Triton 和 Python eDSL 怎么样|AI 算力民主化系列第 7 篇
- 2026-06-15 03:13:09
AI 编译器一直绕不开一个根本性的取舍:它们想抽象掉底层细节,让系统更好用、更容易扩展;但现代生成式 AI 工作负载又需要可编程性和硬件控制,才能跑出顶级性能。CUDA C++ 能提供这种控制力,但它出了名地笨重、难用。与此同时,AI 开发主要发生在 Python 里。因此,行业很自然地尝试把 GPU 编程和 Python 结合起来。
但这里有个问题:Python 不能在 GPU 上运行。为了跨过这道鸿沟,研究人员构建了嵌入式领域专用语言(Embedded Domain-Specific Language,eDSL),它们是基于 Python 的抽象,看起来像 Python,但底层会编译成高效的 GPU 代码。想法很简单:让工程师获得 CUDA 的能力,同时不用承受 C++ 的痛苦。可这条路真的走得通吗?
本文会拆解 Python eDSL 的工作方式以及优缺点,并重点看看 Triton,它是这个方向里最受欢迎的方案之一,以及其他几个类似项目。Python eDSL 能不能同时满足性能和易用性的要求?还是说它只是 AI 算力民主化路上的又一次绕行?接下来,我们将回答这些问题。
什么是嵌入式领域专用语言(eDSL)?
领域专用语言[1]适用于这样一些场景:某个特定领域有自己独特的表达方式,能让开发者更高效。最有名的例子大概是 HTML、SQL 和正则表达式[2]。eDSL 是一种复用现有语言语法的 DSL,但它会借助编译器技术改变代码的执行方式。很多系统都基于 eDSL 构建,从分布式计算里的 PySpark,到深度学习框架里的 TensorFlow、PyTorch,再到 GPU 编程里的 Triton。
例如,PySpark 让用户用 Python 表达数据转换,但它会构建一个优化过的执行计划,在集群上高效运行。类似地,TensorFlow 的 tf.function 和 PyTorch 的 torch.fx 会把类似 Python 的代码转换成优化过的计算图。这些 eDSL 抽象掉了底层细节,让开发者即使不懂分布式系统、GPU 编程或编译器设计,也能写出高效代码。
eDSL 的工作原理
eDSL 的核心做法是:在 Python 代码真正运行之前先捕获代码,再把它转换成自己能处理的形式。它们通常会利用装饰器(Decorator)这种 Python 特性,在函数运行之前拦截函数。当你使用 @triton.jit 时,Python 会把函数交给 Triton,而不是直接执行它。
下面是一个简单的 Triton 示例:
@triton.jitdefkernel(x_ptr, y_ptr, BLOCK_SIZE: tl.constexpr): offs = tl.arange(0, BLOCK_SIZE) x = tl.load(x_ptr + offs) tl.store(y_ptr + offs, x)Triton 收到这段代码后,会把函数解析成抽象语法树(Abstract Syntax Tree,AST)。AST 表示函数结构,包括操作和数据依赖。有了这个表示,Triton 就能分析模式、应用优化,并生成执行同样操作的高效 GPU 代码。
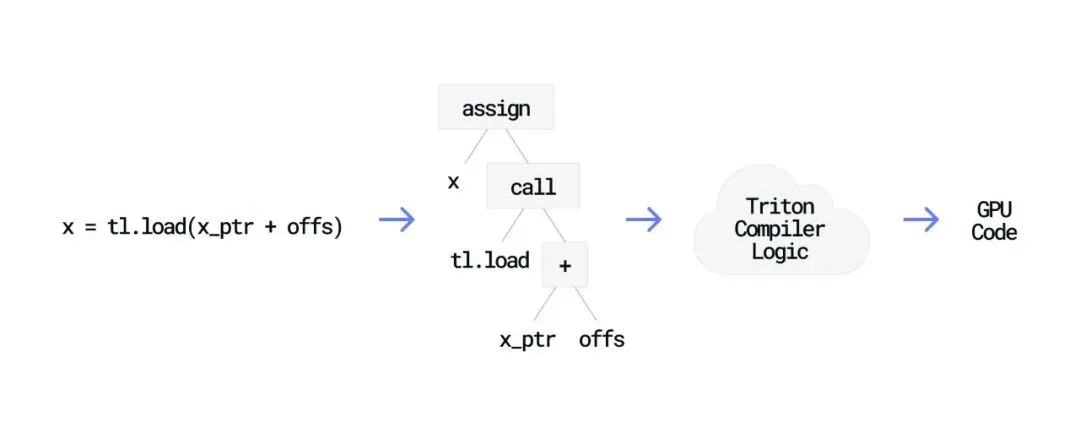
借助 Python 现有的语法和工具,eDSL 创建者可以专注于构建编译器逻辑,而不必从零设计一门新语言,包括解析器、语法和工具链。
eDSL 的优势
对构建领域专用编译器的人来说,eDSL 有很大优势:把语言嵌入 Python 之后,开发者可以专注于编译器逻辑,而不是重新发明整套编程语言。设计新语法、编写解析器、构建 IDE 工具是一项巨大工程。借助 Python 已有的语法和 AST 工具,eDSL 创建者可以跳过这些工作,直接解决眼前的问题。
eDSL 用户也会受益。Python eDSL 让开发者留在熟悉的环境里,他们可以继续使用同样的 Python IDE、自动补全、调试工具、包管理器(例如 pip 和 conda),以及整个库生态。开发者不必学习 CUDA C++ 这样完全不同的语言,只需要在 Python 里写代码,底层执行交给 eDSL 接管。
不过,这种便利也带来了明显的取舍。如果开发者期待 eDSL 像普通 Python 代码一样工作,往往会感到挫败。
eDSL 的挑战
当然,这里面也有代价。eDSL 有自己的取舍,其中一些非常让人头疼。
它看起来像 Python,但不是 Python
这是 eDSL 最容易让人困惑的地方。代码看起来像普通 Python,但在关键地方并不像 Python 那样工作:
# Regular Python: This works as expecteddefworks(): kv = dict((i, i * i) for i in range(5)) return sum(kv.values())# Python eDSL: The same code fails@numba.njit()deffails(): # Generator expressions aren't supported kv = dict((i, i * i) for i in range(5)) # Built-in function sum isn't implemented return sum(kv.values())为什么会这样?因为 eDSL 并不是在执行 Python,而是在捕获函数并把它转换成别的东西。它会决定支持哪些结构,而许多日常 Python 特性,例如动态列表、异常处理或递归,可能根本不能用。于是,当你以为某段 Python 代码应该能工作时,它可能突然失败,或者抛出难懂的错误。
错误和工具限制
调试 eDSL 代码可能是一场噩梦。代码失败时,你通常拿不到熟悉、友好的 Python 错误信息。相反,你看到的可能是来自某个编译器内部深处的不透明堆栈跟踪,几乎看不出哪里出了问题。更糟的是,Python 调试器这类标准工具往往完全不能用,你只能依赖 eDSL 自己提供的调试设施(如果它有的话)。此外,虽然 eDSL 存在于 Python 里,但它不能直接使用 Python 库。
表达能力有限
eDSL 借用 Python 语法,因此无法引入对自身领域有用的新语法。CUDA C++ 这样的语言可以增加自定义关键字、新结构或领域专用优化,而 eDSL 被锁在 Python 的一个子语言里,很多东西就没法表达得那么干净。
归根结底,具体 eDSL 的质量决定了这些取舍会有多痛苦。实现得好的 eDSL 可以提供顺畅体验,设计糟糕的 eDSL 则会让预期不断落空,处处踩坑。那么,Triton 这样的 eDSL 做对了吗?它和 CUDA 相比又如何?
Triton:OpenAI 用于 GPU 编程的 Python eDSL
Triton 最早是哈佛大学 Philippe Tillet[3] 的研究项目,在研究 OpenCL 多年[4]之后,他在 2019 年首次发表[5]了 Triton(也可以看我前面关于 OpenCL 的文章)。Tillet 加入 OpenAI,以及 PyTorch 2 决定采用 Triton 之后,这个项目得到了很大的推动。
和通用 AI 编译器不同,Triton 专注于让 Python 开发者更容易上手,同时仍然允许深入优化。它在高层简洁性和底层控制之间找到了某种平衡:给开发者足够的灵活性去调优性能,同时不让他们淹没在 CUDA 的复杂性里。
下面看看 Triton 到底好用在哪里。
以块为中心的编程模型
传统 GPU 编程迫使开发者以单个线程为单位思考,手工管理同步和复杂索引。Triton 把编程模型提升到块级别,从而简化这个过程,而块正是 GPU 自然执行工作的层级,因此可以消除不必要的底层协调:
@triton.jitdefsimplified_kernel(input_ptr, output_ptr, n_elements, BLOCK_SIZE: tl.constexpr):# One line gets us our block position block_start = tl.program_id(0) * BLOCK_SIZE# Create indexes for the entire block at once offsets = block_start + tl.arange(0, BLOCK_SIZE)# Process a whole block of data in one operation data = tl.load(input_ptr + offsets, mask=offsets < n_elements)# No need to worry about thread synchronization这种模型抽象掉了线程管理,也简化了基本索引。更重要的是,它让开发者更容易用上 Tensor Cores,也就是贡献 GPU 大部分 FLOPS 的专用硬件:
# This simple dot product automatically uses TensorCores when availableresult = tl.dot(matrix_a, matrix_b)原本需要几十行复杂 CUDA 代码的事情,现在变成一次函数调用,同时仍然能获得高性能。Triton 会自动处理数据布局转换和硬件相关优化。
简化优化
CUDA 最令人沮丧的地方之一,是要为多维数据管理复杂索引计算,Triton 则大幅简化了这点:
# Simple indexing with broadcast semanticsrow_indices = tl.arange(0, BLOCK_M)[:, None]col_indices = tl.arange(0, BLOCK_N)[None, :]这些数组操作感觉很像 NumPy,但会编译成高效 GPU 代码,而且没有运行时开销。
Triton 还包含由编译器驱动的优化,例如向量化。它也让双缓冲和软件流水线更容易使用,从而把内存传输和计算重叠起来。在 CUDA 中,这些技术需要很深的 GPU 专业知识;在 Triton 中,非专家也能实际用起来。想深入了解的话,OpenAI 提供了详细教程[6]。
Triton 让 GPU 编程容易上手得多,但这种易用性也有代价。下面看看几个关键挑战。
Triton 的短板
Triton 在部分场景里得到了广泛使用,结果也非常成功,例如训练前沿模型的研究人员和一些特殊用例。不过,它并没有被所有应用广泛采用,尤其是在 AI 推理场景中,它并不好用,因为推理需要最高效率。此外,尽管几年前行业领袖曾做出预测[7],Triton 并没有统一生态,也没有挑战 CUDA 的主导地位。除了所有 eDSL 都有的通用限制之外,Triton 还面临一些额外挑战。
GPU 性能和总拥有成本(TCO)损失明显(相对 CUDA C++)
Triton 用性能换生产力,它的创造者也这样解释过[8]。这让 GPU 代码更容易写,但也让 Triton 很难达到峰值效率。具体损失多少会变化,但在今天主导 AI 算力的 NVIDIA H100 上,损失 20% 很常见。
问题在于,编译器的优化能力比不上熟练的 CUDA 开发者,尤其是在今天的先进 GPU 上。我做了几十年编译器,从没见过“足够聪明的编译器[9]”这个神话真正兑现!这就是为什么包括 DeepSeek 在内的领先 AI 实验室,在要求苛刻的工作负载上仍然依赖 CUDA,而不是 Triton:对生成式 AI 来说,20% 的差距无法接受。在规模化场景中,这就是 10 亿美元和 8 亿美元云账单的差别!
治理:OpenAI 的控制和重心
Triton 是开源的,但 OpenAI 掌控它的路线图。这是个问题,因为 OpenAI 直接和其他前沿模型实验室竞争。于是问题来了:它会优先照顾更广泛 AI 社区的需求,还是只照顾自己的需求?
许多工程师都表达过挫败感,给 Triton 贡献改进很困难,尤其是当这些改动不符合 OpenAI 内部优先级时。一个反复出现的抱怨是,对替代硬件的支持远远落后,因为 OpenAI 没有什么动力去优化自己不用的加速器。Triton 的领导者也承认,“对新用户的支持几乎不存在[10]”,他们也没有足够精力跟上社区需求。
工具和调试器支持不足
CUDA 虽然复杂,但成熟的工具生态抵消了一部分痛苦,包括 Nsight Compute、Profiler API 和内存调试器,这些工具能让开发者深入理解性能瓶颈。Triton 不能和这些工具配合使用。eDSL 在设计上就是要抽象掉细节。结果是,一旦出问题,开发者无法判断问题来源,经常只能猜编译器做了什么。尽管 Triton 的编程模型更简单,但这种可观察性缺失让 Triton 的性能调试比 CUDA 更难。
GPU 可移植,但性能不可移植,也不够通用
如果 Triton 代码是为某一种具体 GPU 写的,它可以跑得“相当快”。但这段代码换到其他 GPU 上就跑不快,即使都属于 NVIDIA 硬件也是如此。例如,针对 A100 优化的 Triton 代码在 H100 上通常表现糟糕,因为新的架构需要不同的代码结构才能达到 80% 的性能。Triton 并没有把流水线和异步内存传输这类东西抽象掉。

迁移到 AMD GPU 更糟。虽然 Triton 在技术上支持 AMD 硬件,但性能和功能完整度远远落后于 NVIDIA,让跨厂商可移植性在实践中很难成立。对非 GPU AI 加速器来说,情况会变得很灾难,例如 TPU、Groq 芯片或 Cerebras 晶圆。这些架构不遵循 Triton 假设的 SIMT 执行模型,结果要么性能严重下降,要么需要太多变通,反而得不偿失。
最后,“一次编写,随处运行”的承诺通常会变成“一次编写,随处运行,但在其他平台上性能显著下降。”
Triton 表现如何?
在上一篇和再上一篇文章中,我们开始为 AI 编程系统整理一份愿望清单。根据这份清单来评估,Triton 有几个很大的优势和挑战:
提供参考实现:Triton 提供的是完整实现,而不只是技术规范,并且配有实用示例和教程。👍 具备强有力的领导力和愿景:Triton 在 OpenAI 之下有明确领导,但优先级和 OpenAI 的需求一致,而不是和更广泛的社区一致。长期治理仍然是个问题,尤其是对和 OpenAI 竞争的 AI 实验室来说。👍👎 在行业领导者的硬件上跑出顶级性能:Triton 在 NVIDIA 硬件上运行不错,但和优化过的 CUDA 相比,通常有大约 20% 的性能差距。它也难以应对 FP8 和 TMA 这类最新硬件特性。👎 快速演进:Triton 已经适配了一些生成式 AI 需求,但在支持前沿硬件特性上仍然落后。演进速度取决于 OpenAI 的内部优先级,而不是整个行业需求。👎 让开发者真正喜欢用它:Triton 提供了清晰、基于 Python 的编程模型,许多开发者觉得直观、效率高。它和 PyTorch 2.0 的集成也扩大了使用范围。👍👍👍 建立开放社区:虽然 Triton 是开源的,但它的社区受到 OpenAI 路线图控制的限制,来自外部组织的贡献面临明显障碍。👎 避免碎片化:Triton 本身统一面向 NVIDIA GPU。👍 但它又被其他硬件厂商广泛分叉,不同版本有不同限制和取舍。👎 支持完整可编程性:Triton 对标准操作提供了不错的可编程性。👍 但它无法访问或控制所有硬件特性,尤其是最新加速器能力。👎 帮开发者应对 AI 复杂度:Triton 能高效处理常见模式,也简化了开发。👍 但它不支持自动融合,因此无法解决指数级复杂度问题。👎 支持大规模应用:Triton 专注于单设备内核,缺少内置的多 GPU 或多节点扩展支持,但它和 PyTorch 集成得很好,可以由 PyTorch 处理这些问题。👍
总体来看,Triton 显然是 AI 开发生态里非常有价值的一部分,尤其是对 NVIDIA GPU 而言。话虽如此,虽然 Triton 因为和 PyTorch 集成而成为最知名的 eDSL,其他项目也在探索生产力、性能和硬件支持之间的不同取舍,例如 Pallas、CUTLASS Python 和 cuTile。这些替代方案想解决的问题相似,但处理 GPU 可编程性的方式各不相同。
其他 Python eDSL:Pallas、CUTLASS Python、cuTile 等
Python eDSL 的目标并不是提供最好的性能,而是让编译器开发者更容易把东西推向市场。因此,这类项目很多,Triton 只是最有名的一个。下面是几个经常有人问我的项目(免责声明:我没有直接参与过这些项目)。
Google Pallas
Google Pallas[11] 是 JAX 的一个子项目,设计目标是支持自定义算子,尤其是 TPU 上的自定义算子。它很大程度上借鉴了 Triton,但暴露出更多底层编译器细节,而不是提供一个高层、友好的 API。
从局外人的角度看,Pallas 似乎很强大,但也很难用,需要深入了解 TPU 硬件和编译器内部机制。它自己的文档就列出了大量容易踩的坑[12],这清楚表明它是给具备底层知识的专家用的工具。因此,它在 Google 之外的采用很有限。
CUTLASS Python 和 cuTile
在 GTC 2025 上,NVIDIA 发布了两个新的 Python eDSL:
CUTLASS Python:这场 GTC 演讲[13]中有展示,看起来很受 Google Pallas 的启发。它暴露底层编译器细节,需要很深的硬件知识,却没有 CUDA 开发者依赖的工具和调试器。我也很好奇,Python 缺少静态类型这件事,在编写这种底层系统代码时会带来什么影响。 cuTile:这个项目曾在 X 上被广泛转发[14],后来也正式公开,成为 CUDA Tile 编程模型的 Python 实现。真正的采用情况还要看它能否在 NVIDIA 自己的库和实际生产工作负载中持续落地。
这些 eDSL 只是 NVIDIA 庞杂 Python GPU 生态的一部分。NVIDIA 在 GTC 2025 上表示[15],没有一种工具适合所有事情,你要为工作选择正确的工具。NVIDIA 甚至还有一场名为用 Python 写 CUDA 内核的 1,001 种方式[16]的演讲。光是想到要选择正确路径,就已经很可怕了。

按照 NVIDIA 的说法,“没有一种工具对所有应用都是最优的”(上图来源:NVIDIA GTC 2025,CUDA:新特性及更多内容[17])。作为开发者,我不觉得几十个带着细微取舍的选项能帮到我。我们需要的是更少但更好用的工具,而不是一张不断增长的取舍清单。NVIDIA 正在切碎自己的开发者生态。
MLIR:AI 编译器的统一未来?
2017 年和 2018 年,当我参与扩展 Google TPU 时,一个模式逐渐浮现:TensorFlow 和 PyTorch 这类第一代 AI 框架缺少可扩展性,而 XLA 这类第二代 AI 编译器又牺牲了灵活性。为了打破这个循环,我带领团队构建了新的 MLIR 编译器框架[18]。它是一个模块化、可扩展的编译器框架,旨在支持快速变化的 AI 硬件格局。
它成功了吗?MLIR 推动了行业范围内的突破。Triton、cuTile 等 Python DSL 都基于它构建,重新定义了 GPU 编程。但和之前的 TVM 和 XLA 一样,MLIR 也面临治理挑战、碎片化和公司利益冲突。真正统一的 AI 编译器栈这个愿景,似乎仍然近在眼前却难以触及,被困在几十年来塑造这个行业的同一套权力拉扯里。
碎片化似乎不可避免,而抵抗 cuTile 是徒劳的。统一的编译器技术真的能帮助 AI 算力民主化吗?
译者注:英文原文“Resistance is cuTile futile”。这里 Chris 借用了《星际迷航》中博格人的名言“抵抗是徒劳的(Resistance is futile)”,并把
futile嵌进cuTile里做双关,意思是面对 cuTile 这类新工具继续出现,碎片化似乎很难避免,统一的 AI 编译器栈这个愿景很难实现。
下篇我们将深入探讨 MLIR 的成与败,以及其背后的组织博弈。
关于作者
本文作者 Chris Lattner 是 Modular 联合创始人兼首席执行官(CEO)。他长期从事编译器、开发者工具和 AI 基础设施工作,曾创建并推动 LLVM、Clang、MLIR、Swift 和 Cloud TPU 等关键技术,也曾在 Apple、Google、SiFive 和 Tesla 参与或领导底层系统与 AI 平台相关工作。
更多资源
官网:https://www.modular.com/ GitHub:https://github.com/modular/modular Discord:https://discord.gg/modular 论坛:https://forum.modular.com/ 博客:https://www.modular.com/blog 文档:https://docs.modular.com/
参考资料
领域专用语言: https://en.wikipedia.org/wiki/Domain-specific_language
[2]正则表达式: https://en.wikipedia.org/wiki/Regular_expression
[3]Philippe Tillet: https://scholar.google.com/citations?user=SQfo7UgAAAAJ&hl=fr
[4]Philippe Tillet 谈 OpenCL: https://youtu.be/WnBG7je7tO4?si=_M9jWBO4m0XR2R-e&t=70
[5]Triton 2019 论文: https://www.eecs.harvard.edu/~htk/publication/2019-mapl-tillet-kung-cox.pdf
[6]Triton 教程: https://triton-lang.org/main/getting-started/tutorials/
[7]SemiAnalysis 关于 Triton 和 PyTorch 的分析: https://semianalysis.com/2023/01/16/nvidiaopenaitritonpytorch/
[8]Triton 创造者谈性能与生产力取舍: https://youtu.be/WnBG7je7tO4?si=VwRalE1KOPX0k3eo&t=1186
[9]足够聪明的编译器: https://wiki.c2.com/?SufficientlySmartCompiler
[10]Triton 领导者谈新用户支持: https://youtu.be/o3DrHb-mVLM?si=9cp9syo9S8tKwqQ0&t=880
[11]Google Pallas: https://docs.jax.dev/en/latest/pallas/index.html
[12]Pallas 异步说明中的坑: https://docs.jax.dev/en/latest/pallas/design/async_note.html#why-doesnt-this-work
[13]CUTLASS Python GTC 演讲: https://www.nvidia.com/gtc/session-catalog/?tab.catalogallsessionstab=16566177511100015Kus#/session/1738891305735001ygGc
[14]cuTile: https://x.com/blelbach/status/1902113767066103949
[15]NVIDIA GTC 2025 CUDA 演讲: https://www.nvidia.com/gtc/session-catalog/?tab.catalogallsessionstab=16566177511100015Kus&search=what%27s%20new%20in%20cuda#/session/1726614035480001yvEQ
[16]1,001 Ways to Write CUDA Kernels in Python: https://www.nvidia.com/gtc/session-catalog/?tab.catalogallsessionstab=16566177511100015Kus#/session/1727175449007001EIKh
[17]CUDA:新特性及更多内容: https://www.nvidia.com/en-us/on-demand/session/gtc24-s62400/
[18]MLIR 编译器框架: https://en.wikipedia.org/wiki/MLIR_(software)
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- GESP第13次认证真题解析|Python五级真题回顾
- Python基础练习题100道电子版及源码文件
- Python绘制不同区域相关性分析对比复合热图
- 玩着玩着就学会Python,这个宝藏网站太香了!
- 【视频教程】基于Python常见地球科学数据(ERA5、雪深、积雪覆盖、海温、植被指数、土地利用)处理实践技术应用
- Python中下划线“_”的妙用
- Python实战宝典:30道经典编程挑战,演绎多变解法,源码在手,编程无忧!,高清PDF电子版下载
- 当你知道python有12种题型后…
- Python入门好书推荐:笨办法学Python
- 项目详解:Python蜜雪数据可视化案例.
