说明:
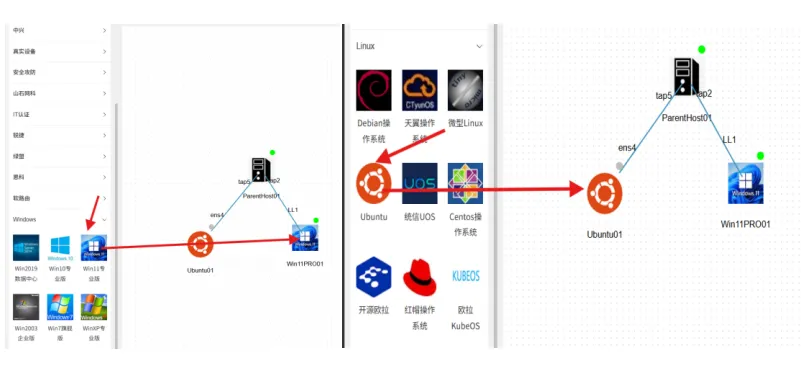
1.本实验使用翼航仿真平台,相关软件已经预先存放到相关目录(Ubuntu的/root/deepseek,Win11的e盘),创建拓朴如下图。
2.Ubuntu使用版本20.04
3.使用WIN11
4.无需安装GPU驱动
5.deepseek模型使用1.5B,请修改对应的参数。
一、部署前的准备工作
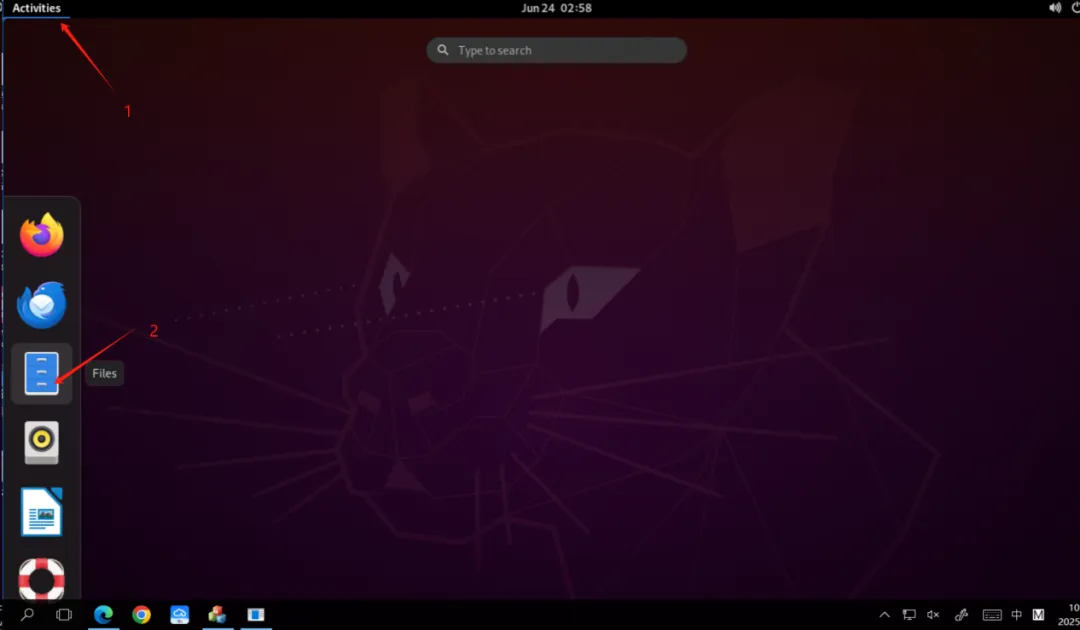
1.进入到测试系统中的“files”
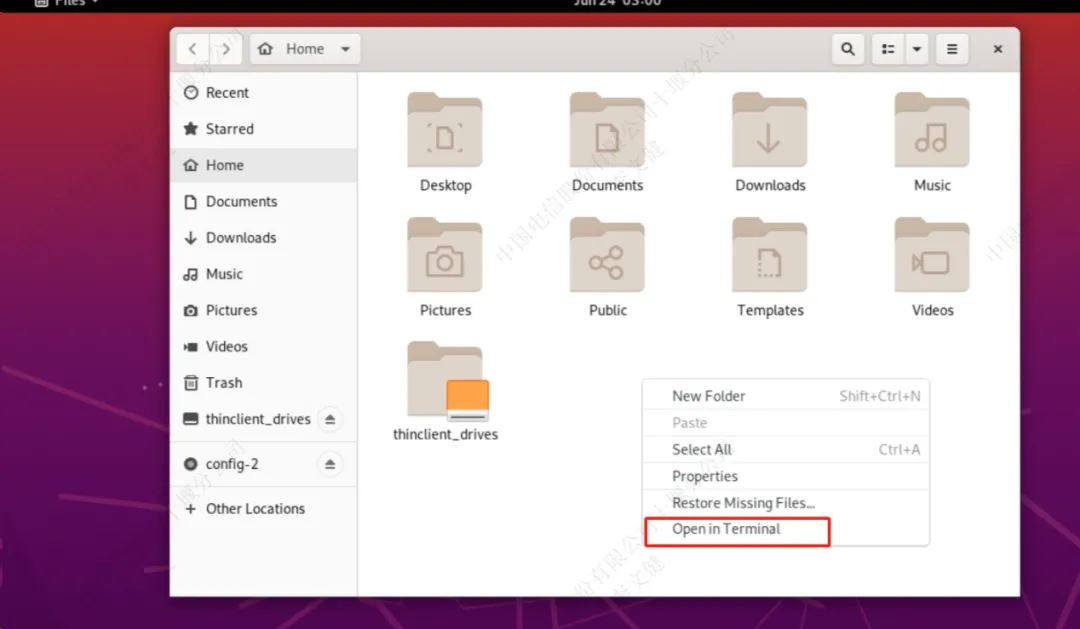
2.右键进入到系统终端
3.在终端中进入到deepseek资源目录中,并对”deepseek-v0.1.0.tar.gz“进行解压
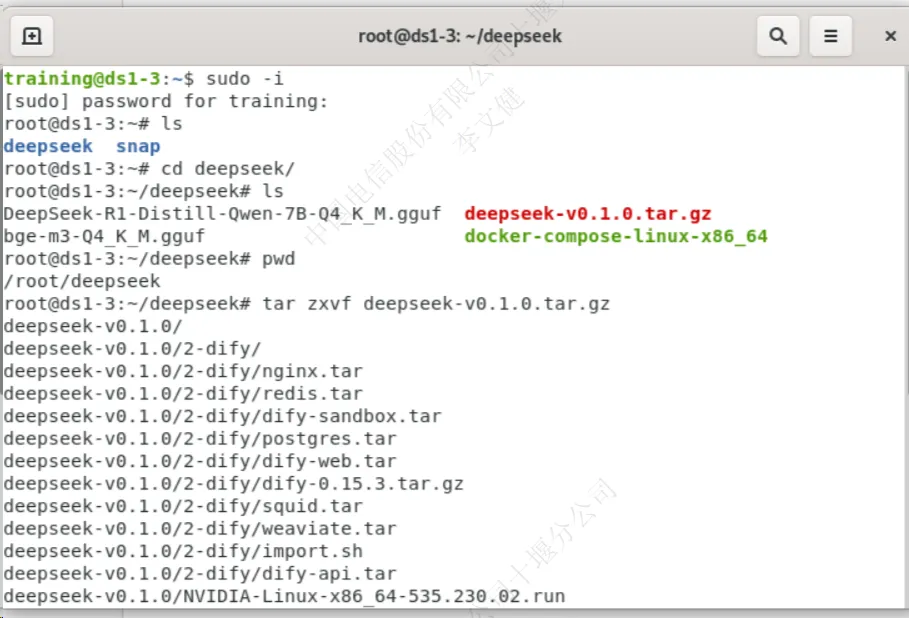
###临时切换到 root 用户 sudo -i ###切换到deepseek目录 cd /root/deepseek ###对”deepseek-v0.1.0.tar.gz“压缩文件进行解压并进入解压后的目录 tar zxvf deepseek-v0.1.0.tar.gz cd deepseek-v0.1.0/ |
二、驱动安装
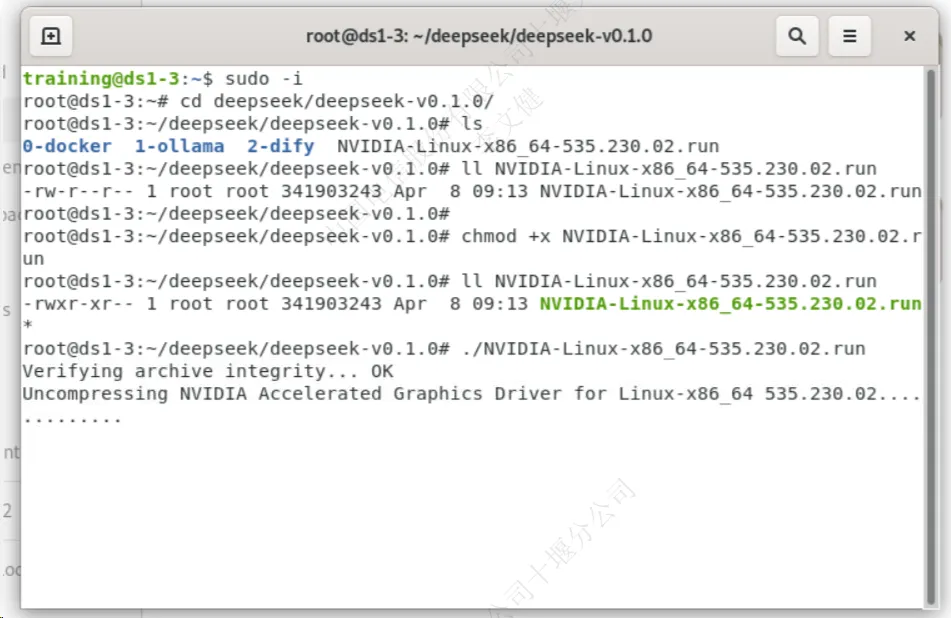
###给Nvidia驱动文件赋予执行权限 chmod +x NVIDIA-Linux-x86_64-535.230.02.run ###进行驱动安装 ./NVIDIA-Linux-x86_64-535.230.02.run |
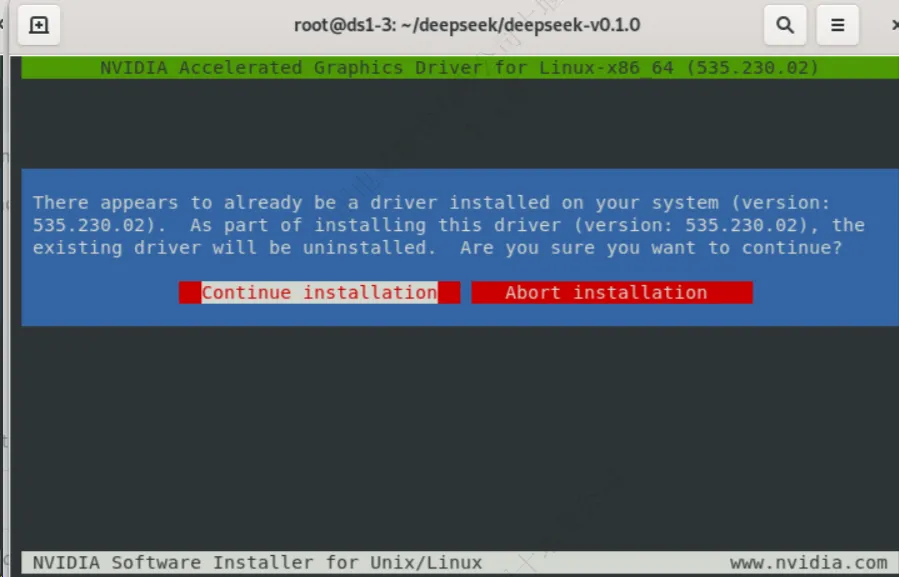
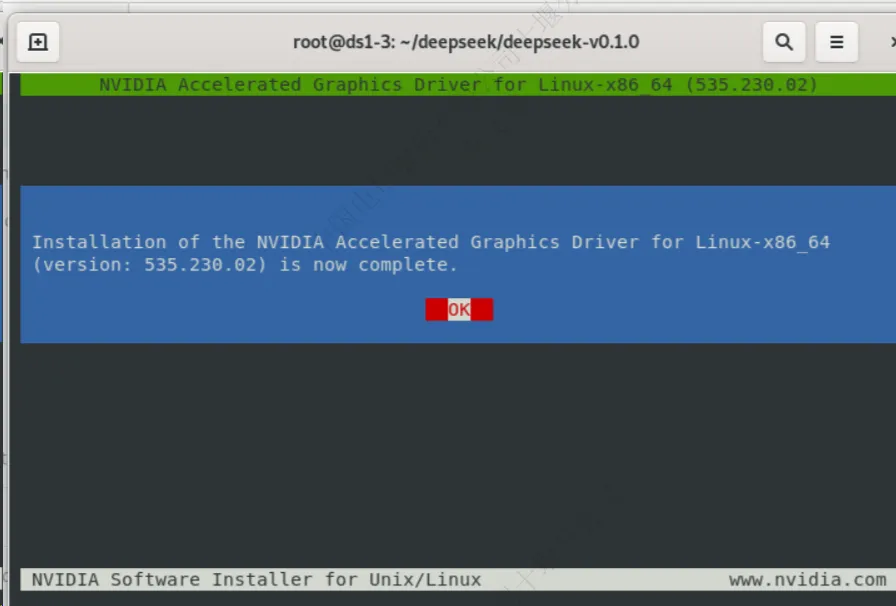
Nvidia驱动安装完毕
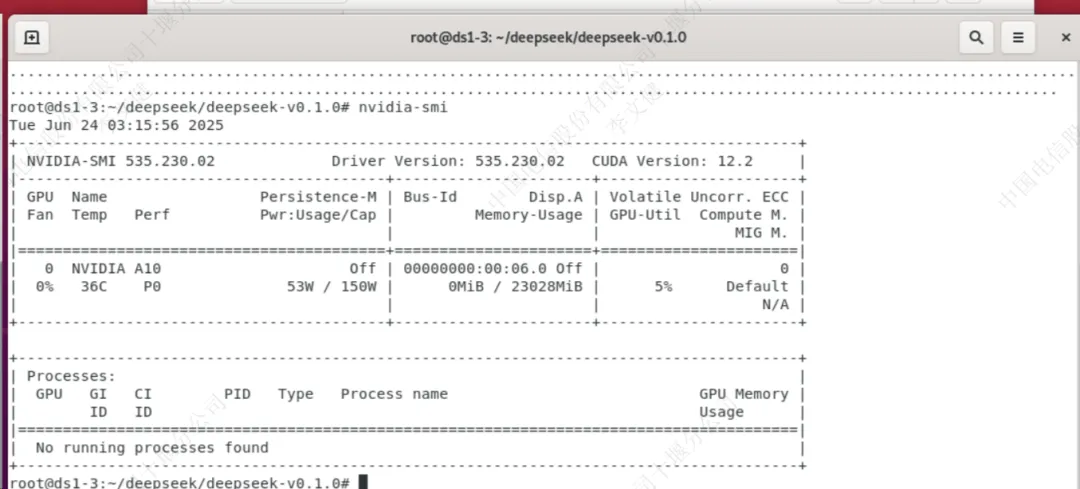
使用”nvidia-smi“命令验证驱动安装是否成功
三、Docker、Ollama、dify的部署安装
1.docker的安装
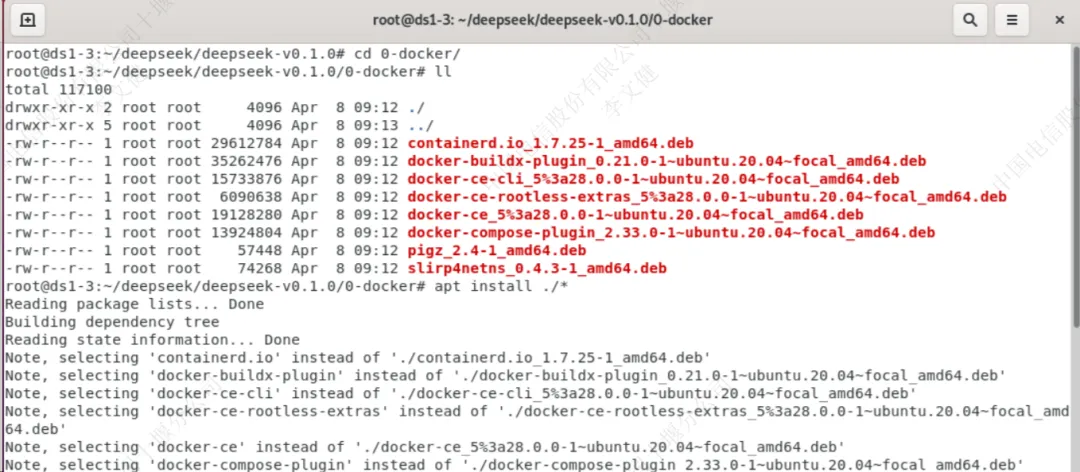
###进入到0-docker目录里 cd 0-docker/ ###安装docker文件 apt install ./* |
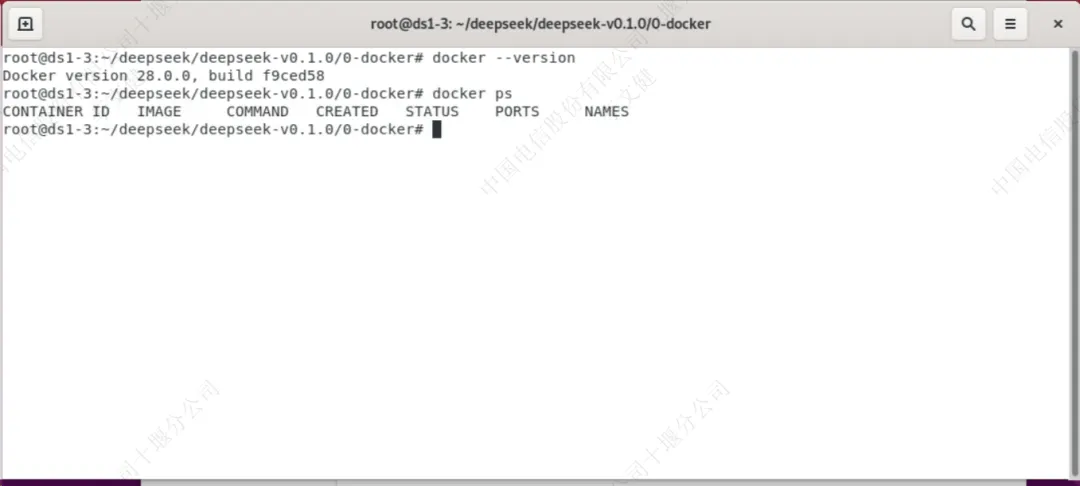
使用”docker --version“验证docker的安装
附:Docker的常用命令
# 拉取镜像(如官方Nginx镜像) docker pull nginx # 运行容器(-d 后台运行,-p 映射端口) docker run -d -p 80:80 nginx # 查看运行中的容器 docker ps # 构建镜像(基于当前目录的Dockerfile) docker build -t my-app . # 进入容器内部 docker exec -it <容器ID> /bin/bash |
2.ollama离线部署
(一)ollama离线安装
进入到”1-ollama“目录中,并对压缩文件进行解压
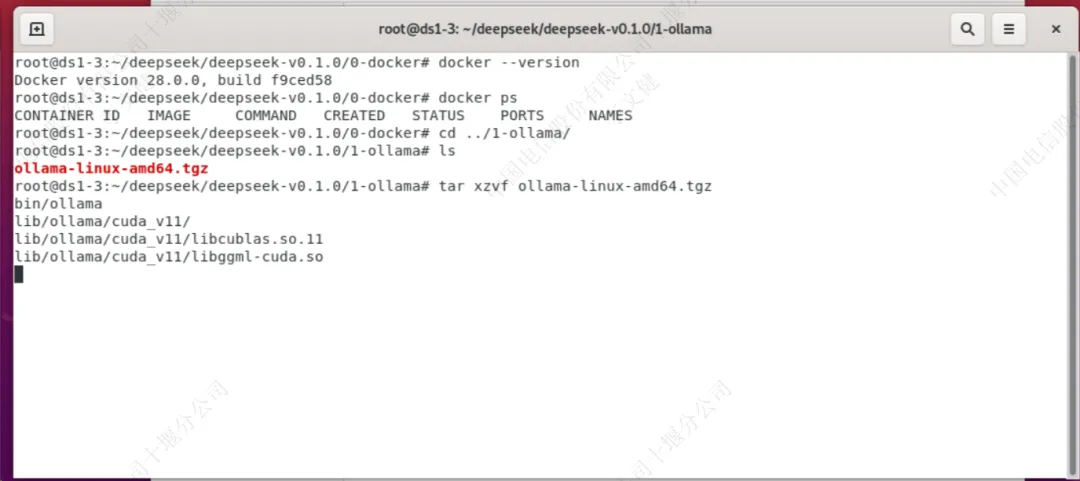
root@ds1-3:~/deepseek/deepseek-v0.1.0/0-docker# cd ../1-ollama/ root@ds1-3:~/deepseek/deepseek-v0.1.0/1-ollama# tar xzvf ollama-linux-amd64.tgz |
将ollama目录中的执行文件复制到”/bin”目录里,并使用“ollama serve”启动ollama服务
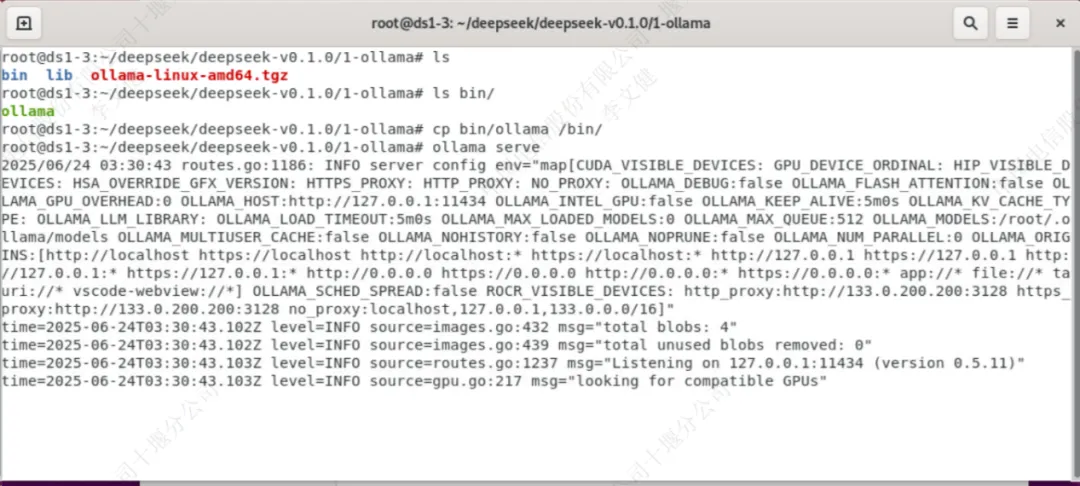
###将ollama目录中的执行文件复制到”/bin”目录里 root@ds1-3:~/deepseek/deepseek-v0.1.0/1-ollama# cp bin/ollama /bin/ ###启动ollama服务 root@ds1-3:~/deepseek/deepseek-v0.1.0/1-ollama# ollama serve |
创建systemd服务文件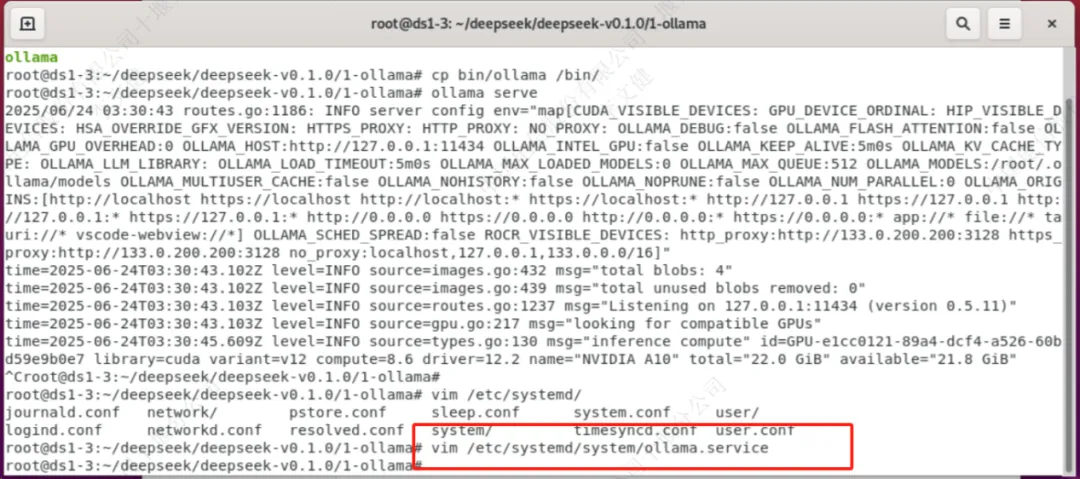
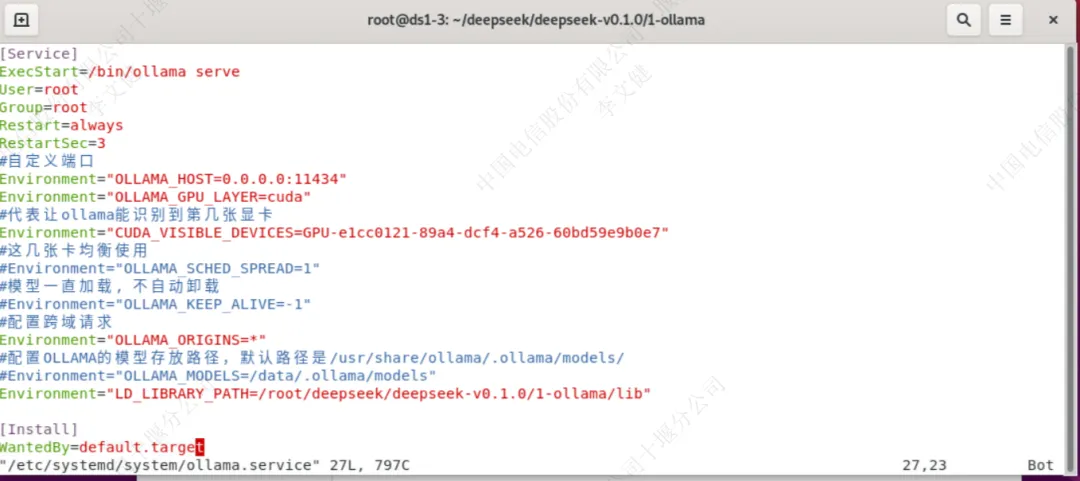
vim /etc/systemd/system/ollama.service |
ollama.service文件内容如下
[Service] ExecStart=/bin/ollama serve User=root Group=root Restart=always RestartSec=3 #自定义端口 Environment="OLLAMA_HOST=0.0.0.0:11434" Environment="OLLAMA_GPU_LAYER=cuda" #代表让ollama能识别到第几张显卡 Environment="CUDA_VISIBLE_DEVICES=0" #这几张卡均衡使用 #Environment="OLLAMA_SCHED_SPREAD=1" #模型一直加载, 不自动卸载 #Environment="OLLAMA_KEEP_ALIVE=-1" #配置跨域请求 Environment="OLLAMA_ORIGINS=*" #配置OLLAMA的模型存放路径,默认路径是/usr/share/ollama/.ollama/models/ #Environment="OLLAMA_MODELS=/data/.ollama/models" Environment="LD_LIBRARY_PATH=/root/deepseek/deepseek-v0.1.0/1-ollama/lib" [Install] WantedBy=default.target |
编辑完成后,点击“ESC”退出编辑模式并键入“:wq”进行保存退出
###退出文件编辑界面后,需重新载入 systemd 配置 systemctl daemon-reload ###启动ollama服务 systemctl start ollama ###设置开机自启 systemctl enable ollama ###查看ollama服务状态 systemctl status ollama |
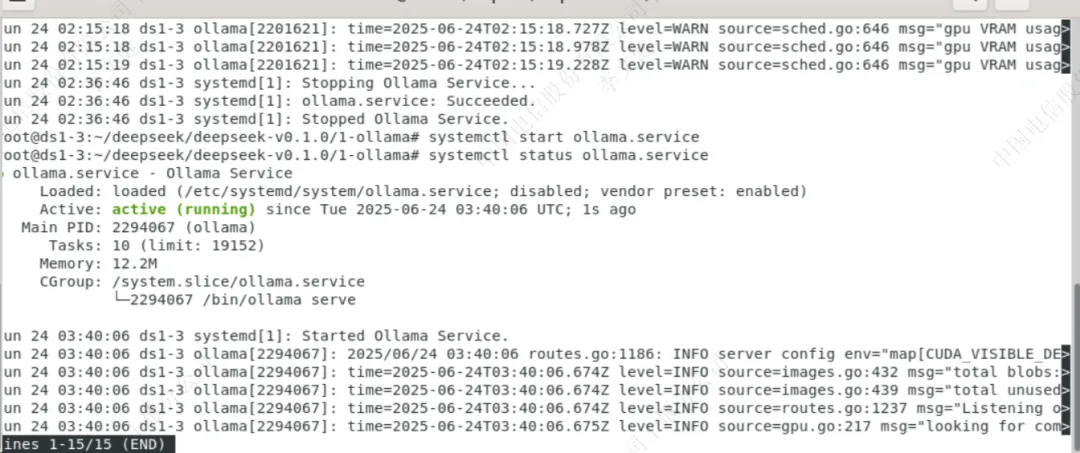
(二)使用ollama导入模型
进入到“/root/deepseek”目录,添加“deepseek7B.mf”和“bge-m3.mf”文件
cd /root/deepseek vim deepseek7B.mf vim bge-m3.mf |
deepseek7B.mf文件内容如下:
FROM ./DeepSeek-R1-Distill-Qwen-7B-Q4_K_M.gguf |
bge-m3.mf文件内容如下
FROM ./bge-m3-Q4_K_M.gguf |
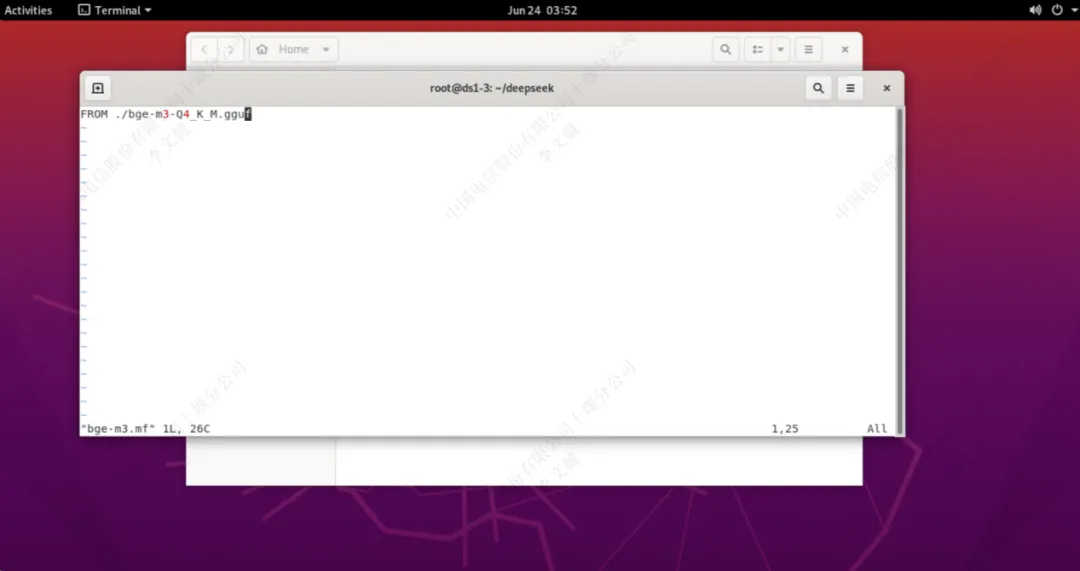
编辑完成后,点击“ESC”退出编辑模式并键入“:wq”进行保存退出
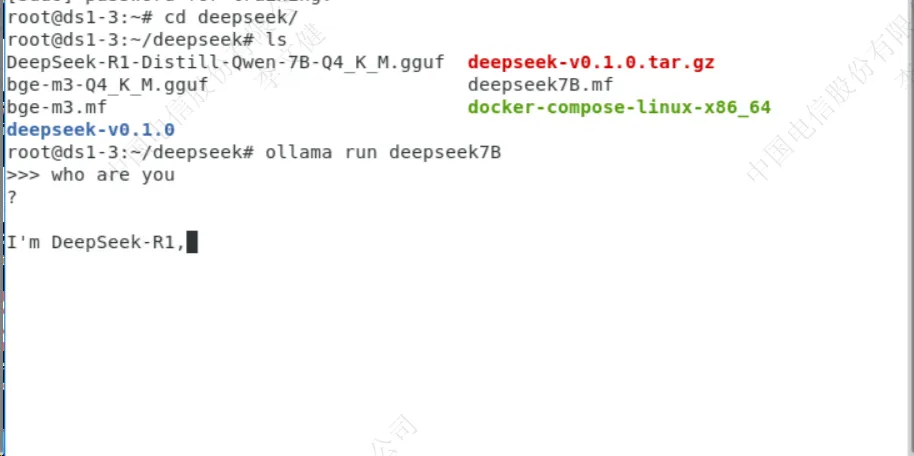
使用ollama加载模型
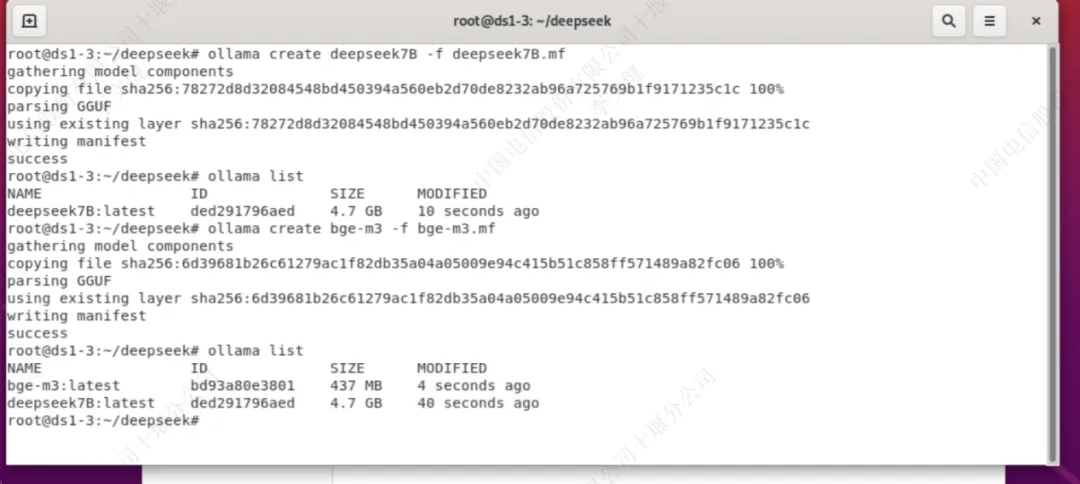
使用“ollama run 模型名”可以运行对应的模型
3.dify部署
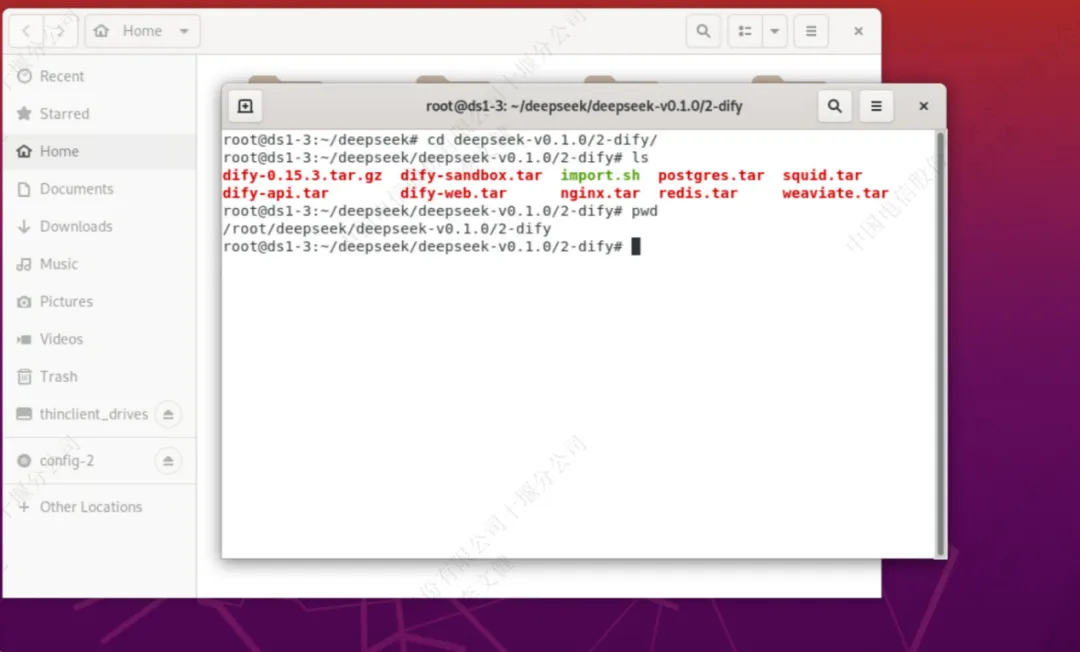
首先进入到dify目录里
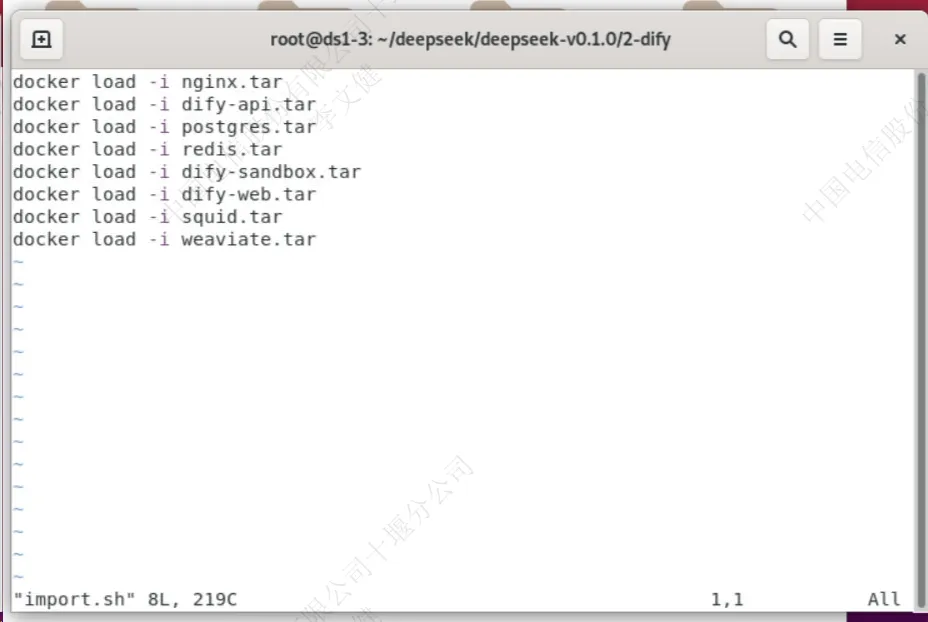
执行“import.sh”导入dify所需的docker镜像
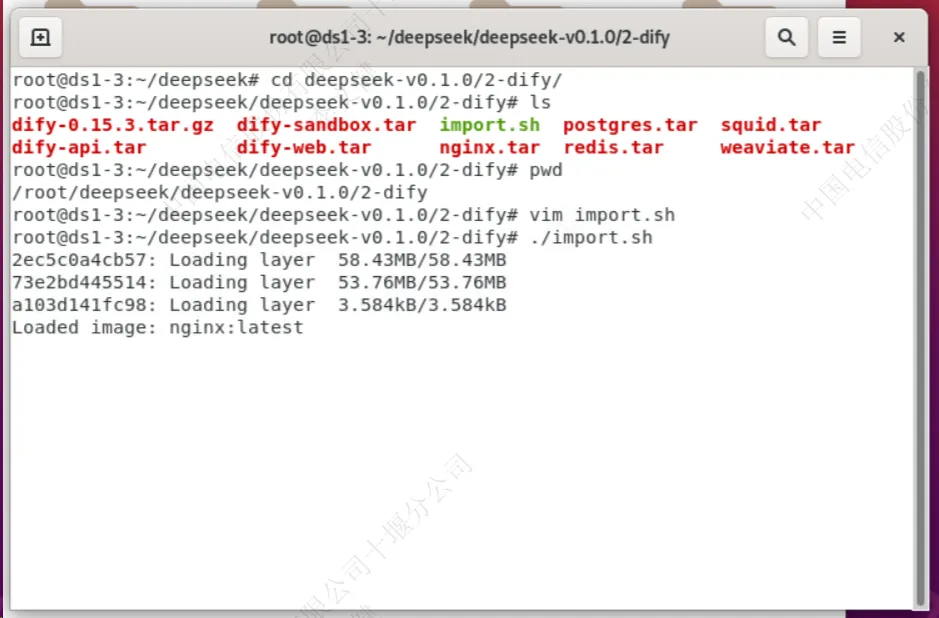
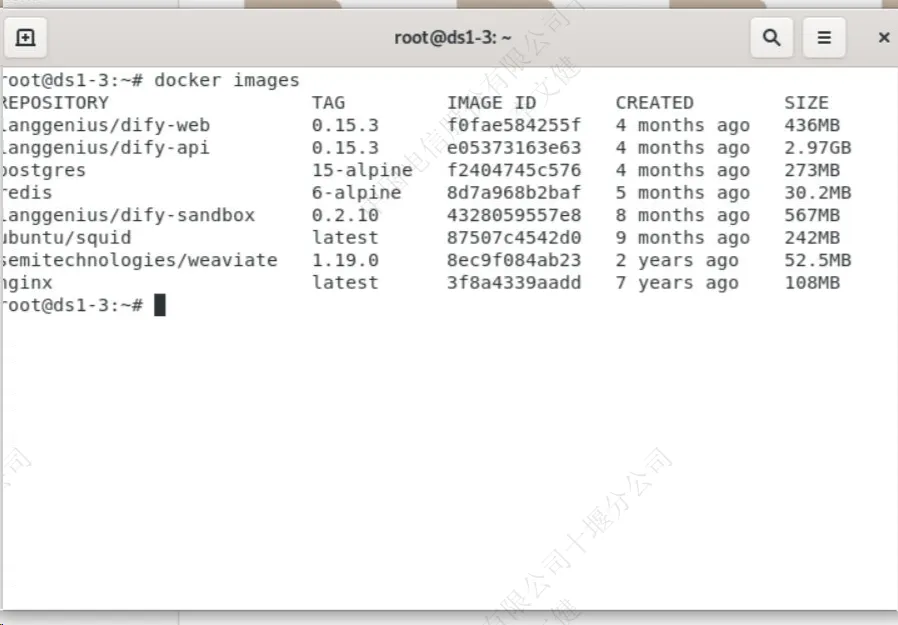
使用命令“docker images”查看加载的模型
解压dify压缩文件并进去到解压目录里
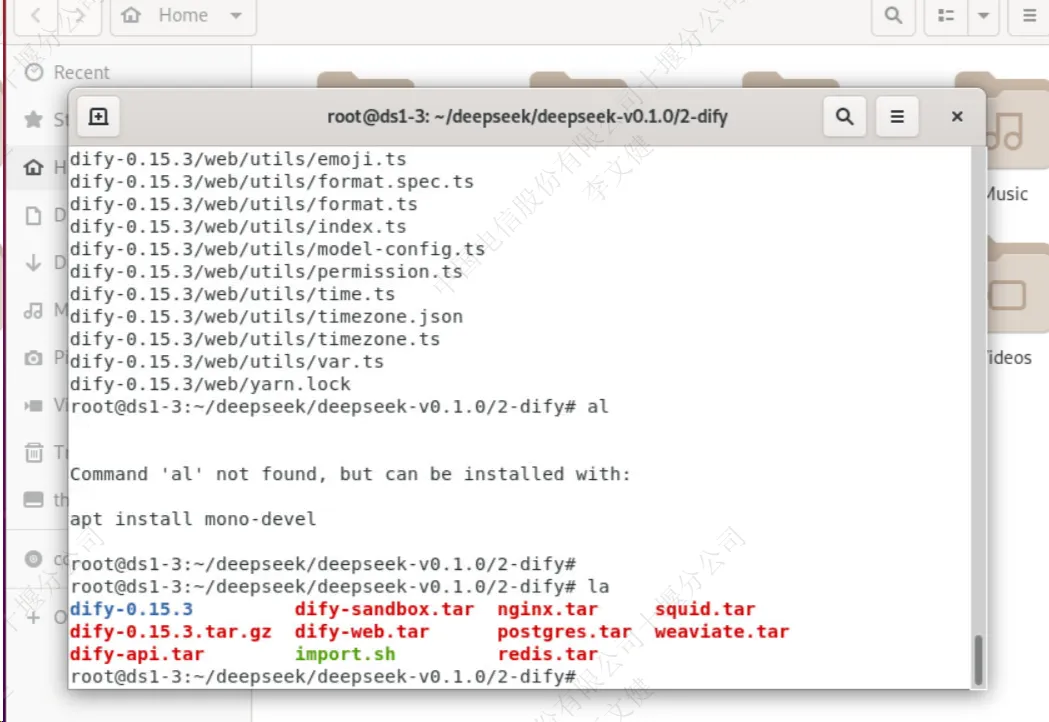
cd /root/deepseek/deepseek-v0.1.0/2-dify ###解压dify压缩文件 tar zxvf dify-0.15.3.tar.gz |
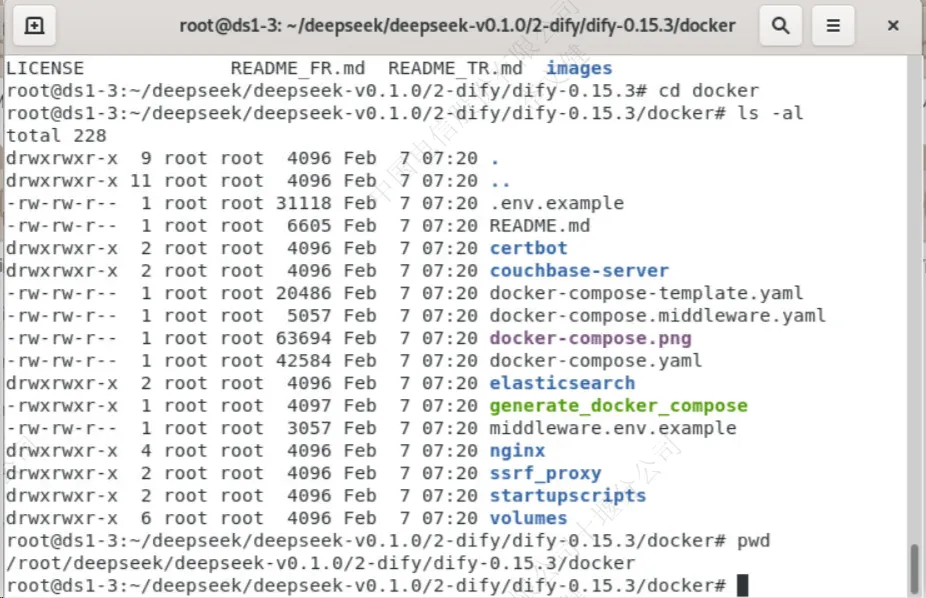
进入到dify文件中的docker目录里
将“.env”配置文件后缀去掉,并运行docker compose起容器
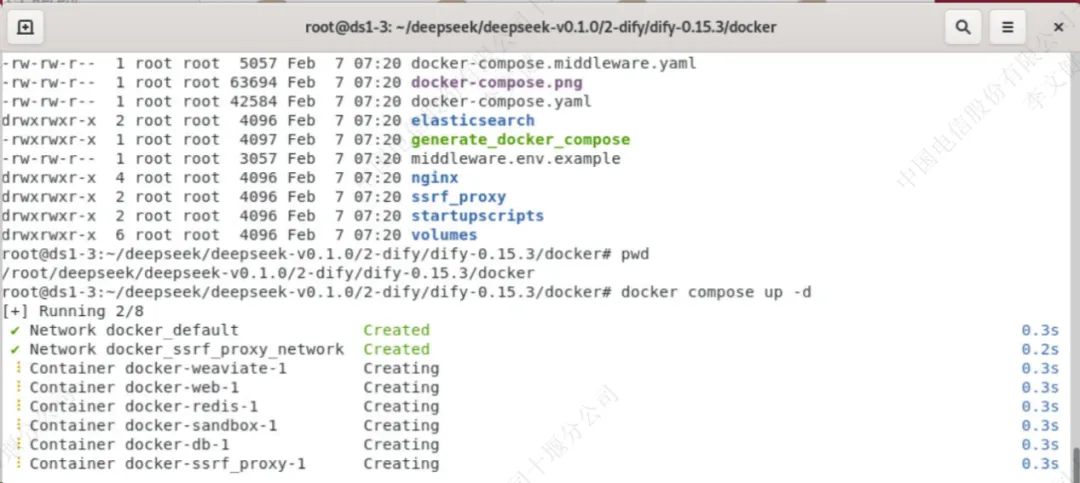
cp .env.example .env ###起dify容器 docker compose up -d |
静待几秒钟,使用“docker ps”命令查看容器启动状态
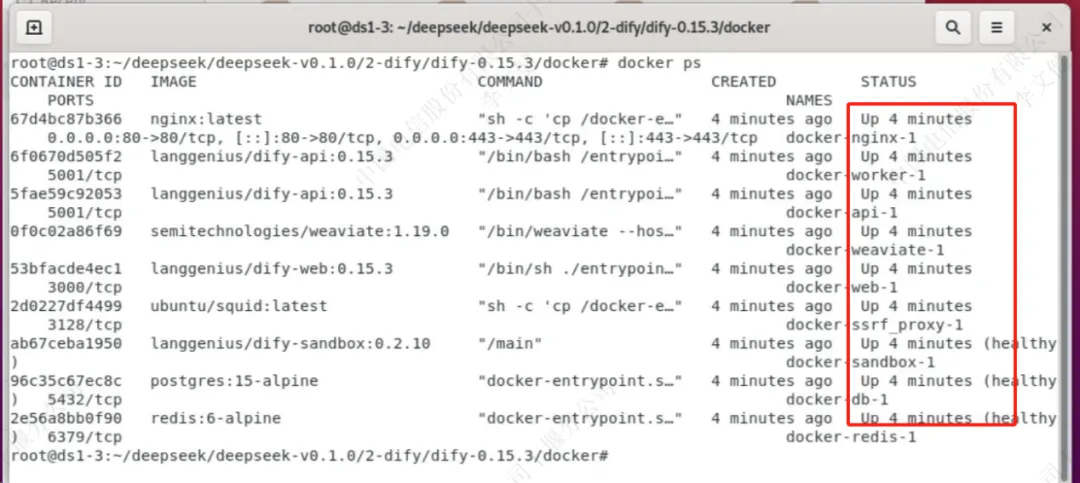
没问题后就可使用浏览器访问
访问地址:http://localhost:80
进入dify设置管理员邮箱、用户名、密码
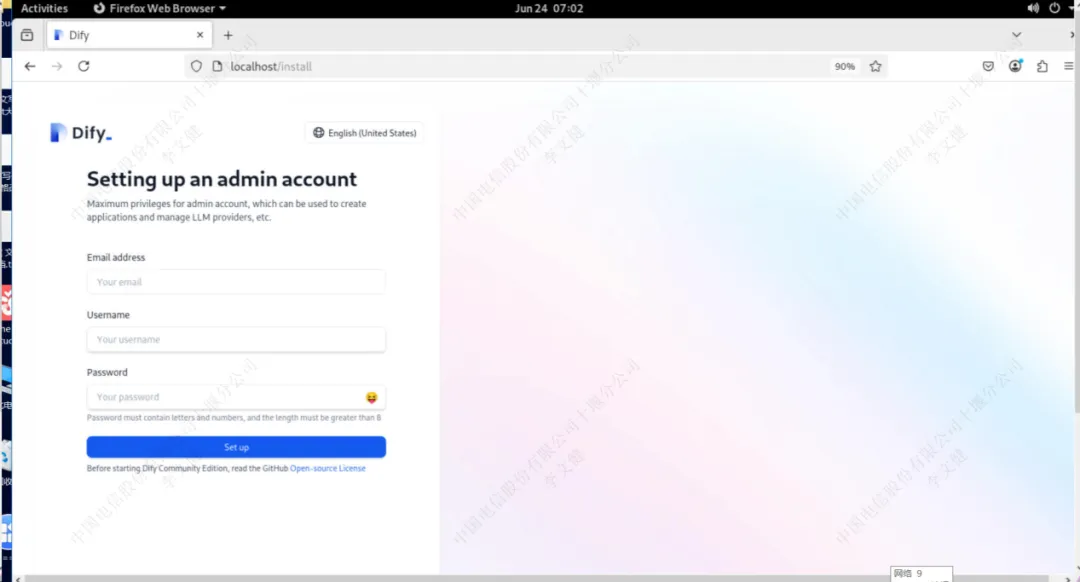
输入管理员信息完毕后即可进入dify页面
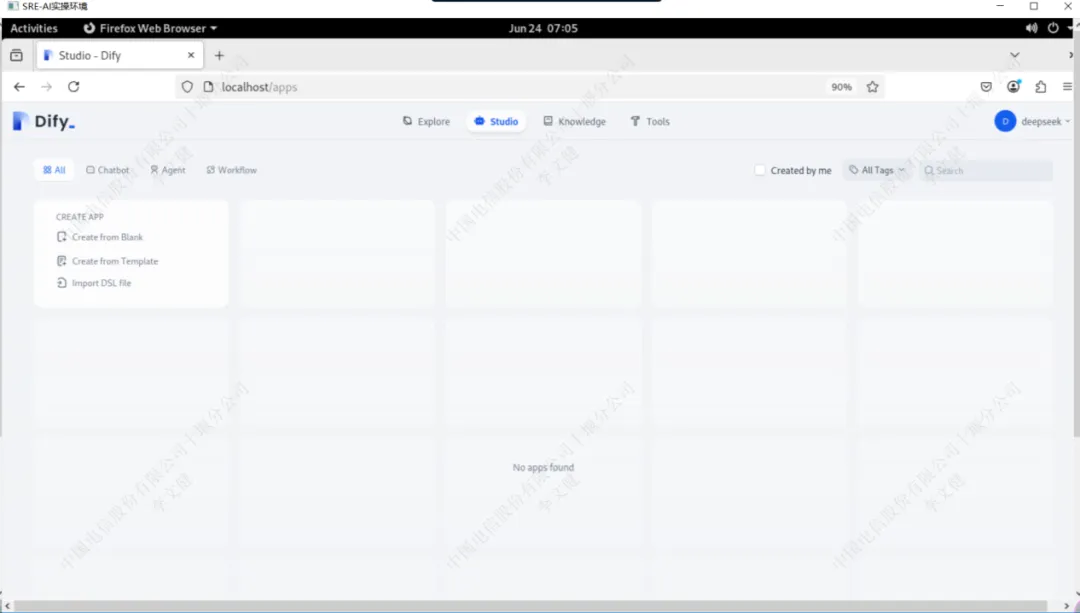
依次点击右上角用户名位置->”settings”可进入设置页面修改语言
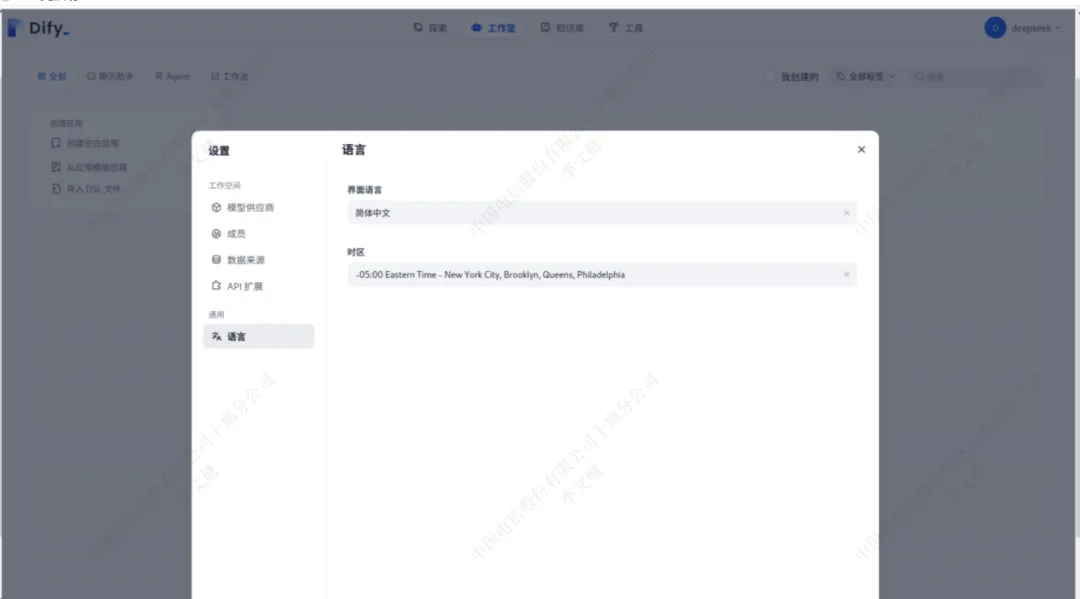
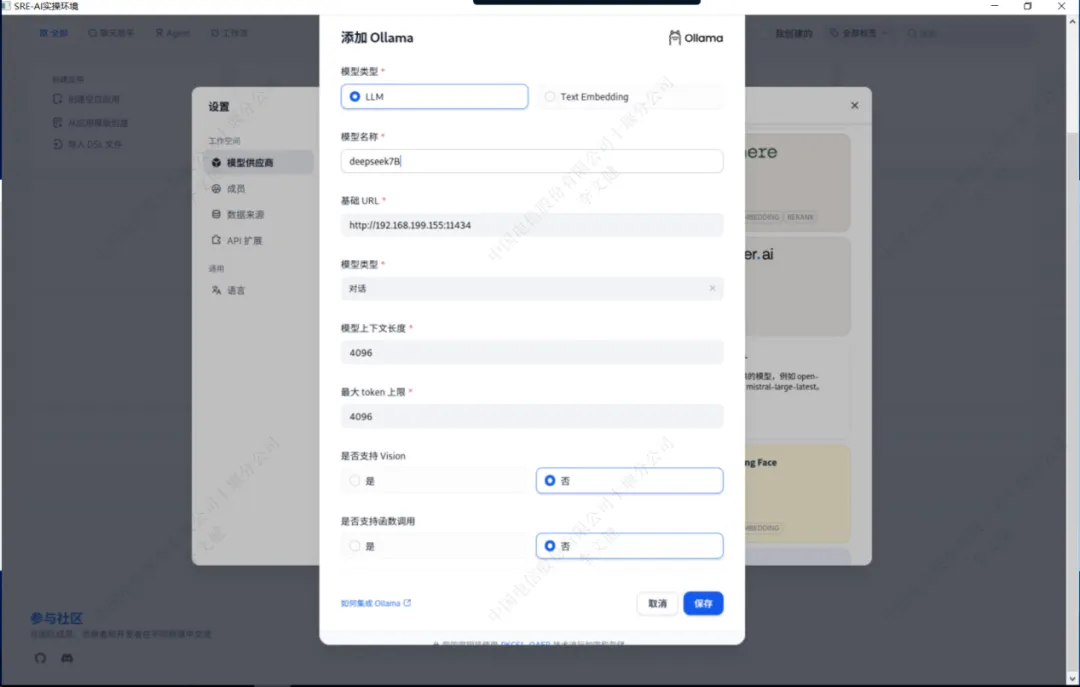
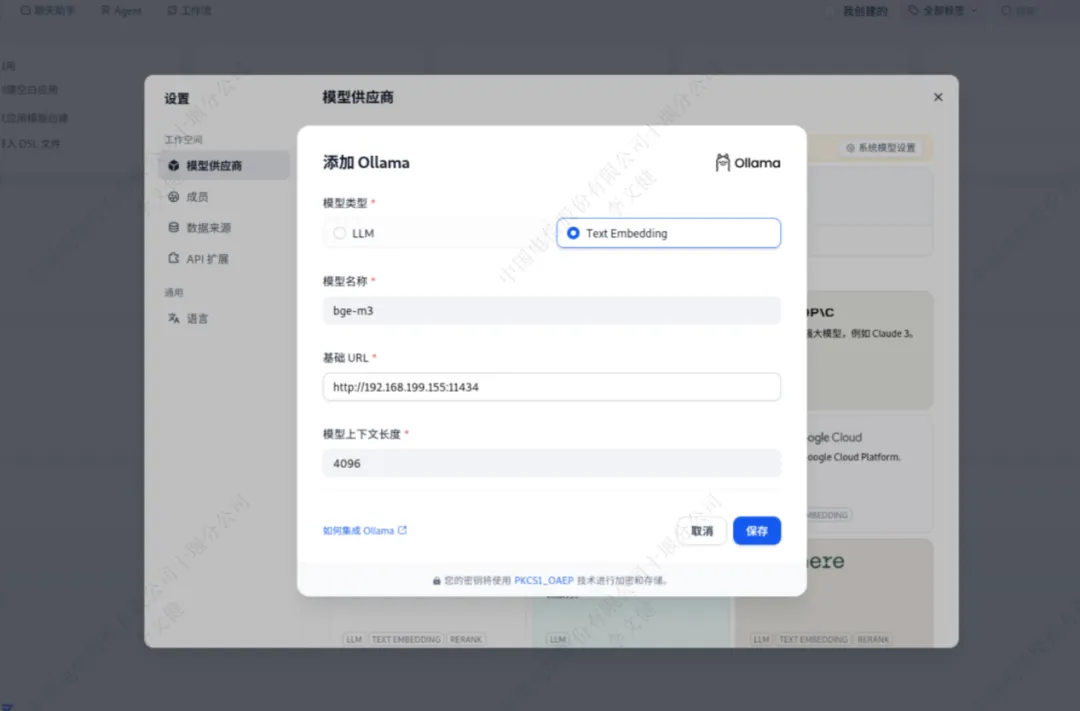
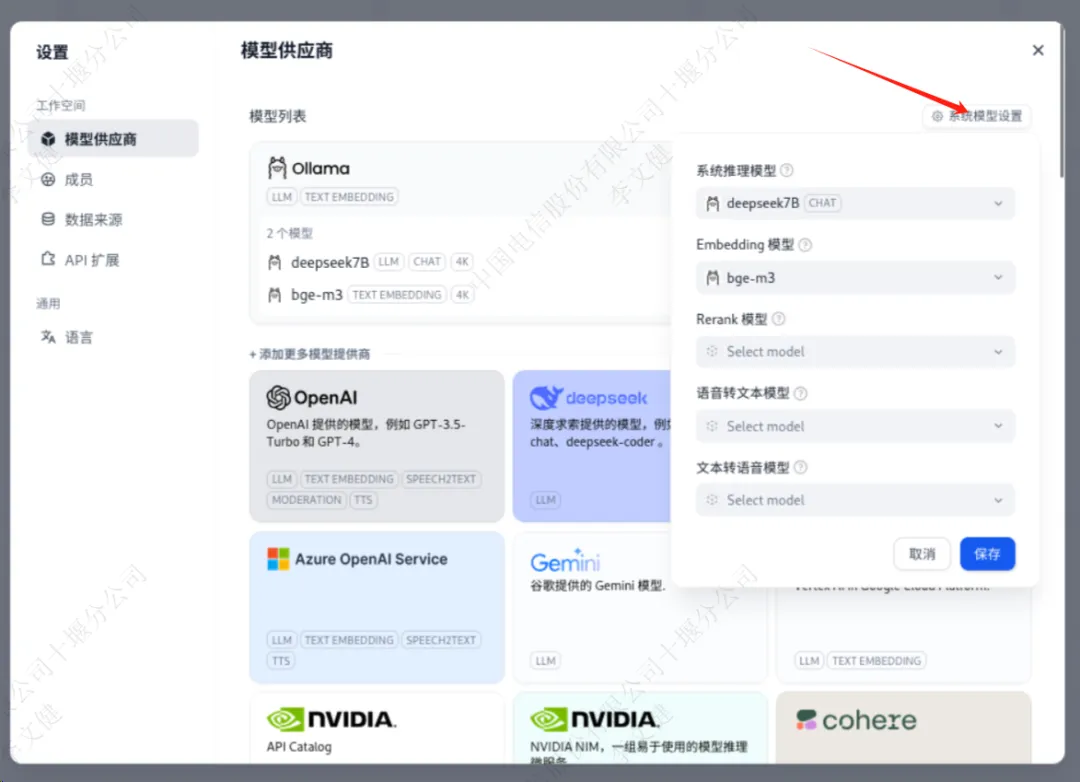
通过设置里面的“模型供应商”找到ollama,添加ollama运行的deepseek模型以及bge-m3模型
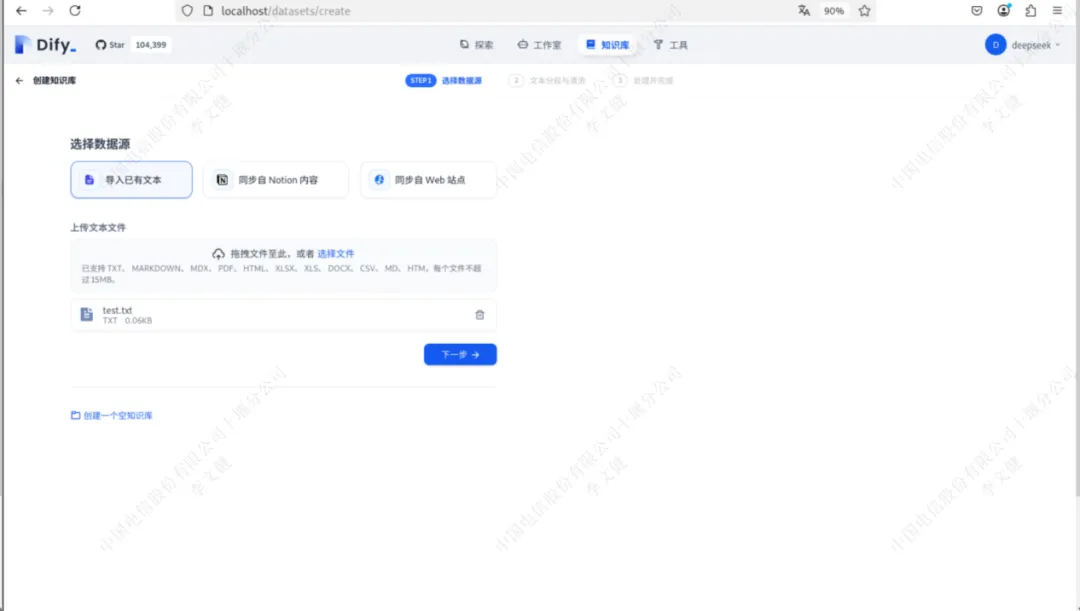
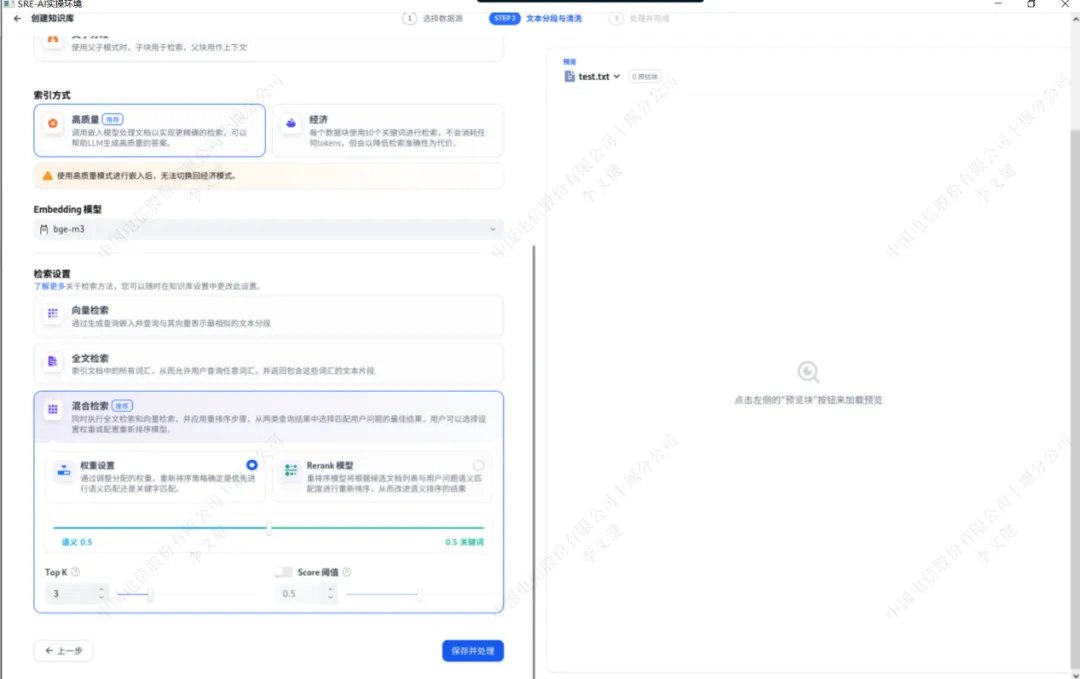
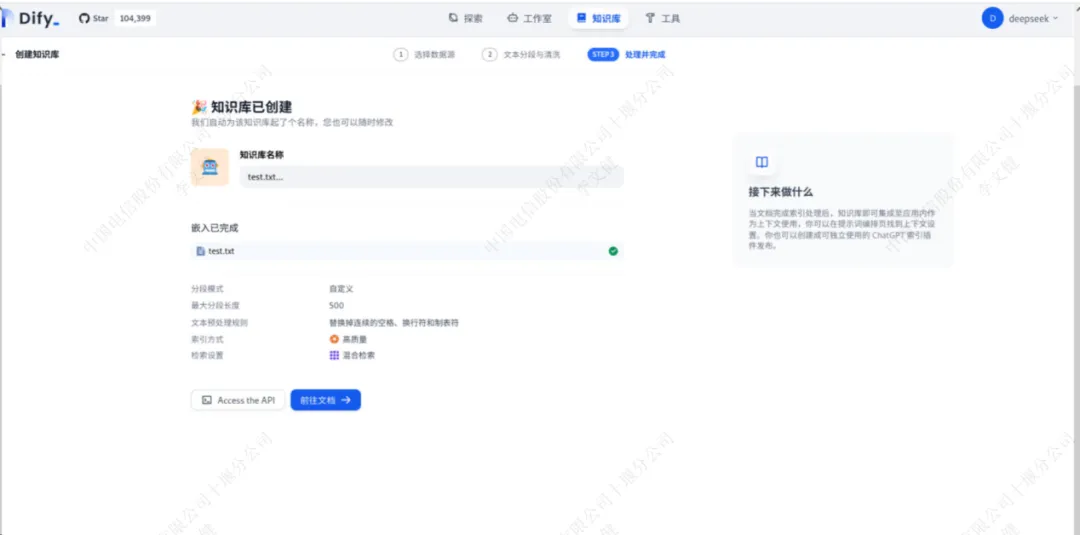
创建知识库并上传文件