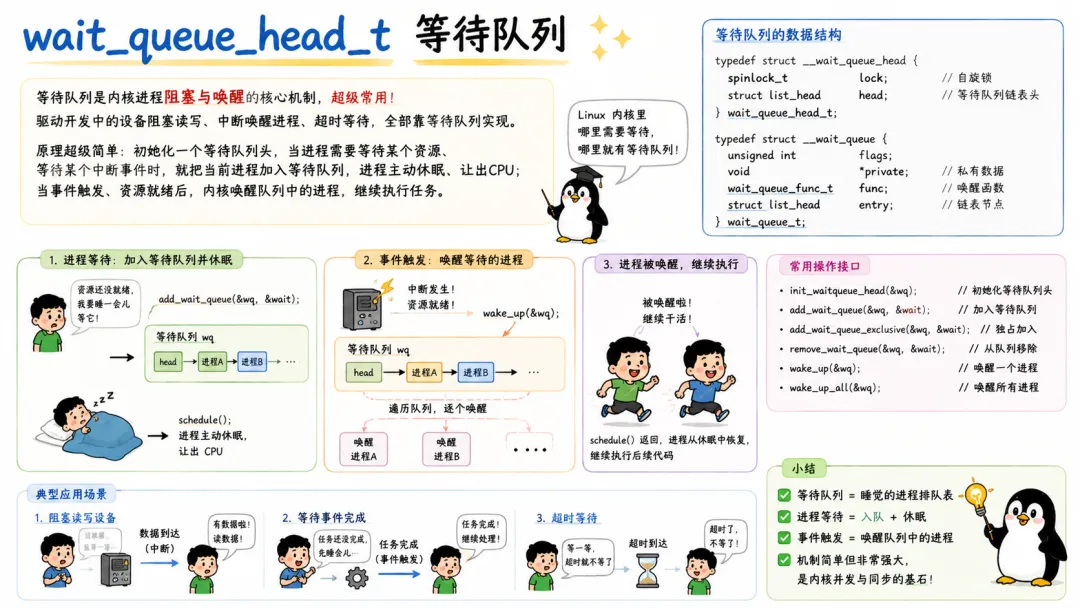
5.1 wait_queue_head_t 等待队列
内核里进程阻塞的基石,就是等待队列。当进程需要等待某个条件(如设备可读、IO 完成、定时器到期)时,它就通过等待队列进入睡眠状态,条件满足后再被唤醒。
一个典型的等待队列使用流程长这样:
DECLARE_WAIT_QUEUE_HEAD(my_queue);// 等待方wait_event(my_queue, condition);// 唤醒方condition = 1;wake_up(&my_queue);
看着简单,但背后涉及进程状态切换、schedule() 调度、竞态处理等一堆细节。等待队列可以配置为互斥等待,以避免"惊群"问题(多个进程被同时唤醒,但只有一个能处理条件)。
在字符设备驱动、信号处理、completion 机制中,等待队列都扮演核心角色。如果你想理解阻塞 IO 和 epoll 的内部原理,先把 wait_queue 吃透。
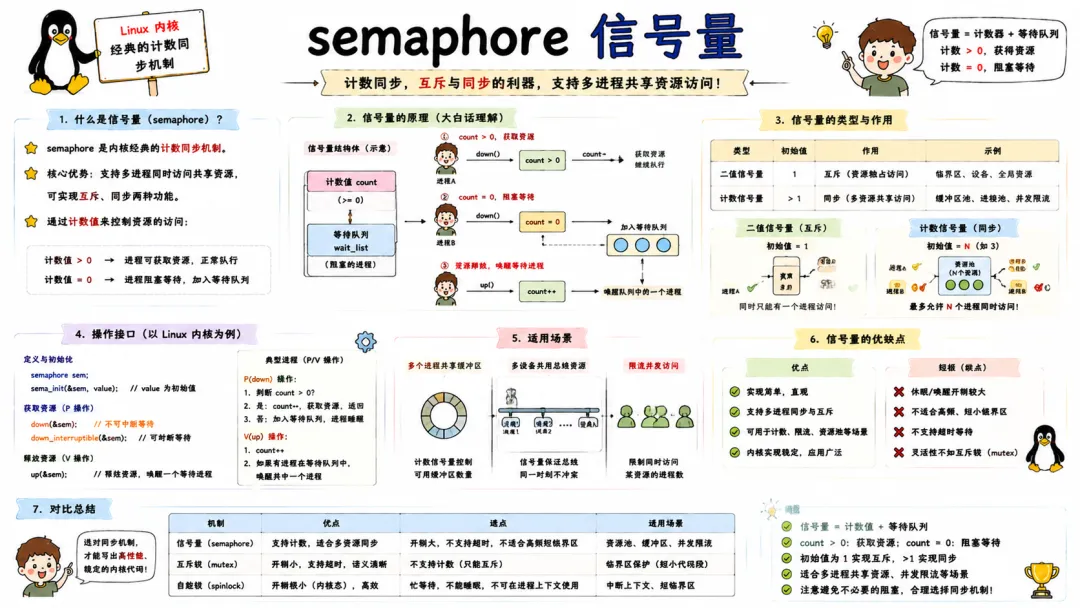
5.2 semaphore 信号量
信号量是是内核经典的计数同步机制,支持多个持有者。二进制信号量退化为互斥锁,计数信号量则能控制并发访问资源的最大数量。
在内核中,用 struct semaphore 表示,通过 down() 获取(如果计数为 0 则阻塞),up() 释放。它的实现底层仍然依赖等待队列和原子操作。
信号量允许在中断上下文中使用 up() 唤醒等待者,但不允许在中断中调用可能阻塞的 down(),这点在写驱动时必须时刻警惕。常见的死锁场景就是进程持有一个信号量然后睡眠,导致其他进程永久等待。
5.3 mutex 互斥锁
mutex 是信号量的轻量级替代品,专门用于一对一互斥保护。它的语义更简单:同一时间只允许一个拥有者,不上计数,不支持递归加锁。
与自旋锁相比,mutex 在竞争时会睡眠让出 CPU,所以只能用在线程上下文(中断上下文绝不能碰 mutex)。与信号量相比,mutex 有严格的 lock owner 检查,有死锁检测(CONFIG_DEBUG_MUTEXES)等调试支持,性能也更好。
现代内核里,大部分临界区保护都用 mutex,只有需要在中断上下文或者需要极短持锁的场景才用自旋锁。写内核代码有一个黄金法则:能用 mutex 就别用 semaphore,语义清晰、调试友好。
六、网络栈核心数据结构(1 个)
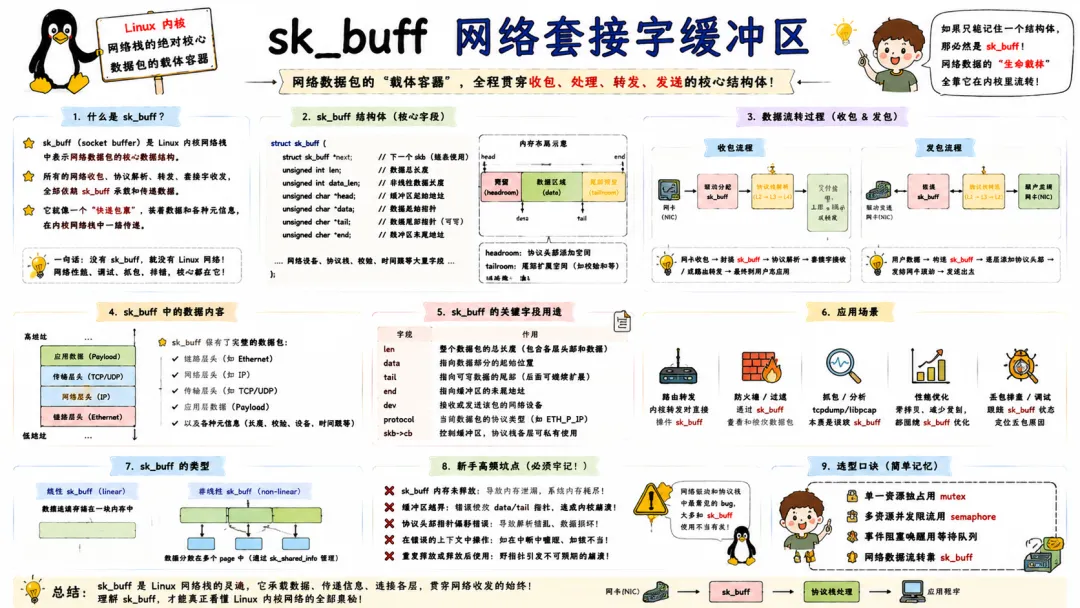
Linux 网络性能为什么强?大名鼎鼎的 sk_buff 居头顶功。
6.1 sk_buff 网络套接字缓冲区
Linux 网络栈里最核心的数据结构,没有之一。sk_buff 贯穿网络数据包的整个生命周期,从网卡驱动接收到最后交给用户态 socket,全链路都是用 sk_buff 承载数据。
一个 sk_buff 不仅包含数据包本身,还携带大量元信息:头部指针(transport_header、network_header、mac_header)、网络设备信息(dev)、套接字关联(sk)、协议类型、校验和、分段信息等。
它采用了分段存储与非线性缓冲区设计:数据存储在线性区(headroom + data + tailroom)和分片页(frags)中,可以高效地添加/剥离协议头部,而无需复制整个数据包。这也是为什么内核网络性能如此之高的原因之一。
开发网络驱动、netfilter 钩子或者 eBPF 程序时,你几乎无处不在地和 sk_buff 打交道:克隆、释放、线性化、调整头部空间……一定要小心 sk_buff 的引用计数,一次疏忽就可能导致内存泄漏或者 double free,直接内核崩溃。
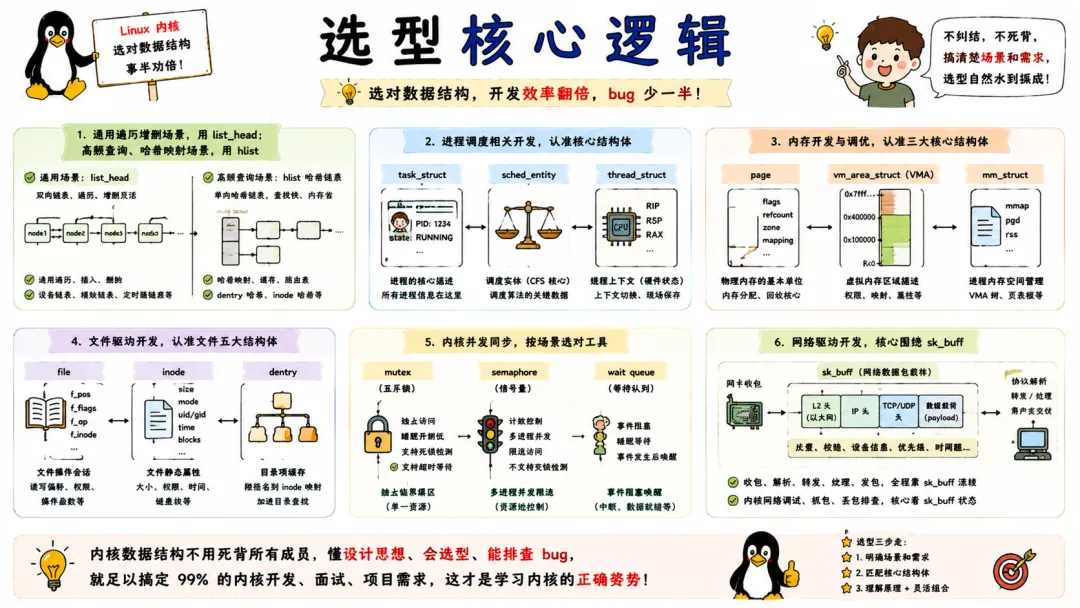
七、核心数据结构选型 & 调试
7.1 15 个核心结构选型对照表
唠到这儿,你一定也发现了,内核数据结构没有谁天下第一,只有在特定上下文中谁最合适:
| | | | |
|---|
list_head | | | container_of | 死循环、忘记用 list_for_each_entry_safe |
hlist_head | | | pprev | |
task_struct | | | 字段极多,current 快速获取,clone_flags 区分进程/线程 | 混淆 tgid 和 pid,忘记 RCU 保护读取 |
thread_struct | | | | |
sched_entity | CFS | | | |
page | | | | page |
vm_area_struct | | | | |
mm_struct | | | | OOM |
file | | | | |
inode | | | | |
dentry | | | | dentry |
wait_queue | | | | |
semaphore | | | down | |
mutex | | | | |
sk_buff | | | | alloc_skb |
选型其实就两句话:一眼看需求,二眼看约束。需要通用链表选 list_head,需要哈希选 hlist,进程表示用 task_struct,同步保护优先 mutex,网络数据包就是 sk_buff。
7.2 内核数据结构调试核心技巧
内核数据结构出问题,没有 Segmentation Fault 弹窗,只有死机、panic、内存破坏或者石沉大海般的 hang。我的调试三板斧:printk 打桩、ftrace 跟踪、crash dump 分析,覆盖 90% 以上的内核数据结构故障。
printk + dmesg:最古老但最可靠的办法。在可疑的数据结构操作前后打印关键指针、引用计数、状态字段。如果内核还没完全死透,dmesg 能看到最后的挣扎。切记打印时不要加锁,避免引入新 bug。
ftrace + tracepoint:想动态跟踪进程调度、文件系统调用、内存分配?ftrace 是你最好的朋友。比如打开 sched_switch 事件,你能看到 vruntime 是怎么影响进程切换的;跟踪 kmalloc / kfree,能发现谁偷偷释放了还在用的 page。
crash 工具分析 vmcore:一旦内核 panic,生成的 vmcore 就是案发现场的"尸检报告"。用 crash 命令可以直接查看 task_struct、mm_struct、list_head 等所有内核结构体的当时状态,遍历链表、红黑树,甚至重建调用栈。这是定位数据结构破坏的终极手段。
核心调试原则:先隔离,再追踪,最后看现场。不要一看到 panic 就乱改代码,先用 printk 缩小范围,用 ftrace 确认执行路径,最后用 crash 还原死亡瞬间的数据结构状态。绝大部分数据结构翻车,都是并发竞争、引用计数漏加、或者内存踩踏造成的,慢下来分析,比瞎蒙有效得多。
内核数据结构,把 list_head 玩顺了,链表驱动不在话下;把 task_struct 看透了,进程管理一目了然;把 sk_buff 嚼烂了,网络栈任你驰骋。
加油,头发重要,但理解内核更酷!