一起读经典 · Linux 内核网络(2):打开"快递盒"——sk_buff 深度解剖
「本文是「一起读经典 · Linux 内核网络」系列第 2 篇。承接第 01 篇关于协议栈两大基石的介绍,本文聚焦其中之一 sk_buff,从内存布局到指针操作、从克隆到分片、从经典设计到 6.x 演进,完整剖析内核数据包载体的"快递盒"。
版本契约:本文以 Linux 6.6 LTS / 6.12 Stable 为基准。凡涉及"经典视角"(Benvenuti 一书、2.6 内核)与"现代实现"有出入处,文中显式标注,文末给出版本契约对照表。」
一、从一次 tcpdump 抓包说起
抓包工具人人会用:
tcpdump -i eth0 -nn 'tcp port 80' -w trace.pcap
但你想过没有——同一个数据包,内核既要把它送给 TCP 协议栈让 socket 收到,又要送给 tcpdump 抓到。这两件事是同时发生的。内核会把数据包"复印"一份吗?如果复印,几十万 PPS 的高速吞吐谁吃得消?如果不复印,两边怎么各自往包上做修改而不打架?
更深的问题:协议栈每往上走一层,IP 头、TCP 头都要"被剥掉"或"被加上",但抓包工具看到的应该是完整的包——这是怎么做到的?
这两个问题的答案,都藏在 struct sk_buff 这个"快递盒"的设计里。
一个常见疑问是:sk_buff 为何不能简化为 char *buf 加一个长度字段?本篇剖析其原因。
二、本文坐标:sk_buff 落在三张地图哪里
第 01 篇给了三张地图——数据面、控制面、性能面。读 02 篇前,先把 sk_buff 在这三张图上钉个坐标,后面才不会迷路。
sk_buff 首先是数据面的载体:它带着包从驱动、GRO、L2/L3/L4,一路走到 socket。
但它绝不只是数据面对象。控制面会在它身上打标签——mark、priority、Netfilter 连接跟踪(_nfct)、安全路径(secpath)、skb_ext。性能面也把状态塞进它——truesize、hash、queue_mapping、checksum offload、GSO/GRO 元数据。
| sk_buff |
|---|
| 线性区、非线性 frags、协议头偏移、设备与 socket 关系 |
| mark、priority、Netfilter / 安全 / 路由相关附加信息 |
| truesize、hash、queue_mapping、checksum / GSO / GRO / offload 元数据 |
所以读这篇,不要把 sk_buff 想成"一个包缓冲区",而要想成三张地图的交汇点。
本文边界:本篇只讲 sk_buff 的核心模型——几何布局、共享语义、非线性数据、元数据账本。完整字段清单不在正文展开,需要时请回到 include/linux/skbuff.h。
三、类比:为什么需要一个"快递盒"
想象你在做跨境物流。
货品(应用层数据)从工厂出来,要装进盒子。这个盒子要支持:
- 多层包装。在国内段贴一张面单,转入国际段时再外贴一张报关单,出关后再外贴目的国海关单。每加一层包装,不能拆已有的盒子重做。
- 多人共看。海关、物流、收件人都要能"看到"这个包裹的某些信息,但不能因为一个看的人撕开盒子,影响其他人的视角。
- 拆分与合并。一个大集装箱要能拆成若干小包分别派送(分片);若干小包到达目的地后又要合并成一个大订单(GRO 聚合)。
- 零拷贝。从仓库到机场到目的港,货品本体不要反复"搬家",最多只是换标签。
sk_buff 就是为同时满足以上四个需求设计的。它不是简单的"缓冲区 + 长度",而是一套"既能层层封装、又能多人共享、又能分片聚合、又支持零拷贝"的多面手。
简单粗暴的 char *buf + int len 四个需求都做不到:
- 多层包装?每加一个头部都要重新分配内存并拷贝整段数据。一个包从 TCP 走到驱动,要拷贝 4 次。
sk_buff 用四个指针 + 共享数据区 + 引用计数的组合,把上面四件事一次性解决。下面我们打开看。
四、四指针:先预留,再使用
sk_buff 内存布局的核心,是 head / data / tail / end 四个边界,加上一段连续的线性数据区。
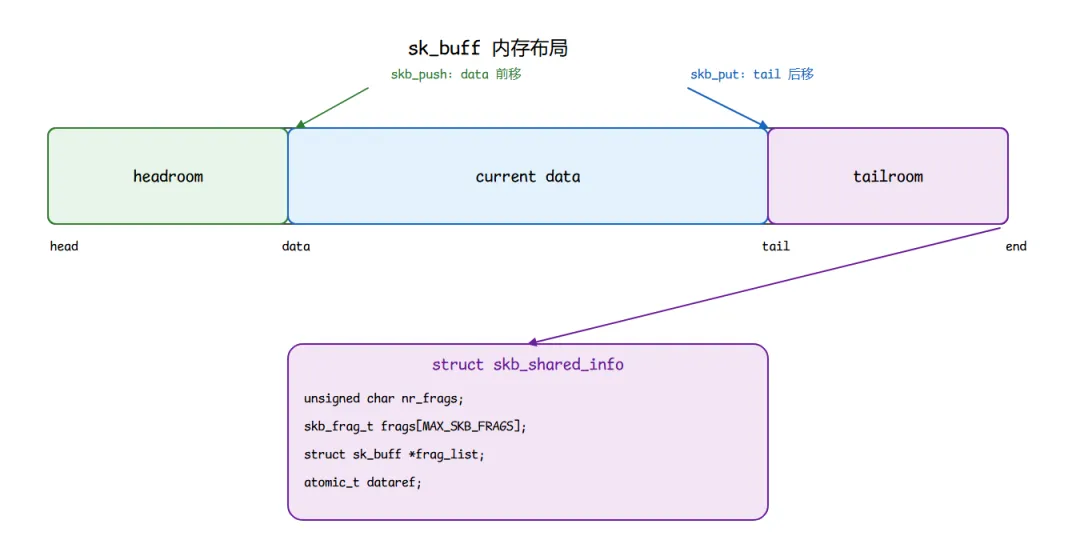 图 02-1:sk_buff 完整内存布局
图 02-1:sk_buff 完整内存布局四个边界的含义:
| | |
|---|
head | | |
data | | |
tail | | |
end | 线性数据区结束,也是 skb_shared_info 起点 | |
head 与 end 划定可用于线性数据的范围,data 与 tail 在中间游走。真正的 head buffer 还在 end 之后紧跟一段 struct skb_shared_info;也就是说,end 不是整块分配内存的最后一个字节,而是 skb_shinfo(skb) 的定位点。它们之间的核心关系是:
head ≤ data ≤ tail ≤ end
两处必须说清楚的精确性(否则后面查源码会困惑):
- 它们是"概念模型",字段类型并不都是裸指针。在现代 64 位内核里,
head和data是真指针,但tail和end通常以offset形式保存(sk_buff_data_t,即unsigned int),为的是缩小struct sk_buff体积。真实地址要通过skb_tail_pointer()/skb_end_pointer() 换算。后文说"四指针",都是概念称呼。 head/end 的"稳定"只是第一层模型。在普通协议头 push/pull 的热路径里,它们保持不动;但一旦要扩展 headroom、解除共享或线性化,内核会通过 pskb_expand_head() 等路径重新分配 head buffer,head/end 随之改变。"永不移动"只适合入门理解。
更妙的设计在于很多分配路径会在拿到空 skb 后立即 skb_reserve():刚初始化时 data/tail 可以等于 head,随后被故意往后挪一段,预留出 headroom。这样下层封装时(比如要加以太网头),skb_push 直接把 data 往前推,头部空间已经备好,不需要重新分配内存。
具体预留多少,取决于驱动、设备和分配路径——常见目的是对齐 IP 头、为后续协议头或驱动私有需求留空间,语义上接近 NET_SKB_PAD + NET_IP_ALIGN 这一类。不要把某个固定公式当成通用值;现代驱动还大量用 napi_alloc_skb()、build_skb()、page pool 等不同分配路径。
对称地,tailroom 是线性数据区尾部的剩余空间,适合 skb_put() 追加线性数据:接收侧驱动填入 frame、发送侧构造小包 payload、某些协议补尾部数据时都会用到。(注意:GRO 更常通过 frags/frag_list 组织非线性数据,不要把它简化成"消耗 tailroom"。)
这就是"先预留,再使用"的哲学。它不是某个奇技淫巧,而是整个发送路径零拷贝的基础。
4.1 四个基本操作
操作 sk_buff 的指针,有四个核心函数:
unsigned char *skb_put(struct sk_buff *skb, unsigned int len); // tail 后移unsigned char *skb_push(struct sk_buff *skb, unsigned int len); // data 前移unsigned char *skb_pull(struct sk_buff *skb, unsigned int len); // data 后移voidskb_reserve(struct sk_buff *skb, int len); // 初始化时同时前移 data 和 tail
它们的语义,对应接收和发送两条路径,有一种漂亮的对称:
| | |
|---|
| skb_pull | skb_push |
| | skb_put |
| skb_reserve | skb_reserve |
举个具体路径。一个 TCP 段被接收时:
- 驱动分配 sk_buff,
skb_reserve(skb, NET_IP_ALIGN),留出 2 字节,让后续 IP 头落到对齐边界上。 - 驱动
skb_put(skb, frame_len),把 DMA 来的整个以太网帧填进数据区。这时 data 指向以太网头开始。 eth_type_trans(skb, dev) 内部 skb_pull 掉 ETH_HLEN(14 字节),data 跳过以太网头,并设置 skb->protocol 与 skb->pkt_type。这个 helper 至今仍是绝大多数驱动(igb/ixgbe/mlx5e/i40e 等)收包时设置协议类型的标准入口。- 进入 IPv4 层后,内核先校验 IP 头、过 PRE_ROUTING、做路由决策。若路由结果是本机接收,以 6.6/6.12 为准,在本地投递路径(
ip_local_deliver_finish)里会 __skb_pull(skb, skb_network_header_len(skb)),把数据视角推进到传输层头部,再调用 TCP/UDP/ICMP 处理函数。(这是概念化路径,不是 ip_rcv 一行就能概括——真正的 pull 发生在本地投递阶段。) tcp_v4_rcv 拿到 sk_buff,data 已指向 TCP 头。
整段过程,数据本体一次也没拷贝过,只是 data 指针在缓冲区里"往后挪"。
发送是反向的:应用 write() 的 payload 进入 socket buffer 时,内核已经为下层头部预留了 headroom。tcp_transmit_skb 通过 skb_push(skb, tcp_header_size) 在前面"长出"一个 TCP 头;__ip_queue_xmit 再 skb_push(skb, sizeof(struct iphdr) + optlen) 长出 IP 头;L2 头则通常在 dev_hard_header(或驱动 ndo_start_xmit 之前)由 skb_push 补上。每一次"长出",都是 data 向前推一段距离,headroom 里的预留空间被消费掉。
4.2 三个 header offset 是协议栈的书签
只盯着 data 是不够的。现代 skb 还维护一组协议头书签:
| |
|---|
mac_header | |
network_header | |
transport_header | |
(经典视角里,这三者是 mac/nh/h 一个裸指针联合体;6.x 已改为独立 offset 字段。)
有了这组 offset,即使 data 被反复移动,内核也能随时重新定位各层协议头。后面讲 Netfilter、GRO、checksum offload 时,这些书签往往比 data 本身更关键。
4.3 边界检查的真相
老教材里有个说法,称 skb_put 越界只在 debug 配置下报警。这是不对的。
打开 include/linux/skbuff.h,看 skb_put 的实际实现(简化):
void *skb_put(struct sk_buff *skb, unsigned int len){void *tmp = skb_tail_pointer(skb); SKB_LINEAR_ASSERT(skb); skb->tail += len; skb->len += len;if (unlikely(skb->tail > skb->end)) skb_over_panic(skb, len, __builtin_return_address(0));return tmp;}
最后两行才是关键。一旦 tail > end,unlikely(skb->tail > skb->end) 直接触发 skb_over_panic → BUG()——这是无条件 panic,与 CONFIG_DEBUG_NET 无关,生产内核同样崩。对称地还有 skb_under_panic(data < head)。CONFIG_DEBUG_NET 控制的是另一类、更细的健全性检查(比如 skb->len 与 data_len、各分片之和是否一致),不是这条主线。
为什么内核要在生产环境也敢 BUG?因为驱动算错 DMA 长度导致 sk_buff 越界,后果是 page 之外的内存被写坏——继续运行只会以更隐蔽的方式崩在别处。直接 panic 反而是负责任的选择。
4.4 skb->len 不等于 tail - data
另一个常见误解。
很多老博客会写:skb->len = skb->tail - skb->data。这只在 sk_buff 完全线性时才对。
真相是:
skb->len = (skb->tail - skb->data) + skb->data_len
data_len 记录"非线性部分"的长度——也就是挂在 skb_shared_info->frags 数组里的那些 page,和挂在 frag_list 链表里的那些子 sk_buff。下一节就讲它们。
为什么这件事重要?因为只要你的代码假设 skb->len == tail - data,在 GRO 合并出来的大包、Scatter/Gather DMA 收上来的包面前,立刻就会算错长度,引出诡异 bug。skb_headlen() 才是"线性部分长度",skb->len 是总长度。
4.5 非线性 skb 不能随便 skb->data + offset
既然包可能非线性,就有一条铁律:如果 offset 落在线性区内,skb->data + offset 没问题;一旦跨进 frags,这个指针就失效。 内核为此提供了一组安全访问 API:
pskb_may_pull(skb, len):确保某段头部在线性区(不在则拉进来)。skb_header_pointer():安全读取可能跨非线性区的头部(必要时拷到本地缓冲)。skb_copy_bits():从线性区 + frags + frag_list 统一拷贝数据。
这组 API 是写网络子系统代码的底线。非线性 skb 的 bug,常常就是从"我以为数据是连续的"开始的。
五、frags 与 frag_list:非线性的两种姿势
线性 sk_buff 已经强大,但现代网络栈的常态是非线性。
非线性意味着 payload 不是连续的一块内存,而是散落在若干 page 或若干 sk_buff 里。两种组织方式各有用途。
 图 02-2:frags vs frag_list
图 02-2:frags vs frag_list5.1 skb_shared_info:非线性数据的总账
skb_shared_info 紧跟在线性数据区之后,通过 skb_end_pointer() / skb_shinfo(skb) 定位。它是所有非线性数据和 offload 元数据的总账:
struct skb_shared_info {unsigned char nr_frags; // frags 数组中有效元素数skb_frag_t frags[MAX_SKB_FRAGS]; // (page, offset, size) 三元组数组struct sk_buff *frag_list;// 子 sk_buff 链表(分片 / GRO fallback)atomic_t dataref; // 共享数据引用计数(含 payload-only 高位)unsigned short gso_size; // GSO 分段大小unsigned short gso_segs; // GSO 段数unsigned int gso_type; // GSO 类型(TCPv4/TCPv6/UDP/ECN...) ...};
| |
|---|
nr_frags | |
frags[] | 指向 page 的 (page, offset, size) 三元组数组 |
frag_list | 子 sk_buff 链表(分片 / GRO fallback) |
dataref | 共享数据区引用计数;低 16 位是总引用数,高 16 位还编码 payload-only 引用 |
gso_size | |
MAX_SKB_FRAGS 不要硬编码。6.6/6.12 里它来自 CONFIG_MAX_SKB_FRAGS,默认值是 17,Kconfig 允许在 17 到 45 之间调整;老资料里用 65536 / PAGE_SIZE + 1 解释默认值来源,但这不是现代内核的版本契约。
5.2 frags:页数组,服务 Scatter/Gather
每个 skb_frag_t 是 (page, offset, size) 三元组,指向一段 page 内的连续数据。
典型场景一:Scatter/Gather DMA。高速网卡的 DMA 引擎能从多个不连续的物理页一次性收包/发包。驱动接收时,把每个 DMA buffer 直接挂进 frags[],完全不需要拷贝。
典型场景二:sendfile 零拷贝。Web 服务器 sendfile(socket, file, offset, len) 把磁盘 page cache 中的内容直接挂进 socket 发送队列的 sk_buff frags[] 里,不经用户态缓冲区,也不经内核线性拷贝。整段数据从磁盘到网卡,只在 page cache 里活了一次。
「但 sendfile 的零拷贝有前提:文件已在 page cache、网卡支持 SG DMA、且不经 TLS 软件加密(kTLS offload 是另一回事)。任一条件不满足,都会回退到拷贝路径。」
5.3 frag_list:子 sk_buff 链表,服务分片与聚合
frag_list 是另一条路:它把若干完整的 sk_buff 链起来,表示一个由多个 skb 组成的逻辑大包。
典型场景一:IP 分片重组。多个 fragment 到齐后,内核把它们组织成一个逻辑大 IP 包送上去。(现代重组路径有独立的重组队列、超时与内存核算,frag_list 是它最终的组织形态之一,但不要把"所有 fragment 一收到就挂进 frag_list"当成全过程。)
典型场景二:GSO/GRO 的 fallback。后面讲 GRO 时会看到,当 frags 数组放不下时,内核会退回 frag_list 链接整个 skb。
5.4 GRO 合并:首选 frags 数组,链表是退路
NAPI poll 阶段,napi_gro_receive 把几个相邻、同流的 TCP 段合并成一个大 sk_buff,后续 ip_rcv、tcp_rcv 只走一次,大幅降低 per-packet 开销。
但合并的物理形态,首选不是 frag_list,而是 frags 数组。 查 net/core/gro.c:skb_gro_receive,合并按优先级有三条路径:
- frags 合并(最常见):有效数据都在 frags 中时,直接把新 skb 的 frags 元素拷进目标 skb 的 frags 数组,
nr_frags 增加。零额外分配。 - head_frag 路径:线性区数据也在 page 中(
skb->head_frag 为真)时,把线性区当作一个 frag 插入,再拷剩余 frags。 - merge / frag_list 路径(fallback):常见触发条件包括 frags 数组放不下(超过
MAX_SKB_FRAGS)、head_frag 形态不匹配、已有 frag_list 需要 flush、GRO 大小上限或 page_pool recycle 属性不兼容等;此时才把整个 skb 挂到 frag_list/链表上。
所以正确的说法是:GRO 优先尝试把 frags 数组合并(零额外分配),frag_list 是重要退路而不是主路径。 老博客里"GRO 通常挂到 frag_list"是把退路当成了主路。
5.5 GSO/GRO 让"一个 skb"不等于"一个线上包"
GRO 在接收侧把多个相邻段聚合成一个大 skb;GSO/TSO 在发送侧允许协议栈先构造大 skb,晚些时候再由内核或网卡分段。skb_shared_info 里的 gso_size、gso_segs、gso_type 就是这类"大 skb"的说明书。
所以排查时务必区分三个数,它们不一定相等:
5.6 怎么选?
简单的判定原则:
- 数据本来就在多个 page 里(DMA、page cache、用户态 splice)→ 用
frags。 - 数据本来就在多个完整 sk_buff 里(分片、GRO fallback)→ 用
frag_list。
两者并不互斥。一个高速 TCP 段经过 GRO 聚合后,得到的"大 sk_buff"可能同时既有 frags(每个被聚合的段自己带 DMA pages)又有 frag_list(放不下时的退路)。
六、克隆与共享:tcpdump 怎么和协议栈"同时看见同一个包"
回到开篇的问题:tcpdump 怎么和 TCP 协议栈"同时看见同一个包"?
答案是 skb_clone 这一族"复印"机制。
6.1 三种"复印"机制
| | | |
|---|
skb_clone() | | | dataref |
pskb_copy() | | | 各 page refcount +1,新 dataref=1 |
skb_copy() | | | |
skb_clone 是性能关键路径上最常用的。它返回一个新 sk_buff 头,头里的 data/tail/len 等是独立的(所以两个 sk_buff 可以各自移动自己的数据视角),但 head/end 指向同一块物理内存,数据区由 skb_shared_info->dataref 引用计数管理。注意:移动元数据视角不等于可以随便写共享数据;真正要改 header 或 payload 时,还要看 header 是否可写,必要时触发 COW。
注意:skb_clone不复制 payload,只分配/复制一个 struct sk_buff 元数据对象。这个对象远小于大 payload,但不是"几十字节"——在 x86_64 6.6 内核上约 232–248 字节,具体随编译配置变化(本文实验 1 会实测)。
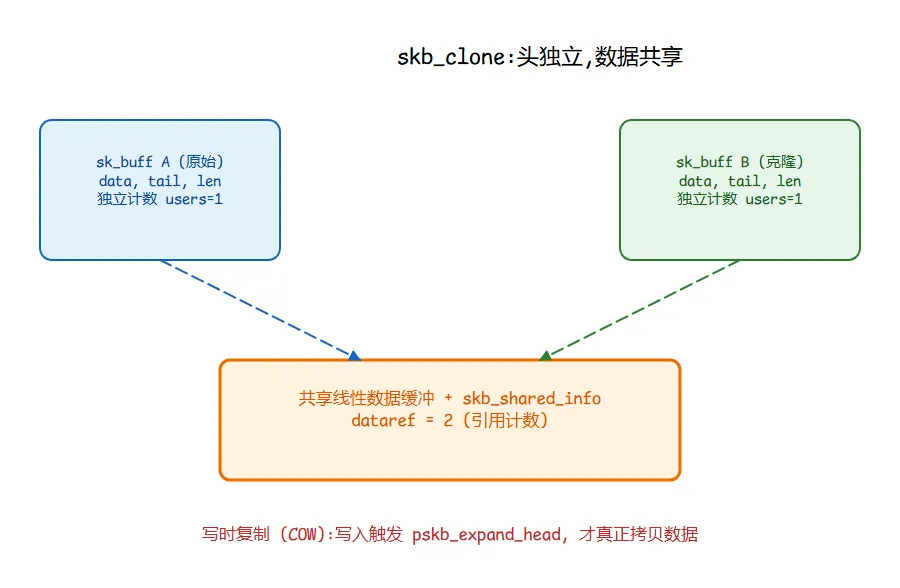 图 02-3:skb_clone 的"指针独立、数据共享"
图 02-3:skb_clone 的"指针独立、数据共享"两点常被遗漏的细节:
pskb_copy 与 __pskb_copy 的 headroom 语义。6.6/6.12 里 pskb_copy(skb, gfp) 仍是两参数 wrapper,它保留原有 headroom;若需要更大的头部预留空间(如 NAT、IPsec 要改/扩头),用底层的 __pskb_copy(skb, headroom, gfp) 显式指定。(注意签名:带 headroom 参数的是 __pskb_copy,不是 pskb_copy。)skb_copy 的副作用是线性化。它分配 end_offset + data_len 大小的线性区,用 skb_copy_bits 把所有 frags 数据拷进线性区,结果是一个完全线性的新 skb。适合需要完全私有、可改全部数据的场景;只想改头部时用 pskb_copy 更轻。
6.2 fclone:skb_clone 不是每次都走 slab 分配
还有一个容易被忽略、却是 TCP 性能秘密的优化:Fast Clone(fclone)。
__alloc_skb 带 SKB_ALLOC_FCLONE 标志时,从 skbuff_fclone_cache 一次性分配"主 skb + 备用 clone 槽 + fclone_ref"。当 skb->fclone == SKB_FCLONE_ORIG 且槽还空着时,skb_clone直接取这个预分配的槽,不走 kmem_cache_alloc,只需复制头 + dataref 自增。
TCP 发送路径(tcp_stream_alloc_skb → alloc_skb_fclone)大量使用它,因为重传队列需要频繁 clone。不知道 fclone,会误以为每次 clone 都要走一遍 slab 分配,从而严重高估 clone 开销。
「一句话记牢:truesize 是内存配额的语言,dataref 是数据共享的语言,users 是 sk_buff 头生命周期的语言——三者不能混着说。」
6.3 修正一个常见误解:skb->users ≠ dataref
老教材里(包括 Benvenuti)有时把"引用计数"统一说成"skb->users"。事实上这里有两层引用计数,语义完全不同:
skb->users:sk_buff 头本身的引用计数。同一个 sk_buff 头被多个上下文持有时(比如同时挂在两个队列里),这个数加 1。kfree_skb 先把它减 1,减到 0 才真正释放头。skb_shared_info->dataref:数据区的引用计数。skb_clone 出新 sk_buff 头时,dataref 加 1,新头的 users=1。释放数据区的判断,看 dataref 减到 0 没有。
两者一起决定:头能不能释放(看 users),以及数据能不能释放(看 dataref)。混为一谈,在并发场景下会写出微妙的双重释放或内存泄露。
还有一个相关标志:skb->cloned。它提示"数据区被共享了"。当需要修改数据内容(而不仅是移动头指针)时,内核会检查 cloned,若为真则触发写时复制(COW)——通过 pskb_expand_head 分配私有数据区再拷贝。这也是 4.4 节说"head/end 可能移动"的根源之一。
补一层 6.x 细节:skb->users 在现代内核里是refcount_t,而skb_shared_info->dataref仍是atomic_t。dataref还被拆成低 16 位和高 16 位:低 16 位记录总引用数,高 16 位记录 payload-only 引用数。TCP 发送路径会用__skb_header_release()标记 headerless skb,clone 下发时由skb_header_cloned()判断下层是否还能安全追加/改写头部。如果只是要保证前write_len字节可写,常见 helper 是skb_ensure_writable():它先pskb_may_pull()保证线性可访问,再在 clone 不可写时通过pskb_expand_head() 做 COW。
6.4 tcpdump 的实际路径:避免深拷贝,但不是零开销
__netif_receive_skb_core 是关键代码点。摘几行(简化):
list_for_each_entry_rcu(ptype, &ptype_all, list) {if (pt_prev) ret = deliver_skb(skb, pt_prev, orig_dev); pt_prev = ptype;}...if (pt_prev) ret = pt_prev->func(skb, skb->dev, pt_prev, orig_dev); // 最后一个,直接调用
而 deliver_skb 内部:
static inline int deliver_skb(struct sk_buff *skb, struct packet_type *pt_prev,struct net_device *orig_dev){if (unlikely(skb_orphan_frags_rx(skb, GFP_ATOMIC)))return -ENOMEM; refcount_inc(&skb->users); // 给"还要继续往下走"的人留一份引用return pt_prev->func(skb, skb->dev, pt_prev, orig_dev);}
注意这里是 refcount_inc(&skb->users) 而不是skb_clone。配合上面的 pt_prev 延迟投递模式,得到一个关键优化:
pt_prev 优化的真实含义:内核把"上一个 packet_type"延迟到看到下一个时再投递,这样最后一个处理者可以少一次 deliver_skb()。但对普通 IP 包来说,抓包的 ptype_all 后面通常还有 L3 协议处理者,所以不能简单说"单个 tcpdump 不 inc users"。只有某个 packet_type 恰好是整条分发链最后一个处理者时,它才会直接 func()。- 多个抓包者或后续处理者:前面的处理者会走
deliver_skb 增加 skb->users;packet_rcv / tpacket_rcv 发现 skb 已共享时,必要时才 skb_clone 出自己那份。
但要破除一个迷信:"开 tcpdump 协议栈基本没开销"这句话是错的,必须删掉。 Linux 上的 libpcap/tcpdump 常见配置会启用 PACKET_MMAP / TPACKET 环形缓冲,内核路径是 tpacket_rcv;条件不满足或未启用 ring 时也可能走 packet_rcv。无论哪条路,BPF 过滤、snaplen、ring/接收队列空间、时间戳、用户态消费与写盘速度都会带来成本;在 TPACKET 路径中,内核还会按 snaplen skb_copy_bits() 到用户态 ring。
「准确的说法是:这套机制避免了"为抓包给主路径深拷贝一整份 payload",但抓包绝不是免费午餐——高 PPS 下完全可能丢包或影响观测结果。」
这也呼应了 01 篇那句:抓包不是判决书,只是证人证言。它证明包经过了某个点,不证明包抵达了应用。
七、元数据账本:sk_buff 不只是装数据
第 02 篇真正难讲、也最容易漏的,是 sk_buff 上那些关于这个包的判断。它们才是控制面和性能面在 sk_buff 上的落点。
7.1 truesize 才是内存账本
skb->len 回答"这个包逻辑上有多长";skb->truesize 回答"内核为了保存这个包付出了多少内存"。这两个数经常差很多。
一个 64 字节小包的 truesize 可能远大于 64,因为还要算 struct sk_buff 头、head buffer、skb_shared_info、对齐和 slab 成本。这就是为什么小包 PPS 很可怕:你以为每个包只有 64 字节,内核记账却贵得多。socket 的 sk_rcvbuf / sk_wmem_queued、内存压力、TCP 自动调参,都按 truesize 算,而不是按 payload。
排查 SO_RCVBUF、UDP drop、TCP receive queue 变满时,如果只看 skb->len,你会严重低估真实内存压力。
7.2 checksum 不只是包里的两个字节
01 篇提醒过"tcpdump 看到的校验和可能骗你"。原因就在 skb 的 checksum 元数据:ip_summed、csum、csum_start、csum_offset。
现代网卡常做 checksum offload:
- 发送侧 skb 可用
CHECKSUM_PARTIAL 表示"校验和还没填完,请设备按 csum_start/csum_offset 完成"。 - 接收侧 skb 可能带
CHECKSUM_UNNECESSARY 或 CHECKSUM_COMPLETE,表示设备/内核已验证或已算出。
所以 tcpdump 抓到"bad checksum"不一定表示线上包错了——很可能只是抓包点太早,看到的是网卡填 checksum 之前的 skb。
7.3 mark / hash / vlan:包内容之外的系统判断
sk_buff 也是策略和性能元数据的载体,但归因要稳:
mark:不只是"用户态打的标签"。socket option、tc、Netfilter/nftables、路由策略等路径都可能设置它,并参与策略路由或分类。hash:可服务 RPS/RFS、队列选择、flow dissection、流量分布等,不要简单写成"用于 ECMP"。- VLAN tag:可能由硬件/驱动抽取到 skb 元数据中(
skb_vlan_tag_present()),也可能仍在线性数据区里。
重点不是背字段,而是知道:skb 同时携带"包内容"和"系统对这个包的判断"。
八、现代演进与版本契约
Benvenuti 写书时,sk_buff 已经很完善。但 2.6 之后的二十年,内核给它又加了几件家伙什。
8.1 skb extension(skb_ext)
老内核里,某些子系统需要在 sk_buff 上挂自己的元数据时,常见做法是给 struct sk_buff加一个字段或维护专门的 clone/free 钩子。典型历史包袱包括 IPsec secpath、bridge netfilter 的 nf_bridge 等。结果是结构体或释放路径越来越复杂,大部分包却用不上这些字段。
skb_ext 可扩展机制在 5.0 引入,5.6+ 随 MPTCP 合入而更常被讨论。它把部分低频元数据从 struct sk_buff 主体剥离,按需挂载——SKB_EXT_SEC_PATH、SKB_EXT_BRIDGE_NF、SKB_EXT_MPTCP 都是这套机制下的"插件"。注意不要把范围说过头:6.6/6.12 里 Netfilter conntrack 仍有 skb->_nfct 字段,并没有被整体搬进 skb_ext。
效果:sk_buff 主体在 cache 友好范围里基本稳定,新增功能不再无止境地胀。
8.2 page pool
每收一个高速包都 alloc_page 一次,在 100 Gbps 网卡上是不可承受的开销。
page_pool API 在 4.18 引入框架,5.x 时代开始被更多高速网卡驱动采用(4.18 时多数驱动尚未迁移)。它不是简单的"预先放一堆 page 的池子",而是一套 fast cache、ptr_ring、慢路径分配、DMA sync/recycle 协同的机制。NIC 驱动通常按 RX queue 创建 page_pool,利用 NAPI/softirq 的单消费者语义减少锁竞争——而不是简单的"per-CPU 页池"。DMA 也要说清条件:只有驱动按 page_pool 的 DMA 模型接入,并正确使用 PP_FLAG_DMA_MAP / PP_FLAG_DMA_SYNC_DEV、回收和 sync 规则时,同一 page 的复用才可能显著减少重复 map/unmap 成本;它不是无条件的"映射一次永久有效"。
8.3 XDP / AF_XDP:水的源头开始多元化
XDP/AF_XDP 的高性能来自多层优化,不是单靠 page_pool:
page_pool 解决的是内存分配瓶颈——高 PPS 下避免每包 alloc_page,是支撑线速的底座之一。而 AF_XDP zero-copy 另有自己的内存模型:UMEM(用户态内存池)、XSKMAP、queue binding 与驱动 zero-copy 支持,和 page_pool 是不同层面的事。
边界也要说清:在传统内核协议栈里,sk_buff 仍是最核心的数据载体;但在 native XDP/AF_XDP 路径中,包可能先以 xdp_buff 或 UMEM frame 的形态被处理,只有需要进入经典协议栈的包,才会继续构造成 sk_buff。所以 sk_buff 仍是"协议栈的水",但水的源头开始多元化了。
8.4 版本契约对照表
| | |
|---|
| h | transport_header/network_header/mac_header offset |
tail | | 64 位上为 sk_buff_data_t offset |
| | |
| 直接往 struct sk_buff 加字段或维护专门钩子 | skb_ext 按需挂载(5.0+,但 _nfct 等仍在主结构) |
| | page_pool 复用(4.18 框架 / 5.x 起更多驱动采用) |
| | TCP 发送路径用 fclone,命中槽不走 slab |
九、动手实验与下篇预告
实验 1:打印当前内核里 sk_buff 头的大小。
# 最通用:读 slab 里 skb 头缓存的对象大小(无需 BTF)cat /sys/kernel/slab/skbuff_head_cache/object_size# 有 BTF 的内核也可用 bpftrace 交叉验证sudo bpftrace -e 'BEGIN { printf("sizeof sk_buff = %d\n", sizeof(struct sk_buff)); exit(); }'
在 6.6 内核上,通常落在 232–248 字节,与编译选项有关。和 6.1 节说的"clone 只复制元数据头"对上号了。
实验 2:观察发送出口附近 skb 的非线性程度。
# 需要 BTF。arg0 是 struct sk_buff *sudo bpftrace -e 'kprobe:__dev_queue_xmit{ $skb = (struct sk_buff *)arg0; @data_len = hist($skb->data_len); // 非线性部分 @linear = hist($skb->len - $skb->data_len); // 线性部分}'
在 sendfile、GSO/TSO、SG DMA 生效的 HTTP 下载路径上观察 @data_len 的分布,你通常会看到不少大包是非线性的。但这个实验结果依赖应用发送方式、TLS 是否软件加密、qdisc/隧道路径、网卡 SG/GSO 能力和 offload 开关;不要把"所有 HTTP 大包都非线性"当成定律。 (老博客里那条挂在 tcp_sendmsg 上、把 args[1] 当 sk_buff* 的命令是错的:tcp_sendmsg(sk, msg, size) 的 args[1] 是 struct msghdr *。)
实验 3:看 skb 的释放路径。
sudo perf stat -e 'skb:kfree_skb' -e 'skb:consume_skb' -a sleep 5
consume_skb 是正常消费释放;现代内核的 kfree_skb tracepoint / kfree_skb_reason() 体系可以携带 drop reason,但普通释放可能只是 SKB_DROP_REASON_NOT_SPECIFIED。两者比值不能直接换算成业务丢包率——clone、GSO/GRO 聚合、控制包、未标注原因的释放都会影响计数。要定位丢点,得结合 drop reason、调用栈、nstat、ethtool -S、tc -s qdisc 和抓包位置:
sudo perf record -e 'skb:kfree_skb' -a sleep 5 && sudo perf script # 看丢在哪个栈
下篇预告:
第 03 篇,把目光从"水"转向"管道"——struct net_device。
eth0 和 br0 在内核眼里有什么区别(以及没什么区别)?netdev_ops 虚函数表为什么不用 C++?网卡 up/down 时,通知链是怎么把消息广播给路由、防火墙、bridge 各个子系统的?为什么 6.x 把 atomic_t refcnt 改成了 per-CPU 引用计数,这个改动解决了什么生产问题?
挑战题:如果一个 sk_buff 同时有 frags(非空)和 frag_list(非空),它的 skb->len 怎么算?画一张图说明数据在内存里是怎么分布的。
「提示: skb->len = (tail - data) + data_len 其中 data_len = frags 各页数据之和 + frag_list 中所有子 skb 的 len 之和。线性部分用 skb_headlen() 拿,总长用 skb->len。」
延伸阅读
- 内核源码:
include/linux/skbuff.h、net/core/skbuff.c、net/core/gro.c、net/packet/af_packet.c - 内核文档:Checksum offloads、Segmentation offloads
- LWN:"The page pool API"、"Extending the use of skb extensions"
- Christian Benvenuti, Understanding Linux Network Internals, Chapter 2
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
