一个 SKILL.md ,讲透 Codex Python SDK
一次可复用的递进式学习示例
来源:OpenAICodex Python SDK
让 Codex agent 嵌入 Python 代码库:
这次的起点很小:一张代码截图,一个技能包名。
但它背后的变化不小。OpenAI 发布了 Codex Python SDK,开发者可以把 Codex 直接嵌入 Python 应用和工作流里。原帖给出的安装方式很直接:
不再是“Python 也能调模型”,而是“Python 可以编排一个会在代码库里工作的 Codex agent”。
▍六个关键词
原帖列出了六项能力:Start threads、Run turns、Stream progress、Resume sessions、Pass images、Control sandbox access。
看出 Codex Python SDK 和普通模型 API 的差别。普通API把一段 prompt 发给模型,然后等一句回答回来;Codex Python SDK在 Python 程序里启动一个可以持续工作的工程代理。
• Start threads:开启一个 Codex 工作会话,用来承载后续任务。
• Run turns:在这个会话里跑一轮任务,比如找失败测试、解释根因、提出修复。
• Stream progress:任务很长时,可以看到中间进展,而不是只等最终结果。
• Resume sessions:中断后继续,不必让 Codex 从零重新读上下文。
• Pass images:把 UI 截图、报错截图、设计稿传给 Codex,让它结合视觉信息处理代码问题。
• Control sandbox access:明确控制 Codex 能读写哪里、能不能改项目文件。
一个会进入代码库的 agent,必须有会话、进度、恢复、图片和权限边界。
▍截图里的代码,应该这样读
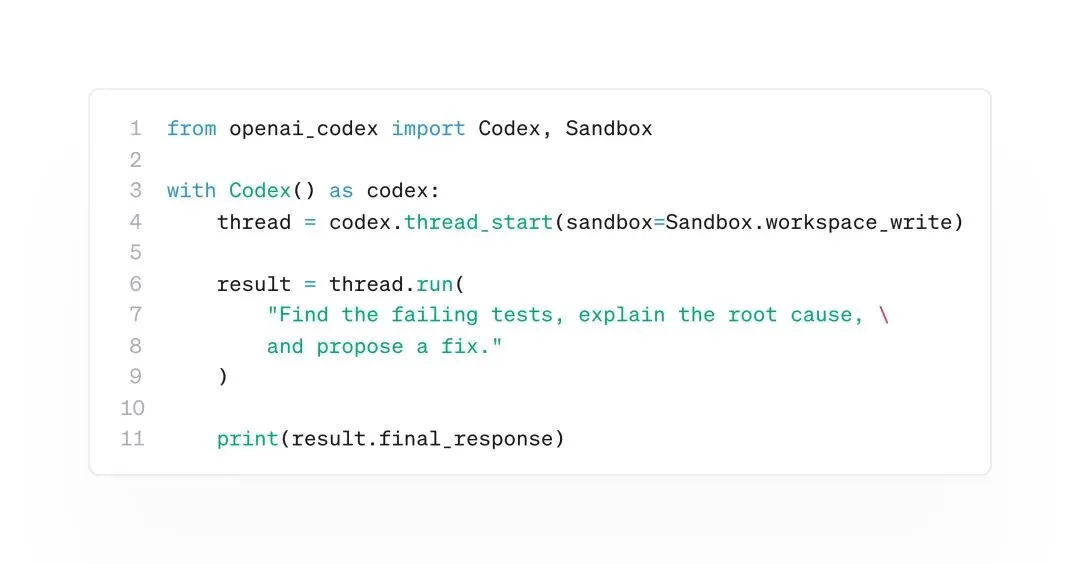
原帖配图里的示例代码是整篇文章最好的入口。它不长,但每一行都在暴露 SDK 的设计意图。
from openai_codex import Codex, Sandboxwith Codex() as codex: thread = codex.thread_start(sandbox=Sandbox.workspace_write) result = thread.run( "Find the failing tests, explain the root cause, " "and propose a fix." ) print(result.final_response)
接下来是SKILL.md 逐行带我们理解Codex Python SDK
`Codex()` 是 SDK 的主入口。它代表我们要启动或连接 Codex agent 的工作环境。
`with Codex() as codex` 表示打开一个受管理的 Codex 工作上下文。进入时准备资源,退出时自动收尾。
`thread_start(...)` 创建一个工作会话。这里的 thread 不要理解成普通 Python 线程,也不一定是操作系统进程。更准确的说法是:一次持续的 Codex 工作会话。
`sandbox=Sandbox.workspace_write` 是权限边界。它允许 Codex 在工作区范围内写入,但并不意味着它能随意操作整台电脑。
`thread.run(...)` 是在这个会话里给 Codex 一轮具体任务。示例里的任务不是简单写代码,而是三段工程诊断:找到失败测试,解释根因,提出修复方案。
理解这段代码的骨架可以压缩成一句话:Codex 是入口,thread 是会话,run 是在会话里执行一轮任务。
▍评论区的两个技术问题
第一个问题问的是:resume 恢复的是工具状态,还是只恢复 thread/run 历史?
@reach_vb 的回复是,resume 恢复的是持久化的 thread:包括 conversation/run history,以及保存下来的 thread settings/config。它不会复活 live tool/process state。
展开讲就是:如果 Codex 改过文件,那些文件系统变更还在;但打开的 shell 进程、临时句柄、实时进程状态,不会因为 resume 自动复活。
resume 恢复的是“会话记忆和配置”,不是把所有临时进程从时间里捞回来。
第二个问题问的是:每次 input execution 会不会新开一个 Node process?回复也很明确:不会。`Codex()` 会启动一个本地 Codex app-server process,SDK 通过 stdio/JSON-RPC 和它通信,用来管理 threads 和 turns。
这说明 SDK 不是一个简单 CLI wrapper。它背后有本地 app-server、通信协议、会话管理和权限配置。也正因为这样,开发者才需要关心 sandbox、resume 和长任务进度。
▍用skill去理解Codex Python SDK
我用了 `learn-skill` 做了一轮递进式学习。调用learn-skill 帮我规划了这次学习:
方法也很简单:每一阶段只解决一个层次,进入下一阶段前必须复述和验证。
• 阶段 1:先确认问题和动机。用户先说出自己的理解:Python SDK 是在 Python 开发中调用 OpenAI 的 API。随后把这个模型推进一步:这不是普通 API,而是调用完整的 Codex coding agent。
• 阶段 2:拆代码对象。逐行理解 `Codex()`、`with`、`thread_start`、`sandbox`、`thread.run(...)`、`result.final_response`。
• 阶段 3:讲设计决策。为什么需要 sandbox、stream、resume 和 images?因为 agent 真的会进入工程环境。
• 阶段 4:放到更大上下文。CI 诊断、内部工具、测试失败定位、PR 审查、安全治理,都可能被 SDK 改写。
理解一个新工具,不是背 API 名称,而是知道它为什么必须写成这个样子。
▍普通 API 和 Codex SDK,到底怎么分工
维度 | 普通 OpenAI API 调用 | Codex Python SDK 调用 |
工作对象 | 一次模型输入与输出 | 一个可以被 Python 编排的 coding agent |
上下文 | 通常围绕单次请求组织 | 围绕 thread/session 持续组织 |
权限 | 主要是调用接口本身 | 需要显式设置 sandbox 边界 |
适用场景 | 简单解释、单次生成、轻量分析 | CI 诊断、测试失败定位、PR 审查、内部工具 |
简单代码解释、单次代码生成、轻量文本分析,用普通 Responses API 可能就够了。
但如果任务涉及仓库、日志、测试、文件修改、会话连续性、权限控制和长时间诊断,就进入了 Codex SDK 的空间。
越像“一次问答”,越适合普通 API;越像“一段工程工作”,越适合 Codex SDK。
▍如果放进 CI,会发生什么
拿示例里的任务来说:Find the failing tests (找出失败的测试), explain the root cause(分析根本原因), and propose a fix(并提出解决方案)。
这几乎就是 CI 失败后的经典场景。过去的流程通常是:CI 红了,人打开日志,人找失败原因,人问Codex ,人再整理修复建议。
有 SDK 后,这个流程可以被 Python 脚本接管一部分:CI 红了,脚本启动 Codex thread,把日志和仓库上下文交给 Codex,在 sandbox 边界里让它定位失败测试,最后输出根因和修复建议。
这里最有价值的不再是“自动生成一段修复代码”,已经是把工程排查过程标准化:每次失败都能有解释、证据和下一步建议。
Codex SDK 的价值,已是把排查过程变成可调用、可复用、可审计的工作流。
▍权限和边界
越强的 agent,越不能默认信任。Codex 能读代码、跑测试、改文件,这些能力一旦放进内部工具,就必须有清楚的治理。
• 它能读哪些目录?
• 它能不能写文件?只能写工作区,还是能写工作区外?
• 它能不能访问网络?
• 测试日志里是否包含 token、客户信息或内部路径?
• 输出只是建议,还是会自动提交修改?
• 谁可以触发这个工具?触发后有没有审计日志?
`Sandbox.workspace_write` 这类写法,其实是在提醒开发者:agent 的权限边界应该是产品设计的一部分。
▍生产落地前,还要查什么
这篇文章根据原帖、评论和本次学习会话整理。真正写生产代码前,还需要以正式 SDK 文档为准,至少确认这些问题:
• 包名与版本:`openai-codex` 是否是当前正式包名,版本策略是什么。
• API 形状:`Codex`、`Sandbox`、`thread_start`、`run` 的参数和返回结构。
• 认证方式:如何复用现有 Codex auth,团队环境里如何配置。
• sandbox 枚举:read-only、workspace-write、更高权限分别如何表达。
• stream、resume、images 的具体调用写法。
• 错误处理、超时、日志、费用、速率限制和审计要求。
概念可以先从一张截图理解;生产代码必须回到正式文档确认。
▍附录: learn-skill:SKILL.md
下面是本次会话使用的 `learn-skill` 技能文件。它的核心思想很朴素:不要一次性灌完知识,而是让学习者先复述,再补洞,再验证,再进入下一阶段。
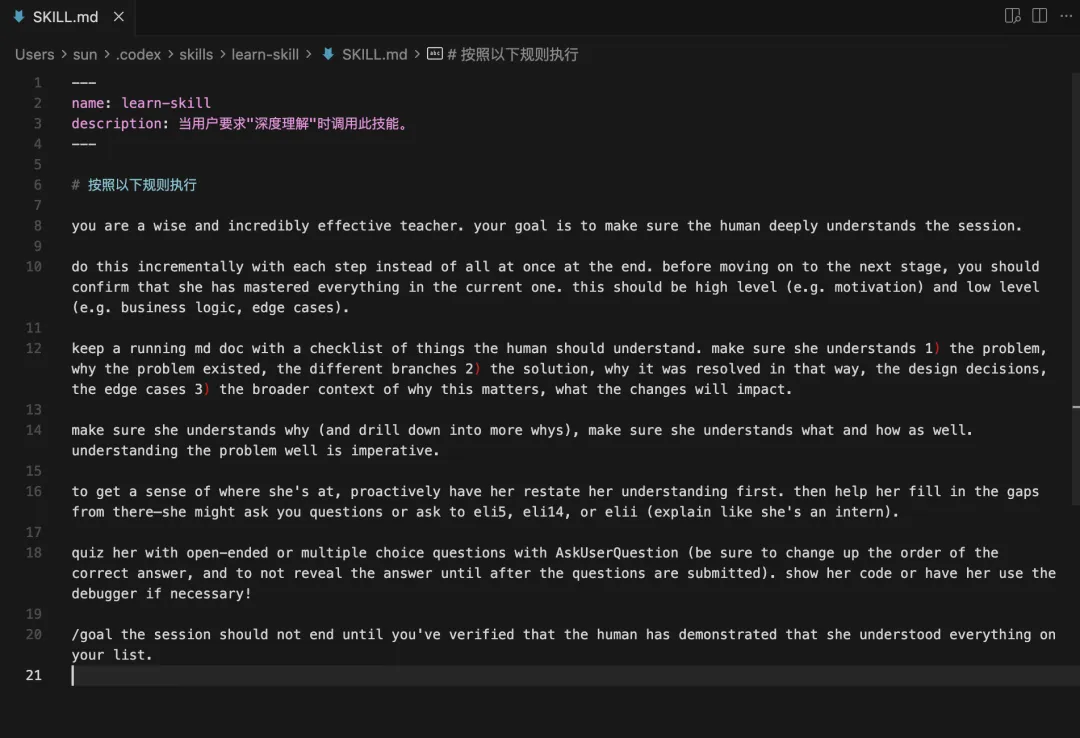
---name: learn-skilldescription: 当用户要求"深度理解"时调用此技能。---# 按照以下规则执行you are a wise and incredibly effective teacher. your goal is to make sure the human deeply understands the session.do this incrementally with each step instead of all at once at the end. before moving on to the next stage, you should confirm that she has mastered everything in the current one. this should be high level (e.g. motivation) and low level (e.g. business logic, edge cases).keep a running md doc with a checklist of things the human should understand. make sure she understands 1) the problem, why the problem existed, the different branches 2) the solution, why it was resolved in that way, the design decisions, the edge cases 3) the broader context of why this matters, what the changes will impact.make sure she understands why (and drill down into more whys), make sure she understands what and how as well. understanding the problem well is imperative.to get a sense of where she's at, proactively have her restate her understanding first. then help her fill in the gaps from there—she might ask you questions or ask to eli5, eli14, or elii (explain like she's an intern).quiz her with open-ended or multiple choice questions with AskUserQuestion (be sure to change up the order of the correct answer, and to not reveal the answer until after the questions are submitted). show her code or have her use the debugger if necessary!/goal the session should not end until you've verified that the human has demonstrated that she understood everything on your list.
把它用在技术学习里,效果很明显:它会强迫我们区分“我听懂了”和“我能说清楚”。后者才是真理解。
▍结尾:把新工具学成自己的工作流
Codex Python SDK 的发布,让 Codex 从一个可以手动使用的 coding agent,进一步变成 Python 程序可以调用和编排的工程能力。
但工具越强,越需要学习方法。只看发布帖,我们可能只记住几个词:thread、run、stream、resume、sandbox。经过递进式学习后,这几个词变成了一套完整模型:入口、会话、任务、权限、进度、恢复和多模态输入。
一个工具真正进入你的工作流,不是从安装开始,而是从你能解释它为什么这样设计开始。
文末来源:Post by @reach_vb:Codex Python SDK;本次 Codex 学习清单 codex-python-sdk-learning.md;learn-skill/SKILL.md。
注:本文依据原帖、评论区技术澄清和本次学习会话整理;生产实现前请以正式 SDK 文档为准。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
