用Python做科研级画图——分组误差
- 2026-07-02 10:57:52
大家好,我是你们的小帅学长。
做模型评估时,很多人都会先看整体指标:R²、RMSE、MAE、Bias……只要这些数字不错,心里就会松一口气。
但科研里一个非常常见、也非常危险的误区是:整体表现好,不等于局部表现也好。
你可能会遇到这样的情况:
模型总体 RMSE 不高,但在高值区误差明显变大
整体 Bias 接近 0,但在某一类样本上系统性高估
总体精度看起来很好,但一旦按地类、区间、季节拆开,问题就暴露出来了
所以这一篇,我们就讲一个非常关键、也非常“论文级”的评估思路——分组误差,也就是,不要只看整体误差,还要看误差到底“坏”在什么地方。
01.为什么一定要做“分组误差”?
整体误差指标会把所有样本“平均”掉。
平均有一个很大的问题就是它会掩盖结构差异。
比如一个模型在低值区预测很好,在高值区预测很差,最后平均下来,可能看起来只是“还不错”。
但从科学解释和应用角度,这种模型其实并不稳。因为它的误差是有条件地变化的。
分组误差的意义就在于:找出模型在哪些区间表现更差、判断误差是否具有类别依赖、识别系统偏差来自哪里、整体误差告诉你“平均水平”,分组误差告诉你“问题位置”。
02.最常见的两种分组方式
1)按数值区间分箱(bin by range)
适合连续变量,比如:
真值大小区间(低值 / 中值 / 高值)
温度区间、浓度区间、反射率区间
预测值区间
这种分法特别适合回答:模型是不是在某些值域上更容易出错?
例如:在低温区表现很好,在高温区误差突然增大
在小样本区间稳定,在极端值区间崩掉
2)按类别分组(bin by category)
适合离散类别,比如:
地表类型(水体、植被、裸地、建筑)
区域(华北、东北、西北)
季节(春夏秋冬)
模型类别、样本类别
这种分法特别适合回答:模型是不是对某类样本有“偏心”?
例如:对植被区预测更准,对裸地偏差更大
对夏季样本误差低,对冬季样本误差高
03.分组误差最推荐画什么图?
如果你想把“误差结构”讲清楚,我最推荐三种表达:
1)箱线图
每个分组一个箱线图。
优点是:能看中位数、能看离散程度、能看异常值
适合论文里做“误差结构对比”。
2)条形图
每个分组一个 RMSE / MAE / Bias 条形图。
优点是:一眼看清哪个组最好、哪个组最差、适合展示摘要型指标
适合论文中当“总结图”。
3)点图
如果组别多、误差指标单一,我会更推荐点图。
它比柱状图更轻、更干净,也更现代。
04.最常见的误区:分组之后还只看均值
很多人做分组误差,只画每组平均误差。
这当然比只看整体强,但还不够。
因为平均值只能告诉你“中心”,不能告诉你:误差是否分散、是否偏态、是否存在异常值、某一组是不是不稳定
论文里至少用一种“结构图”(箱线图/小提琴图/雨云图)来补充分组指标。这会让你的分析更扎实。
05.论文级示例:按区间分箱 + 箱线图
下面给你一个非常实用的模板,按真值区间分箱,然后看每个区间的误差分布。
import osimport numpy as npimport pandas as pdimport matplotlib as mplimport matplotlib.pyplot as pltfrom matplotlib import font_manager as fm# =========================# 字体设置:英文 Times New Roman + 中文 SimSun# =========================win_fonts = r"C:\Windows\Fonts"for p in [os.path.join(win_fonts, "times.ttf"),os.path.join(win_fonts, "timesbd.ttf"),os.path.join(win_fonts, "timesi.ttf"),os.path.join(win_fonts, "simsun.ttc"),]:if os.path.exists(p):try:fm.fontManager.addfont(p)except Exception:passmpl.rcParams["font.family"] = ["Times New Roman", "SimSun"]mpl.rcParams["axes.unicode_minus"] = False# =========================# 输出路径# =========================OUT_DIR = r"D:\py_figs"os.makedirs(OUT_DIR, exist_ok=True)# =========================# 构造示例数据# =========================np.random.seed(42)y_true = np.random.uniform(280, 320, 600)y_pred = y_true + np.random.normal(0, 2.0, 600)# 制造“高值区误差更大”的现象mask_high = y_true > 305y_pred[mask_high] += np.random.normal(1.2, 1.0, mask_high.sum())errors = y_pred - y_true# =========================# 按真值区间分箱# =========================bins = [280, 290, 300, 310, 320]labels = ["280–290", "290–300", "300–310", "310–320"]df = pd.DataFrame({"True": y_true,"Pred": y_pred,"Error": errors})df["True_bin"] = pd.cut(df["True"], bins=bins, labels=labels, include_lowest=True)# 每个区间的误差数据grouped_errors = [df.loc[df["True_bin"] == lab, "Error"].values for lab in labels]# =========================# 绘图# =========================fig, ax = plt.subplots(figsize=(7.0, 4.6))box = ax.boxplot(grouped_errors,patch_artist=True,widths=0.6,showfliers=True,medianprops=dict(color="black", linewidth=1.5),whiskerprops=dict(color="black", linewidth=1.2),capprops=dict(color="black", linewidth=1.2),boxprops=dict(facecolor="white", edgecolor="black", linewidth=1.2),flierprops=dict(marker='o', markerfacecolor='white', markeredgecolor='black',markersize=4, linestyle='none'))ax.axhline(0, color="red", linestyle="--", linewidth=1.3)ax.set_xticks(range(1, len(labels) + 1))ax.set_xticklabels(labels, fontsize=11)ax.set_title("Grouped Errors by True Value Bins / 按真值区间分组的误差分布", fontsize=14)ax.set_xlabel("True Value Bin (K) / 真值区间", fontsize=12)ax.set_ylabel("Error = Predicted - True (K) / 误差", fontsize=12)for spine in ax.spines.values():spine.set_linewidth(1.2)out_path = os.path.join(OUT_DIR, "grouped_error_by_bins.jpg")fig.savefig(out_path, dpi=300, bbox_inches="tight", pad_inches=0.05)plt.close(fig)print("Saved:", out_path)
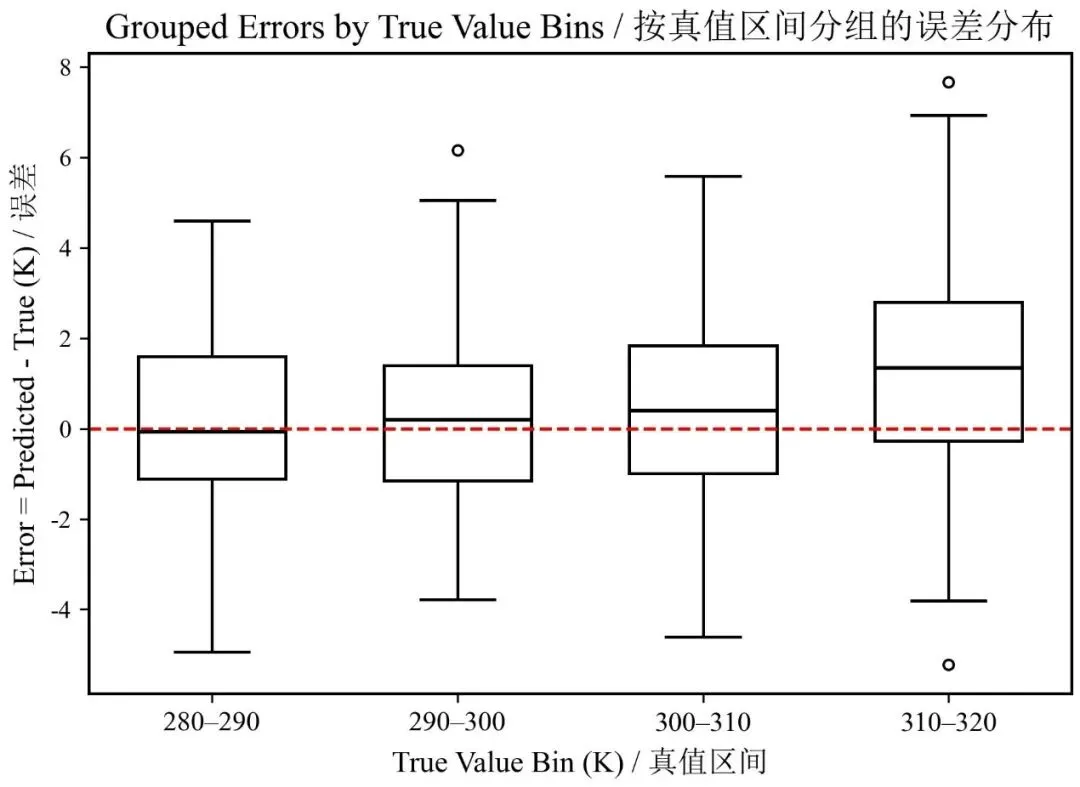
整体误差只能告诉你模型“平均上怎么样”,而分组误差才能告诉你模型“究竟坏在什么地方”——按区间或类别拆开之后,误差的真实结构才会显现出来。
下一篇我们会把误差评估再往前推进一步,进入更适合“横向比较”的图:《多模型对比(箱线 / 条形 / 点图组合)》。这一篇我们会讲,当你不只评估一个模型,而是想把多个模型放在一起比较时,怎样组合不同图形,才能既看出精度差异,又看出稳定性差异。
——期待你的关注——
往期内容:

