由于借助 AI 工具学习编程已经变得非常容易了,因此之后的课程就不再默认进行视频讲解了,如果特别需要视频讲解也可以联系李老师预约讲解~讲义材料学习过程中遇到的问题也可以及时与李老师联系。
购买 RStata 名师讲堂会员即可参加该课程啦(之前的和未来的都可以参加)!
价格:2800/年 或者 4800/长期
购买会员可以从这里下单:https://rstata.duanshu.com/#/card/list/
名师讲堂会员权益:
- 参加平台上的其他 R 语言和 Stata 的课程;
- 以会员折扣价购买我们分享的数据资料(10 元/份);
* 如果发票可添加小编微信 r_stata2 (RStata 李老师)开具。如需数据资料,购买后可添加小编微信免费领取数据折扣卡。
更多关于 RStata 会员的更多信息可添加微信号 r_stata2 咨询:

课程主页(点击文末的阅读原文即可跳转):https://rstata.duanshu.com/#/brief/course/fd6b33d0630545daafa61ecd607a55f5
今天给大家分享使用 Python 提取城市共同边界、识别边界相交乡镇并计算各乡镇到边界距离的完整方法。该指标可用于研究城市交界地区的经济发展、人口流动、环境溢出等空间边界效应,是空间计量与城市经济学研究中的重要变量。
处理过程基于 2021 年行政区划矢量数据,识别出全国 955 对相邻城市,提取其共同边界,并计算出各边界乡镇到共同边界的距离。最终产出包括:城市共同边界矢量文件、边界相交乡镇列表及距离矩阵,可直接用于 Stata 或 Python 的实证分析。
指标介绍
城市共同边界:指两个相邻城市行政区划多边形相交形成的线段(shared border)。例如成都市与德阳市相邻,两者的行政边界相交形成一条共同边界线。
边界相交乡镇:指行政边界多边形与城市共同边界线相交的乡镇(街道)。这些乡镇位于城市交界处,是研究"边界效应"(border effect)的核心样本。
距边界距离:指乡镇行政中心(质心)到最近的城市共同边界线的直线距离(米),用于构造连续的空间边界距离变量。
乡镇对-城市对距离矩阵:对于每一对相邻城市,分别列出两侧所有边界乡镇及其到共同边界的距离,形成"乡镇对"级别的分析数据。
整个处理流程分为九个步骤,下面逐一介绍。
使用 reticulate 创建与管理 Python 虚拟环境
在 R 中通过 reticulate 包来调用 Python,最好的实践是为项目创建一个专属的 Python 虚拟环境,将所需依赖隔离到独立空间,避免与系统 Python(如 Anaconda)发生版本冲突。
重要说明(避免"已初始化"报错):reticulate 在 R 会话中只能绑定一次 Python——一旦某个 {python} 代码块运行,Python 解释器就被锁定,之后再调用 use_virtualenv() 会报错:
ERROR: The requested version of Python cannot be used, as another version has already been initialized.因此,虚拟环境的激活必须在所有 {python} 代码块之前完成。本文档的解决方案是在 setup chunk 中通过 Sys.setenv(RETICULATE_PYTHON = ...) 提前锁定 Python 路径,这是 reticulate 选取 Python 的最高优先级入口。
安装 reticulate(仅首次)
options(repos = c(CRAN = "https://mirrors.tuna.tsinghua.edu.cn/CRAN/"))if (!requireNamespace("reticulate", quietly = TRUE)) { install.packages("reticulate") message("reticulate 安装完成!") message("reticulate 已安装,版本:", packageVersion("reticulate"))虚拟环境初始化原理(已在 setup chunk 中完成)
本文档的 setup chunk(隐藏运行)包含如下逻辑:
.venv_python <- virtualenv_python(.venv_name)if(!file.exists(.venv_python)){ virtualenv_create(.venv_name) .venv_python <- virtualenv_python(.venv_name)Sys.setenv(RETICULATE_PYTHON = .venv_python)use_virtualenv(.venv_name, required =TRUE)这样做的关键在于:knitr 在处理第一个 {python} chunk 时,reticulate 已经通过 RETICULATE_PYTHON 环境变量知道要使用 .venv,不会再去碰 Anaconda。
在虚拟环境中安装 Python 包(仅首次)
"numpy", "pandas", "geopandas", "shapely","pyproj", "matplotlib", "pyogrio"installed <- py_list_packages(".venv")$packageneed_install <- setdiff(py_pkgs, installed)if (length(need_install) > 0) { virtualenv_install(".venv", packages = need_install) message("已安装缺失的包:", paste(need_install, collapse = ", ")) message("所有 Python 包已就绪,无需安装")验证激活状态
查看已安装的包
pkgs <- py_list_packages(".venv")key_pkgs <- c("numpy", "pandas", "geopandas", "shapely", "matplotlib")pkgs[pkgs$package %in% key_pkgs, c("package", "version")]虚拟环境管理常用命令
# virtualenv_remove(".venv") # 删除虚拟环境# virtualenv_install(".venv", "geopandas", ignore_installed = TRUE) # 升级包
数据准备:将 town.rds 转为 GeoPackage
Python 无法直接读取 R 的 .rds 格式,需在 R 中先将乡镇矢量数据转出为通用格式(GeoPackage):
town_rds_path <-"town.rds"town_gpkg_path <-"town.gpkg"if(!file.exists(town_gpkg_path)){ town_r <- readRDS(town_rds_path) st_write(town_r, town_gpkg_path, delete_dsn =TRUE, quiet =TRUE) message(sprintf("✓ town.gpkg 已生成(%d 个乡镇)", nrow(town_r))) message("town.gpkg 已存在,跳过转换")
第 1 步:读取数据
首先加载 Python 包,读取 2021 年城市级和乡镇级行政区划矢量数据,并统一投影坐标系(Albers 等面积投影):
from shapely.ops import unary_unionwarnings.filterwarnings("ignore")RES_DIR = os.path.join(SRC_DIR, "res")os.makedirs(RES_DIR, exist_ok=True)city_raw = gpd.read_file(os.path.join(SRC_DIR, "2021行政区划/市.shp"))town_raw = gpd.read_file(os.path.join(SRC_DIR, "town.gpkg"))town_raw = town_raw.rename(columns={"code": "乡镇代码", "Name": "乡镇名称"})town_raw["乡镇代码"] = town_raw["乡镇代码"].astype(str)city_raw = city_raw.to_crs(proj_crs)city = city_raw[["市代码","市","省","geometry"]].rename( columns={"市": "市名称", "省": "省名称"}print(f"CRS: {proj_crs}")print(f"城市数:{len(city)},乡镇数:{len(town_raw)}")关键说明:
town.gpkg 为从 town.rds 转换而来的乡镇级矢量数据(含 43,366 个乡镇多边形),已使用 Albers 等面积投影;- 城市数据同步转换到相同 CRS,确保后续空间运算准确无误;
MAX_TOWNS_PER_SIDE = 500 控制每侧最多保留的乡镇数量;GRID_SIZE = 400000 为格网大小(400 km),用于后续空间索引加速。
第 2 步:预计算乡镇质心坐标
为提高后续大规模距离计算的速度,先一次性计算所有乡镇的质心坐标并存入数据框:
town_base = town_raw[["乡镇代码","乡镇名称"]].copy()town_base["cx"] = town_raw.geometry.centroid.x.valuestown_base["cy"] = town_raw.geometry.centroid.y.valuesprint(f"质心计算完成:{len(town_base)} 个乡镇")关键说明:
geometry.centroid 计算每个乡镇多边形的质心(几何中心);- 将几何信息转为普通数据框列(
cx、cy),为后续格网索引和空间匹配做准备。
第 3 步:判断乡镇所属城市
乡镇矢量数据本身不包含"所属城市"字段,用空间连接(sjoin within)将乡镇质心与城市多边形匹配:
第 4 步:构建格网空间索引(加速查询)
将整个研究区域划分为 400 km × 400 km 的网格,每个乡镇根据其质心归入对应格网,大幅缩短候选乡镇的筛查时间:
town_tbl["gx"] = (town_tbl["cx"] / GRID_SIZE).apply(math.floor).astype(int)town_tbl["gy"] = (town_tbl["cy"] / GRID_SIZE).apply(math.floor).astype(int)for _, row in town_tbl.iterrows(): key = (int(row["gx"]), int(row["gy"])) grid_dict.setdefault(key, []).append(row["乡镇代码"])defget_candidates_by_bbox(bbox_m): xmin, ymin, xmax, ymax = bbox_m gx_lo = math.floor(xmin / GRID_SIZE) gx_hi = math.floor(xmax / GRID_SIZE) gy_lo = math.floor(ymin / GRID_SIZE) gy_hi = math.floor(ymax / GRID_SIZE)for gx inrange(gx_lo, gx_hi + 1):for gy inrange(gy_lo, gy_hi + 1): cand_codes.extend(grid_dict.get((gx, gy), []))return town_tbl.iloc[0:0].copy()return town_tbl[town_tbl["乡镇代码"].isin(cand_codes)]print(f"格网数:{len(grid_dict)}")
第 5 步:识别相邻城市对
使用 Shapely 的 .touches() 方法识别哪些城市多边形在空间上相邻(存在公共边界):
city_geom = city.geometry.valuesfor j inrange(i + 1, n_cities):if city_geom[i].touches(city_geom[j]):"市代码1": city.iloc[i]["市代码"],"市名称1": city.iloc[i]["市名称"],"市代码2": city.iloc[j]["市代码"],"市名称2": city.iloc[j]["市名称"],"城市对": f"{city.iloc[i]['市代码']}-{city.iloc[j]['市代码']}"adj_df = pd.DataFrame(adj_rows)print(f"相邻城市对:{len(adj_df)}")关键说明:
.touches() 判断两个几何对象是否有公共边界但不重叠,等价于 R 的 st_touches();range(i+1, n_cities) 确保每个城市对只记录一次;
第 6 步:提取城市共同边界
对每一对相邻城市,用 intersection() 计算两个城市多边形的几何交集,并从中提取线要素:
关键说明:
intersection() 计算两个几何对象的交集,等价于 R 的 st_intersection();- 从
GeometryCollection 中提取线要素,等价于 R 的 st_collection_extract(..., "LINESTRING"); unary_union() 合并多段边界,等价于 R 的 st_union()。
第 6b 步:保存城市对共同边界矢量数据
将所有城市对的共同边界几何数据导出为 shp 矢量文件:
关键说明:
GeoDataFrame() 构造包含属性和几何数据的空间数据框,等价于 R 的 st_sf();city_pair 字段为"市代码1-市代码2"格式,可直接与其他数据关联;- shp 格式字段名不超过 10 字符,因此使用短英文名。
输出文件说明:
第 7 步:构建乡镇空间数据(含所属城市)
将乡镇矢量数据与城市匹配结果合并,为后续相交判断做准备:
town_sf = town_raw[["乡镇代码","乡镇名称","geometry"]].copy() town_tbl[["乡镇代码","市代码","市名称"]],print(f"乡镇空间数据:{len(town_sf)} 行")
第 8 步:查找边界相交乡镇并计算距离
这是整个流程的核心步骤。对每对城市,用格网索引快速筛选候选乡镇,再用 .intersects() 精确判断,最后计算各乡镇质心到共同边界的距离:
找到相交乡镇后,用 .distance() 计算每个相交乡镇质心到共同边界的最短距离,然后将两侧乡镇交叉配对,形成"乡镇对"级别的分析数据。最终得到 82,497 对乡镇对,涉及 14,789 个边界相交乡镇。
第 9 步:输出结果文件
所有结果均输出为 Stata .dta 格式(version=118 支持 UTF-8 中文),并添加了详细的变量标签:
"乡镇对": "乡镇对(乡镇代码1-乡镇代码2)","城市对": "所在城市对(市代码1-市代码2)","乡镇代码1": "乡镇1行政区划代码(12位)","乡镇代码2": "乡镇2行政区划代码(12位)","所在城市代码1":"乡镇1所在城市代码(6位)","所在城市代码2":"乡镇2所在城市代码(6位)","距离1_米": "乡镇1质心到城市对共同边界距离(米)","距离2_米": "乡镇2质心到城市对共同边界距离(米)",defwrite_dta(df, path, labels=None):for col in df2.select_dtypes(include="object").columns: df2[col] = df2[col].astype(str) variable_labels = {k: v for k, v in (labels or {}).items() if k in df2.columns} df2.to_stata(path, write_index=False, version=118, variable_labels=variable_labels)write_dta(result_df, os.path.join(RES_DIR, "乡镇对边界距离.dta"), LABELS)print(f"✓ res/乡镇对边界距离.dta({len(result_df)} 行)")side1 = result_df[["乡镇代码1","乡镇名称1","所在城市代码1","所在城市名称1","距离1_米","城市对"]].copy()side1.columns = ["乡镇代码","乡镇名称","所在城市代码","所在城市名称","距离_米","城市对"]side2 = result_df[["乡镇代码2","乡镇名称2","所在城市代码2","所在城市名称2","距离2_米","城市对"]].copy()side2.columns = ["乡镇代码","乡镇名称","所在城市代码","所在城市名称","距离_米","城市对"]touching_towns = pd.concat([side1, side2], ignore_index=True).drop_duplicates()"乡镇代码": "与共同边界相交的乡镇代码(12位)","距离_米": "乡镇质心到共同边界距离(米)",write_dta(touching_towns, os.path.join(RES_DIR, "边界相交乡镇.dta"), town_labels)print(f"✓ res/边界相交乡镇.dta({len(touching_towns)} 个乡镇)") town_raw[["乡镇代码","乡镇名称"]].drop_duplicates() .sort_values("乡镇代码").reset_index(drop=True)write_dta(town_lookup, os.path.join(RES_DIR, "乡镇代码名称.dta"), {"乡镇代码":"乡镇行政区划代码(12位)","乡镇名称":"乡镇名称"})print(f"✓ res/乡镇代码名称.dta({len(town_lookup)} 行)") city_raw[["市代码","市","省"]].rename(columns={"市":"市名称","省":"省名称"}) .drop_duplicates().sort_values("市代码").reset_index(drop=True)write_dta(city_lookup, os.path.join(RES_DIR, "城市代码名称.dta"), {"市代码":"城市行政区划代码(6位)","市名称":"城市名称","省名称":"所属省份"})print(f"✓ res/城市代码名称.dta({len(city_lookup)} 行)")print("\n======== 统计摘要 ========")print(f"相邻城市对数量:{n_valid}")print(f"边界相交乡镇:{len(touching_towns)} 个")print(f"乡镇对总数:{len(result_df)}")输出文件说明:
| | |
|---|
乡镇对边界距离.dta | | |
边界相交乡镇.dta | | |
乡镇代码名称.dta | | |
城市代码名称.dta | | |
专题地图展示
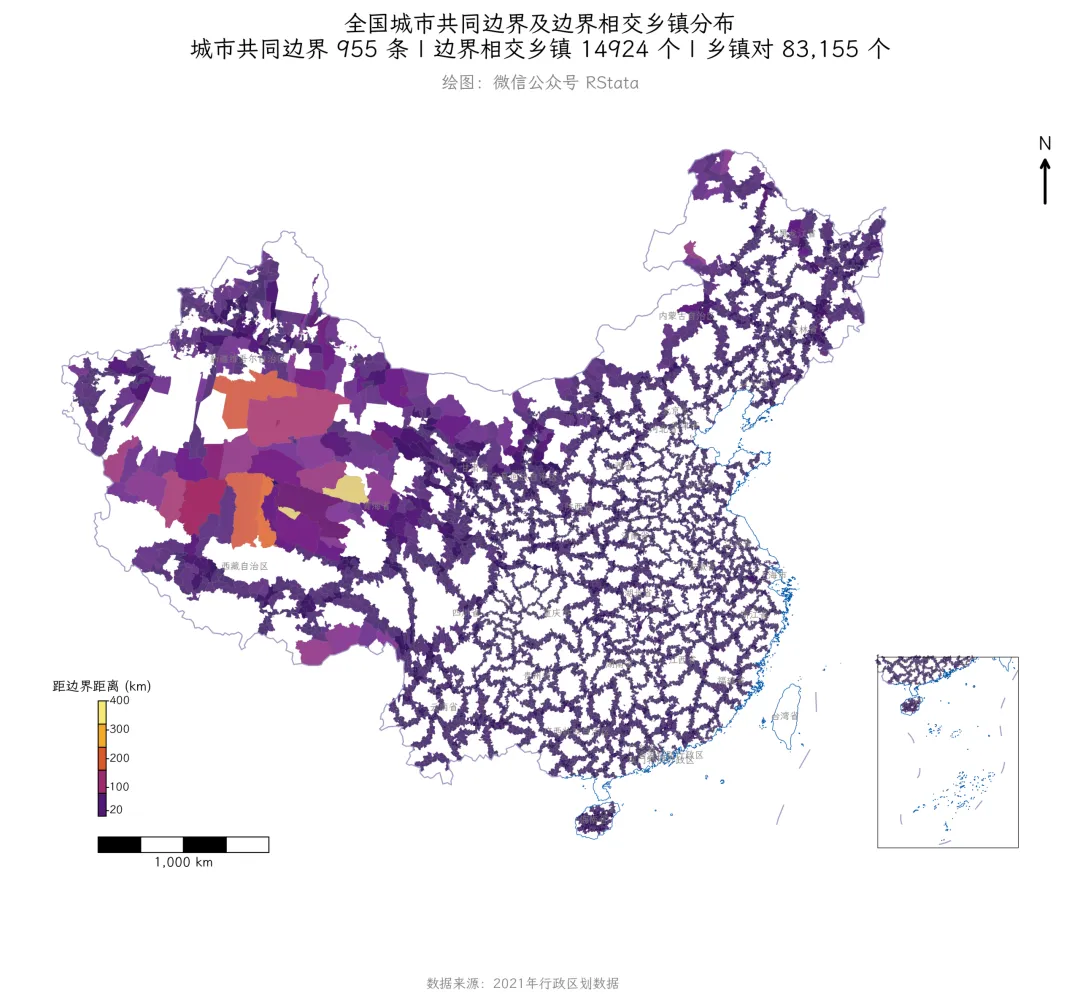
全国城市共同边界及边界乡镇分布图
代码文件:china_border_map_touching.py
该图使用 draw_china_map.py 的辅助函数绘制专业级中国地图,包含南海小地图、省名标注、九段线/海岸线、比例尺和指北针等标准地图元素。乡镇多边形按距边界距离用 Lipari 渐变色填色。
输出图件:
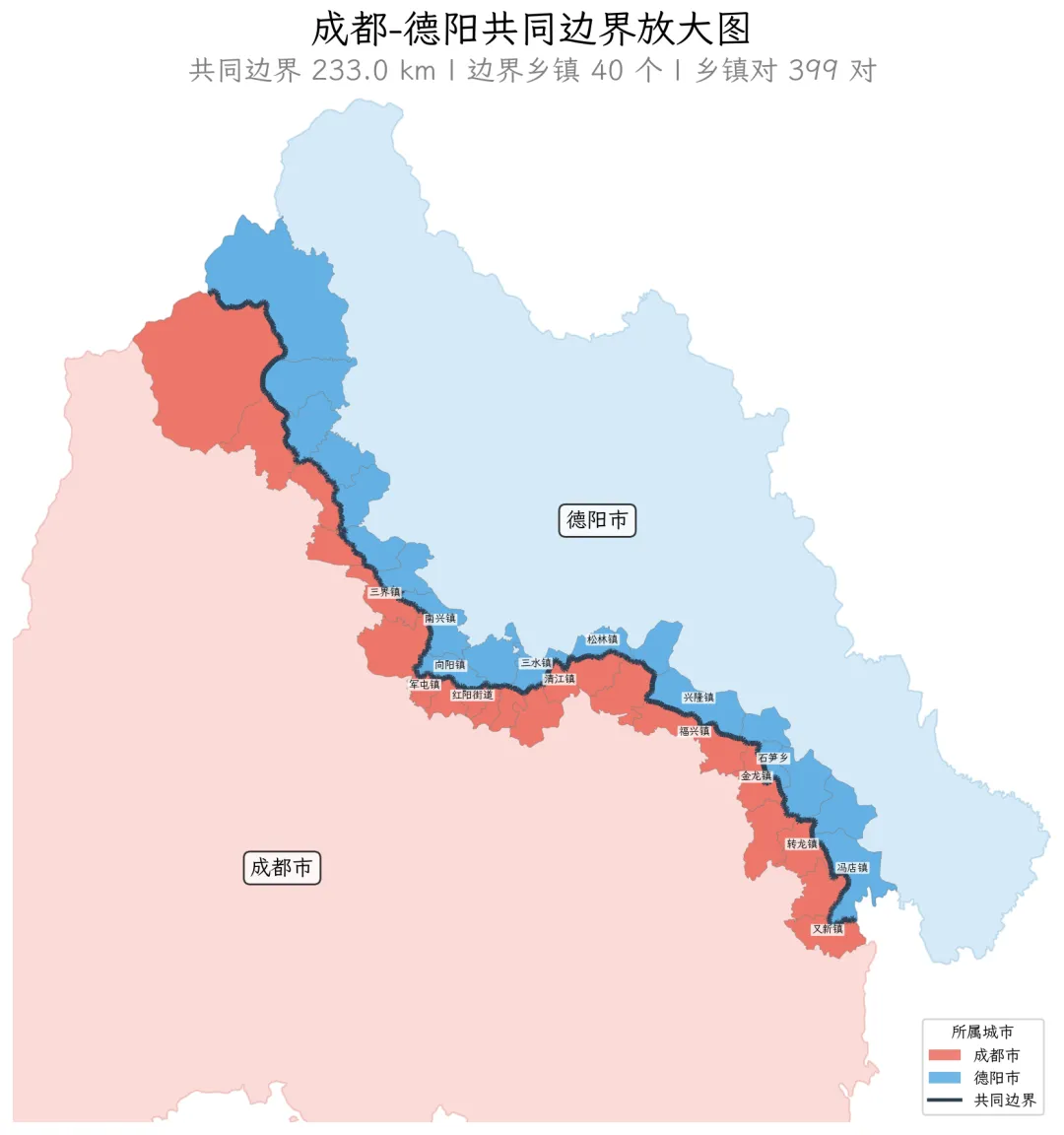
成都-德阳城市对专题放大图
代码文件:chengdu_deyang_map.py
["python", "chengdu_deyang_map.py"], cwd=SRC_DIR, capture_output=True, text=Trueif result.returncode != 0:print("STDERR:", result.stderr)输出图件:
如何参加课程?
购买 RStata 名师讲堂会员即可参加该课程啦(之前的和未来的都可以参加)!
价格:2800/年 或者 4800/长期
购买会员可以从这里下单:https://rstata.duanshu.com/#/card/list/
名师讲堂会员权益:
- 参加平台上的其他 R 语言和 Stata 的课程;
- 以会员折扣价购买我们分享的数据资料(10 元/份);
* 如果发票可添加小编微信 r_stata2 (RStata 李老师)开具。如需数据资料,购买后可添加小编微信免费领取数据折扣卡。
更多关于 RStata 会员的更多信息可添加微信号 r_stata2 咨询:

课程主页(点击文末的阅读原文即可跳转):https://rstata.duanshu.com/#/brief/course/fd6b33d0630545daafa61ecd607a55f5








 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
